# 数据类型 ## 数值 ## 分类 ## 时间序列 当处理有时间序的数据时,很容易把时间结构去掉或者简单地把它当作分类或者数值数据。 一个容易忽略的点就是建立预测性的模型的时候参考了未来的数据点。一定要注意不能把未来的数据用来建模。因为事后诸葛亮是百分之百正确的,回顾比预测要容易太多。在构建预测模型时,通常会把一个时间节点之前的数据作为训练数据,验证数据从那个时间节点向后,测试数据在验证数据后面直到现在。这样你的算法才不会因为用了未来的数据而变的过拟合。 # 分类数据处理 许多算法都要求数据输入是数值型的。对于类别类数据,这通常意味着把类别转换成数字数据并保留同样的信息。 一种标准的做法是使用[scikit-learn](http://scikit-learn.org/stable/)里面的[one-hot encoding](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html)。 本质上来说,一个有三个可能值的分类特征被转换成了对应这三个值的二分类特征。新特征当中对应这个数据的值标为1,其他特征标为0。 这并不是所有特征转换的方法。[这篇文章](http://www.kdnuggets.com/2015/12/beyond-one-hot-exploration-categorical-variables.html) 描述了七种可能的类别类数据转换方法。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
fruit = ['apple','orange','apple']
game = ['lol','overwatch','cf']
data = pd.DataFrame({'fruit':fruit,'game':game})
data
我们构建了一个具有2个特征fruit和game的3条记录。 ||fruit|game| :-:|:-:|:-: 0|apple|lol 1|orange|overwatch 2|apple|cf
le = LabelEncoder()
data = data.apply(le.fit_transform,axis=0)
data
可以看到,字符串类别型的特征通过`LabelEncoder`已经转换成为了对应的数值类别。 ||fruit|game| :-:|:-:|:-: 0|0|1 1|1|2 2|0|0
ohe = OneHotEncoder()
ohelabels = ohe.fit_transform(data)
print ohelabels
可以看到,经过`OneHotEncoder`处理过的数据是稀疏矩阵存储的形式,下面转换为`numpy.array`查看原始形式。 
ohelabels.toarray()
很明显的看出来,每个特征的可能取值,被转换为相应的二值特征 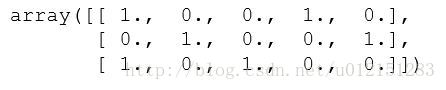 以上操作也可以通过`pandas`自带的`get_dummies`函数实现,但是结果是普通数组,不是稀疏矩阵的形式。
pd.get_dummies(data,columns=data.columns)
| fruit_0 | fruit_1 | game_0 | game_1 | game_2 |
| 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 2 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |



 京公网安备 11010502036488号
京公网安备 11010502036488号