

说一说Java的Unsafe类
最近在看Java并发包的源码,发现了神奇的Unsafe类,仔细研究了一下,在这里跟大家分享一下。
Unsafe类是在sun.misc包下,不属于Java标准。但是很多Java的基础类库,包括一些被广泛使用的高性能开发库都是基于Unsafe类开发的,比如Netty、Cassandra、Hadoop、Kafka等。Unsafe类在提升Java运行效率,增强Java语言底层操作能力方面起了很大的作用。
Unsafe类使Java拥有了像C语言的指针一样操作内存空间的能力,同时也带来了指针的问题。过度的使用Unsafe类会使得出错的几率变大,因此Java官方并不建议使用的,官方文档也几乎没有。Oracle正在计划从Java 9中去掉Unsafe类,如果真是如此影响就太大了。
通常我们最好也不要使用Unsafe类,除非有明确的目的,并且也要对它有深入的了解才行。要想使用Unsafe类需要用一些比较tricky的办法。Unsafe类使用了单例模式,需要通过一个静态方法getUnsafe()来获取。但Unsafe类做了限制,如果是普通的调用的话,它会抛出一个SecurityException异常;只有由主类加载器加载的类才能调用这个方法。其源码如下:

1 public static Unsafe getUnsafe() {
2 Class var0 = Reflection.getCallerClass();
3 if(!VM.isSystemDomainLoader(var0.getClassLoader())) {
4 throw new SecurityException("Unsafe");
5 } else {
6 return theUnsafe;
7 }
8 }
网上也有一些办法来用主类加载器加载用户代码,比如设置bootclasspath参数。但更简单方法是利用Java反射,方法如下:
1 Field f = Unsafe.class.getDeclaredField("theUnsafe");
2 f.setAccessible(true);
3 Unsafe unsafe = (Unsafe) f.get(null);
获取到Unsafe实例之后,我们就可以为所欲为了。Unsafe类提供了以下这些功能:
一、内存管理。包括分配内存、释放内存等。
该部分包括了allocateMemory(分配内存)、reallocateMemory(重新分配内存)、copyMemory(拷贝内存)、freeMemory(释放内存 )、getAddress(获取内存地址)、addressSize、pageSize、getInt(获取内存地址指向的整数)、getIntVolatile(获取内存地址指向的整数,并支持volatile语义)、putInt(将整数写入指定内存地址)、putIntVolatile(将整数写入指定内存地址,并支持volatile语义)、putOrderedInt(将整数写入指定内存地址、有序或者有延迟的方法)等方法。getXXX和putXXX包含了各种基本类型的操作。
利用copyMemory方法,我们可以实现一个通用的对象拷贝方法,无需再对每一个对象都实现clone方法,当然这通用的方法只能做到对象浅拷贝。
二、非常规的对象实例化。
allocateInstance()方法提供了另一种创建实例的途径。通常我们可以用new或者反射来实例化对象,使用allocateInstance()方法可以直接生成对象实例,且无需调用构造方法和其它初始化方法。
这在对象反序列化的时候会很有用,能够重建和设置final字段,而不需要调用构造方法。
三、操作类、对象、变量。
这部分包括了staticFieldOffset(静态域偏移)、defineClass(定义类)、defineAnonymousClass(定义匿名类)、ensureClassInitialized(确保类初始化)、objectFieldOffset(对象域偏移)等方法。
通过这些方法我们可以获取对象的指针,通过对指针进行偏移,我们不仅可以直接修改指针指向的数据(即使它们是私有的),甚至可以找到JVM已经认定为垃圾、可以进行回收的对象。
四、数组操作。
这部分包括了arrayBaseOffset(获取数组第一个元素的偏移地址)、arrayIndexScale(获取数组中元素的增量地址)等方法。arrayBaseOffset与arrayIndexScale配合起来使用,就可以定位数组中每个元素在内存中的位置。
由于Java的数组最大值为Integer.MAX_VALUE,使用Unsafe类的内存分配方法可以实现超大数组。实际上这样的数据就可以认为是C数组,因此需要注意在合适的时间释放内存。
五、多线程同步。包括锁机制、CAS操作等。
这部分包括了monitorEnter、tryMonitorEnter、monitorExit、compareAndSwapInt、compareAndSwap等方法。
其中monitorEnter、tryMonitorEnter、monitorExit已经被标记为deprecated,不建议使用。
Unsafe类的CAS操作可能是用的最多的,它为Java的锁机制提供了一种新的解决办法,比如AtomicInteger等类都是通过该方法来实现的。compareAndSwap方法是原子的,可以避免繁重的锁机制,提高代码效率。这是一种乐观锁,通常认为在大部分情况下不出现竞态条件,如果操作失败,会不断重试直到成功。
六、挂起与恢复。
这部分包括了park、unpark等方法。
将一个线程进行挂起是通过park方法实现的,调用 park后,线程将一直阻塞直到超时或者中断等条件出现。unpark可以终止一个挂起的线程,使其恢复正常。整个并发框架中对线程的挂起操作被封装在 LockSupport类中,LockSupport类中有各种版本pack方法,但最终都调用了Unsafe.park()方法。
七、内存屏障。
这部分包括了loadFence、storeFence、fullFence等方法。这是在Java 8新引入的,用于定义内存屏障,避免代码重排序。
loadFence() 表示该方法之前的所有load操作在内存屏障之前完成。同理storeFence()表示该方法之前的所有store操作在内存屏障之前完成。fullFence()表示该方法之前的所有load、store操作在内存屏障之前完成。
Unsafe类是啥?
Java最初被设计为一种安全的受控环境。尽管如此,Java HotSpot还是包含了一个“后门”,提供了一些可以直接操控内存和线程的低层次操作。这个后门类——sun.misc.Unsafe——被JDK广泛用于自己的包中,如java.nio和java.util.concurrent。但是丝毫不建议在生产环境中使用这个后门。因为这个API十分不安全、不轻便、而且不稳定。这个不安全的类提供了一个观察HotSpot JVM内部结构并且可以对其进行修改。有时它可以被用来在不适用C++调试的情况下学习虚拟机内部结构,有时也可以被拿来做性能监控和开发工具。
为什么叫Unsafe?
Java官方不推荐使用Unsafe类,因为官方认为,这个类别人很难正确使用,非正确使用会给JVM带来致命错误。而且未来Java可能封闭丢弃这个类。
如何使用Unsafe?
1. 获取Unsafe实例:
通读Unsafe源码,Unsafe提供了一个私有的静态实例,并且通过检查classloader是否为null来避免java程序直接使用unsafe:
//Unsafe源码
private static final Unsafe theUnsafe;
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if(var0.getClassLoader() != null) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们可以通过如下代码反射获取Unsafe静态类:
/**
* 获取Unsafe
*/
Field f = null;
Unsafe unsafe = null;
try {
f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
unsafe = (Unsafe) f.get(null);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2. 通过Unsafe分配使用堆外内存:
C++中有malloc,realloc和free方法来操作内存。在Unsafe类中对应为:
//分配var1字节大小的内存,返回起始地址偏移量
public native long allocateMemory(long var1);
//重新给var1起始地址的内存分配长度为var3字节大小的内存,返回新的内存起始地址偏移量
public native long reallocateMemory(long var1, long var3);
//释放起始地址为var1的内存
public native void freeMemory(long var1); - 1
- 2
- 3
- 4
- 5
- 6
分配内存方法还有重分配内存方法都是分配的堆外内存,返回的是一个long类型的地址偏移量。这个偏移量在你的Java程序中每块内存都是唯一的。
举例:
/**
* 在堆外分配一个byte
*/
long allocatedAddress = unsafe.allocateMemory(1L);
unsafe.putByte(allocatedAddress, (byte) 100);
byte shortValue = unsafe.getByte(allocatedAddress);
System.out.println(new StringBuilder().append("Address:").append(allocatedAddress).append(" Value:").append(shortValue));
/**
* 重新分配一个long
*/
allocatedAddress = unsafe.reallocateMemory(allocatedAddress, 8L);
unsafe.putLong(allocatedAddress, 1024L);
long longValue = unsafe.getLong(allocatedAddress);
System.out.println(new StringBuilder().append("Address:").append(allocatedAddress).append(" Value:").append(longValue));
/**
* Free掉,这个数据可能脏掉
*/
unsafe.freeMemory(allocatedAddress);
longValue = unsafe.getLong(allocatedAddress);
System.out.println(new StringBuilder().append("Address:").append(allocatedAddress).append(" Value:").append(longValue)); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出:
Address:46490464 Value:100
Address:46490480 Value:1024
Address:46490480 Value:22 - 1
- 2
- 3
3. 操作类对象
我们可以通过Unsafe类来操作修改某一field。原理是首先获取对象的基址(对象在内存的偏移量起始地址)。之后获取某个filed在这个对象对应的类中的偏移地址,两者相加修改。
/**
* 获取类的某个对象的某个field偏移地址
*/
try {
f = SampleClass.class.getDeclaredField("i");
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
long iFiledAddressShift = unsafe.objectFieldOffset(f);
SampleClass sampleClass = new SampleClass();
//获取对象的偏移地址,需要将目标对象设为辅助数组的第一个元素(也是唯一的元素)。由于这是一个复杂类型元素(不是基本数据类型),它的地址存储在数组的第一个元素。然后,获取辅助数组的基本偏移量。数组的基本偏移量是指数组对象的起始地址与数组第一个元素之间的偏移量。
Object helperArray[] = new Object[1];
helperArray[0] = sampleClass;
long baseOffset = unsafe.arrayBaseOffset(Object[].class);
long addressOfSampleClass = unsafe.getLong(helperArray, baseOffset);
int i = unsafe.getInt(addressOfSampleClass + iFiledAddressShift);
System.out.println(new StringBuilder().append(" Field I Address:").append(addressOfSampleClass).append("+").append(iFiledAddressShift).append(" Value:").append(i)); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
Field I Address:3610777760+24 Value:5 - 1
4. 线程挂起和恢复
将一个线程进行挂起是通过park方法实现的,调用 park后,线程将一直阻塞直到超时或者中断等条件出现。unpark可以终止一个挂起的线程,使其恢复正常。整个并发框架中对线程的挂起操作被封装在 LockSupport类中,LockSupport类中有各种版本pack方法,但最终都调用了Unsafe.park()方法。
public class LockSupport {
public static void unpark(Thread thread) {
if (thread != null)
unsafe.unpark(thread);
}
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
unsafe.park(false, 0L);
setBlocker(t, null);
}
public static void parkNanos(Object blocker, long nanos) {
if (nanos > 0) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
unsafe.park(false, nanos);
setBlocker(t, null);
}
}
public static void parkUntil(Object blocker, long deadline) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
unsafe.park(true, deadline);
setBlocker(t, null);
}
public static void park() {
unsafe.park(false, 0L);
}
public static void parkNanos(long nanos) {
if (nanos > 0)
unsafe.park(false, nanos);
}
public static void parkUntil(long deadline) {
unsafe.park(true, deadline);
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
5. CAS操作
/**
* 比较obj的offset处内存位置中的值和期望的值,如果相同则更新。此更新是不可中断的。
*
* @param obj 需要更新的对象
* @param offset obj中整型field的偏移量
* @param expect 希望field中存在的值
* @param update 如果期望值expect与field的当前值相同,设置filed的值为这个新值
* @return 如果field的值被更改返回true
*/
public native boolean compareAndSwapInt(Object obj, long offset, int expect, int update); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6. Clone
如何实现浅克隆?在clone(){…}方法中调用super.clone(),对吗?这里存在的问题是首先你必须继续Cloneable接口,并且在所有你需要做浅克隆的对象中实现clone()方法,对于一个懒懒的程序员来说,这个工作量太大了。
我不推荐上面的做法而是直接使用Unsafe,我们可以仅使用几行代码就实现浅克隆,并且它可以像某些工具类一样用于任意类的克隆。
首先,我们需要一个计算Object大小的工具类:
class ObjectInfo {
/**
* Field name
*/
public final String name;
/**
* Field type name
*/
public final String type;
/**
* Field data formatted as string
*/
public final String contents;
/**
* Field offset from the start of parent object
*/
public final int offset;
/**
* Memory occupied by this field
*/
public final int length;
/**
* Offset of the first cell in the array
*/
public final int arrayBase;
/**
* Size of a cell in the array
*/
public final int arrayElementSize;
/**
* Memory occupied by underlying array (shallow), if this is array type
*/
public final int arraySize;
/**
* This object fields
*/
public final List<ObjectInfo> children;
public ObjectInfo(String name, String type, String contents, int offset, int length, int arraySize,
int arrayBase, int arrayElementSize) {
this.name = name;
this.type = type;
this.contents = contents;
this.offset = offset;
this.length = length;
this.arraySize = arraySize;
this.arrayBase = arrayBase;
this.arrayElementSize = arrayElementSize;
children = new ArrayList<ObjectInfo>(1);
}
public void addChild(final ObjectInfo info) {
if (info != null)
children.add(info);
}
/**
* Get the full amount of memory occupied by a given object. This value may be slightly less than
* an actual value because we don't worry about memory alignment - possible padding after the last object field.
* <p/>
* The result is equal to the last field offset + last field length + all array sizes + all child objects deep sizes
*
* @return Deep object size
*/
public long getDeepSize() {
//return length + arraySize + getUnderlyingSize( arraySize != 0 );
return addPaddingSize(arraySize + getUnderlyingSize(arraySize != 0));
}
long size = 0;
private long getUnderlyingSize(final boolean isArray) {
//long size = 0;
for (final ObjectInfo child : children)
size += child.arraySize + child.getUnderlyingSize(child.arraySize != 0);
if (!isArray && !children.isEmpty()) {
int tempSize = children.get(children.size() - 1).offset + children.get(children.size() - 1).length;
size += addPaddingSize(tempSize);
}
return size;
}
private static final class OffsetComparator implements Comparator<ObjectInfo> {
@Override
public int compare(final ObjectInfo o1, final ObjectInfo o2) {
return o1.offset - o2.offset; //safe because offsets are small non-negative numbers
}
}
//sort all children by their offset
public void sort() {
Collections.sort(children, new OffsetComparator());
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder();
toStringHelper(sb, 0);
return sb.toString();
}
private void toStringHelper(final StringBuilder sb, final int depth) {
depth(sb, depth).append("name=").append(name).append(", type=").append(type)
.append(", contents=").append(contents).append(", offset=").append(offset)
.append(", length=").append(length);
if (arraySize > 0) {
sb.append(", arrayBase=").append(arrayBase);
sb.append(", arrayElemSize=").append(arrayElementSize);
sb.append(", arraySize=").append(arraySize);
}
for (final ObjectInfo child : children) {
sb.append('\n');
child.toStringHelper(sb, depth + 1);
}
}
private StringBuilder depth(final StringBuilder sb, final int depth) {
for (int i = 0; i < depth; ++i)
sb.append("\t");
return sb;
}
private long addPaddingSize(long size) {
if (size % 8 != 0) {
return (size / 8 + 1) * 8;
}
return size;
}
}
class ClassIntrospector {
private static final Unsafe unsafe;
/**
* Size of any Object reference
*/
private static final int objectRefSize;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
objectRefSize = unsafe.arrayIndexScale(Object[].class);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* Sizes of all primitive values
*/
private static final Map<Class, Integer> primitiveSizes;
static {
primitiveSizes = new HashMap<Class, Integer>(10);
primitiveSizes.put(byte.class, 1);
primitiveSizes.put(char.class, 2);
primitiveSizes.put(int.class, 4);
primitiveSizes.put(long.class, 8);
primitiveSizes.put(float.class, 4);
primitiveSizes.put(double.class, 8);
primitiveSizes.put(boolean.class, 1);
}
/**
* Get object information for any Java object. Do not pass primitives to
* this method because they will boxed and the information you will get will
* be related to a boxed version of your value.
*
* @param obj Object to introspect
* @return Object info
* @throws IllegalAccessException
*/
public ObjectInfo introspect(final Object obj)
throws IllegalAccessException {
try {
return introspect(obj, null);
} finally { // clean visited cache before returning in order to make
// this object reusable
m_visited.clear();
}
}
// we need to keep track of already visited objects in order to support
// cycles in the object graphs
private IdentityHashMap<Object, Boolean> m_visited = new IdentityHashMap<Object, Boolean>(
100);
private ObjectInfo introspect(final Object obj, final Field fld)
throws IllegalAccessException {
// use Field type only if the field contains null. In this case we will
// at least know what's expected to be
// stored in this field. Otherwise, if a field has interface type, we
// won't see what's really stored in it.
// Besides, we should be careful about primitives, because they are
// passed as boxed values in this method
// (first arg is object) - for them we should still rely on the field
// type.
boolean isPrimitive = fld != null && fld.getType().isPrimitive();
boolean isRecursive = false; // will be set to true if we have already
// seen this object
if (!isPrimitive) {
if (m_visited.containsKey(obj))
isRecursive = true;
m_visited.put(obj, true);
}
final Class type = (fld == null || (obj != null && !isPrimitive)) ? obj
.getClass() : fld.getType();
int arraySize = 0;
int baseOffset = 0;
int indexScale = 0;
if (type.isArray() && obj != null) {
baseOffset = unsafe.arrayBaseOffset(type);
indexScale = unsafe.arrayIndexScale(type);
arraySize = baseOffset + indexScale * Array.getLength(obj);
}
final ObjectInfo root;
if (fld == null) {
root = new ObjectInfo("", type.getCanonicalName(), getContents(obj,
type), 0, getShallowSize(type), arraySize, baseOffset,
indexScale);
} else {
final int offset = (int) unsafe.objectFieldOffset(fld);
root = new ObjectInfo(fld.getName(), type.getCanonicalName(),
getContents(obj, type), offset, getShallowSize(type),
arraySize, baseOffset, indexScale);
}
if (!isRecursive && obj != null) {
if (isObjectArray(type)) {
// introspect object arrays
final Object[] ar = (Object[]) obj;
for (final Object item : ar)
if (item != null)
root.addChild(introspect(item, null));
} else {
for (final Field field : getAllFields(type)) {
if ((field.getModifiers() & Modifier.STATIC) != 0) {
continue;
}
field.setAccessible(true);
root.addChild(introspect(field.get(obj), field));
}
}
}
root.sort(); // sort by offset
return root;
}
// get all fields for this class, including all superclasses fields
private static List<Field> getAllFields(final Class type) {
if (type.isPrimitive())
return Collections.emptyList();
Class cur = type;
final List<Field> res = new ArrayList<Field>(10);
while (true) {
Collections.addAll(res, cur.getDeclaredFields());
if (cur == Object.class)
break;
cur = cur.getSuperclass();
}
return res;
}
// check if it is an array of objects. I suspect there must be a more
// API-friendly way to make this check.
private static boolean isObjectArray(final Class type) {
if (!type.isArray())
return false;
if (type == byte[].class || type == boolean[].class
|| type == char[].class || type == short[].class
|| type == int[].class || type == long[].class
|| type == float[].class || type == double[].class)
return false;
return true;
}
// advanced toString logic
private static String getContents(final Object val, final Class type) {
if (val == null)
return "null";
if (type.isArray()) {
if (type == byte[].class)
return Arrays.toString((byte[]) val);
else if (type == boolean[].class)
return Arrays.toString((boolean[]) val);
else if (type == char[].class)
return Arrays.toString((char[]) val);
else if (type == short[].class)
return Arrays.toString((short[]) val);
else if (type == int[].class)
return Arrays.toString((int[]) val);
else if (type == long[].class)
return Arrays.toString((long[]) val);
else if (type == float[].class)
return Arrays.toString((float[]) val);
else if (type == double[].class)
return Arrays.toString((double[]) val);
else
return Arrays.toString((Object[]) val);
}
return val.toString();
}
// obtain a shallow size of a field of given class (primitive or object
// reference size)
private static int getShallowSize(final Class type) {
if (type.isPrimitive()) {
final Integer res = primitiveSizes.get(type);
return res != null ? res : 0;
} else
return objectRefSize;
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
我们通过这两个类计算一个Object的大小,通过Unsafe的 public native void copyMemory(Object var1, long var2, Object var4, long var5, long var7)方法来拷贝:
两个工具方法:
private static Object helperArray[] = new Object[1];
/**
* 获取对象起始位置偏移量
* @param unsafe
* @param object
* @return
*/
public static long getObjectAddress(Unsafe unsafe, Object object){
helperArray[0] = object;
long baseOffset = unsafe.arrayBaseOffset(Object[].class);
return unsafe.getLong(helperArray, baseOffset);
}
private final static ClassIntrospector ci = new ClassIntrospector();
/**
* 获取Object的大小
* @param object
* @return
*/
public static long getObjectSize(Object object){
ObjectInfo res = null;
try {
res = ci.introspect(object);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return res.getDeepSize();
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
测试:
SampleClass sampleClass = new SampleClass();
sampleClass.setI(999);
sampleClass.setL(999999999L);
SampleClass sampleClassCopy = new SampleClass();
long copyAddress = getObjectAddress(unsafe,sampleClassCopy);
unsafe.copyMemory(sampleClass, 0, null,copyAddress, getObjectSize(sampleClass));
i = unsafe.getInt(copyAddress + iFiledAddressShift);
System.out.println(i);
System.out.println(sampleClassCopy.getL()); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
999
999999999
LockSupport详解
长久以来对线程阻塞与唤醒经常我们会使用object的wait和notify,除了这种方式,java并发包还提供了另外一种方式对线程进行挂起和恢复,它就是并发包子包locks提供的LockSupport。
LockSupport提供了park和unpark进行线程的挂起和恢复操作,来看一个简单挂起和恢复的简单例子:
由于编辑格式限制,直接贴代码有人反映会显得很杂乱,之后有关代码将直接放图片,上例子中描述了一个场景,周末了某男兴奋的去打游戏了,于是被游戏阻塞了(park),其他的都不干了,这个时候女朋友打来电话,别打游戏了,陪她逛街,把男朋友从游戏中唤醒(unpark)。LockSupport使用方式和wait/notify很类似,LockSupport使用更加灵活,unpark可以先于park进行调用,因为这个特点,我们可以不用担心挂起和恢复时序问题,就如流打开了必须关闭这中类似问题,给我们带来很多编程麻烦。
LockSupport底层是有Unsafe提供的两个基本同步语句,这个在关于Unsafe介绍中已经做了分析,LockSupport是对这两个函数的进一步封装,除了例子中方法,它还提供了其他几个功能。
以上为LockSupport属性,Unsafe这个很好理解,整个LockSupport的实现都是基于Unsafe的两个方法,SEED、PROBE、SECONDARY都是Thread类中为了对象上图中三个字段的相对地址偏移量,功能主要用于ThreadLocalRandom类进行随机数生成,它比Random性能要高的多,可阅读该篇文章了解详细(https://my.oschina.net/adan1/blog/159371),虽然LockSupport定义这三个字段但是基本没有使用,可能之后JDK会有所变化吧。这里parkBlockerOffset字段,解释起来就是挂起线程对象的偏移地址,对应的是Thread类的parkBlocker。
这个字段可以理解为专门为LockSupport而设计的,它被用来记录线程是被谁堵塞的,当程序出现问题时候,通过线程监控分析工具可以找出问题所在。注释说该对象被LockSupport的getBlocker和setBlocker来获取和设置,且都是通过地址偏移量方式获取和修改的。由于这个变量LockSupport提供了park(Object parkblocker)方法。
代码很好理解获取当前线程,通过偏移量的方式设置parkBlocker的值,将调取unsafe.park把线程挂起,线程被恢复后,修改blocker为null。
那我们可以把文章开篇例子修改的更加应景一些,如下:
定义一个blocker者名字叫“游戏”,某男被游戏堵塞park(a),我们通过jstack pid获取当前线程相关信息(jstack用于打印出给定的Java进程ID或core file或远程调试服务的Java堆栈信息):
可以看到当前线程状态是WAITING,确实通过unsafe.park挂起的,blocker为一个字符串类型的id为0x…的。通过mat工具可以知道这个id对应得对象即为变量名为game的string对象。若不设置blocker,则是空的,如下:
只是将线程进行了挂起,无blocker。
那么LockSupport的park/unpark与wait/notify有啥区别呢?首先wait/notify对线程所起的作用和park/unpark是一样的,如下为使用wait阻塞线程的线程状态:
也是waiting,只是方式是调取Object.wait。说明产生的效果是一样,那来继续分析一下两者实现机制。
它俩面向操作的对象不同,通过上述分析,我们知道LockSupport阻塞和唤醒线程直接操作的就是线程,所以从语义上讲,它更符合常理,或者叫更符合语义。而Object的wait/notify它并不是直接对线程操作,它是被动的方法,它需要一个object来进行线程的挂起或唤醒。
park/unpark使用起来会更加的灵活、方便。在调用对象的wait之前当前线程必须先获得该对象的监视器(synchronized),被唤醒之后需要重新获取到监视器才能继续执行。而LockSupport则不会,如例子中所示,它可以随意进行park或者unpark。
两则虽然都能更改线程状态为WAITING,但由于实现的机制不同,所以不会产生交集,就是park挂起线程,notify/notifyall是无法进行唤醒的。我们来看个例子。就好比你在打游戏,一个陌生大妈让你逛街去,你应该不会去吧(特殊需求的除外)。如下例子(代码这样写也是绝了,仅仅举例子):
使用notify还有一个问题就是,有时候为了保险起见大多数都用notifyall,notify只能唤醒一个线程,假如有两个被阻塞的话,另外一个就悲剧了。
除此之外,park也可以响应中断异常,关于中断异常详讲也需要一大篇文章,这里不做详细分析,来看一下park响应中断过程。
对开篇代码改造一下,还是某男打游戏,且深深陷入其中(park),突然屎意甚浓,于是被其中断(interrupt),然后某男去拉屎去了。最终线程退出了运行,在这里你会发现,park并不会抛出InterruptedException异常。那问题来,不抛出异常,那和正常的unpark有何区别?不能拉屎中断和女朋友召唤效果一样吧。这里就要依赖线程的interruptedstatus,如果线程被中断而退出阻塞该状态会被修改为true。如下可获取到当前interrupted status。
总结起来LockSupport有以下不同和特点:
-
其实现机制和wait/notify有所不同,面向的是线程。
-
不需要依赖监视器
-
与wait/notify没有交集
-
使用起来更加灵活方便
LockSupport 源码解析
LockSupport 和 CAS 是Java并发包中很多并发工具控制机制的基础,它们底层其实都是依赖Unsafe实现。
LockSupport是用来创建锁和其他同步类的基本线程阻塞原语。LockSupport 提供park()和unpark()方法实现阻塞线程和解除线程阻塞,LockSupport和每个使用它的线程都与一个许可(permit)关联。permit相当于1,0的开关,默认是0,调用一次unpark就加1变成1,调用一次park会消费permit, 也就是将1变成0,同时park立即返回。再次调用park会变成block(因为permit为0了,会阻塞在这里,直到permit变为1), 这时调用unpark会把permit置为1。每个线程都有一个相关的permit, permit最多只有一个,重复调用unpark也不会积累。
park()和unpark()不会有 “Thread.suspend和Thread.resume所可能引发的死锁” 问题,由于许可的存在,调用 park 的线程和另一个试图将其 unpark 的线程之间的竞争将保持活性。
如果调用线程被中断,则park方法会返回。同时park也拥有可以设置超时时间的版本。
需要特别注意的一点:park 方法还可以在其他任何时间“毫无理由”地返回,因此通常必须在重新检查返回条件的循环里调用此方法。从这个意义上说,park 是“忙碌等待”的一种优化,它不会浪费这么多的时间进行自旋,但是必须将它与 unpark 配对使用才更高效。
三种形式的 park 还各自支持一个 blocker 对象参数。此对象在线程受阻塞时被记录,以允许监视工具和诊断工具确定线程受阻塞的原因。(这样的工具可以使用方法 getBlocker(java.lang.Thread) 访问 blocker。)建议最好使用这些形式,而不是不带此参数的原始形式。在锁实现中提供的作为 blocker 的普通参数是 this。
看下线程dump的结果来理解blocker的作用。
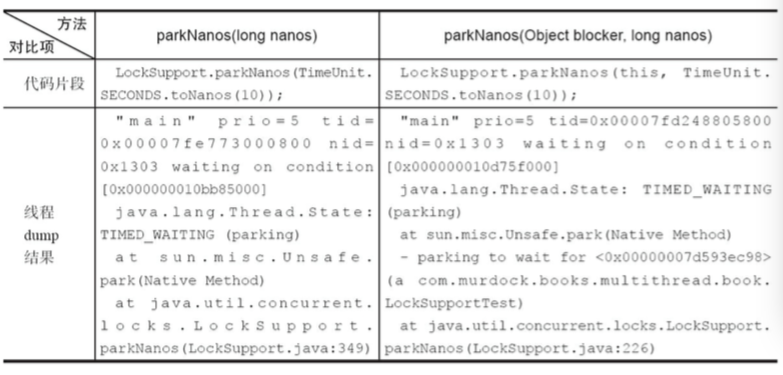
从线程dump结果可以看出:
有blocker的可以传递给开发人员更多的现场信息,可以查看到当前线程的阻塞对象,方便定位问题。所以java6新增加带blocker入参的系列park方法,替代原有的park方法。
看一个Java docs中的示例用法:一个先进先出非重入锁类的框架
class FIFOMutex {
private final AtomicBoolean locked = new AtomicBoolean(false);
private final Queue<Thread> waiters
= new ConcurrentLinkedQueue<Thread>();
public void lock() {
boolean wasInterrupted = false;
Thread current = Thread.currentThread();
waiters.add(current);
// Block while not first in queue or cannot acquire lock
while (waiters.peek() != current ||
!locked.compareAndSet(false, true)) {
LockSupport.park(this);
if (Thread.interrupted()) // ignore interrupts while waiting
wasInterrupted = true;
}
waiters.remove();
if (wasInterrupted) // reassert interrupt status on exit
current.interrupt();
}
public void unlock() {
locked.set(false);
LockSupport.unpark(waiters.peek());
}
}} LockSupport 源码解读
-
LockSupport中主要的两个成员变量:
// Hotspot implementation via intrinsics API
private static final sun.misc.Unsafe UNSAFE;
private static final long parkBlockerOffset; unsafe:全名sun.misc.Unsafe可以直接操控内存,被JDK广泛用于自己的包中,如java.nio和java.util.concurrent。但是不建议在生产环境中使用这个类。因为这个API十分不安全、不轻便、而且不稳定。
LockSupport的方法底层都是调用Unsafe的方法实现。
再来看parkBlockerOffset:
parkBlocker就是第一部分说到的用于记录线程被谁阻塞的,用于线程监控和分析工具来定位原因的,可以通过LockSupport的getBlocker获取到阻塞的对象。
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> tk = Thread.class;
parkBlockerOffset = UNSAFE.objectFieldOffset
(tk.getDeclaredField("parkBlocker"));
} catch (Exception ex) { throw new Error(ex); }
} 从这个静态语句块可以看的出来,先是通过反射机制获取Thread类的parkBlocker字段对象。然后通过sun.misc.Unsafe对象的objectFieldOffset方法获取到parkBlocker在内存里的偏移量,parkBlockerOffset的值就是这么来的.
JVM的实现可以自由选择如何实现Java对象的“布局”,也就是在内存里Java对象的各个部分放在哪里,包括对象的实例字段和一些元数据之类。 sun.misc.Unsafe里关于对象字段访问的方法把对象布局抽象出来,它提供了objectFieldOffset()方法用于获取某个字段相对 Java对象的“起始地址”的偏移量,也提供了getInt、getLong、getObject之类的方法可以使用前面获取的偏移量来访问某个Java 对象的某个字段。
为什么要用偏移量来获取对象?干吗不要直接写个get,set方法。多简单?
仔细想想就能明白,这个parkBlocker就是在线程处于阻塞的情况下才会被赋值。线程都已经阻塞了,如果不通过这种内存的方法,而是直接调用线程内的方法,线程是不会回应调用的。
2.LockSupport的方法:
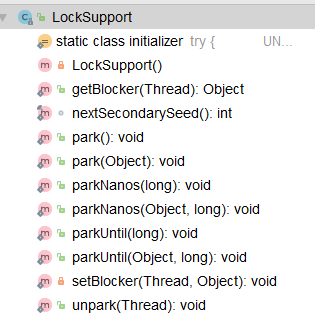
可以看到,LockSupport中主要是park和unpark方法以及设置和读取parkBlocker方法。
private static void setBlocker(Thread t, Object arg) { // Even though volatile, hotspot doesn't need a write barrier here. UNSAFE.putObject(t, parkBlockerOffset, arg); }对给定线程t的parkBlocker赋值。
public static Object getBlocker(Thread t) {
if (t == null)
throw new NullPointerException();
return UNSAFE.getObjectVolatile(t, parkBlockerOffset);
}
从线程t中获取它的parkBlocker对象,即返回的是阻塞线程t的Blocker对象。
接下来主查两类方法,一类是阻塞park方法,一类是解除阻塞unpark方法
阻塞线程
-
park()
public static void park() { UNSAFE.park(false, 0L); }调用native方法阻塞当前线程。
-
parkNanos(long nanos)
public static void parkNanos(long nanos) { if (nanos > 0) UNSAFE.park(false, nanos); }阻塞当前线程,最长不超过nanos纳秒,返回条件在park()的基础上增加了超时返回。
-
parkUntil(long deadline)
public static void parkUntil(long deadline) { UNSAFE.park(true, deadline); }阻塞当前线程,知道deadline时间(deadline - 毫秒数)。
JDK1.6引入这三个方法对应的拥有Blocker版本。
-
park(Object blocker)
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false, 0L);
setBlocker(t, null);
} 1) 记录当前线程等待的对象(阻塞对象);
2) 阻塞当前线程;
3) 当前线程等待对象置为null。
-
parkNanos(Object blocker, long nanos)
public static void parkNanos(Object blocker, long nanos) {
if (nanos > 0) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false, nanos);
setBlocker(t, null);
}
} 阻塞当前线程,最长等待时间不超过nanos毫秒,同样,在阻塞当前线程的时候做了记录当前线程等待的对象操作。
-
parkUntil(Object blocker, long deadline)
public static void parkUntil(Object blocker, long deadline) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(true, deadline);
setBlocker(t, null);
} 阻塞当前线程直到deadline时间,相同的,也做了阻塞前记录当前线程等待对象的操作。
唤醒线程
-
unpark(Thread thread)
public static void unpark(Thread thread) {
if (thread != null)
UNSAFE.unpark(thread);
} 唤醒处于阻塞状态的线程Thread。
微信公众号【程序员江湖】
作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于2018 年秋招拿到 BAT 头条、网易、滴滴等 8 个大厂 offer
个人擅长领域 :自学编程、技术校园招聘、软件工程考研(关注公众号后回复”资料“即可领取 3T 免费技术学习资源)


 京公网安备 11010502036488号
京公网安备 11010502036488号