

前篇主要是讲明pandas到底是什么,pandas中的常用的基本数据方法,数据交互方式,需要注意的踩坑点等。 之前整理了numpy部分的知识点,numpy的numpy.array对于python的数组运算做了很大贡献,使得python程序员可以用接近c语言的速度对矩阵数据进行运算吗,这对于后置的机器学习模块包括深度学习模块的贡献非常大,但对于数据分析来说,例如一个excel文件中,它并不是单独的包含一个数值类型,之前在读取csv文件的时候,显然里面包含时间序列,姓名等字符串序列,那numpy显然在很多时候并不适用于这种场景,而pandas模块应运而生。
安装方式
1. anconda自带
2. pip install pandas -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com/
什么是pandas
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
pandas的特点:
- 基于numpy构建,这一点非常关键,一个模块基于另一个模块构建的话,我们就需要注意在更新版本的时候一定要注重他们之间的版本关联性。
- 由于基于numpy,因此它继承了numpy对于矩阵数据的高性能运算。
- 提供了大量快速且便捷处理数据的方法。
- 常用于数据挖掘与数据分析
- 提供了数据分析的功能。
# daraframe对象与series对象
import pandas as pd
import numpy as np
ser_obj = pd.Series(range(1,6), index = ['a', 'b', 'c', 'd', 'e'])
df_obj = pd.DataFrame(range(5), index = ['a', 'b', 'c', 'd', 'e'])
print(df_obj)
# 它的索引是一个对象,而且这个对象是不可更改的,这样直接的保证了数据的安全性。
print(df_obj.index)
# 尝试打印索引数据,可以观察到是可以打印索引数据的。
print(df_obj.index[0])
# 尝试改变索引数据
try:
df_obj.index[0] = 'e'
print('改变成功')
except Exception as e:
print(e)
print('改变失败')
# 可以观察到这里是直接改变失败的,一旦数据构造完毕,就不能随便去更改它的索引了。
# head属性可以查看dataframe对象的头部信息。
print(df_obj.head())
0
a 0
b 1
c 2
d 3
e 4
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
a
Index does not support mutable operations
改变失败
0
a 0
b 1
c 2
d 3
e 4
# 查看数据
print(ser_obj)
# 查看数据,显然series数据类型,可以通过head名与下标进行访问。
print(ser_obj['a'])
print(ser_obj[0])
a 1
b 2
c 3
d 4
e 5
dtype: int64
1
1
# 切片索引,这里可以观察到切片数据是带有索引的。
print(ser_obj[1:3])
# 换一种方法,结果是一样的。
print(ser_obj['a':'c'])
# 索引也可以是不连续的,这是类似于list和numpy.array对象的。
print(ser_obj[[0, 2, 4]])
# 同样有基于numpy.array的布尔索引。
print(ser_obj[ser_obj>2])
print(ser_obj>2)
b 2
c 3
dtype: int64
a 1
b 2
c 3
dtype: int64
a 1
c 3
e 5
dtype: int64
c 3
d 4
e 5
dtype: int64
a False
b False
c True
d True
e True
dtype: bool
Dataframe数据对象的索引与series是不同的!!!
# 构建一个dataframe数据
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
df_obj
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0.297178 | -0.064710 | -1.945154 | -0.178690 |
| 1 | 1.496176 | -0.369095 | 1.124525 | -0.913287 |
| 2 | 0.341343 | -1.080503 | -0.478856 | 0.418045 |
| 3 | 0.743871 | -0.024557 | 0.241574 | -0.192667 |
| 4 | 1.156650 | 0.549655 | 0.481397 | -0.812955 |
# 尝试根据索引去打印
print(df_obj['a'])
# 换一种方法
try:
print(df_obj[1])
print('打印成功')
except Exception as e:
print(e)
print('显然出错')
0 0.297178
1 1.496176
2 0.341343
3 0.743871
4 1.156650
Name: a, dtype: float64
1
显然出错
讲到这里似乎,dataframe和series并没有什么联系呀,其实不然,两个数据结构放到一块是有原因的,上面那个代码块报错了,那么如果我们换一种写法,如下所示:
print(df_obj['a'][1])
1.4961760531418462
# 显然,这并没有报错,那么在考虑到先前series数据
ser_obj = pd.Series(range(1,6), index = ['a', 'b', 'c', 'd', 'e'])
print(ser_obj[1])
2
series数据类型支持这种写法,提取出dataframe一个column也支持这种写法,答案显然已经呼之欲出了。 一个series对象其实就等于datafram的一个column,或者说,dataframe就是由一堆series组成的。
# 那么dataframe同样支出不连续的索引。
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj)
print(df_obj[['a','c']])
a b c d
0 0.173106 0.199585 -0.292090 -0.324643
1 0.382805 0.207301 1.874807 -0.716093
2 0.606986 -0.370534 1.616169 -1.343322
3 -0.428249 -0.397338 -1.001129 -0.796805
4 2.070116 -0.709817 -1.543283 -0.239500
a c
0 0.173106 -0.292090
1 0.382805 1.874807
2 0.606986 1.616169
3 -0.428249 -1.001129
4 2.070116 -1.543283
高级索引是pandas最重要的索引方式,也是我们能灵活利用pandas的核心技能。必修
- loc:基于列名的索引方式
- iloc:基于列索引id的索引方式
- ix结合12的索引方式
print(df_obj)
a b c d
0 0.173106 0.199585 -0.292090 -0.324643
1 0.382805 0.207301 1.874807 -0.716093
2 0.606986 -0.370534 1.616169 -1.343322
3 -0.428249 -0.397338 -1.001129 -0.796805
4 2.070116 -0.709817 -1.543283 -0.239500
# 前为行数,后为列数,核心是这四种用法,掌握应该就差不多了。
print(df_obj.loc[0:3, 'a':'c'])
print(df_obj.loc[0:3, 'a'])
print(df_obj.loc[0:3, ['a','b']])
print(df_obj.loc[[0,3], ['a','b']])
a b c
0 0.173106 0.199585 -0.292090
1 0.382805 0.207301 1.874807
2 0.606986 -0.370534 1.616169
3 -0.428249 -0.397338 -1.001129
0 0.173106
1 0.382805
2 0.606986
3 -0.428249
Name: a, dtype: float64
a b
0 0.173106 0.199585
1 0.382805 0.207301
2 0.606986 -0.370534
3 -0.428249 -0.397338
a b
0 0.173106 0.199585
3 -0.428249 -0.397338
# 可以看到iloc取用下标为01对应了之前的abc
print(df_obj.iloc[0:3, 0:3])
a b c
0 0.173106 0.199585 -0.292090
1 0.382805 0.207301 1.874807
2 0.606986 -0.370534 1.616169
在现版本中,ix已经被舍弃了,如果输出的话,可以看到报错信息,其实我也觉得ix挺鸡肋的。哈哈哈。
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
print('s1: ' )
print(s1)
print('')
print('s2: ')
print(s2)
# 经过分析得到无数据+有数据为NAN
print(s1 + s2)
s1:
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
s2:
0 20
1 21
2 22
3 23
4 24
dtype: int64
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
dtype: float64
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])
print('df1: ')
print(df1)
print('')
print('df2: ')
print(df2)
print('df1+df2 = \n', df1+df2)
df1:
a b
0 1.0 1.0
1 1.0 1.0
df2:
a b c
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
df1+df2 =
a b c
0 2.0 2.0 NaN
1 2.0 2.0 NaN
2 NaN NaN NaN
观察上面部分的结果,我们来看,不论是series还是datafram,都可以抽象到表格水平进行计算。
pandas的层级索引
import pandas as pd
import numpy as np
ser_obj = pd.Series(np.random.randn(12),index=[
['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]
])
print(ser_obj)
a 0 0.304068
1 -1.109702
2 -0.070409
b 0 -1.344512
1 1.013383
2 -0.208385
c 0 1.443918
1 -0.366639
2 0.016325
d 0 1.172133
1 -0.260486
2 -0.231875
dtype: float64
print(ser_obj['a'][0])
0.3040683834625479
print(ser_obj.index)
MultiIndex([('a', 0),
('a', 1),
('a', 2),
('b', 0),
('b', 1),
('b', 2),
('c', 0),
('c', 1),
('c', 2),
('d', 0),
('d', 1),
('d', 2)],
)
可以根据切片的写法选择子集,或者根据索引的写法取得固定的值
## 验证子集是否可以遍历,如下证明,取出的属于可遍历的元素。
for ele in ser_obj['a']:
print(ele)
0.3040683834625479
-1.1097020808798908
-0.07040932160774192
## 根据子集推论,整体也可以遍历。
for i in ser_obj:
print(i)
0.3040683834625479
-1.1097020808798908
-0.07040932160774192
-1.3445122594840375
1.0133826686923877
-0.20838546585243495
1.4439176185886589
-0.3666390729905095
0.016324813488977796
1.172133369304898
-0.26048645446327456
-0.23187463237829625
## 从如上两个遍历的结果分析,series类是可遍历的数据,那么它的索引应该是这个类的其他某发个属性。
swaplevel()方法可以交换内外层索引顺序。
print(ser_obj.swaplevel())
0 a 0.304068
1 a -1.109702
2 a -0.070409
0 b -1.344512
1 b 1.013383
2 b -0.208385
0 c 1.443918
1 c -0.366639
2 c 0.016325
0 d 1.172133
1 d -0.260486
2 d -0.231875
dtype: float64
利用pandas进行统计描述
## 先构建一个随机矩阵
# 1. 构建一个随机数据,利用np.random.rand()
# 2. 利用pandas.DataFrame添加索引,生成对应的数据
# 3. 可利用lambda表达式+applymap()方法进行数据整理
## 让代码失去可读性……
df = pd.DataFrame(np.random.rand(3,3), columns=list('abc'), index=list('ABC')).applymap(lambda x: '%.2f'%x).astype(float)
几个关键的方法
- applymap():该方法即对dataframe类中每一个元素做一个函数映射,该函数就是我们要传入的参数。(这里我们传入的是lambda表达式,它可以快速构建简易的函数。)
- lambda表达式,构建简易函数的方法。但注意它的返回值是一个迭代对象,不可直接展示。如下模块可以该函数进行简单演示
- 代码杂糅,如上本人是一行写完的,首先,这样写并不会影响运行速度,甚至如果调用了生成式等写***比普通的循环还要快,但是这样写会极度影响可读性,在特殊情况下,比如我们非常不希望别人看懂我们的代码的情况下,可以选择10行,20行,甚至30行杂糅,这样杂糅起来分解会非常的麻烦。
test_func = lambda x:x+1
test_list = [ i for i in range(2,10,2)]
print(test_list)
map_list = map(test_func,test_list)
print(map_list)
print(list(map_list))
## lambda表达式在统计中会非常常用,与正则表达式同等重要。
[2, 4, 6, 8]
<map object at 0x00000235C2BACE80>
[3, 5, 7, 9]
我们知道常用的统计函数有,max,min,sum,mean之类的。pandas同样提供了这些方法。接下来让我们回到数据。
df
| a | b | c | |
|---|---|---|---|
| A | 0.06 | 0.05 | 0.05 |
| B | 0.81 | 0.90 | 0.89 |
| C | 0.54 | 0.23 | 0.53 |
# 这是四种最基本的统计运算,同时很多运算也是基于此计算。
print(df['a'].sum())
print(df['a'].mean())
print(df['a'].max())
print(df['a'].min())
1.4100000000000001
0.47000000000000003
0.81
0.06
这些函数经过封装后,就包含了一些必要的参数。
# 默认情况。
print(df.sum())
# 加上参数:axis=1。
print(df.sum(axis=1))
# 默认情况取出每一个column数值的max。
print(df.idxmax())
# 加上参数
print(df.idxmax(axis=1))
a 1.41
b 1.18
c 1.47
dtype: float64
A 0.16
B 2.60
C 1.30
dtype: float64
a B
b B
c B
dtype: object
A a
B b
C a
dtype: object
而事实上,axis也不是唯一的参数,对于特殊的数据nan,也有针对与它的方法。
df = pd.DataFrame(np.random.rand(3,3), columns=list('abc'), index=list('ABC')).applymap(lambda x: '%.2f'%x).astype(float)
df['a']['A'] = np.NAN
print(df)
a b c
A NaN 0.01 0.80
B 0.03 0.47 0.88
C 0.88 0.44 0.63
## 在nan存在的情况下。计算某些值会受到阻塞,比如。
print(df['a'].mean())
## 这里注意,虽然mean中是没有填任何东西的,但是实际上对于我们可以使用numpy测试一下。
try:
a = np.array([np.NAN, 1, 2])
print(a.mean())
print(a.sum())
except Exception as e:
print(e)
## 可以看到输出的是nan,这是因为nan与任何数相加都得nan。那么为什么df中就没有出错呢。是因为里面有一个默认的参数为skip=True表示忽略NAN值。
## 如果取消它结果就会。如下
0.455
nan
nan
print(df['a'].mean(skipna=False))
## ok过。
nan
## describe方法
df.describe()
## 一般情况下我们需要加一个,否则describe只会描述数值列,字符串等,会忽略掉。
df.describe(include='all')
| a | b | c | |
|---|---|---|---|
| count | 2.000000 | 3.000000 | 3.000000 |
| mean | 0.455000 | 0.306667 | 0.770000 |
| std | 0.601041 | 0.257358 | 0.127671 |
| min | 0.030000 | 0.010000 | 0.630000 |
| 25% | 0.242500 | 0.225000 | 0.715000 |
| 50% | 0.455000 | 0.440000 | 0.800000 |
| 75% | 0.667500 | 0.455000 | 0.840000 |
| max | 0.880000 | 0.470000 | 0.880000 |
其他常用方法
# 输出非nan的数量
print(df.count())
print(df.count(axis=1))
a 2
b 3
c 3
dtype: int64
A 2
B 3
C 3
dtype: int64
# 获取最大最小值索引,针对与series类数据。
print(df['a'].argmax())
print(df['a'].argmin())
2
1
# 获取最大最小值索引,针对与dataframe类数据
print(df.idxmax())
print(df.idxmin())
a C
b B
c B
dtype: object
a B
b A
c C
dtype: object
# 算术中位数
print(df.median())
a 0.455
b 0.440
c 0.800
dtype: float64
pandas的文件操作
- 如基于numpy的文件操作一样,对于dataframe独特的结构来说,pandas也提供了独特的读取文件以及写入文件方式。
- 我们只需要记住几种常用的读取方式
- read_csv()
- read_excel()
- read_html()
- read_json()
- read_sql()
# 上面的方法,因常用才需要说,csv和excel文件根本不用多说,常用于数据分析,数据处理。
# html以及json文件在web开发爬虫中也需要用到。
# sql必知必会,但是一般对于pandas来说,这个方法不太常用。
# 读取csv文件,直接调用read_csv的方法。
data = pd.read_csv('student_info.csv')
# 这里获取到文件直接就是我们需要的dataframe,当然,通常情况下可能在读取文件时,会报错,此时我们需要调整参数,核心的几个参数:
"""
1. encoding='':pd.read_csv('student_info.csv', encoding='utf-8')指定以utf-8的编码方式读取。
2. engine='python':可以解决路径中含有中文的问题。
3. usecols=[]:读取指定列数。
"""
"\n1. encoding='':pd.read_csv('student_info.csv', encoding='utf-8')指定以utf-8的编码方式读取。\n2. engine='python':可以解决路径中含有中文的问题。\n3. usecols=[]:读取指定列数。\n"
## 写入csv文件在dataframe中有其方法:to_csv
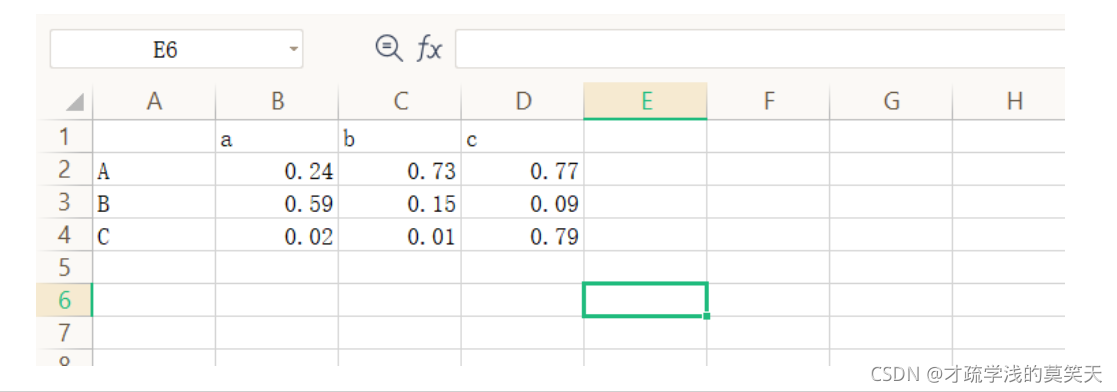
df = pd.DataFrame(np.random.rand(3,3), columns=list('abc'), index=list('ABC')).applymap(lambda x: '%.2f'%x).astype(float)
print(df)
a b c
A 0.24 0.73 0.77
B 0.59 0.15 0.09
C 0.02 0.01 0.79
## 就需要一句代码即可。这看上去确实要比基本的python操作方便很多。
df.to_csv('write_csv_1.csv')
## 或者你可以选择牺牲可读性。效果相同。
pd.DataFrame(np.random.rand(3,3), columns=list('abc'), index=list('ABC')).applymap(lambda x: '%.2f'%x).astype(float).to_csv('write_csv_2.csv')
当然事实上to_csv是有很多可选参数的。
- file_path:也就是写入文件的路径了。
- sep:值数据的分隔符,分割符要放到下一个代码块中单独说一下。如下。这里默认为','
- columns:指定保存的列,我们可以指定写入列,而非全部列。
- header:是否需要列名。默认为True
- index:是否保留行索引。默认为True
- na_rep:指定字符代替nan。默认为空字符
- mode:方式,默认为w,可指定为a,即文件的操作参数,写入,与追加。
说到这个sep,我们就必须知道csv文件是什么,在上一篇博客中我提到过,csv文件就是纯文本文件,那么利用记事本将csv文件打开,如下:

可以看到这里的逗号','其实就是数据分隔符的意思,它将数据分为条条框框成一个表格。如果没有我们将它的分隔符设置为其他。那么整体数据就会发生变化。 对于pandas读取csv文件来说,默认为','这是一般情况下认定的一个标准格式,如果转来转去,那得有多麻烦。
数据库交互
# 数据库作为就业的必知必会,基础内容很多人就算没有很会,也多少知道一点。这里直接讲方法了。
# 导入必要的模块
# panda负责处理数据
import pandas as pd
# create_engine负责对数据库进行连接
from sqlalchemy import create_engine
# 在此之前,必须要先创建对应的数据库。
# 测试连接
try:
engine = create_engine('mysql+pymysql://root:root@localhost:3306/db2')
except Exception as e:
print(e)
# 创建数据库语句
sql_op = """
select * from test_table;
"""
# 上一步没有报错信息说明连接成功。
# 这里对于pandas.read_csv是可以加入数据库语句的,这提供了很大的操作性。
df = pd.read_sql(sql_op,engine)
print(df)
Empty DataFrame
Columns: [id, name]
Index: []
## 如上所示,我们可以获取到数据,这里没有是因为我这里仅仅是创建了一个表。。。它确实没有数据,不过我们可以写入呀。
df = pd.DataFrame({'id':[1,2,3,4],'name':[34,56,78,90]})
print(df)
try:
df.to_sql('df',engine=engine, index=False)
except Exception as e:
print(e)
# 这里是报错了,显然,只是我将它的报错信息打印出来了,try和except是抛出异常语句,这种语句在任何一种高级语言都非常重要,属于基本功,其实就是
# 先try,如果报错,将采取什么措施,最后还有一个finally,只是我一般不咋用,finally表示最终做什么操作,整体格式如下:
"""
try:
step_1_1
except Exception as e:
step_1_2
finally:
step_2
"""
id name
0 1 34
1 2 56
2 3 78
3 4 90
to_sql() got an unexpected keyword argument 'engine'
'\ntry:\n step_1_1\nexcept Exception as e:\n step_1_2\nfinally:\n step_2\n'
## 接下来排错,修改bug。根据错误信息提示,该方法没有这个关键字,那么这时候要考虑几点。
# 1. 方法更新确实没有了这个参数有了其他参数替代。
# 2. 格式写错了。
# 3. 参数拼错了。
df.to_sql('df_1',engine, index=False)
# 这里显然,哈哈哈,格式写错了,笑死了。加了个engine=
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p6gYRE4R-1637411323180)(attachment:%E5%9B%BE%E7%89%87.png)]](https://img-blog.csdnimg.cn/2b829c29bbf3440ea1878055864695a7.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5omN55aP5a2m5rWF55qE6I6r56yR5aSp,size_17,color_FFFFFF,t_70,g_se,x_16)

 京公网安备 11010502036488号
京公网安备 11010502036488号