

倍增做法请见《题解:P3379 【模板】最近公共祖先(LCA)倍增》。
树剖求最近公共祖先
一棵有根树 T T T 的两个结点 u u u、 v v v 的最近公共祖先表示一个结点 x x x,满足 x x x 是 u u u、 v v v 的祖先且 x x x 的深度尽可能大。本题解讲解用重链剖分求两节点的最近公共祖先。
暴力
首先计算出结点 a a a 和 b b b 的深度 d 1 d1 d1 和 d 2 d2 d2。如果 d 1 > d 2 d1>d2 d1>d2,将 a a a 结点向上移动 d 1 − d 2 d1-d2 d1−d2 步,如果 d 1 < d 2 d1<d2 d1<d2,将 b b b 结点向上移动 d 2 − d 1 d2-d1 d2−d1 步,现在 a a a 结点和 b b b 结点在同一个深度了。下面只需要同时将 a a a、 b b b 结点向上移动,直到它们相遇(到达同一个结点)为止,相遇的结点即为 a a a、 b b b 结点的最小公共祖先。
该算法时间复杂度为 O ( n m ) O(nm) O(nm),对于多次询问的题目(比如本题)不能解决。
思想
树链剖分用于将树分割成若干条链的形式,以维护树上路径的信息。具体来说,将整棵树剖分为若干条链,使它组合成线性结构,然后用其他的数据结构维护信息,但本题目的是求最近公共祖先,不需要如此麻烦,就不展开讲述。
重链剖分将树上的任意一条路径划分成不超过 O ( log n ) O(\log n) O(logn) 条连续的链,每条链上的点深度互不相同,即是自底向上的一条链,链上所有点的最近公共祖先为链的一个端点。
为方便表示,进行以下定义,其实也是代码里要用到的数组:
- 用 f a u fa_u fau 表示点 u u u 的父亲节点。
- 用 s u s_u su 表示以点 u u u 为根的子树的节点个数。
- 用 s o n u son_u sonu 表示 u u u 的重儿子(不知道什么是重儿子没关系,下面会讲)。
- 用 d u d_u du 表示 u u u 节点的深度。
- 用 t o p u top_u topu 表示所在重链的顶部节点。
一些定义
- 重儿子:设点 v v v 是点 u u u 的儿子,若点 v v v 是点 u u u 的所有儿子中 s v s_v sv 最大的一个,则 v v v 是 u u u 的重儿子。由此易得,当一点 u u u 仅有 1 1 1 个儿子 v v v,那 v v v 就是 u u u 的重儿子。
- 轻儿子:一节点的子结点中,除了重儿子,其余都为轻儿子。
- 重链:一条由轻儿子或根节点(即不是重儿子)开头,全部由重儿子组成的链(所以一个点也算一条重链)。
举个例子,如下图:黄色的是重儿子,一个紫色圈起来的是一条重链。
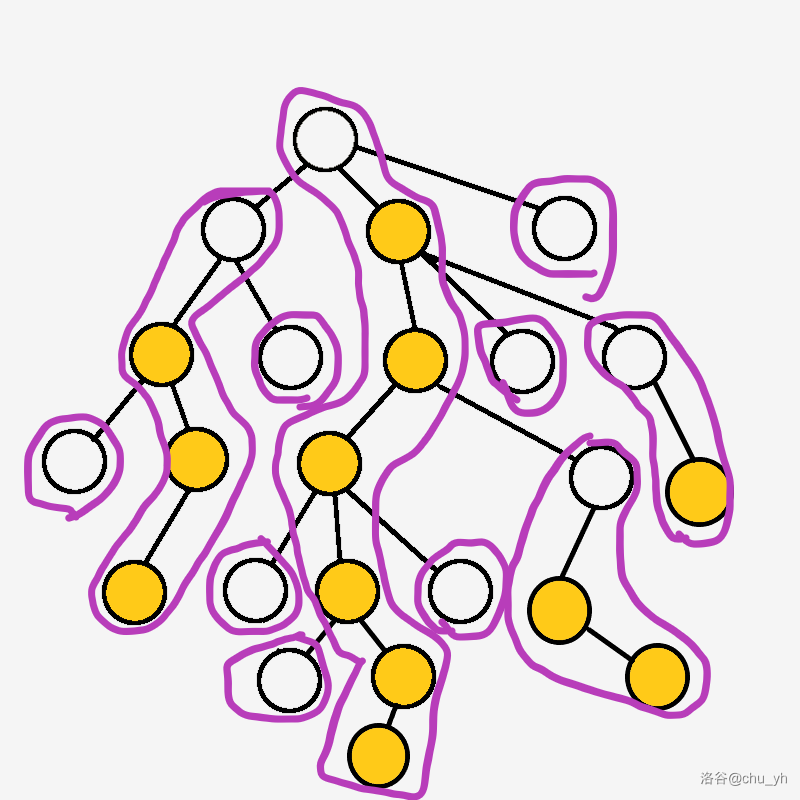
如何找最近公共祖先?
若我们要找点 a a a、 b b b 的最近公共祖先
若点 a a a、 b b b 在同一条重链上
很显然,此时深度小的点是点 a a a、 b b b 的最近公共祖先。
若点 a a a, b b b 不在同一条重链上
这时联想暴力做法,我们会惊喜地发现,只要我们预处理出 t o p top top 数组,就可以利用它直接往上跳,从而避免暴力中的一步一步龟速上爬,大大的提升效率。
有人就问了:但这样不能精确控制上调步数啊?实际上我们不需要精确控制步数,重链的定义就给予了我们极大的便利。
我们只需要不断将深度小的点跳到到重链顶端的父亲上,直至两点在同一重链上,结合图仔细观察并举个例子手模,可得知其正确性。
具体的,我们令 d a ≥ d b d_a \ge d_b da≥db,让 a a a 跳到 f a t o p a fa_{top_a} fatopa,重复此操作,直到 t o p a = t o p b top_a = top_b topa=topb。下面是代码实现:
int lca(int a,int b){
while(top[a]!=top[b]){
if(deep[top[a]]<deep[top[b]]) swap(a,b);//强制让d[a]>=d[b]
a=fa[top[a]];
}
return deep[a]<deep[b]?a:b;
}
预处理
上面的代码用到了:
- f a u fa_u fau 表示点 u u u 的父亲节点。
- d u d_u du 表示 u u u 节点的深度。
- t o p u top_u topu 表示所在重链的顶部节点。
要预处理出他们,还需定义两个数组,即上文提到过的 s o n u son_u sonu 和 s u s_u su,定义如下:
- 用 s u s_u su 表示以点 u u u 为根的子树的节点个数。
- 用 s o n u son_u sonu 表示 u u u 的重儿子。
我们采用两次 DFS 来预处理。
第一次 DFS
其中, s u s_u su、 d u d_u du 和 f a u fa_u fau 明显可以对树进行 DFS 来处理。在 DFS 的过程中,到 u u u 点时,我们会遍历 u u u 的所有子节点,此时根据重儿子的定义就能轻松地处理出 s o n u son_u sonu。
//Fa是u的父亲
//deep[u]是u点深度,即上文的d_u
//Size[u]即上文的s_u,因为要避免变量名重复
void dfs(int u,int Fa){
fa[u]=Fa,deep[u]=deep[Fa]+1,Size[u]=1;//Size初始化不要忘
for(int v:e[u]) if(v!=Fa){
dfs(v,u);
Size[u]+=Size[v];//这排一定要放在DFS处理完Size[v]后,判定重儿子之前
if(Size[v]>Size[son[u]])//找重儿子
son[u]=v;
}
}
第二次 DFS
第一次 DFS 完了后会发现最重要的 t o p top top 数组还没求,然后想办法求 t o p top top 数组。
根据重链的定义可以知:若 u u u 为轻儿子或根节点,那么 t o p u = u top_u=u topu=u,且以它开头的重链上的点 v v v 的 t o p v top_v topv 都为 u u u。
由此可以想到再进行一次 DFS,DFS 函数中传递的参数设为当前走到的节点 u u u 和为 u u u 节点所在的重链开头的点 r o o t root root。DFS 操作开始将 u u u 赋值给 t o p u top_u topu。单独 DFS 重儿子,下传的 r o o t root root 不变。在遍历所有轻儿子 v v v,下传 r o o t root root 参数为 v v v。代码实现如下:
void Dfs(int u,int root){
top[u]=root;
if(!son[u]) return ;
Dfs(son[u],root);
for(int v:e[u]) if(v!=fa[u]&&v!=son[u]) Dfs(v,v);
}
完整代码
#include<bits/stdc++.h>
using namespace std;
const int N=5e6+5;
int n,Q,s,fa[N],Size[N],deep[N],son[N],top[N];
vector<int> e[N];
void dfs(int u,int Fa){
fa[u]=Fa,deep[u]=deep[Fa]+1,Size[u]=1;
for(int v:e[u]) if(v!=Fa){
dfs(v,u);
Size[u]+=Size[v];
if(Size[v]>Size[son[u]]) son[u]=v;
}
}
void Dfs(int u,int root){
top[u]=root;
if(!son[u]) return ;
Dfs(son[u],root);
for(int v:e[u]) if(v!=fa[u]&&v!=son[u]) Dfs(v,v);
}
int lca(int a,int b){
while(top[a]!=top[b]){
if(deep[top[a]]<deep[top[b]]) swap(a,b);
a=fa[top[a]];
}
return deep[a]<deep[b]?a:b;
}
int main(){
scanf("%d%d%d",&n,&Q,&s);
for(int i=1,u,v;i<n;i++){
scanf("%d%d",&u,&v);
e[u].push_back(v),e[v].push_back(u);
}
dfs(s,0);
Dfs(s,s);
while(Q--){
int a,b;
scanf("%d%d",&a,&b);
printf("%d\n",lca(a,b));
}
return 0;
}

 京公网安备 11010502036488号
京公网安备 11010502036488号