

E 题 铃兰小姐是我们的光。
写在前面
这是一道很久以前出的题,当时刚学了 fhq tree,了解到范浩强,陈立杰等人,一窥了他们的风采。闲暇时候我读了陈立杰的集训队论文,发现了平衡树维护标号,实现 比较的神奇的动态序列做法。于是我就以此为基础想出一道题。裸题是没意思的,直接给一个序列上的问题又缺乏趣味,我就想到了把问题搬到树上。
当你觉得序列题不够难的时候,把它变成树题就好了。
后面的就自然而然想到了,我可以用动态序列来维护 dfs 序,就变成了一道树上数颜色题。
这是笔者第一次把题放在一个正式的公开赛上,还是蛮开心的。一直担心自己的数据有没有出锅。不过后面写了几个做法反复验证,数据应该是正确的。虽然一开始就是奔着防 ak 去的,但真没人写出来,还没人补,还是有点小伤心的。
由于数据丢了一次,我在重新造数据的过程感觉到这道题应该有其他的做法,很像一道树上分块的题,但是比赛开始前还想不出做法,就不了了之了。异想天开,找到了突破口,终于把树上分块写法给写出来了,于是有了这篇题解。
而题解写着写着,又想到了块状链表,于是有了解法 3。
简明题意
一棵树,一开始为空,每次加入一个有颜色的节点,或者求一个节点的子树内的颜色数。强制在线。
解法1 平衡树维护动态序列
整体思路是替罪羊树维护动态的 dfs 序,然后把数颜色转换成序列区间和。在这题是转换成了子树和。
新生长一个节点时,我门在 后插入
和
,
,
,查询的时候查询 dfs 序上的
到
的区间和即可。
为了维护 dfs 序,能够支持插入和比较前后关系,我们为每个节点维护一个标记 ,需要比较两个节点在 dfs 序上的前后关系,只需要比较
的大小即可。
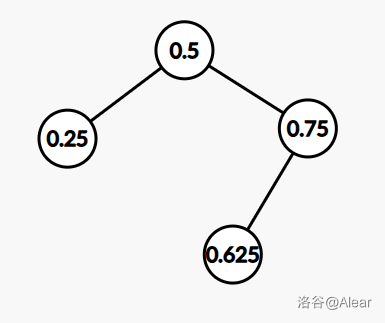
如何维护这个标记呢?我们让每个点对应一个实数区间 ,其中根节点对应实数区间
。对于每个节点
,该节点的
,左儿子对应的区间为
,右儿子对应的区间为
。由于插入节点的时候都是插入到节点
后面,我们只需根据
找到替罪羊树上的该节点,然后插入到
右儿子的位置即可。替罪羊树用重构保证了树高
的,分母的复杂度为
,因此无需担心浮点数精度问题。该做法的来源是陈立杰的 IOI 2013 集训队论文《重量平衡树和后缀平衡树在信息学奥赛中的应用》。大概是下图这种感觉:
对于维护颜色,我们将相同颜色的节点按 dfs 序排序,对每个节点维护一个权值 。只需在每个节点处
,相邻节点处的
(最近公共祖先)处
,计算一个节点的子树内颜色数就变成了求子树权值和。实现上,我们每加入一个新节点
,进行以下三种操作:节点
处
;
和同色前驱的
处
;
和同色后继的
处
;前驱和后继的
处
,因为前驱和后继不再相邻。需要操作的节点不存在(例如没有前驱)则跳过该步。这个思想类似树上链并,看成对同颜色的节点到根节点的链求一个并,也是本题的灵感来源之一。
为了实现同颜色节点排序、查找前驱后继的操作,我们可以每个颜色开一个 set 保存所有该颜色的节点,这个 set 的比较函数用替罪羊树的标号比较进行重载,这样就能找到当前插入节点相同颜色前驱和后继。替罪羊树发生重构时虽然会修改 的值,但是大小关系一直没变,保证了重载比较的正确性。最近公共祖先可以使用倍增实现。
这样处理之后,问题变成了单点修改,子树求和。前面我们使用替罪羊树维护了 dfs 序,单点修改,区间求和也可以在替罪羊树上完成。因为替罪羊树树高是 的,我们类似线段树地维护所有节点的子树和即可。查询的时候也类似线段树地求
和
之间所有节点的权值和即可。
时间复杂度 ,空间复杂度
。
解法2 树上分块
由于没有针对这个做法专门造数据和测试,这个做法相当卡常。我费了不少力气才把代码卡进 2s。
考虑分块。一种朴素的想法是,将树分成 块,每块用 bitset 把颜色存起来,每次查询的时候只需要将子树下的散点和整块统计即可。但是仅有如此不足以通过本题。主要有两个缺陷:合并各块时 bitset 消耗过大;难以确保分块数量,会被菊花图卡掉。
我们将一部分点指定为关键点,将一个关键点和以该关键点为最近关键点祖先的非关键点划分为一块,出于计算复杂度方便考虑块的大小 不仅包含块内的节点,还需要计入块内节点的子节点。我们需要找到一种关键点选取方案,满足以下三个性质:
- 任意点到根的关键点个数至多是
的。
至多为
朴素的想法是,设块大小阈值为 ,加入一个点时,如果父亲所在的块的
达到阈值则将其定为关键点,否则反之。然而这个做法只能满足性质 1,会被菊花图卡将
卡成
,因为加在当前块的一个新的关键点仍会使得
增大。
而一个应对菊花图的常见技巧能解决这个问题:三度化。具体来说,就是将图 1 变成图 2。
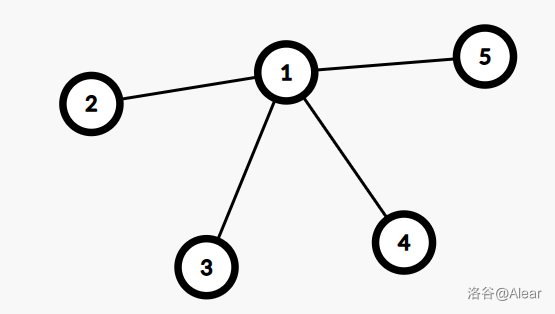
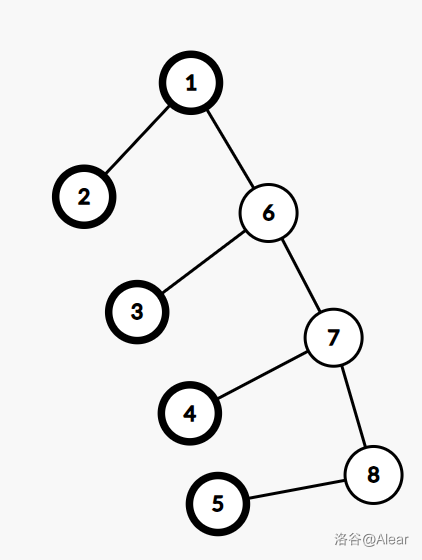
我们添加一些虚点,它们没有颜色,不会影响颜色统计和节点祖先关系,却能够将节点度数限制在 3 以内。
通过这样的转换,块内的每个节点,至多拥有两个直接儿子,限制了已经达到阈值的块的扩张,从而满足 ;同时,路径上的每一个关键点,都意味着经过了一个大小达到阈值的块,保证了点到根的路径上至多只有
个关键点。这个划分方案存在一个小问题,在针对块大小进行造数据的时候,关键点数量能够被卡到
的,(例如造出总大小为
的若干满块,然后添加
个关键点,这使得后续使用 bitset 统计会出点问题。但是因为出题人
就是我没有卡,而且可以使用一些寄巧(例如子树大小小于10时不建 bitset,当然这对常数的要求就更苛刻了)来绕过去,要卡掉也比较困难,我们作为趣味介绍接下来的做法。
有了划分方案之后,我们该如何统计信息呢?我们为每个关键点开一个 bitset,记录其子树内所有节点的颜色存在情况。每个节点用一个权值 用于记录答案,和上一个解法一样把颜色数转化为对子树内所有节点的
的和。另开一个
,当
为关键点时,
表示子树内
的和;当
为非关键点时,
。新加入一个颜色为
的节点
,
,然后找到最近的子树中已经包含颜色
的祖先
,
。如果
存在,其所在块的关键点一定包含色
,因此我们可以逐个关键点往上跳,检查 bitset 中是否包含颜色
,然后 dfs 检查块内节点的子树中是否包含颜色
。
的块大小保证了暴力查找的复杂度。卡常小技巧是,不要一次遍历整个块,而是从下往上检查,可以避免大约一半的计算量。
查询的时候只需要只需要递归求和子树的 ,遇到关键点则停止。
总时间复杂度 ,最差空间复杂度
,没被卡中的话大约是
。牛客实测运行时间是 1758 ms 到 1888 ms 之间。
使用 set 代替 bitset 后,时间 ,空间复杂度
。
有没有卡常王愿意试一试能不能卡进去。
能造出卡掉该解法的数据的,或者有避免该缺陷的更好的方法的同学,可以私信我。
解法 3 块状链表
因为是很久以前出的题,这个解法我以前出题的时候应该有想出来,还试图用 的规模去卡,结果是解法 1 也跑了八秒,遂不了了之。难怪存档文件没有数据。写题解的时候思考了其他分块做法,才想起来可以用分块链表。本题相比初版放宽了限制,就是想放分块做法通过。
整体思路和解法 1 类似,但是动态序列和标号使用分块链表而不是平衡树来维护。
分块链表是结合分块思想的链表,链表中的每一个节点为一个块,插入的时候使用暴力插入,当块大小超过阈值(通常为 )时,将当前块分裂成两个块,并更新信息。整块上统计
的和。
为了维护按 dfs 序排序的 set,我们需要为节点维护一个标号。节点 的标号类型为
pair<int, int>,第一个整数为所在块的序号(这里可以理解为块的地址,不能直接用于比较),第二个整数为节点 在块内的下标。另外维护每个块的标号,因为块的数量也是
的,暴力即可。
同样重载 set 的比较函数,以块的标号和块内偏移作为第一第二关键字。接下来的做法和解法 1 完全一样。
新生长一个节点时,我门在 后插入
和
,
,
,查询的时候查询 dfs 序上的
到
的区间和即可。
对于维护颜色,我们将相同颜色的节点按 dfs 序排序,对每个节点维护一个权值 。只需在每个节点处
,相邻节点处的
(最近公共祖先)处
,计算一个节点的子树内颜色数就变成了求子树权值和。实现上,我们每加入一个新节点
,进行以下三种操作:节点
处
;
和同色前驱的
处
;
和同色后继的
处
;前驱和后继的
处
,因为前驱和后继不再相邻。需要操作的节点不存在(例如没有前驱)则跳过该步。这个思想类似树上链并,看成对同颜色的节点到根节点的链求一个并,也是本题的灵感来源之一。
以防大家不想看长长长的平衡树题解。
时间复杂度 ,空间复杂度
。
该做法也是最容易实现的一个做法。最实用的一集。

 京公网安备 11010502036488号
京公网安备 11010502036488号