

ACM·大一寒假学习笔记
1/23
DFS代码框架
int ans;//(全局)
void dfs(层数,其他参数){
if(出局判断){
更新答案;
return;
}
(剪枝)
for(枚举下一层可能的情况){
if(used[i]==0){
used[i]=1;
dfs(层数+1,其他参数);
used[i]=0;
}
}
return;
}
DFS的代码比BFS更简单,如果一道题用BFS和DFS都行的话,一般优先DFS。
拓展和优化:剪枝,记忆化(DFS),双向广搜(BFS),迭代加深搜索(DFS),A*算法(BFS),IDA*(DFS)等技术。
3.1.6连通性判断(DFS和BFS)
P8662 [蓝桥杯 2018 省 AB] 全球变暖

DFS求解连通性问题
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1005; int n,cnt=0; int dir[4][2]={{0,1},{1,0},{0,-1},{-1,0}}; int vis[N][N]; string mp[N]; bool flag=false; void dfs(int x,int y){ vis[x][y]=1; if(mp[x][y+1]=='#'&&mp[x][y-1]=='#' &&mp[x+1][y]=='#'&&mp[x-1][y]=='#') flag=1; for(int i=0;i<4;i++){ int nx=x+dir[i][0],ny=y+dir[i][1]; if(!vis[nx][ny] && mp[nx][ny]=='#') dfs(nx,ny); } } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); cin>>n; for(int i=1;i<=n;i++) cin>>mp[i]; for(int i=1;i<=n;i++){ for(int j=1;j<=n;j++){ if(mp[i][j]=='#'&&!vis[i][j]){ flag=0; dfs(i,j); if(!flag) cnt++; } } } cout<<cnt; return 0; }BFS求解连通性问题
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1005; int n,cnt=0; int dir[4][2]={{0,1},{1,0},{0,-1},{-1,0}}; int vis[N][N]; string mp[N]; bool flag=false; void bfs(int x,int y){ queue<pair<int,int>>q; q.push({x,y}); vis[x][y]=1; while(!q.empty()){ pair<int,int> t=q.front(); q.pop(); int tx=t.first,ty=t.second; if(mp[tx][ty+1]=='#'&&mp[tx][ty-1]=='#'&& mp[tx+1][ty]=='#'&&mp[tx-1][ty]=='#') flag=1; for(int i=0;i<4;i++){ ` if(vis[nx][ny]==0 && mp[nx][ny]=='#'){ vis[nx][ny]=1; q.push({nx,ny}); } } } } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); cin>>n; for(int i=1;i<=n;i++) cin>>mp[i]; for(int i=1;i<=n;i++){ for(int j=1;j<=n;j++){ if(mp[i][j]=='#'&&!vis[i][j]){ flag=0; bfs(i,j); if(!flag) cnt++; } } } cout<<cnt; return 0; }
P1219八皇后

#include<bits/stdc++.h> using namespace std; const int N=14; int n,cnt=0; int sav[N]; int row[N],col[N],l[2*N],r[2*N]; //(x,i)对应的行x,列i,左斜线n-x+i,右斜线x+i-1 void dfs(int x){ if(x==n+1){ cnt++; if(cnt==1 || cnt==2 || cnt==3){ for(int i=1;i<=n;i++) cout<<sav[i]<<" "; cout<<endl; } return; } for(int i=1;i<=n;i++){ if(!row[x]&&!col[i]&&!l[n-x+i]&&!r[x+i-1]){ row[x]=1,col[i]=1,l[n-x+i]=1,r[x+i-1]=1; sav[x]=i; dfs(x+1); row[x]=0,col[i]=0,l[n-x+i]=0,r[x+i-1]=0; } } } signed main(){ cin>>n; dfs(1); cout<<cnt; }#include<bits/stdc++.h> using namespace std; const int N=14; int n,cnt=0; int vis[N][N]; int sav[N]; int dir[3][2]={{1,-1},{1,0},{1,1}}; void dfs(int x){ if(x==n+1) { cnt++; if(cnt==1 || cnt==2 || cnt==3){ for(int i=1;i<=n;i++) cout<<sav[i]<<" "; cout<<endl; } return; } for(int i=1;i<=n;i++){ if(vis[x][i]==0){ sav[x]=i; for(int j=0;j<3;j++){ int p=1; while(x+p*dir[j][0]<=n && x+p*dir[j][0]>=1 && i+p*dir[j][1]>=1 && i+p*dir[j][1]<=n){ vis[x+p*dir[j][0]][i+p*dir[j][1]]++; p++; } } dfs(x+1); for(int j=0;j<3;j++){ int p=1; while(x+p*dir[j][0]<=n && x+p*dir[j][0]>=1 && i+p*dir[j][1]>=1 && i+p*dir[j][1]<=n){ vis[x+p*dir[j][0]][i+p*dir[j][1]]--; p++; } } } } } signed main(){ cin>>n; dfs(1); cout<<cnt; }
P1019 [NOIP2000 提高组] 单词接龙

#include<bits/stdc++.h> using namespace std; const int N=21; int vis[N],ycl[N][N],ans=0,n; string s[N]; int link(int x,int y){ if(x==0 && s[y][0]==s[0][0]) return 1; string str1=s[x],str2=s[y]; for(int i=1;i<min(str1.length(),str2.length());i++){ int flag=1; for(int j=0;j<i;j++) if(str1[str1.length()-i+j]!=str2[j]) flag=0; if(flag) return i; } return 0; } void dfs(int x,int cnt){ ans=max(ans,cnt); for(int i=1;i<=n;i++){ if(ycl[x][i] && vis[i]<2){ vis[i]++; dfs(i,cnt+s[i].length()-ycl[x][i]); vis[i]--; } } } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); cin>>n; for(int i=1;i<=n;i++) cin>>s[i]; cin>>s[0];//存首字符 for(int i=0;i<=n;i++) for(int j=1;j<=n;j++) ycl[i][j]=link(i,j); dfs(0,1); cout<<ans; }==预处理的思想==,==两个字符串前后缀交集==
P5194 [USACO05DEC] Scales S
一道绿的不能再绿的紫题

首先想到背包,但是发现其实很难描述状态, 然后,虽然题目中说 n≤1000n≤1000 ,但考虑到“每个砝码的质量至少等于前面两个砝码的质量的和”这一条件,可以推出 n≤30n≤30 。 在这么小的数据范围下,我们考虑用搜索的方法来解决这道题。 背包(dp)弱化后实在不行可以考虑dfs。
#include<bits/stdc++.h> using namespace std; #define int long long const int N=42;//如果N只取到40正好会被第六个样例点卡掉 int n,c,a[N],sum[N]; int ans=0; void dfs(int cur,int x){ //end if(x>c) return; //cut1:前面的能取全取走就结束 if(x+sum[cur-1]<=c) { ans=max(ans,x+sum[cur-1]); return; } ans=max(ans,x); for(int i=1;i<cur;i++) dfs(i,x+a[i]); } signed main(){ cin>>n>>c; for(int i=1;i<=n;i++) { cin>>a[i]; sum[i]=sum[i-1]+a[i]; } dfs(n+1,0); cout<<ans; }==dfs剪枝,前缀和==(无剪枝不搜索)
有空去刷些数论和组合题,把线性筛啊,取模操作啊,排列组合数啊用熟练。(第二次选拔的泪)
1/26
重载运算符(结构体)
//示例(结构体元素直接存入堆中进行nlogn排序) struct node{ int a,b; bool operator <(const node &x)const{return a<x.a;} }; signed main(){ node x{1,2},y{2,1}; priority_queue<node> p; p.push(x); p.push(y); cout<<p.top().b; }大根堆从小到大排序(取出大的)
==bool operator <(const node &x)const{return a<x.a;}==
大根堆从大到小排序(取出小的)
==bool operator <(const node &x)const{return a>x.a;}==
解释: const node &x表示创建了一个外部结构体元素 bool operator < :表示对 < 进行重新定义 主义分号在{}内部,整条语句后边不需要; 重载语句可以写在结构体内部任意位置
BFS判重!(map真的很好用)
例3.2跳蚂蚱
#include<bits/stdc++.h> using namespace std; struct node{ string x; int y; }; map<string,bool> mp; queue<node>q; void solve(){ while(!q.empty()){ node now=q.front(); q.pop(); if(now.x=="087654321"){ cout<<now.y; break; } int i; for(i=0;i<=9;i++) if(now.x[i]=='0') break; for(int j=i-2;j<=i+2;j++){ if(j==i) continue; int k=(j+9)%9; string tmp=now.x; swap(tmp[k],tmp[i]); if(!mp[tmp]){ mp[tmp]=1; q.push(node{tmp,now.y+1}); } } } } signed main(){ string s="012345678"; q.push(node{s,0}); mp[s]=1; solve(); return 0; }==本题思维:将一堆蚂蚱在动转换为一个0的盘子在动==
==map判重== 本题中,map<string,bool> mp; if(!mp[tmp]){mp[tmp]=1;...} 不在map中才执行,不然不跑if内部
==BFS用结构体来存储层数,结束条件直接在进行BFS中if判断==
三角计算优化+最优性剪枝
P1118 [USACO06FEB] Backward Digit Sums G/S (数字三角形)


1.27
DevC++常见错误码
前面一大串是不记的💦 结尾477是数组越界 结尾725是栈溢出(一般就是dfs递归一直一直往下搜) 结尾620是计算的时候除以0 如果程序没动静但是也不跳出来那就是死循环( Lyr-ids: 01-27 00:34:22 然后关于调试这个操作我好长时间没用了喵💦
代码调试小妙招
比如我觉得程序会在某个while里跑不出来然后在while前面后面都输出一个>最后程序跑出来只输出了一个>那就说明这个while确实是死了()
(上述来自喵佬)
1/29
浅浅规划一下。开学前任务量
1.刘某所有课听完。
2.图相关内容强化。
倍增法与ST算法
ST(Sparse Table稀疏表?)总结:
ST算法:用二维数组m[i] [j]表示从下标i开始,长度为2的i次方的子数组的最小值(eg)的索引。
1.常用于解决==RMQ==问题(最值,GCD,LCM等) 2.适用于==静态数据的查询(不支持修改)== 3.经过一次==O(nlogn)的离线预处理==后,==单次查询O(1)== 所有,ST算法尤其适用于查询量很大的问题。

预处理:
m[i] [0]=i hl=(1<<(j-1));//一半长度 if(a[m[i] [j-1]]>=a[m[i+hl] [j-1]]) m[i] [j]=m[i] [j-1]; else m[i] [j]=m[i+hl] [j-1];
void init(){ for(int i=0;i<=n;i++) m[i][0]=i; for(int j=1;(1<<j)<n;j++){ for(int i=1;i<=n;i++){ int hl=(1<<(j-1));//一半长度 if(a[m[i][j-1]]>=a[m[i+hl][j-1]]) m[i][j]=m[i][j-1]; else m[i][j]=m[i+hl][j-1]; } } }
查询:
预处理m[i] [j]实现后,==查询RMQ(i,j)的值ans==。 关键:选择两块能够完全覆盖的区间。
取k=floor(log2(j-i+1)); ans=min(a[m[i] [k]],a[m[j-ksm(s,k)+1] [k]]);
突然想起hdu编赛的黑暗第一题
氯化钠
Time Limit (Java / Others) 17000 / 8500 MS Memory Limit (Java / Others) 262144 / 262144 K Ratio (Accepted / Submitted) 6.19% (14/226)

好像和ST无关? DS说用二分答案+滚动数组维护两个deque? 有空去把书上的deque部分看完好了。
1/30
单调栈
单调栈即==满足单调性的栈结构==。与单调队列相比,其只在一端进行进出。 以下举例及伪代码以维护一个整数的单调递增栈为例。
将一个元素插入单调栈时,为了维护栈的单调性,需要在保证将该元素插入到栈顶后整个栈满足单调性的前提下弹出最少的元素。
例如,栈中自顶向下的元素为{0,11,45,81} 。
插入元素 14 时为了保证单调性需要依次弹出元素 0,11 操作后栈变为 {14,45,81}.
遇到哪些具体的问题会用到单调栈呢?比如:
- 括号匹配问题:确保每个括号都有对应的匹配对象。
- 移除k个最大的元素:保持数组中的最大值在一定范围内。
- 找出最长递增子序列:维护一个递增序列。
- 滑动窗口中的最大值问题:高效地跟踪窗口中的最大值。
- 矩形包围盒的更新:维护当前图形的包围盒。
伪代码
insert x while !sta.empty() && sta.top()<x sta.pop() sta.push(x)P2866 [USACO06NOV] Bad Hair Day S

要求C
1+C2+⋯+CN。改变求和顺序。 sum(每头牛能看到的牛的数量) -> sum(前面的能看到这头牛的牛数量)将问题转化成: (子序列首元素)只对单调严格递减子序列中的后续元素计数,考虑维护单调栈。
10 (a[0]:0) -- 10 10 3 (a[1]:1) -- 10 3 10 3 7 (a[2]:1) -- 10 7 10 3 7 4 (a[3]:2) --10 7 4 10 3 7 4 12 (a[4]:0) -- 12 10 3 7 4 12 2 (a[5]:1) -- 12 2
#include<bits/stdc++.h> using namespace std; #define int long long const int N=8*10e4+5; stack<int> s; signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int n,ans=0,tmp; cin>>n; for(int i=0;i<n;i++){ cin>>tmp; while(!s.empty() && s.top()<=tmp) s.pop(); ans+=s.size(); s.push(tmp); } cout<<ans; }
P2947 [USACO09MAR] Look Up S

从后往前维护单调栈。
#include<bits/stdc++.h> using namespace std; #define int long long const int N=10e5+5; struct node{ int x,id; bool operator <(const node &_)const{return x<_.x;} }cow[N]; stack<node> s; int ans[N]; signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int n; cin>>n; for(int i=1;i<=n;i++){ cow[i].id=i; cin>>cow[i].x; } node tmp; for(int i=n;i>=1;i--){ tmp=cow[i]; while(!s.empty()&&s.top().x<=tmp.x) s.pop(); if(s.empty()) ans[i]=0; else ans[i]=s.top().id; s.push(tmp); } for(int i=1;i<=n;i++) cout<<ans[i]<<"\n"; }
P1901 发射站

分析:ans[i] = 离i最近比a[i]大的a[j] (j<i)
1+ 离i最近比a[i]大的a[j] (j>i)2维护一个单调递减的栈,对于a[i]更新栈后,栈顶元素即为离i最近比a[i]大的a[j] (j<i)
1。对于之前在栈第一个被pop()掉的元素a[k], a[i]就是离k最近比a[k]大的a[i] (i>k)2。#include<bits/stdc++.h> using namespace std; #define int long long const int N=10e6+5; struct node{ int id,h,v; }a[N]; int ans[N]; stack<node> s; bool cmp(int x,int y){ return x>y; } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int n; cin>>n; for(int i=1;i<=n;i++){ a[i].id=i; cin>>a[i].h>>a[i].v; while(!s.empty() && a[i].h>=s.top().h){ if(a[i].h>s.top().h) ans[i]+=a[s.top().id].v; s.pop(); } if(!s.empty()) ans[s.top().id]+=a[i].v; s.push(a[i]); } sort(ans+1,ans+n+1,cmp); cout<<ans[1]; }
单调队列(滑动窗口)
定义:
顾名思义,单调队列的重点分为「单调」和「队列」。 「单调」指的是元素的「规律」——递增(或递减)。 「队列」指的是元素只能从队头和队尾进行操作。 Ps. 单调队列中的 "队列" 与正常的队列有一定的区别
STL中与之类似的数据结构:deque(双端队列)
双端队列:一种具有队列和栈性质的数据结构,它能在两端进行插入和删除,而且只能在两端进行插入和删除。
deque<int> dq dq[i]:返回下标为i的元素 dq.front():返回队头 dq.back():返回队尾 dq.pop_back():删尾 dq.pop_front():删头 dq.push_back():插尾 dq.push_front():插头
P1886 滑动窗口 /【模板】单调队列

#include<bits/stdc++.h> using namespace std; #define int long long const int N=10e6+5; struct node{ int x,id; }a[N]; void Min(int n,int m){ deque<node> dq;//单调递增,首元素为min for(int i=1;i<=n;i++){ while(!dq.empty() && dq.back().x>=a[i].x) dq.pop_back(); dq.push_back(a[i]); //维护deque的长度 while(dq.front().id <= i-m) dq.pop_front(); if(i>=m) cout<<dq.front().x<<" "; } } void Max(int n,int m){ deque<node> dq;//单调递减,首元素为max for(int i=1;i<=n;i++){ while(!dq.empty() && dq.back().x<=a[i].x) dq.pop_back(); dq.push_back(a[i]); //维护deque的长度 while(dq.front().id <= i-m) dq.pop_front(); if(i>=m) cout<<dq.front().x<<" "; } } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int n,m; cin>>n>>m; for(int i=1;i<=n;i++){ a[i].id=i; cin>>a[i].x; } Min(n,m); cout<<endl; Max(n,m); }
堆(题目)
在代码中,如果堆q在某个步骤变成了空,而之后又执行q.top(),这会导致问题,比如未定义的行为,进而导致程序崩溃或无法继续运行,从而卡死。
P1090 [NOIP2004 提高组] 合并果子
P1168 中位数
每次都排序O(nlogn)的时复TLE了...
==通过维护一个大根堆、一个小根堆的保持可以直接查询到中位数。== 对于2i+1个数,大根堆存排序后前i个数,小根堆存排序后后i+1个数。
#include<bits/stdc++.h> using namespace std; #define int long long const int N=10e5+5; int a[N]; priority_queue<int>Mq; priority_queue<int,vector<int>,greater<int>>mq; signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int n; cin>>n; for(int i=1;i<=n;i++){ cin>>a[i]; if(i==1){ mq.push(a[i]); cout<<a[1]<<endl; continue; } if(i%2==0){//偶数 if(a[i]>=mq.top()){ Mq.push(mq.top()); mq.pop(); mq.push(a[i]); } else Mq.push(a[i]); } if(i%2==1){//奇数 if(a[i]>=Mq.top()) mq.push(a[i]); else{ mq.push(Mq.top()); Mq.pop(); Mq.push(a[i]); } cout<<mq.top()<<endl; } } }
P2085 最小函数值
P2827 [NOIP2016 提高组] 蚯蚓
m≤7×10e6 (用来卡prioity_queue).所有只有85...
1/31
欧拉线性筛代码:
int vis[N],p[N];
void get_prime(){
p[0]=0;//记录个数
for(int i=2;i<=N;i++){
if(!vis[i]) p[++p[0]]=i;
for(int j=1;j<=p[0] && i*p[j]<N;j++){
vis[i*p[j]]=1;
if(i%p[j]==0) break;
}
}
}
反悔贪心
反悔贪心是什么?
其实贪心本身不带有反悔,是因为此时的贪心可以从局部最优解推出全局最优解。但当有些时候局部最优解推不出全局最优解时,就要用反悔贪心,在适当的时候撤销之前做出的决策。
希望大家都能真正理解返回贪心,它的精髓就是“常思己过”!
***常思己过,闲谈莫论人非。——明 · 罗洪先《醒世诗》
P3045 [USACO12FEB] Cow Coupons G
题目背景
Subtask 0 为原数据,Subtask 1,2 为 hack 数据。
题目描述
FJ 准备买一些新奶牛。市场上有
头奶牛,第
头奶牛价格为
。FJ 有
张优惠券,使用优惠券购买第
,当然每头奶牛只能使用一次优惠券。FJ 想知道花不超过
的钱最多可以买多少奶牛?
输入格式
* Line 1: Three space-separated integers: N, K, and M.
* Lines 2..N+1: Line i+1 contains two integers: P_i and C_i.
输出格式
* Line 1: A single integer, the maximum number of cows FJ can afford.
样例 #1
样例输入 #1
4 1 7 3 2 2 2 8 1 4 3样例输出 #1
3
第一版...没考虑”换一个用券这个过程为什么不会考虑买另一头牛。因为一开始前k个数据是根据用券后的价格进行排序的。但有可能后面没买过的这个之前用券买的牛的原价要便宜“
(没过hack的数据)
#include<bits/stdc++.h> using namespace std; #define int long long const int N=5e4+5; int n,k,m,ans; struct node{ int p,c; }a[N]; bool cmp1(node x,node y){return x.p<y.p;} bool cmp2(node x,node y){return x.c<y.c;} priority_queue<int,vector<int>,greater<int>> delta; signed main(){ cin>>n>>k>>m; for(int i=1;i<=n;i++) cin>>a[i].p>>a[i].c; sort(a+1,a+n+1,cmp2); if(k<n) sort(a+1+k,a+n+1,cmp1); for(int i=1;i<=n;i++){ if(k){ if(m<a[i].c) break; k--;ans++;m-=a[i].c; delta.push(a[i].p-a[i].c); continue; } //反悔后费用delta.top()+a[i].c //不反悔费用a[i].p if(delta.top()+a[i].c<a[i].p){//反悔策略 if(m<delta.top()+a[i].c) break; ans++;m-=delta.top()+a[i].c; delta.pop(); delta.push(a[i].p-a[i].c); } else{//不反悔,继续贪心 if(m<a[i].p) break; ans++;m-=a[i].p; } } cout<<ans; }
第二版:
#include<bits/stdc++.h> using namespace std; #define int long long #define mp make_pair const int N=5e4+5; int n,k,m,cnt=0; int vis[N],p[N],c[N]; priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>>P,C; priority_queue<int,vector<int>,greater<int>>delta; signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); cin>>n>>k>>m; for(int i=1;i<=n;i++){ cin>>p[i]>>c[i]; P.push(mp(p[i],i)); C.push(mp(c[i],i)); } for(int i=1;i<=n;i++){ if(k){ int x=C.top().second; C.pop(); if(m<c[x]) break; k--;cnt++; m-=c[x]; vis[x]=1; delta.push(p[x]-c[x]); continue; } while(vis[P.top().second]==1) P.pop(); while(vis[C.top().second]==1) C.pop(); int x=P.top().second;//原价最低 int y=C.top().second;//优惠后最低 if(delta.top()+c[y]<p[x]){//反悔(修改用券) if(m<delta.top()+c[y]) break; cnt++; m-=delta.top()+c[y]; vis[y]=1; C.pop(); delta.pop(); delta.push(p[y]-c[y]); } else{//继续贪心,买原价最低 if(m<p[x]) break; cnt++; m-=p[x]; vis[x]=1; P.pop(); } } cout<<cnt; }
Devin说:
ci最小的k个和pi最小的可能有重复
不能简单分段排序就结束,得通过分别都排序,通过标记来做。
所以后面AC的都是3个堆。
实际上维护p,c的也不用堆,事前先都一遍序就行
双指针扫就可以了
这个出队不会再进队了,数组排完序不会变了,给序号打个标记,不要重复就可以了
结构体的priority_queue实现小根堆
Way1:==重载运算符==
struct node{ int val,p; bool operator <(const node &x)const{return val>x.val;} }; priority_queue<node>q;Way2:==取负==
将比较数据变负(取负),将大根堆强行实现小根堆的作用,取出数据时记得取反得到原数据。
Way3:==定义小根堆==
(不知道为什么自家编译器跑不了)
struct node{ int val,p; }; priority_queue<node,vector<node>,greater<node>>q;
2/1
pair(STL)
初始化
- 可以在定义时直接用括号完成
pair的初始化。pair<int, double> p0(1, 2.0);
- 用{}直接表示一对pair
eg:{p[i],i}
q.push({p[i],i});
- 也可以使用先定义,后赋值的方法完成
pair的初始化。pair<int, double> p1; p1.first = 1; p1.second = 2.0;
- ==还可以使用
make_pair函数==。该函数接受两个变量,并返回由这两个变量组成的pair。pair<int, double> p2 = make_pair(1, 2.0);一种常用的方法是使用==宏定义==
#define mp make_pair,将有些冗长的make_pair化简为mp。 (感觉容易和mapmp搞重复啊...)
make_pair可以==配合auto使用==,以避免显式声明数据类型。auto p3 = make_pair(1, 2.0);
访问
通过成员函数
first与second,可以访问pair中包含的两个变量。int i = p0.first; double d = p0.second;
比较
==
pair已经预先定义了所有的比较运算符==,包括<、>、<=、>=、==、!=。当然,这需要组成pair的两个变量所属的数据类型定义了==和/或<运算符。其中,
<、>、<=、>=四个运算符会==先比较两个pair中的第一个变量==,==在第一个变量相等的情况下再比较第二个变量。==由于
pair定义了 STL 中常用的<与==,使得其能够很好的与其他 STL 函数或数据结构配合。==
pair可以作为priority_queue的数据类型。==priority_queue<pair<int, double>> q;
赋值与交换
可以将
pair的值赋给另一个类型一致的pair。p0=p1;==使用
swap函数交换pair的值。==swap(p0, p1);
离散化
pair可以轻松实现离散化。我们可以创建一个
pair数组,将原始数据的值作为每个pair第一个变量,将原始数据的位置作为第二个变量。在排序后,将原始数据值的排名(该值排序后所在的位置)赋给该值原本所在的位置即可。==ai存储的是a按值排序后的id序号== (数组空间:将值的范围->个数)
// a为原始数据 pair<int, int> a[MAXN]; // ai为离散化后的数据 int ai[MAXN]; for (int i = 0; i < n; i++) { // first为原始数据的值,second为原始数据的位置 scanf("%d", &a[i].first); a[i].second = i; } // 排序 sort(a, a + n); for (int i = 0; i < n; i++) { // 将该值的排名赋给该值原本所在的位置 ai[a[i].second] = i; }

USACO2025铜T3


样例1:
输入: 3 1 2 3 1 2 3 输出: 0 3 0 3样例2:
输入: 7 1 3 2 2 1 3 2 3 2 2 1 2 3 1 输出: 0 6 14 6 2 0 0 0==回文数从对称中心开始搜==
#include<bits/stdc++.h> using namespace std; const int N=8e3+5; int a[N],b[N],ans[N]; int k,n; void sol(int l,int r){ int tmp=k; while(l>=1 && r<=n){ tmp-=(a[l]==b[l])+(a[r]==b[r]); tmp+=(a[l]==b[r])+(a[r]==b[l]); l--,r++; ans[tmp]++; } } signed main(){ cin>>n; for(int i=1;i<=n;i++) cin>>a[i]; for(int i=1;i<=n;i++) cin>>b[i],k+=(a[i]==b[i]); for(int i=1;i<=n;i++) sol(i,i); for(int i=1;i<n;i++) sol(i,i+1); for(int i=0;i<=n;i++) cout<<ans[i]<<endl; }
2/2
倍增与ST表(题目)
时间复杂度
预处理go[] []数组: O(nlogn)
一次查询:O(logn)
预处理LOG2(如果嫌库函数log2()比较慢)
lg[i]的值 与 向下取整的log2(i)相等
查询量较大时,预处理LOG2[]较快
lg[1]=0; for(int i=2;i<=N;i++) lg[i]=lg[i>>1]+1;用log2()函数时通过整数赋值可以省略floor
int k=log2(n); for(int i=1;i<=k;i++){ for(int s=1;s+(1<<k)-1<=n;s++){ ...... } }
P4155 [SCOI2015] 国旗计划 (倍增思想)

1.化圆为线
2.贪心。问题等价于:选取最少的线段使得完全覆盖”数轴“。
对比题目:P1803线段覆盖(经典贪心)

共同点:对右端点进行排序,贪心放置。 不同点:P1803是选择下一条左端点在该点右边(不重合)的点 P4155是选择一条重合部分最少的点。(就是排序后下一个不重合点的前一个)
贪心用来初始化go[s] [0]。
3.倍增法(查询):go[s] [i]表示:从第s区间出发该选择的第2^i条线段(区间编号) 满足go[s] [i]=go[go[s] [i-1]] [i-1]; go数组属于预处理部分
#include<bits/stdc++.h> using namespace std; const int N=2e5+5; #define int long long int n,m; int res[N],go[2*N][20];//go[s][i]表示:s后第2**i的区间 2**20=1e6 struct node{ int id,l,r; bool operator <(const node &x)const{return l<x.l;} }w[2*N]; void init(){ int nxt=1; for(int i=1;i<=2*n;i++){ while(nxt<=2*n&&w[nxt].l<=w[i].r) nxt++; go[i][0]=nxt-1; } for(int i=1;(1<<i)<=n;i++) for(int s=1;s<=2*n-1;s++) go[s][i]=go[go[s][i-1]][i-1]; } void sol(int x){ int end=w[x].l+m,cur=x,ans=1; for(int i=log2(n);i>=0;i--){ int pos=go[cur][i]; if(pos==0 || w[pos].r>=end) continue; ans+=1<<i; cur=pos; } res[w[x].id]=ans+1; } signed main(){ cin>>n>>m; for(int i=1;i<=n;i++){ w[i].id=i; cin>>w[i].l>>w[i].r; if(w[i].r<w[i].l) w[i].r+=m; } sort(w+1,w+n+1); for(int i=1;i<=n;i++){ w[i+n].id=w[i].id; w[i+n].l=w[i].l+m; w[i+n].r=w[i].r+m; } init(); for(int i=1;i<=n;i++) sol(i);//排序后存储顺序变化 for(int i=1;i<=n;i++) cout<<res[i]<<" "; }
P2880 [USACO07JAN] Balanced Lineup G (ST表)

法1:ST表
#include<bits/stdc++.h> using namespace std; #define int long long const int N=5e4+5; int n,q,h[N],LOG2[N],st_max[N][21],st_min[N][21]; void st_init(){//此时ST表直接存值(不存下标) LOG2[0]=-1; for(int i=1;i<=N;i++) LOG2[i]=LOG2[i>>1]+1; for(int i=1;i<=n;i++)//初始化长度为1的ST表 st_max[i][0]=st_min[i][0]=h[i]; for(int i=1;i<=LOG2[n];i++){ for(int s=1;s+(1<<i)-1<=n;s++){ int tmp=(1<<(i-1)); st_max[s][i]=max(st_max[s][i-1],st_max[s+tmp][i-1]); st_min[s][i]=min(st_min[s][i-1],st_min[s+tmp][i-1]); } } } int query(int l,int r){//将一段[l,r]拆成[l,l+(1<<k)]和[r-(1<<k)+1,r] int k=LOG2[r-l+1];//k满足2**k<=len && 2**(k+1)>=len int x=max(st_max[l][k],st_max[r-(1<<k)+1][k]); int y=min(st_min[l][k],st_min[r-(1<<k)+1][k]); return x-y; } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); cin>>n>>q; for(int i=1;i<=n;i++) cin>>h[i]; st_init(); int a,b; for(int i=1;i<=q;i++){ cin>>a>>b; cout<<query(a,b)<<endl; } }法2:线段树
#include<bits/stdc++.h> using namespace std; const int N=5e4+5; #define int long long #define mid ((l+r)>>1) struct node{ int l,r,M,m; }t[N<<2]; int n,q,x,y,a[N]; void build(int x,int l,int r){ if(l==r){t[x].M=t[x].m=a[l];return;} build(x<<1,l,mid); build(x<<1|1,mid+1,r); t[x].M=max(t[x<<1].M,t[x<<1|1].M); t[x].m=min(t[x<<1].m,t[x<<1|1].m); } int query_M(int L,int R,int x,int l,int r){ if(L<=l&&r<=R) return t[x].M; if(L>r||R<l) return 1; return max(query_M(L,R,x<<1,l,mid),query_M(L,R,x<<1|1,mid+1,r)); } int query_m(int L,int R,int x,int l,int r){ if(L<=l&&r<=R) return t[x].m; if(L>r||R<l) return 1e7; return min(query_m(L,R,x<<1,l,mid),query_m(L,R,x<<1|1,mid+1,r)); } signed main(){ cin>>n>>q; for(int i=1;i<=n;i++) cin>>a[i]; build(1,1,n); for(int i=1;i<=q;i++){ cin>>x>>y; cout<<query_M(x,y,1,1,n)-query_m(x,y,1,1,n)<<endl; } }
P5465 [PKUSC2018] 星际穿越


思路:
1.前缀和思想

2.贪心 + 倍增优化 与**[SCOI2015]国旗计划**神似。
以往都是对ans直接进行倍增优化.本题对前缀和数组进行直接倍增优化。
具体转移:
f[i][j]:从i跳2^j步能到达的左端点。 状态转移方程:f[i][j]=f[f[i][j-1]][j-1] g[i][j]:从i到[ f[i][j],i-1 ]区间上所有点的最小步数和 g[i][j]= g[i][j-1] + g[f[i][j-1][j-1]+(f[i][j-1]-f[i][j])*2^(j-1)转移初始化:
关键:f[i] [0]=min(f[i+1] [0] , l[i]);

f[n][0]=l[n];g[n][0]=n-l[n]; for(int i=n-1;i>=2;i--){ f[i][0]=min(f[i+1][0],l[i]); g[i][0]=i-f[i][0]; }代码:
#include<bits/stdc++.h> using namespace std; #define int long long const int N=3e5+5; int n,q,f[N][20],g[N][20],l[N]; int gcd(int a,int b){ return b>0?gcd(b,a%b):a; } void init(){ f[n][0]=l[n];g[n][0]=n-l[n]; for(int i=n-1;i>=2;i--){ f[i][0]=min(f[i+1][0],l[i]); g[i][0]=i-f[i][0]; } int tmp=log2(n); for(int j=1;j<=tmp;j++){ for(int i=(1<<j);i<=n;i++){ f[i][j]=f[f[i][j-1]][j-1]; g[i][j]=g[i][j-1]+ g[f[i][j-1]][j-1]+(1<<j-1)*(f[i][j-1]-f[i][j]); } } } int query(int x,int to){//x到区间[to,x-1]内所有点的步数和 if(l[x]<=to) return x-to;//第一跳,特判 int ans=x-l[x], tot=1;//tot记录已经跳了多少步 x=l[x]; for(int i=log2(n);i>=0;i--){ if(f[x][i]>=to){ ans+= tot*(x-f[x][i])+g[x][i]; tot+=(1<<i);x=f[x][i]; } } if(x>to) ans+= x-to +tot*(x-to);//(?) return ans; } signed main(){ cin>>n; for(int i=2;i<=n;i++) cin>>l[i]; init(); cin>>q; int L,R,x; int fm,fz,GCD; for(int i=1;i<=q;i++){ cin>>L>>R>>x; fz=query(x,L)-query(x,R+1); fm=R-L+1; GCD=gcd(fm,fz); fm/=GCD;fz/=GCD; cout<<fz<<"/"<<fm<<endl; } }疑问(未解答):
2/4
双指针(尺取法)
作用:将二重循环O(n^2)变成O(n)
把双指针技巧再分为两类,一类是「快慢指针」,一类是「左右指针」。
前者主要解决链表中的问题,比如典型的==判定链表中是否包含环==;
后者主要解决数组(或者字符串)中的问题,比如==二分查找,第K小/大的数,滑动窗口==。
1.左右指针(反向扫描)
找指定和的整数对

输入:
9 21 4 5 6 13 65 32 9 23 28输出:
5 23const int N=1e5+5; int a[N]; signed main(){ int n,p,q,tar; cin>>n; for(int i=1;i<=n;i++) cin>>a[i]; cin>>tar; p=1,q=n; sort(a+1,a+n+1); while(p<q){ int sum=a[p]+a[q]; if(sum>tar) q--; if(sum<tar) p++; if(sum==tar){ cout<<a[p]<<" "<<a[q]<<endl; p++; } } }满足条件后别忘记==p++==,不然进死循环
!!!第k小的数(经典双指针对搜+二分答案)
f(x)表示多少对i,j满足a[i]+b[j]<=x. f(x)<=f(x+1),单调 只需找最小的x使得f(x)>=k.关键:对于给定的x,如何统计有多少对i,j满足a[i]+b[j]<=x(重复的最后一个) a[1...n],b[1...m]数组排序后双指针(一个从前一个从后搜,使得实现线性复杂度) int f(int x){ int cnt=0; int j=m; for(int i=1;i<=n;i++){ while(j&&a[i]+b[j]>x) j--; cnt+=j; } return cnt; }
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e5+5; int a[N],b[N]; int n,m,k,l,r,mid; int f(int x){ int cnt=0; int j=m; for(int i=1;i<=n;i++){ while(a[i]+b[j]>=x) j--; cnt+=j; } return cnt; } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int t;cin>>t; while(t--){ cin>>n>>m>>k; for(int i=1;i<=n;i++) cin>>a[i]; for(int j=1;j<=m;j++) cin>>b[j]; sort(a+1,a+n+1); sort(b+1,b+m+1); l=a[1]+b[1],r=a[n]+b[m]; while(l<=r){ mid=(l+r)>>1; int tmp=f(mid); if(tmp<k) l=mid+1; else r=mid-1; } cout<<r<<endl; } }
2.同向扫描
寻找区间和
输入长度为n的数组a[]和一个s,使得找出数组中的区间使得这个区间的数组元素之和等于s。 输出区间的起点和终点位置。
输入:
15 6 1 2 3 4 6 4 2 8 9 10 11 12 13 14 6输出:
0 0 1 3 5 5 6 7指针i,j都从头到尾 (1)sum==s。输出,sum-=a[i++]; (2)sum>s。sum-=a[i++]; (3)sum<s。sum+=a[++j];
代码:
const int N=1e5+5; int a[N]; signed main(){ int n,s; cin>>n; for(int i=1;i<=n;i++) cin>>a[i]; cin>>s; int i=1,j=1,sum=a[1]; while(j<=n){ if(sum==s){ cout<<i<<" "<<j<<endl; sum-=a[i++]; } if(sum>s) sum-=a[i++]; if(sum<s) sum+=a[++j]; } }
数组去重(不保序)
给定数组a[],长度为n,把数组中重复的数去掉。
法1.Hash
法2.尺取法 数组排序 快慢指针i,j。 j为慢指针,始终指向当前不重复部分的最后一个数 i为快指针。 如果a[i]!=a[j],则a[++j]=a[i];
signed main(){ int n; cin>>n; for(int i=1;i<=n;i++) cin>>a[i]; sort(a+1,a+n+1); int i=1,j=1; for(;i<=n;i++) if(a[i]!=a[j]) a[++j]=a[i]; for(int k=1;k<=j;k++) cout<<a[k]<<" "; }
习题:P1102 A-B 数对
2/5-2/6
用sort对vector排序的简便写法
vector<int> a[N];//邻接表
...
sort(a[i].begin(),a[i].end(),cmp);
sort第三个参数实现从大到小
sort(a + 1, a + 1 + n); // 从小到大排序
sort(a + 1, a + 1 + n, greater<int>()); // 从大到小排序
遍历map等stl的简便写法
for(auto it:mp){...}
字符串正整数转int
int tran(string x){
int tmp=0;
for(int i=x.length()-1;i>=0;i--){
tmp*=10;
tmp+=x[i]-'0';
}
return tmp;
}
lower_bound()和upper_bound()函数(STL)
二者均定义于头文件
<algorithm>中三个参数:(起始地址,终止地址+1,目标值) upper_bound():查找==第1==个==大于==x的元素的位置。 lower_bound():查找==第1==个==大于等于==x的元素的位置
作用:找x或x附近的元素的位置。 (1)查找==第1==个==大于==x的元素的位置:
upper_bound()eg:int pos=upper_bound(a+1,a+n+1,x)-a;(2)查找==第1==个==大于等于==x的元素的位置:
lower_bound()(3)查找==第1==个与x==相等==的元素的位置:
lower_bound()并且等于x(4)查找==最后一==个与x==相等==的元素:
upper+bound()的前一个并且等于x(5)查找==最后一==个==小于等于==x的元素:
upper+bound()的前一个(6)查找==最后一==个==小于==x的元素:
lower_bound()的前一个(7)单调序列中x的个数:
upper_bound()-lower_bound()
unique()函数(相邻的重复元素去除)
包含在
#include<algorithm>
搭配sort实现整体数组去重(O(n+nlogn))
sort(a.begin(),a.end()); int cnt=unique(a.begin(),a.end())-a.begin();sort(a+1,a+n+1); //同时实现'去重'和'求去重后的元素个数' int cnt=unique(a+1,a+n+1)-(a+1); //cnt为去重后的数量
离散化
(1)排序 (2)离散化:从1开始逐个分配数值。 (3)归位:把离散后的数据放回原位。
手动离散化
用结构体或者pair进行存储数据。
struct data{ int val,id; bool operator<(const data &x)const{return val<x.val;} }a[N]; int ai[N];//离散后的结果,即ai[i]存'a[i]的数据排第几' signed main(){ int n;cin>>n; for(int i=1;i<=n;i++){ cin>>a[i].val; a[i].id=i; } sort(a+1,a+n+1); for(int i=1;i<=n;i++){ ai[a[i].id]=i; if(a[i].val==a[i-1].val) ai[a[i].id]=ai[a[i-1].id];//等大取等序(第一个数不能是0) //若上面两行注释掉表示:等大时,先输入数据的序小 } for(int i=1;i<=n;i++) cout<<ai[i]<<" "; }重复元素标准处理方法:
sort(a+1,a+n+1); ai[a[1].id]=1; //法1: for(int i=2,cnt=1;i<=n;i++){ if(a[i].val==a[i-1].val) ai[a[i].id]=cnt; else ai[a[i].id]==++cnt; } //法2: for(int i=2;i<=n;i++){ ai[a[i].id]=i; if(a[i].val==a[i-1].val) ai[a[i].id]=ai[a[i-1].id]; }
用STL函数实现离散化(没啥鸟用)
int a[N],ai[N];//离散后的结果,即ai[i]存'a[i]的数据排第几' signed main(){ int n;cin>>n; for(int i=1;i<=n;i++){ cin>>a[i]; ai[i]=a[i]; } sort(a+1,a+n+1); int cnt=n; //cnt=unique(a+1,a+n+1)-(a+1);//去重 for(int i=1;i<=cnt;i++) ai[i]=lower_bound(a+1,a+1+n,ai[i])-a; //查找相等元素的位置,即排第几。 for(int i=1;i<=cnt;i++) cout<<ai[i]<<" "; }
2/7
进制Hash(BKDRHash)
·隐性取模
取空间大小为M=2^64(unsigned long long型的长度)。 当一个unsigned long long型的Hash值H>M时会自动溢出,等价于对M自动取余,避免了低效的取模运算。
·BKDRHash
设置一个进制P,将字符串按照P进制的形式按位计算映射到的数,最后对M进行取余。 进制P常用值为31,131,1313,1331,13131,131313 ...
一种是直接取每个字符的ASCII码代表其数字:
res=res\*p+s[i];另一种是对应字符看作一个数字,eg:a=1,b=2,c=3,...,z=26:res=res\*p+(s[i]-'a'+1);#define ull unsigned long long //typedef unsigned long long ull; ... ull a[N];//ull隐式取模2^64 ull BKDRHash(string s){ ull p=131,res=0; for(int i=0;i<s.length();i++) res=res*p+s[i]; return res; }
·字符串的前后缀问题(进制Hash)
设字符串S的哈希值为H(S),长度为len(S)。 字符串组合:H(S
1+S2)=H(S1)*P[len(S2)]+H(S2); (其中P[i]表示P的i次方)O(n)的时间内处理所有前缀的哈希值: eg:S="abcdefg" (1)H(a) (2)H(ab)=H(a)*P+H(b) (3)H(abc)=H(ab)*P+H(c) ... <1>字符串数组会方便一点。 char s[N]; cin>>(s+1); **
for(int i=1;i<=n;i++) f[i]=f[i-1]*pp+s[i];** <2>字符串s前补一位,使得有效存储首元素下标为1. (space键的ASCII值为0,其实这个无所谓) **for(int i=1;i<=s.length();i++) f[i]=f[i-1]*pp+s[i];**O(1)的时间内查询任意区间[L,R]的哈希值 eg: H(de)=H(abcde) - H(abc)*P[2]; 代码:
ull get_hash(ull L,ull R){return H[R]-H[L-1]*P[R-L+1];}
P3370 【模板】字符串哈希

BKDRHash模板
#include <bits/stdc++.h> #define ull unsigned long long using namespace std; const int N=1e4+5; ull a[N];//ull隐式取模2^64 string s; ull BKDRHash(string s){ ull p=131,res=0; for(int i=0;i<s.length();i++) res=res*p+s[i]; return res; } signed main(){ int n;cin>>n; for(int i=1;i<=n;i++){ cin>>s; a[i]=BKDRHash(s); } int ans=0; sort(a+1,a+n+1); //ans=unique(a+1,a+n+1)-(a+1);去重函数,与下面循环等价 for(int i=1;i<=n;i++) if(a[i]!=a[i+1]) ans++; cout<<ans; }这题还可以直接用map<string,int> mp;
P3501 [POI 2010] ANT-Antisymmetry (?)

STL bitset

2/9
二叉树的三种遍历方式
用一维数组模拟树(适合层序输出)
1 2 3 4 5 6 7 8 void init(int n){ for(int i=1;i<=n;i++){ if((i<<1)<=n) node[i].l=i<<1; if((i<<1|1)<=n) node[i].r=i<<1|1; } }
后序遍历(输出):左->右->根
后序:8->4->5->2->6->7->3->1
void Post(int x){
if(node[x].l!=0) Post(node[x].l);//访问左节点
if(node[x].r!=0) Post(node[x].r);//访问右节点
cout<<node[x].val;//访问根节点
}
中序遍历(输出):左->根->右
中序:8->4->2->5->1->6->3->7
void In(int x){
if(node[x].l!=0) In(node[x].l);
cout<<node[x].val;
if(node[x].r!=0) In(node[x].r);
}
先序遍历(输出):根->左->右
先序:1->2->4->8->5->3->6->7
void Pre(int x){
cout<<node[x].val;
if(node[x].l!=0) Pre(node[x].l);
if(node[x].r!=0) Pre(node[x].r);
}

二分



两种模板(以找区间左端点为例)
(无脑版)
int l=1,r=n,mid,ans;
while(l<=r){
mid=l+r>>1;
if(a[mid]>=tmp) r=mid-1;
else l=mid+1;
}
int l=0,r=n+1,mid;
while(l+1<r){
mid=l+r>>1;
if(a[mid]>=tmp) r=mid;
else l=mid;
}
P3853 [TJOI2007] 路标设置

此题为二分求最优解的模板
对于任意一个给出的“空旷指数”G,我们应该怎样去判断它是否符合题目的意思呢?
我们可以想象,我们已知了这条路上的所有的路标,我们从头开始枚举两两相邻的路标的间距,如果大于G,那么已经不符合G为最大距离的条件了,为了使G满足,我们就可以在前一个路标前面G米处加一个路标,这样与前面一个就符合条件了,再判断新设的路标和后面的路标是否距离小于G,如果不,继续重复操作设置新路标
当新设的路标数已经超过题目所给最大增设值时,如果还有路标不满足G,但已经不能设置新路标了,所以该G值就不满足条件。相反,则G成立。
注意到,如果一个“空旷指数”成立,那么可能存在比它更小的解,但如果一个“空旷指数”不成立,那么答案只能比该值更大
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e5+5; int l,n,k,a[N]; bool jud(int x){ int cnt=0,p=1,tmp=a[p]; while(tmp<l && cnt<=k){ while(a[p+1]<=tmp) p++; if(a[p+1]-tmp<=x) tmp=a[++p]; else{ cnt++; tmp+=x; } } return (cnt<=k)?true:false; } signed main(){ cin>>l>>n>>k; for(int i=1;i<=n;i++) cin>>a[i]; int L=0,R=l,mid,ans=l; while(L<=R){ mid=L+R>>1; if(jud(mid)){ ans=min(ans,mid); R=mid-1; } else L=mid+1; } cout<<ans; }
map对key降序排列
map<int,int,greater<int>> mp;关键字greater<...>的数据类型与key的数据类型相同。
2/10-2/11
拓扑排序

拓扑排序分为无前驱节点优先和无后继节点优先两种,下只记无前驱(入度为0)。
拓扑排序无解判断(可以用来判环)如果队列已空,但还有点未入队(ans.size()<n)
BFS模板
queue<int> q; vector<int> G[N]; vector<int> ans; //存放拓扑序列 int in[N]; bool bfs_topsort(int n){ //n为节点个数 for(int i=1;i<=n;i++) if(in[i]==0) q.push(i); //将入度为0的点入队列 while(!q.empty()){ int u=q.front();q.pop(); //选一个入度为 0 的点,出队 ans.push_back(u); for(int i=0;i<G[u].size();i++){ int v=G[u][i]; if(--in[v]==0) q.push(v); //当某一条边的入度为0,入队 } } if(ans.size()==n){ for(int i=0;i<ans.size();i++) printf("%d%c",ans[i],i==ans.size()-1?'\n':' '); return true; } return false; }
DFS模板
const int N=1e5+10; vector<int> G[N]; int vis[N]; //1代表正在访问,-1代表访问结束,0代表未访问 int ans[N],tot; bool dfs_topsort(int u){ //从节点u出发 vis[u]=1; //正在访问 for (int i=0;i<G[u].size();i++){ int v=G[u][i]; if(vis[v]==1) return false; //如果后继比前驱先访问,说明存在有向环 if(!vis[v]&&!dfs_topsort(v)) return false; //如果后继未被访问,访问后继返回假,也是失败 } vis[u]=-1; ans[tot++]=u; //在递归结束才加入拓扑序列数组中,最深层次先返回 return true; } int main(){ int n,m,a,b; cin>>n>>m; while(m--){ cin>>a>>b; G[a].push_back(b); } for(int i=1;i<=n;i++) if(!vis[i]) dfs_topsort(i); for(int i=tot-1;i>=0;i--) cout<<ans[i]<<" "; return 0; }
拓展
1.如何判断拓扑序列是否唯一?
即判断队列中元素个数是否大于1
//判断拓扑序列是否唯一 bool bfs_topsort(int n){ for(int i=1;i<=n;i++) if(in[i]==0) q.push(i); while(!q.empty()){ if(q.size()>1) return false; int u=q.front(); q.pop(); ans.push_back(u); for(int i=0;i<G[u].size();i++){ int v=G[u][i]; in[v]--; if(in[v]==0) q.push(v); } } return true; }2.如何求出所有的拓扑序列?
回溯法:类比全排列,每次for循环只有没访问过且入度为0的节点更新到答案数组中,每次dfs之后都将标志清空,将入度回复,这样和全排列一样最后可以生成按字典序由小到大的拓扑序列。
int n,m; vector<int> G[maxn]; //邻接表存储图 int ans[maxn],in[maxn]; bool vis[maxn]; void dfs_all_topsort(int x){ //x初始传入1 if(x==n+1){ for(int i=1;i<=n;i++) printf("%d%c",ans[i],i==n?'\n':' '); return; } for(int i=1;i<=n;i++) if(!vis[i]&&!in[i]){ ans[x]=i; vis[i]=1; for(int j=0;j<G[i].size();j++) in[G[i][j]]--; dfs_all_topsort(x+1); //继续深层遍历 //由底层开始逐层返回需要恢复初始状态 vis[i]=0; for(int j=0;j<G[i].size();j++) in[G[i][j]]++; } } int main(){ int a,b; scanf("%d%d",&n,&m); memset(vis,0,sizeof vis); for(int i=1;i<=n;i++) G[i].clear(); while(m--){ scanf("%d%d",&a,&b); G[a].push_back(b); in[b]++; } dfs_all_topsort(1); return 0; }
确定比赛名次(DBcode)

#include<bits/stdc++.h> #define int long long using namespace std; const int N=5e2+5; vector<int> pic[N]; int indgr[N],res[N]; queue<int> q; signed main() { ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); int n,m,x,y; while(cin>>n>>m){ memset(indgr,0,sizeof(indgr)); int cnt=0; for(int i=1;i<=m;i++){ cin>>x>>y; pic[x].push_back(y); indgr[y]++; } for(int j=1;j<=n;j++){ for(int i=1;i<=n;i++){ if(indgr[i]==0){ res[j]=i; indgr[i]=-1; while(!pic[i].empty()){ indgr[pic[i].back()]--; pic[i].pop_back(); } break; } } } for(int i=1;i<n;i++) cout<<res[i]<<" "; cout<<res[n]<<endl; } }
欧拉路
定义¶
通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
通过图中所有边恰好一次且行遍所有顶点的回路(起点和终点相同)称为欧拉回路。
具有欧拉回路的无向图称为欧拉图。
具有欧拉通路但不具有欧拉回路的无向图称为半欧拉图。
性质¶
欧拉图(欧拉回路的无向图)中所有顶点的度数都是偶数。
若 是欧拉图,则它为若干个边不重的圈的并。 若 是半欧拉图,则它为若干个边不重的圈和一条简单路径的并。
判断条件
(1)无向连通图:(度数为奇数的点称为奇点,偶点同理)
存在欧拉回路:所有点都是偶点。
存在欧拉路:只有两个奇点,其一作为起点,另一作为终点。
(2)有向连通图:(将一个点的度数记作
出度-入度)存在欧拉回路:所有点的度数为0.
存在欧拉路径:只有一个点度数为1,一个点度数为-1,其余均为0.(度数为1的点是起点,-1的点是终点)
求欧拉回路或欧拉路¶
例题 luoguP2731,luoguP1341
(先学Tarjan)
B站试听网课
前缀和(prefix)
前缀和数组通常命名pre[N]或者s[N]
前缀异或和性质: 通过两个相同的前缀数组元素可知中间这段数的异或和为0 通过组合数可以很容易算出有多少段区间异或和为0。
二维前缀和: 先计算一行的前缀和 再对每列计算前缀和。
for(int i=1;i<=n;i++) for(int j=1;j<=m;j++) pre[i][j]=pre[i][j-1]+a[i][j]; for(int j=1;j<=m;j++) for(int i=1;i<=n;i++) pre[i][j]+=pre[i-1][j];或者
for(int i=1;i<=n;i++){ partial_sum(a[i]+1,a[i]+m+1,pre[i]+1); for(int j=1;j<=m;j++) pre[i][j]+=pre[i-1][j]; }原数组a[x,y]与a[p,q](p>x&&q>y)所形成的矩形中的所有数求和为
pre[p][q]+pre[x-1][y-1]-pre[p][y-1]-pre[x-1][q];




差分
用
差分 处理 等差数列
任何符合多项式的累加都可以经过(最高次+1)次差分得到一个常数级的修改方案




前缀和函数
partial_sum(arr.begin(),arr.end(),prefix.begin());若原数组后续不需要,可以直接
partial_sum(arr.begin(),arr.end(),arr.begin());
差分函数
adjacent_difference(arr.begin(),arr.end(),d.begin());
2/13
to_string和stoi函数
头文件都是
#include<string>to_string函数
功能:将数字常量(int,double,long等)转换成字符串(string)。
1.支持带负号
2.若对double类型进行操作默认保留六位小数。
cout<<to-string(-123)[0]; << - --- cout<<to_string(123.456); << 123.456000
stoi函数
功能:将n(默认为10)进制的字符串转换成十进制数字常量。
1.支持正负号
2.支持定义原本字符串为几进制数字字符串。
string a="-12"; cout<<stoi(a)<<endl; <<-12 cout<<stoi(a,0,16)<<endl; <<-18
LCA-倍增算法
P3379 【模板】最近公共祖先(LCA)
#include<bits/stdc++.h> using namespace std; const int N=5e5+5; const int M=19; int n,m,s,a,b; vector<int> e[N]; int dep[N],fa[N][20]; void dfs(int u,int father){ dep[u]=dep[father]+1; fa[u][0]=father; for(int i=1;i<=M;i++) fa[u][i]=fa[fa[u][i-1]][i-1]; for(int v:e[u]) if(v!=father) dfs(v,u); } int lca(int u,int v){ if(dep[u]<dep[v]) swap(u,v); //先跳到同一层 for(int i=M;i>=0;i--) if(dep[fa[u][i]]>=dep[v]) u=fa[u][i]; if(u==v) return v; for(int i=M;i>=0;i--) if(fa[u][i]!=fa[v][i]) u=fa[u][i],v=fa[v][i]; return fa[u][0]; } signed main(){ cin>>n>>m>>s; for(int i=1;i<n;i++){ cin>>a>>b; e[a].push_back(b); e[b].push_back(a); } dfs(s,0); for(int i=1;i<=m;i++){ cin>>a>>b; cout<<lca(a,b)<<endl; } }


2/14-2/15
并查集判断连通块个数
P1197 [JSOI2008] 星球大战


#include<bits/stdc++.h> using namespace std; #define int long long const int N=4e5+5; int n,m,k,x,y,u,v,tot; int ans[N],a[N],be[N],s[N]; vector<int> e[N]; int find(int x){ return s[x]==x?x:s[x]=find(s[x]); } void merge(int x,int y){ x=find(x);y=find(y); if(x!=y) s[x]=s[y]; } signed main(){ cin>>n>>m; for(int i=0;i<n;i++) s[i]=i; for(int i=1;i<=m;i++){ cin>>x>>y; e[x].push_back(y); e[y].push_back(x); } cin>>k; for(int i=1;i<=k;i++){ cin>>x; a[i]=x;//记录被摧毁的星球 be[x]=1;//标记x被摧毁 } tot=n-k;//剩余先独立成块 //判断两星球没被摧毁且没在同一个集合,则合并 for(int u=0;u<n;u++) for(int v:e[u]){ int x=find(u),y=find(v); if(!be[u]&&!be[v]&&x!=y){ s[x]=s[y]; tot--; } } ans[k]=tot;//摧毁k个星球后的ans for(int j=k-1;j>=0;j--){//逆向修复 u=a[j+1];be[u]=0; tot++; for(int v:e[u]){ //都没被摧毁并且在同一个集合,则合并 x=find(u);y=find(v); if(!be[v]&&x!=y){ s[x]=s[y]; tot--; } } ans[j]=tot; } for(int i=0;i<=k;i++) cout<<ans[i]<<endl; }
带权值并查集+二分图
P1525 [NOIP 2010 提高组] 关押罪犯
P1525 [NOIP 2010 提高组] 关押罪犯
题目背景
NOIP2010 提高组 T3
题目描述
S 城现有两座监狱,一共关押着
。他们之间的关系自然也极不和谐。很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突。我们用“怨气值”(一个正整数值)来表示某两名罪犯之间的仇恨程度,怨气值越大,则这两名罪犯之间的积怨越多。如果两名怨气值为
的罪犯被关押在同一监狱,他们俩之间会发生摩擦,并造成影响力为
每年年末,警察局会将本年内监狱中的所有冲突事件按影响力从大到小排成一个列表,然后上报到 S 城 Z 市长那里。公务繁忙的 Z 市长只会去看列表中的第一个事件的影响力,如果影响很坏,他就会考虑撤换警察局长。
在详细考察了
那么,应如何分配罪犯,才能使 Z 市长看到的那个冲突事件的影响力最小?这个最小值是多少?
输入格式
每行中两个数之间用一个空格隔开。第一行为两个正整数
,分别表示罪犯的数目以及存在仇恨的罪犯对数。接下来的
,表示
号和
号罪犯之间存在仇恨,其怨气值为
。数据保证
,且每对罪犯组合只出现一次。
输出格式
共一行,为 Z 市长看到的那个冲突事件的影响力。如果本年内监狱中未发生任何冲突事件,请输出
0。输入输出样例 #1
输入 #1
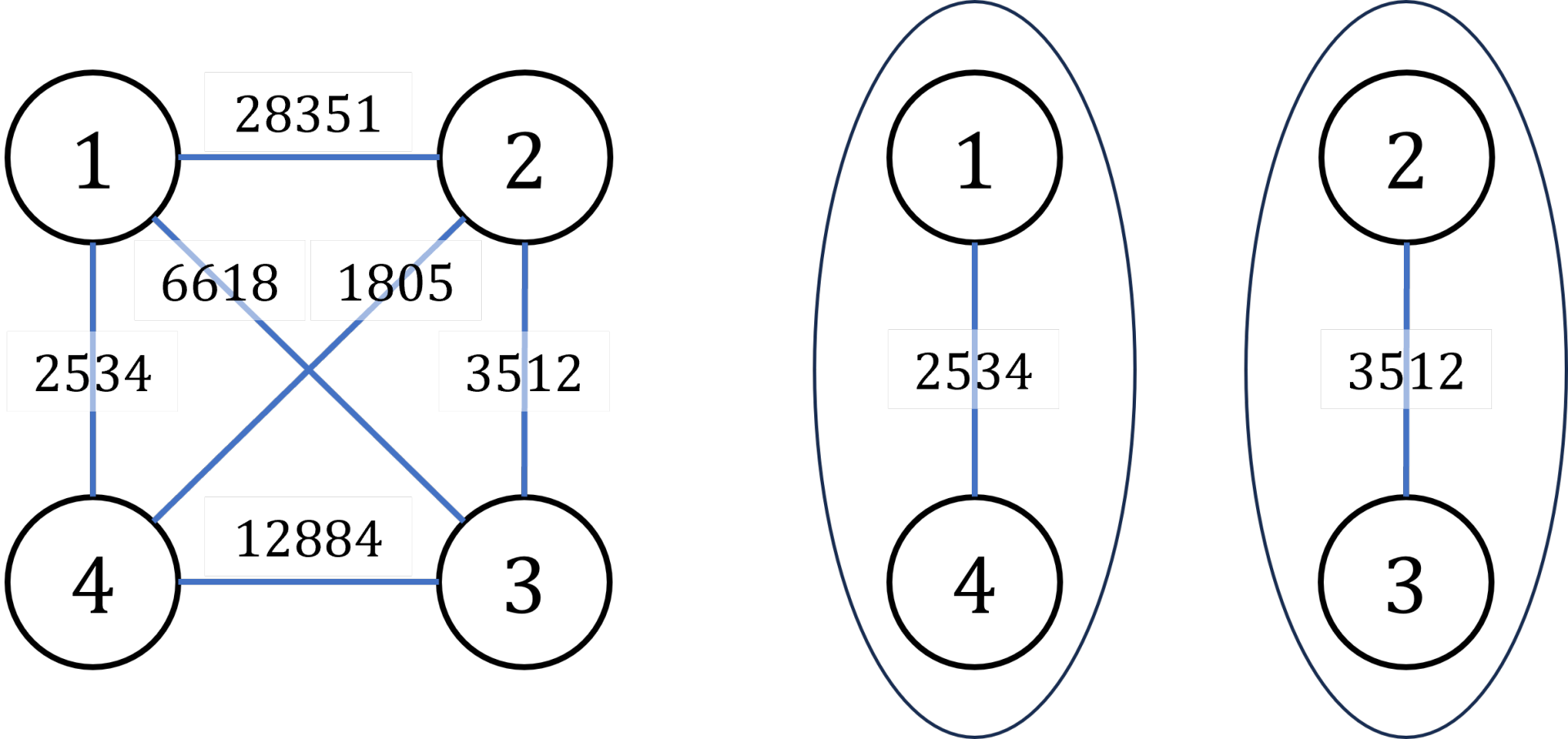
4 6 1 4 2534 2 3 3512 1 2 28351 1 3 6618 2 4 1805 3 4 12884输出 #1
3512说明/提示
输入输出样例说明
罪犯之间的怨气值如下面左图所示,右图所示为罪犯的分配方法,市长看到的冲突事件影响力是
(由
号和
号罪犯引发)。其他任何分法都不会比这个分法更优。
数据范围
对于
的数据有
。
对于
的数据有
。
对于
的数据有
。
题解:
淳朴的并查集~但因为它们带有权值,因此排序是必须的,我们要尽可能让危害大的罪犯在两个监狱里。
那么,再结合**敌人的敌人和自己在一个监狱的规律合并 ( 二分图思想 )**。
当查找时发现其中两个罪犯不可避免地碰撞到一起时,只能将其输出并结束。
还有一点很重要,就是没有冲突时一定输出0!!!
#include<bits/stdc++.h> using namespace std; const int N=1e5+5; int n,m,x,y,s[N]; int p[N];//将罪犯分为0,1两个阵营 struct node{ int x,y,z; bool operator<(const node&x)const{return z>x.z;} }a[N]; int find(int x){ return s[x]==x?x:s[x]=find(s[x]); } void merge(int x,int y){ x=find(x),y=find(y); s[x]=y; } signed main(){ ios::sync_with_stdio(false); cin.tie(0),cout.tie(0); cin>>n>>m; for(int i=1;i<=n;i++) s[i]=i; for(int i=1;i<=m;i++) cin>>a[i].x>>a[i].y>>a[i].z; sort(a+1,a+1+m); for(int i=1;i<=m;i++){ x=find(a[i].x),y=find(a[i].y); if(x==y){cout<<a[i].z;return 0;} else{ if(p[a[i].x]==0) p[a[i].x]=a[i].y; else merge(a[i].y,p[a[i].x]); if(p[a[i].y]==0) p[a[i].y]=a[i].x; else merge(a[i].x,p[a[i].y]); } } cout<<0; }
种类并查集/扩展域并查集
引入
并查集能维护连通性、传递性,通俗地说,
亲戚的亲戚是亲戚。然而当我们需要维护一些对立关系,比如
敌人的敌人是朋友时,正常的并查集就很难满足我们的需求。这时,
种类并查集就诞生了。常见的做法是将原并查集扩大一倍规模,并划分为两个种类。
在同个种类的并查集中合并,和原始的并查集没什么区别,仍然表达
他们是朋友这个含义。考虑在不同种类的并查集中合并的意义,其实就表达
他们是敌人这个含义了。按照并查集美妙的
传递性,我们就能具体知道某两个元素到底是敌人还是朋友了。至于某个元素到底属于两个种类中的哪一个,由于我们不清楚,因此两个种类我们都试试。
具体实现,详见
P1525 关押罪犯。利用并查集本身‘连通性’表示’关系’,用‘坐标区间’表示‘属性’。
P1892 [BalticOI 2003] 团伙

Q:为什么是朋友的情况下不加上merge(x+n,y+n);
Ans(Devin):那句话翻译过来就是“两个朋友各自的敌人是不是需要变成朋友”。
把拓展域并查集理解成’虚拟节点‘:a的敌人a+n,但不知道具体是谁,但是后面把敌人都放到这个并查集里。
#include<bits/stdc++.h> using namespace std; const int N=3e5+5; int s[N]; int n,m,ans; int find(int x){return s[x]==x?x:s[x]=find(s[x]);} void merge(int x,int y){s[find(y)]=find(x);} signed main(){ int x,y; string op; cin>>n>>m; for(int i=1;i<=n<<1;i++) s[i]=i; for(int i=1;i<=m;i++){ cin>>op>>x>>y; if(op=="F"){merge(x,y);} else{merge(x,y+n),merge(y,x+n);} } for(int i=1;i<=n;i++) if(s[i]==i) ans++; cout<<ans; }
P2024 [NOI2001] 食物链
P2024 [NOI2001] 食物链
题目描述
动物王国中有三类动物
,这三类动物的食物链构成了有趣的环形。
吃
,
,
现有
编号。每个动物都是
有人用两种说法对这
- 第一种说法是
1 X Y,表示和
是同类。
- 第二种说法是
2 X Y,表示此人对
- 当前的话与前面的某些真的话冲突,就是假话;
- 当前的话中
- 当前的话表示
你的任务是根据给定的
输入格式
第一行两个整数,
,表示有
第二行开始每行一句话(按照题目要求,见样例)
输出格式
一行,一个整数,表示假话的总数。
输入输出样例 #1
输入 #1
100 7 1 101 1 2 1 2 2 2 3 2 3 3 1 1 3 2 3 14 1 5 5输出 #1
3说明/提示
对于全部数据,
,
。
题解:
概念解释
再来看本题,每个动物之间的关系就没上面那么简单了。
对于动物 x 和 y,我们可能有 x 吃 y,x 与 y 同类,x 被 y 吃。
但由于关系还是明显的,1 倍大小、2 倍大小的并查集都不能满足需求,3 倍大小不就行了!
类似上面,我们将并查集分为 3 个部分,每个部分代表着一种动物种类。
设我们有 n 个动物,开了 3n 大小的种类并查集,其中 1∼n 的部分为 A 群系,n+1∼2n 的部分为 B 群系,2n+1∼3n 的部分为 C 群系。
我们可以认为 A 表示中立者,B 表示生产者,C 表示消费者。此时关系明显:A 吃 B,A 被 C 吃。
当然,我们也可以认为 B 是中立者,这样 C 就成为了生产者,A 就表示消费者。(还有 1 种情况不提及了)
联想一下 2 倍大小并查集的做法,不难列举出:当 A 中的 x 与 B 中的 y 合并,有关系 x 吃 y;当 C 中的 x 和 C 中的 y 合并,有关系 x 和 y 同类等等……
但仍然注意了!我们不知道某个动物属于 A,B,还是 C,我们 3 个种类都要试试!
也就是说,每当有 1 句真话时,我们需要合并 3 组元素。
容易忽略的是,题目中指出若 x 吃 y,y 吃 z,应有 x 被 z 吃。
这个关系还能用种类并查集维护吗?答案是可以的。
若将 x 看作属于 A,则 y 属于 B,z 属于 C。最后,根据关系 A 被 C 吃可得 x 被 z 吃。
既然关系满足上述传递性,我们就能放心地使用种类并查集来维护啦。
一倍存本身,二倍存猎物,三倍存天敌
唯一容易忽略的点就是:一的猎物的猎物 就是一的天敌 那么我们每次只要维护三个并查积的关系就可以了
#include<bits/stdc++.h> using namespace std; const int N=3e5+5; int s[N]; int n,k,ans; int find(int x){return s[x]==x?x:s[x]=find(s[x]);} int merge(int x,int y){ x=find(s[x]),y=find(s[y]); s[x]=y; } signed main(){//对于每种生物:设 x 为本身,x+n为猎物,x+2*n为天敌 int x,y,op; cin>>n>>k; for(int i=1;i<=3*n;++i) s[i]=i; for(int i=1;i<=k;++i) { cin>>op>>x>>y; if(x>n||y>n){ans++;continue;} if(op==1){ if(find(x+n)==find(y)||find(x+2*n)==find(y))//如果x是y的天敌或猎物 {ans++;continue;} merge(x,y);merge(x+n,y+n);merge(x+2*n,y+2*n); } else if(op==2){ if(x==y) {ans++; continue;} if(find(x)==find(y)||find(x+2*n)==find(y))//如果1是2的同类或猎物 {ans++; continue;} merge(x,y+2*n);merge(x+n,y);merge(x+2*n,y+n); //x的同类是y的天敌,x的猎物是y的同类,x的天敌是y的猎物 } } cout<<ans; }
带权并查集
P1196 [NOI2002] 银河英雄传说


dist[i]:i到队列队头的距离. siz[i]:以i为队头的队列的元素个数.
如何计算每个飞船到队头的距离:对于任意一个飞船,我们都知道它的祖先(不一定是队头,但一定间接或直接指向队头),还知道距离它祖先的距离。对于每一个飞船,’它到队头的距离‘ = ’它到它祖先的距离‘ + ’它祖先到队头的距离‘,而它的祖先到队头的距离,也可以变成类似的。 可以递归实现,由于每一次更新都要用到已经更新完成的祖先到队头的距离,所以要先递归找到队头,然后在回溯的时候更新(front[i]+=front[fa[i]]),可以把这个过程和查找队头的函数放在一起。
#include<bits/stdc++.h> using namespace std; const int N=3e4+5; int s[N],dist[N];//dist[i]:i到队列队头的距离 int siz[N];//siz[i]:以i为队头的队列的元素个数 int find(int x){ if(s[x]==x) return x; int root=find(s[x]); dist[x]+=dist[s[x]]; //? return s[x]=root; } signed main(){ char op; int x,y,t; cin>>t; for(int i=1;i<N;i++) s[i]=i,siz[i]=1; while(t--){ cin>>op>>x>>y; if(op=='M'){ int xx=find(x),yy=find(y); s[xx]=yy;//x接在y后面 dist[xx]+=siz[yy]; siz[yy]+=siz[xx]; siz[xx]=0; } else{ if(find(x)!=find(y)) cout<<-1<<endl; else cout<<abs(dist[x]-dist[y])-1<<endl; } } }扩展域并查集不能维护边权。

 京公网安备 11010502036488号
京公网安备 11010502036488号