

目录
1. 缓存淘汰算法
1.1. FIFO
先进先出:最先进入的缓存被最先淘汰掉,这个基本不会有人用来做缓存
1.2. LRU
最近最少未使用:每次访问就把这个元素放到队列头部,队列满了淘汰队列尾的元素,也就是淘汰最长时间没有被访问的。
缺点也是很明显的,某一时刻大量数据的到来容易把热点数据挤出缓存,而这些数据却是只访问了一次的,今后不会再访问了的或者访问频率极低的
1.3. LFU
最不经常使用:也就是淘汰一定时期内被访问次数最少的页,这个和LRU区别是这个讲究的是一定时期,一定时期中的次数也就是频率最低的被淘汰。
这个能避免LRU的缺点,因为是根据频率淘汰,不会出现大量进进来的挤压掉老的,如果在数据的访问的模式不随时间变化时候,LFU将会提供绝佳的命中率,但是如果访问模式随着时间而变化(即缓存元素随着时间增大访问次数越小),新进来的被快速淘汰,因为刚刚进来的频率最低,之前老缓存的频率太高。并且它需要额外空间维护频率这个属性,如果建立一个HashMap维护这个属性,当数据量大的情况下,那么这个HashMap也会十分大。
2. 几种缓存的实现
2.1. 原生Java
我们先看一下Java如何实现一个LRU,如果不考虑自己手撸,那么使用LinkedHashMap即可实现,这个类的构造函数有个初始化标志物,可以生成FIFO的队列和LRU的队列

内部实现如上图所示,就是简单的在HashMap的链式法增加新的引用形成一个链表,即是一个HashMap又是一个链表,这样输出即有序,也可以根据访问来动态调整顺序。达到FIFO或者LRU的特点
可以明显看出这个存在的问题,线程不安全,需要额外加锁,功能结构单一,没有过期时间容易存在内存泄露
2.2. Guava
因为LinkedHashMap存在的问题,所以大神们在此基础上造出了Guava
既然HashMap线程不安全,那么就使用CurrentHashMap(类似不完全是),为了实现过期那么就给数据加上时间戳标志,为了实现写后过期,读后过期,这两种配置,就使用了多条队列分别代表读和写
ps:因为Guava存在很多的配置,例如引用回收之类的,暂时不关注这些,这些也是通过引用队列来完成的
Guava demo
Cache<Integer, String> guavaCache = CacheBuilder
.newBuilder()
.expireAfterWrite(3, TimeUnit.HOURS) //写入后三小时失效
.initialCapacity(50) //初始化容量50
.maximumSize(500) //最大容量
.concurrencyLevel(16).build(); //16个segment,分段锁16 expireAfterWrite对应的还有一个expireAfterAccess这是访问后多少失效,expireAfterAccess(3,TimeUnit.HOURS)如果这样就代表,距离最后一次访问后3小时刷新,每次新访问则刷新一次
为了实现上述的配置所产生的功能,其内部结构如下图所示,简单所示
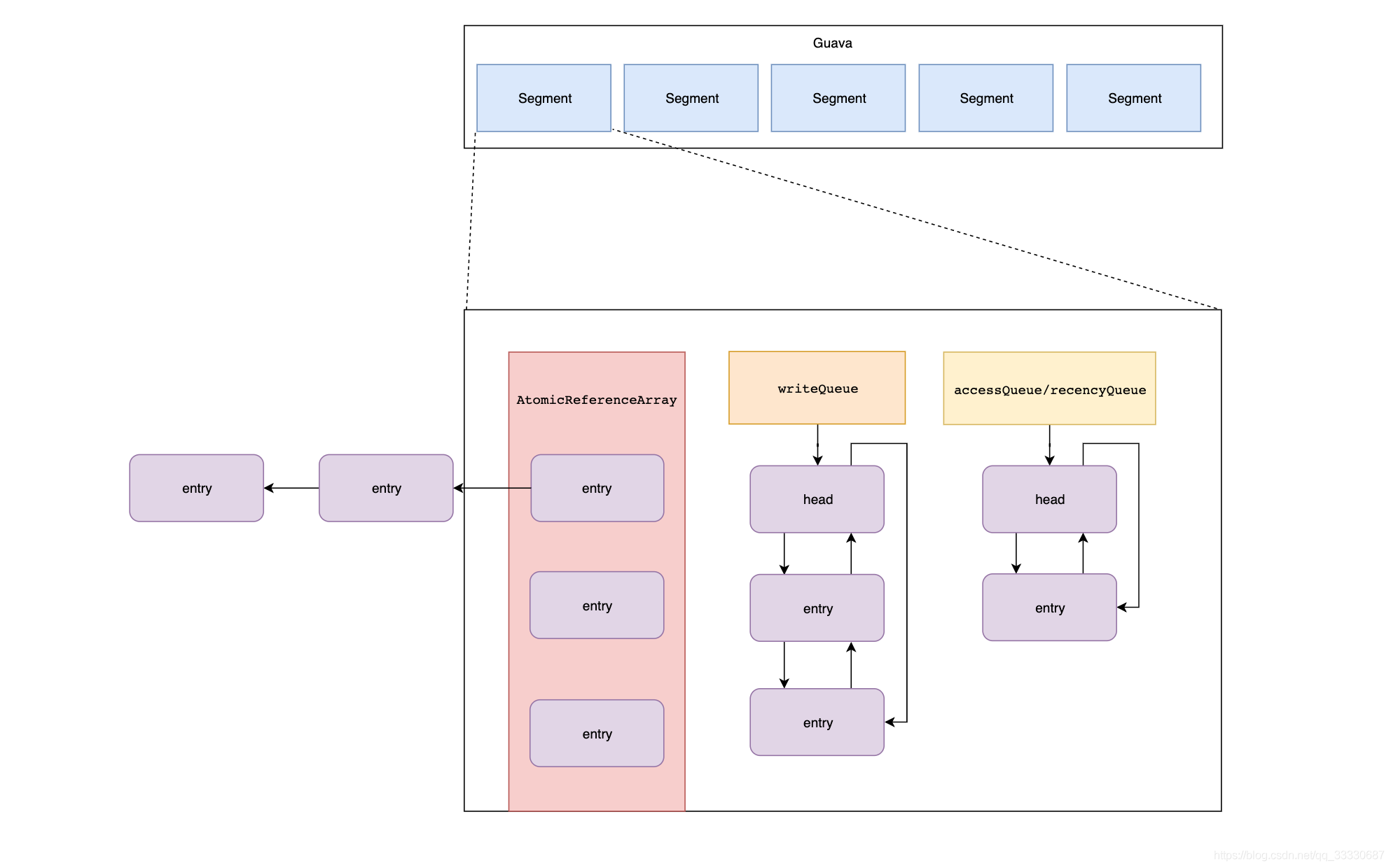
解释一下上面这个图
- AtomicReferenceArray中的node和writeQueue中的node是同一个对象,put时候,先放入atomicReferenceArray中然后再放入writeQueue和accessQueue中
- accessQueue和RecencyQueue区别,前者get方法使用,后者getIfPresent使用,在写操作时候会被清空转入accessQueue队列中
- 每个node中会保存当前的时间,作为失效时间的判断
那么当元素过期怎么清除呢?
Guava cache没有专门写一个定时器去清理,因为这样会造成线程之间的竞争消耗,它采取是一种惰性删除的策略,定时回收周期性地在写操作中执行,偶尔在读操作中执行。
写方法


读方法


2.3. Caffeine
Caffeine是Spring 5默认支持的Cache,可见Spring对它的看重,那么Spring为什么喜新厌旧的抛弃Guava而追求Caffeine呢?
缓存的淘汰策略是为了预测哪些数据在短期内最可能被再次用到,从而提升缓存的命中率。LRU由于实现简单、高效的运行时表现以及在常规的使用场景下有不错的命中率,或许是目前最佳的实现途径。但 LRU 通过历史数据来预测未来是局限的,它会认为最后到来的数据是最可能被再次访问的,从而给与它最高的优先级。这样就意味着淘汰真正热点数据,为了解决这个问题业界运用一些数据结构上的改进巧妙的解决这个问题。
举个例子
- Mysql的缓存池,内部实现是一个LRU,但是其内部有个中间点,指向倒数3/8,一半是old区,另一半是young区,新数据插入是直接插入young区,这样就保护了真正的老数据不会被冲刷掉。
- 多级队列的形式
LFU结合频率这一属性给予更好的预测缓存数据是否在未来被使用。
但是传统LFU有其局限性:
- LFU实现需要维护大而复杂的元数据(频次统计数据等)
- 大多数实际工作负载中,访问频率随着时间的推移而发生根本变化,而传统LFU无法周期衰减频率
传统LFU的实现通过外接一个HashMap统计频率,但是HashMap存在Hash冲突,这会导致频率统计的不准确。
为了解决这些问题,Caffeine提出一种新的算法W-TinyLFU,它可以解决频率统计不准确以及访问频率衰减问题。这个方法让我们从空间、效率、以及适配矩阵的长宽引起的哈希碰撞的错误率上做权衡。
传统Hash存在Hash冲突的问题,使用LFU算法时候记录频率的话一旦发生hash冲突可能造成频率的统计错误。

W-TinyLFU算法使用一种Count-Min Sketch解决维护空间大的问题,类似布隆过滤器,降低冲突可能性,原理是多次hash分散开来,取最小值作为频率,一次Hash冲突的几率是1%的话,4次Hash的几率就是1%的4次方,大大降低的冲突可能性。

在Caffeine中为了实现Count-Min Sketch它在其中村政府,存放四个算法

其中randomSeed是一个随机数,sampleSize=开始设置的缓存最大树*10;table= 最大缓存数最接近的2的次方数(100的话是128,50是64);tableMask = table.length-1;size=0
在向缓存put数据的时候会调用

这个AddTask是一个Runnable,其中run方法会调用increment方法
increment
public void increment(@Nonnull E e) {
if (isNotInitialized()) {
return;
}
int hash = spread(e.hashCode());
//hash&3必定小于4,再<<2 得到是0,4,8,12
int start = (hash & 3) << 2;
// 这下面4行得到是table的索引,即long数组的索引
int index0 = indexOf(hash, 0);
int index1 = indexOf(hash, 1);
int index2 = indexOf(hash, 2);
int index3 = indexOf(hash, 3);
boolean added = incrementAt(index0, start);
added |= incrementAt(index1, start + 1);
added |= incrementAt(index2, start + 2);
added |= incrementAt(index3, start + 3);
//这里衰减频率的条件是size=容量的10倍,这个size是只有每次added最少成功一次才行。发生衰减的过程是4次全部大于15
if (added && (++size == sampleSize)) {
reset(); //这段代码意思是频率/2,衰减一半,个人猜测频率最高设置为15的目的是为了衰减效果明显,如果没有最大频率,衰减也不会很明显
}
}
//Increments the specified counter by 1 if it is not already at the maximum value (15).
boolean incrementAt(int i, int j) {
//因为j = start+x;那么再次<<2 所得即[0,16,32,48],[4,20,36,52],[8,24,40,56],[12,28,44,60],这些区间占用4个bit,例如0-4,4-8,8-12,12-16...56-60,60-64
int offset = j << 2;
//然后根据offset得到mask,mask取值也是一个范围[1],这里为了方便start使用一个值0,那么一个缓存,start = +1,+2,+3,就是0,1,2,3
long mask = (0xfL << offset);
//这个if主要是判断是不是大于了15
if ((table[i] & mask) != mask) {
//每次加数也是个范围的值[2],注意这里会在long分配的范围+1
table[i] += (1L << offset);
return true;
}
return false;
}
[1]:
15 0000000000000000000000000000000000000000000000001111 A
240 0000000000000000000000000000000000000000000011110000 B
3840 0000000000000000000000000000000000000000111100000000 C
61440 0000000000000000000000000000000000001111000000000000 D
[2]:
1 0000000000000000000000000000000000000000000000001 a
16 0000000000000000000000000000000000000000000010000 b
256 0000000000000000000000000000000000000000100000000 c
4096 0000000000000000000000000000000000001000000000000 d
假设,每次加数都是1,那么table[i]15次后到了15,然后&mark=mark 这个时候mark=15 那么return false;
A和a后面的0是一样多的,那么根据相同的hash算法将会落在相同的区间上,也就是说a只会和a相加,b只会和b相加,根据二进制的加法,15次后将会是1111(对应位置上),这个时候判断&mask结果是否相等即可 上面只写了4个,全部的话是会把这个long64位都占用
看图会比较容易得出直观的感觉,使用不同算法的得到hash必定落在规定的区间中。

从图上以及上面分析可以看出一个long可以存放4个不同key频率 ,这样可以再次分散Hash冲突
有趣的事情是table数组的长度是改变的。每次改变都会清空原先的值。


这里会根据缓存中实际存在的数量去动态的调整,节约内存。
然后我们来看看读方法怎么增加频率
这里涉及到了线程池异步操作,调用堆栈不好打印,所以手动写一下轨迹
cache.getAllPresent->afterRead->scheduleDrainBuffers->executor().execute(drainBuffersTask) 这里进入线程池 Runnable是PerformCleanupTask
但是这有个点注意一下,这里的task传递是null

那么是怎么达到这个increment方法的呢?继续追踪perforcleanup方法,会到达到这里,task是在writeBuffer提取出来的,

那么在什么地方offer进去的呢?这个方法是在put时候会放入一个task,而put时候会执行一次task.run

最后会执行到increment方法中

至此我们梳理清晰了put/get时候Caffeine对于频率的维护,那么对于一个缓存来说,更加重要的是淘汰策略。下面就继续看一下Caffeine中的淘汰策略
在Caffeine淘汰一共有三种配置基于大小,基于时间,基于引用。
我们主要关注大小,时间两个
说这个之前关注一下Guaua是怎么淘汰元素的,它是在put方法和get方法中顺带执行,官方解锁是为了降低开辟线程定时清除的线程之间冲突,而Caffeine是在put/get方法主体完成后丢到了线程池中做了个异步处理
这里的队列的数据结构是RingBuffer,一种环形无锁队列,威名显赫。

Caffeine认为读比写多,它为读每个开辟一个线程池,而写却公用一个线程池,左边是读,右边是写
这块代码我没有跟进,但是我跟踪上面put/get方法时候确实看到做成task丢进线程池


接下来我们先关注一下cache的数据结构
caffeine和guava不同,caffeine根据配置的不同产生的cache是不同的,它有非常,非常,非常多不同的cache对象。。。
what?你问有多少?

看其他博主blog上说作者是运用了Java Poet进行代码的生成,有兴趣可以自己了解下
根据Guava的用法,推测如果使用Caffeine的话,常用配置是什么
Cache<Integer, String> cache = Caffeine
.newBuilder()
.expireAfterWrite(3, TimeUnit.HOURS)
.expireAfterAccess(3,TimeUnit.HOURS)
.initialCapacity(100)
.maximumSize(100)
.build(); 这个配置对应起来的是SSMSAW这个cache

看上去贼复杂。。但是我们只关注对我们有用的部分,简化它
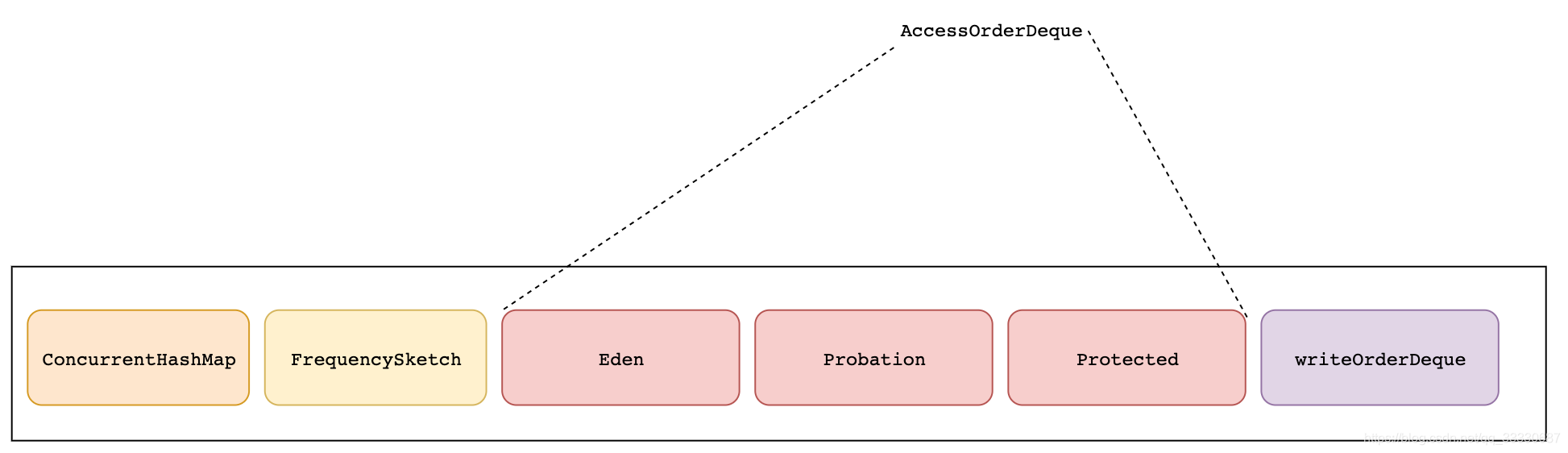
- 其中Caffeine实际存在缓存的地方是concurrentHashMap
- 红色的eden。probation,protected是accessorderDeque,是读顺序的,这三个全集=concurrentHashMap,对应的过期是读过期
- writeOrderDeque保存是写顺序。对应写过期


eden = size*1%
probation = size-eden
protected = size-eden * 80%
为了防止短期流量激增的风险。生成一个eden区域,它的目的就是用来存放短期突发访问记录。存放主要元素的Segmented LRU(SLRU)是一种LRU的改进,主要把在一个时间窗口内命中至少2次的记录和命中1次的单独存放,这样就可以把短期内较频繁的缓存元素区分开来
对于长期保留的数据,W-TinyLFU使用了分段LRU策略。起初,一个数据项存储被存储在试用段(probation)中,在后续被访问到时,它会被提升到保护段(protected)中。保护段满后,有的数据会被淘汰回试用段,这也可能级联的触发试用段的淘汰。这套机制确保了访问间隔小的热数据被保存下来,而被重复访问少的冷数据则被回收。
在Caffeine中有两种缓存,一中无界,一种有界,只有有界时候才存在缓存淘汰策略,无界不存在淘汰也没有界限

有界缓存提供三个配置
- expireAfterWrite:代表着写了之后多久过期。
- expireAfterAccess: 代表着最后一次访问了之后多久过期。
- expireAfter:在expireAfter中需要自己实现Expiry接口,这个接口支持create,update,以及access了之后多久过期。注意这个API和前面两个API是互斥的。这里和前面两个API不同的是,需要你告诉缓存框架,他应该在具体的某个时间过期,也就是通过前面的重写create,update,以及access的方法,获取具体的过期时间。
关注前两个,后面这个Caffeine提供的扩展点而已
清除的方法在scheduleDrainBuffers()中,而这个方法在put/get方法执行过程中均会调用,跟进会进入一个executor().execute(drainBuffersTask);丢进了线程池
跟进这个Task的Run方法中会到这里

关注最下面两个方法expireEntries和evictEntries,前者是过期entries,后者是淘汰entries。区别在于,前者因为时间,后者因为缓存容量
下面首先分析下过期清除
@GuardedBy("evictionLock")
void expireEntries() {
long now = expirationTicker().read();
expireAfterAccessEntries(now);
expireAfterWriteEntries(now);
expireVariableEntries(now);
}
void expireAfterAccessEntries(long now) {
if (!expiresAfterAccess()) {
return;
}
//三个队列都要删除已变过期的
expireAfterAccessEntries(accessOrderEdenDeque(), now);
if (evicts()) {
expireAfterAccessEntries(accessOrderProbationDeque(), now);
expireAfterAccessEntries(accessOrderProtectedDeque(), now);
}
}
void expireAfterAccessEntries(AccessOrderDeque<Node<K, V>> accessOrderDeque, long now) {
long duration = expiresAfterAccessNanos();
//死循环
for (;;) {
Node<K, V> node = accessOrderDeque.peekFirst();
//判断是否过滤,因为是LRU的,后面肯定比前面新
if ((node == null) || ((now - node.getAccessTime()) < duration)) {
return;
}
evictEntry(node, RemovalCause.EXPIRED, now);
}
}
boolean evictEntry(Node<K, V> node, RemovalCause cause, long now) {
K key = node.getKey();
@SuppressWarnings("unchecked")
V[] value = (V[]) new Object[1];
boolean[] removed = new boolean[1];
boolean[] resurrect = new boolean[1];
RemovalCause[] actualCause = new RemovalCause[1];
//这里是唯一一次逃避淘汰机会,如果配置了更新的话
data.computeIfPresent(node.getKeyReference(), (k, n) -> {
if (n != node) {
return n;
}
synchronized (n) {
value[0] = n.getValue();
actualCause[0] = (key == null) || (value[0] == null) ? RemovalCause.COLLECTED : cause;
if (actualCause[0] == RemovalCause.EXPIRED) {
boolean expired = false;
if (expiresAfterAccess()) {
expired |= ((now - n.getAccessTime()) >= expiresAfterAccessNanos());
}
if (expiresAfterWrite()) {
expired |= ((now - n.getWriteTime()) >= expiresAfterWriteNanos());
}
if (expiresVariable()) {
expired |= (n.getVariableTime() <= now);
}
if (!expired) {
resurrect[0] = true;
return n;
}
} else if (actualCause[0] == RemovalCause.SIZE) {
int weight = node.getWeight();
if (weight == 0) {
resurrect[0] = true;
return n;
}
}
writer.delete(key, value[0], actualCause[0]);
makeDead(n);
}
removed[0] = true;
return null;
});
// The entry is no longer eligible for eviction
if (resurrect[0]) {
return false;
}
//这里是三个读队列的删除
if (node.inEden() && (evicts() || expiresAfterAccess())) {
accessOrderEdenDeque().remove(node);
} else if (evicts()) {
if (node.inMainProbation()) {
accessOrderProbationDeque().remove(node);
} else {
accessOrderProtectedDeque().remove(node);
}
}
//写队列的删除
if (expiresAfterWrite()) {
writeOrderDeque().remove(node);
} else if (expiresVariable()) {
timerWheel().deschedule(node);
}
if (removed[0]) {
statsCounter().recordEviction(node.getWeight());
if (hasRemovalListener()) {
// Notify the listener only if the entry was evicted. This must be performed as the last
// step during eviction to safe guard against the executor rejecting the notification task.
notifyRemoval(key, value[0], actualCause[0]);
}
} else {
// Eagerly decrement the size to potentially avoid an additional eviction, rather than wait
// for the removal task to do it on the next maintenance cycle.
makeDead(node);
}
return true;
} 最后再看下容量不足的淘汰evictEntries
void evictEntries() {
if (!evicts()) {
return;
}
//这个方法主要是当eden区域达到最大后从eden区域排除元素进入Probation区域
int candidates = evictFromEden();
evictFromMain(candidates);
}
//这个方法是淘汰具体的node
void evictFromMain(int candidates) {
int victimQueue = PROBATION;
//这里会选择出victim和candidcate进行pk
Node<K, V> victim = accessOrderProbationDeque().peekFirst();
Node<K, V> candidate = accessOrderProbationDeque().peekLast();
//循环淘汰,只要不符合规则,为了得到合格的受害者和候选人,会查询访问前驱和访问后继
while (weightedSize() > maximum()) {
// Stop trying to evict candidates and always prefer the victim
if (candidates == 0) {
candidate = null;
}
// Try evicting from the protected and eden queues
if ((candidate == null) && (victim == null)) {
if (victimQueue == PROBATION) {
victim = accessOrderProtectedDeque().peekFirst();
victimQueue = PROTECTED;
continue;
} else if (victimQueue == PROTECTED) {
victim = accessOrderEdenDeque().peekFirst();
victimQueue = EDEN;
continue;
}
// The pending operations will adjust the size to reflect the correct weight
break;
}
// Skip over entries with zero weight
if ((victim != null) && (victim.getPolicyWeight() == 0)) {
victim = victim.getNextInAccessOrder();
continue;
} else if ((candidate != null) && (candidate.getPolicyWeight() == 0)) {
candidate = candidate.getPreviousInAccessOrder();
candidates--;
continue;
}
// Evict immediately if only one of the entries is present
if (victim == null) {
candidates--;
Node<K, V> evict = candidate;
candidate = candidate.getPreviousInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
continue;
} else if (candidate == null) {
Node<K, V> evict = victim;
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
continue;
}
// Evict immediately if an entry was collected
K victimKey = victim.getKey();
K candidateKey = candidate.getKey();
if (victimKey == null) {
Node<K, V> evict = victim;
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.COLLECTED, 0L);
continue;
} else if (candidateKey == null) {
candidates--;
Node<K, V> evict = candidate;
candidate = candidate.getPreviousInAccessOrder();
evictEntry(evict, RemovalCause.COLLECTED, 0L);
continue;
}
// Evict immediately if the candidate's weight exceeds the maximum
if (candidate.getPolicyWeight() > maximum()) {
candidates--;
Node<K, V> evict = candidate;
candidate = candidate.getPreviousInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
continue;
}
// Evict the entry with the lowest frequency
candidates--;
//admit是pk场所
if (admit(candidateKey, victimKey)) {
Node<K, V> evict = victim;
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
candidate = candidate.getPreviousInAccessOrder();
} else {
Node<K, V> evict = candidate;
candidate = candidate.getPreviousInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
}
}
}
//官方认为这种操作会带来更好的命中率
boolean admit(K candidateKey, K victimKey) {
int victimFreq = frequencySketch().frequency(victimKey);
int candidateFreq = frequencySketch().frequency(candidateKey);
if (candidateFreq > victimFreq) { //候选者>受害者
return true;
} else if (candidateFreq <= 5) { //候选者<=5
// The maximum frequency is 15 and halved to 7 after a reset to age the history. An attack
// exploits that a hot candidate is rejected in favor of a hot victim. The threshold of a warm
// candidate reduces the number of random acceptances to minimize the impact on the hit rate.
return false;
}
//随机
int random = ThreadLocalRandom.current().nextInt();
return ((random & 127) == 0);
} 
3. 参考资料
https://www.cnblogs.com/liujinhua306/p/9808500.html
https://blog.csdn.net/varyall/article/details/81172725
http://www.cnblogs.com/zhaoxinshanwei/p/8519717.html
https://segmentfault.com/a/1190000016091569?utm_source=tag-newest

 京公网安备 11010502036488号
京公网安备 11010502036488号