

前言
大家好,我是fancy呀。
在上一篇关于MySQL的文章中,我讲到了事务的特性、隔离级别和并发一致性问题。其中我们说到了数据库的四个隔离级别,并说明MVCC是实现了提交读,可重复读的重要手段。
MVCC也是MySQL数据库中一个老生常谈的话题了,但是由于它较为底层,实际的开发日常中我们并不会去直接接触它,所以真正将它弄明白的人并不多,许多面试者,提到它很多人都处于:“哦,这个东西我知道!是数据库中的一种并发措施,但是我有点忘记了它的详细内容了...”这样的状态。
所以本篇文章,就来详细讲一讲”MVCC”,带大家理清楚MVCC的内容。
话不多说,列大纲,发车!
什么是MVCC?
MVCC((Mutil-Version Concurrency Control)),全称多版本并发访问,这是一种并发环境下进行数据安全控制的方法,其本质上是一种乐观锁,用于实现提交读(READ COMMITTD)和可重复读(REPEATABLE READ)这两种隔离级别。在这里我先为大家理清楚一个概念:我们常说的MVCC是由MySQL数据库InnoDB存储引擎实现的,并非是由MySQL本身实现的,不同的存储引擎,对MVCC都有不同的实现标准。所以当你在面试官面前说:”MySQL使用了MVCC实现了xxxxxx“,面试官一下子就把你给逮住了,说明你连MySQL和InnoDB之间的关系都模糊不清😑。

那么,当你听到了“多版本”、“并发访问”这两个词,你也许就知道了,InnoDB使用MVCC来解决并发问题的方法,就是让每个不同的事务访问查询同一行数据时,每个事务修改的都是这行数据的不同版本,InnoDB只需要去记录这个数据的访问链,就可以实现一个SELECT操作的并发执行。
那么,它具体是如何实现的呢?
MVCC利用了多版本的思想,在 MVCC 中事务的所有写操作(INSERT、UPDATE、DELETE)会为数据行新增一个最新的版本快照,而读操作是去读旧版本的快照,也就是说,读操作和写操作是分离的,二者之间没有依赖、互斥关系。
核心
Undo Log
什么是Undo Log?
Undo Log是MySQL的三大日志之一,当我们对记录做了变更操作时就会产生一条Undo记录。它的作用就是保护事务在异常发生的时候或手动回滚时可以回滚到历史版本数据,能够让你读取过去某一个时间点保存的数据。通俗易懂地说,它只关心过去的数据。
本文我们不会对Undo Log的作用做太多描述,你需要重点知道的是:对于一个InnoDB存储引擎,一个聚簇索引(主键索引)的记录之中,一定会有两个隐藏字段trx_id和roll_pointer,这两个字段存储于B+树的叶子节点中,分别对应记录着两列信息:
trx_id:只要有任意一个事务对某条聚簇索引记录进行修改,该事务id就会被记录到该字段里面。
roll_pointer:当任意一个聚簇索引记录被修改,上一个版本的数据记录就会被写入Undo Log日志里面。那么这个roll_pointer就是存储了一个指针,这个指针是一个地址,指向这个聚簇索引的上一个版本的记录位置,通过这个指针就可以获得到每一个历史版本的记录。
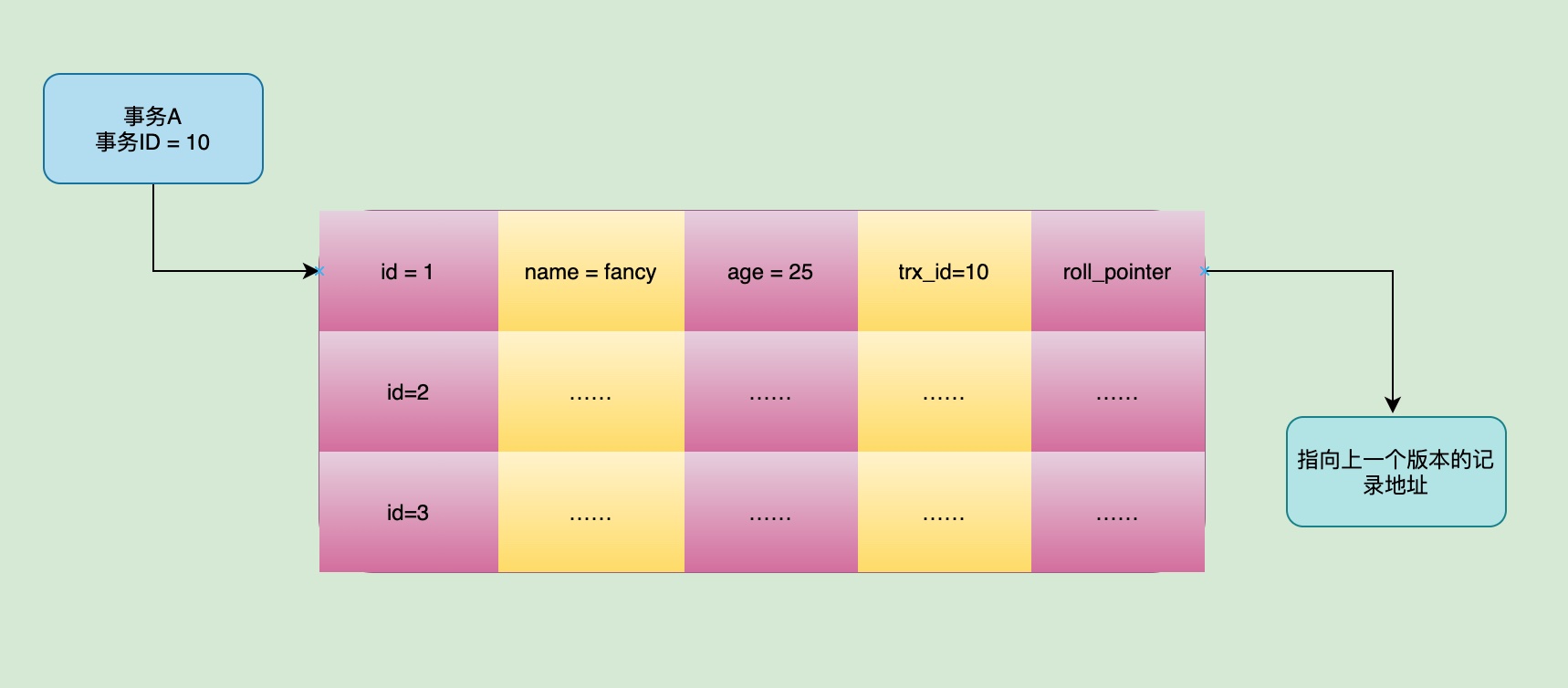
OK,假设我们现在有一张员工表employee,有主键id、name、age三个字段。使用一个事务A创建第一条主键id为1的记录,把名字修改为fancy,他的年龄为25岁。
那么,这条记录的trx_id隐藏字段就会记录此次插入记录的事务ID:
假设现在有一个事务B,事务ID为20,要对这条记录进行修改,把fancy的age从25改成了28,那么此时Undo Log会发生啥?
此时,这这条id为1的记录,trx_id就变为了20,是的。trx_id此时记录了修改这条记录的事务ID,而对应的roll_pointer指针,就指向了上次事务A的操作对应的Undo Log:
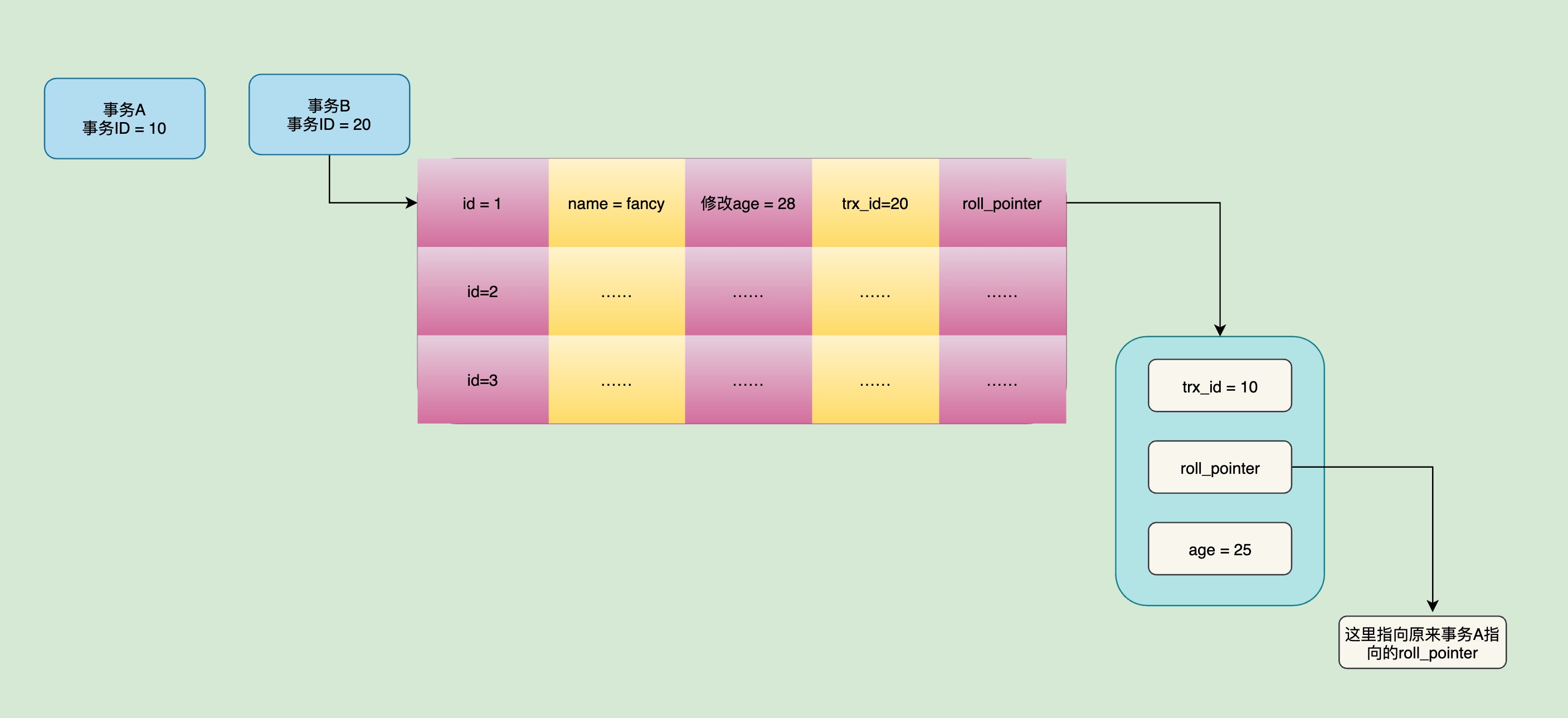
好,所以这里先总结一下:trx_id就是记录修改了每条聚簇索引的事务id;roll_pointer顾名思义就是个指针,指向每一个历史操作版本的数据存储的地址;每一次修改操作都会生成一个Undo Log版本,每个版本之间是隔离的。
如果接下去有事务C,事务D等等一直对这条记录进行修改,那么这条记录的roll_pointer指针就会一直这样递归修改下去,最终形成一个关于修改和删除操作的Undo Log版本链!
为什么我说是关于修改和删除操作的版本链,而没有查询操作的呢?因为,查询操作不会生成Undo Log版本链。
那么,InnoDB有几种版本链呢?其实只有两种:insert undo log(插入操作产生) 和update undo log(更新操作产生)。 就像我开头所说的,读操作和写操作是分离的,它们之间没有关系。写操作去生成版本链,而读操作只需要根据规则去查看对应的某一个版本,然后读取就完事了。至于是什么规则?就是我们下文要说的:Read View。
Read View
什么是Read View?
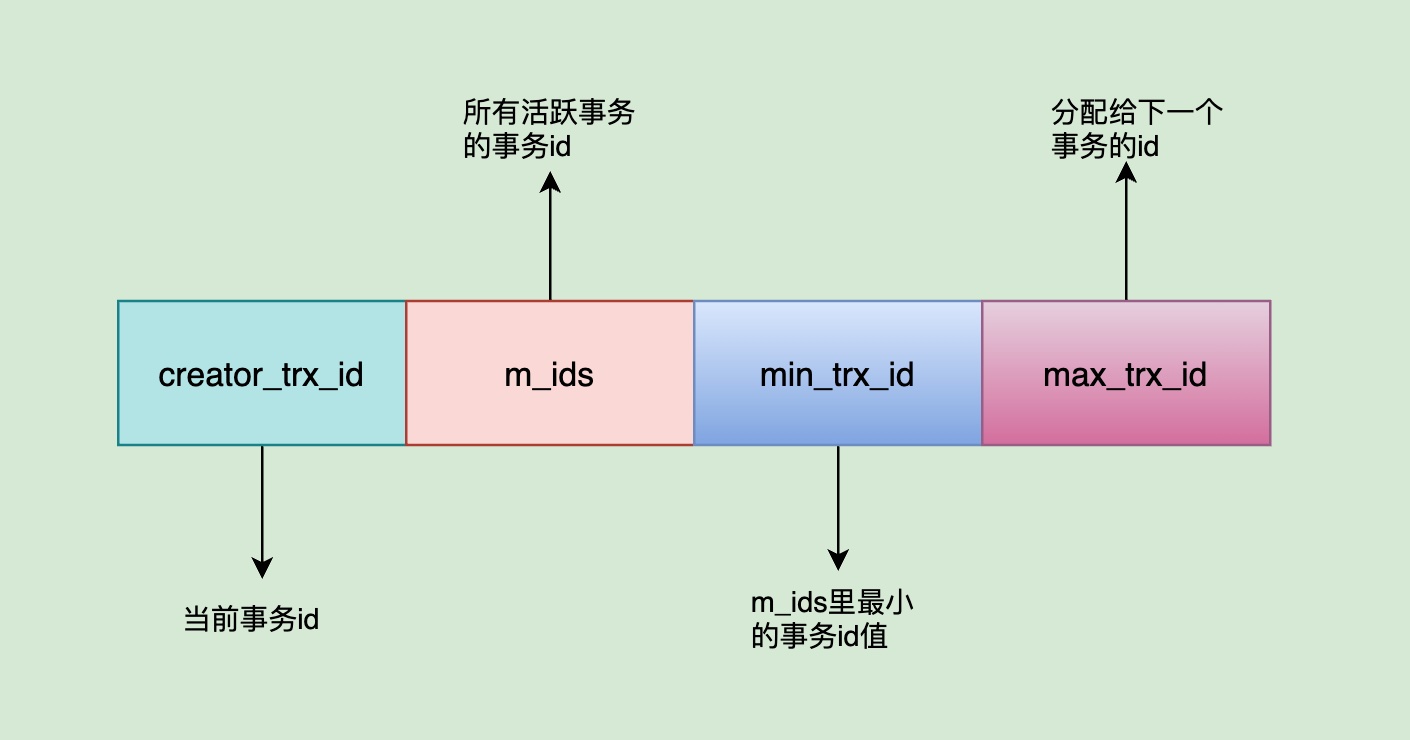
Read View 存放着一个列表,这个列表用来记录当前数据库系统中活跃的读写事务,也就是已经开启了,正在进行数据操作但是还未提交保存的事务。可以通过这个列表来判断某一个版本是否对当前事务可见。其中,有四个重要的字段:
creator_trx_id:创建当前Read View所对应的事务ID
m_ids:所有当前未提交事务的事务ID,也就是活跃事务的事务id列表
min_trx_id:m_ids里最小的事务id值
max_trx_id:InnoDB 需要分配给下一个事务的事务ID值(事务 ID 是累计递增分配的,所以后面分配的事务ID一定会比前面的大!)
MVCC里面最难的估计就是记住这四个字段的概念了。但是由于它们非常重要,如何判断当前版本对每一个事务是否可见,就是拿它们的值进行区间比较,所以请你务必要记住它们✊。接下来我也会通过详细的图解为大家说明这一过程。
MVCC如何实现可重复读?
ok,假设现在事务A和事务B同时对主键id = 1进行操作。事务A的id为20,事务B的id为30。
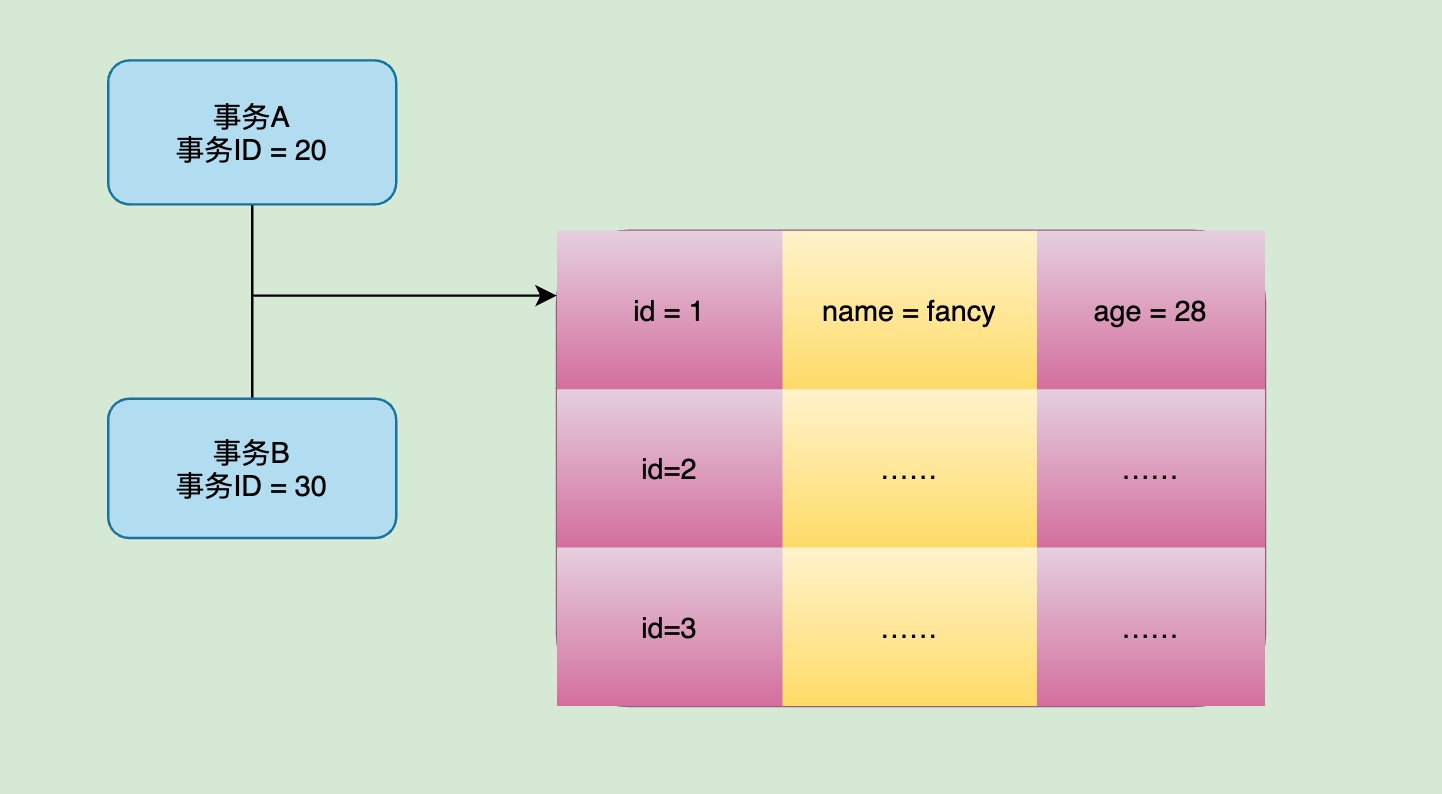
那么这两个事务就会创建各自的Read View:
 此时事务A的creator_trx_id=20,事务B的creator_trx_id=30。
此时事务A的creator_trx_id=20,事务B的creator_trx_id=30。
由于仅有两个活跃的事务,事务id分别为20和30。事务列表中最小的的事务id是事务A,所以min_trx_id应该为20,下一个也就是最大的事务id的max_trx_id值应该为事务B的下一个id,也就是31。
事务A去读取主键id为1的数据,找到了记录后就会去查看该记录的trx_id,事务A查看到该记录的trx_id值为10。

随后和自己的creator_trx_id值进行比较:

发现主键id=1这条记录.trx_id = 10 < 自己.creator_trx_id = 20,就判断到该记录的事务id不存在于活跃的事务列表中并且小于自己的事务id,这代表本次记录S的值是在自己查询之前提交的,那就可以放心的读取啦。读取完之后,会将该记录的trx_id修改为自己的事务id。
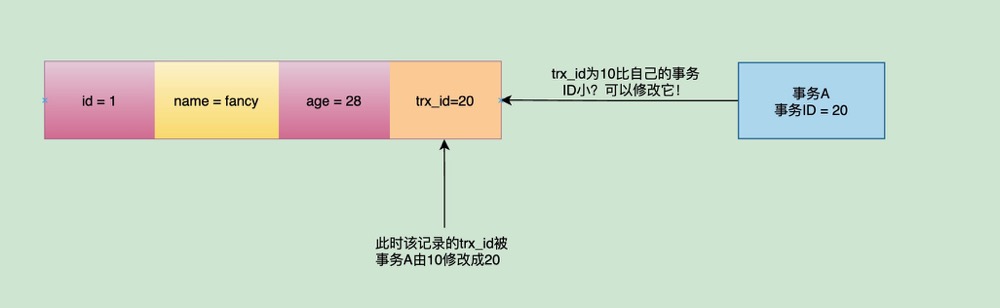
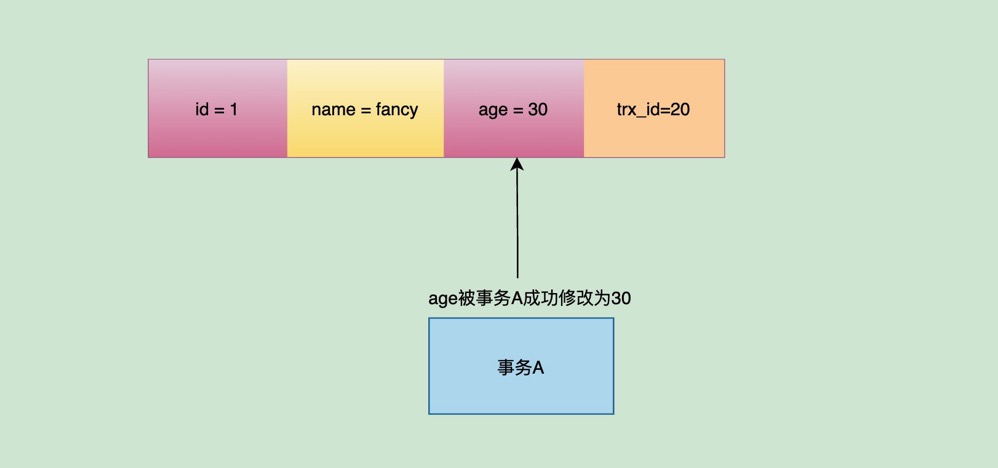
然后,把fancy的age从28又改成了30🙃。
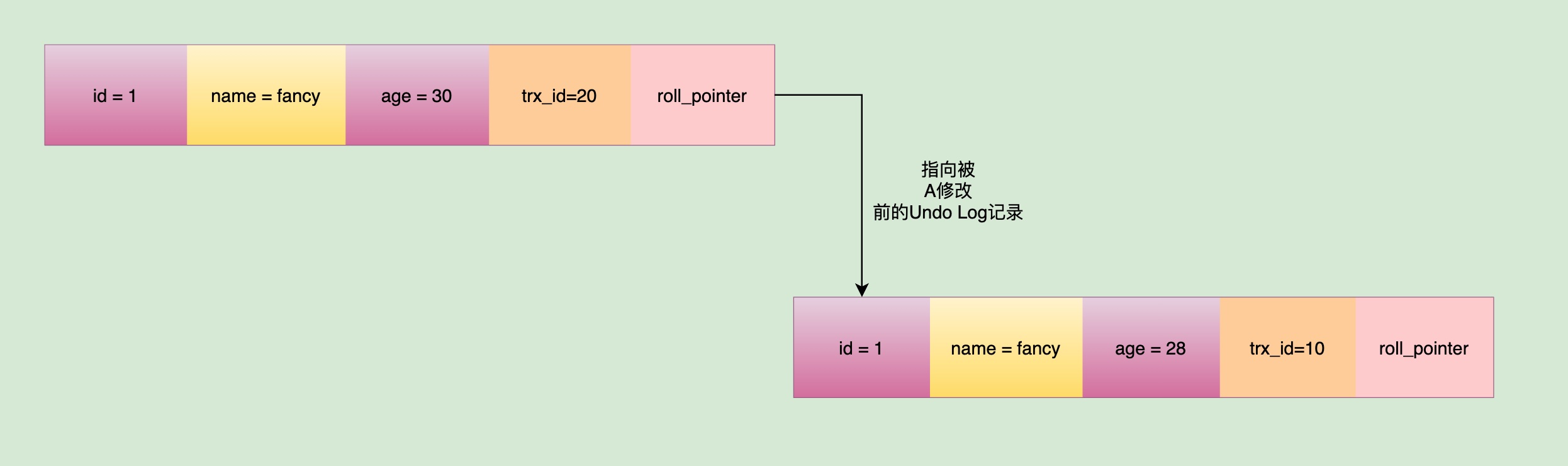
那么还有什么字段此时也会被修改吗?没错,就是我们刚刚提到的,Undo Log的另一个隐藏字段:roll_pointer指针。它会去指向被事务A修改之前的版本,也就是fancy的年龄还是28时候的地址,就为了用来记录,方便下次被查询:
随后,事务B也进来了,哈哈。它也要进行对主键id为1的update操作。把fancy的年龄直接从30更改为50!此时会再次进行一次trx_id的比较过程,去判断自己的creator_trx_id是否大于这条记录对应的trx_id,如果大于,就去修改这条记录的值,将年龄从30修改为50:
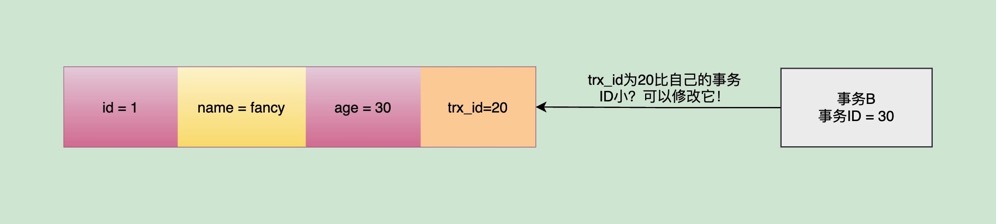
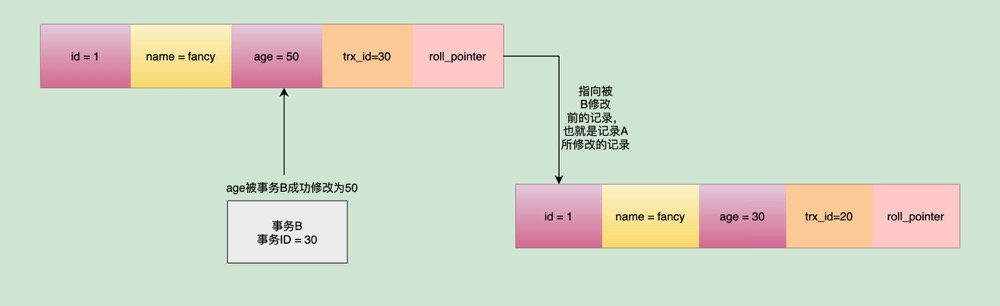
重点来了!
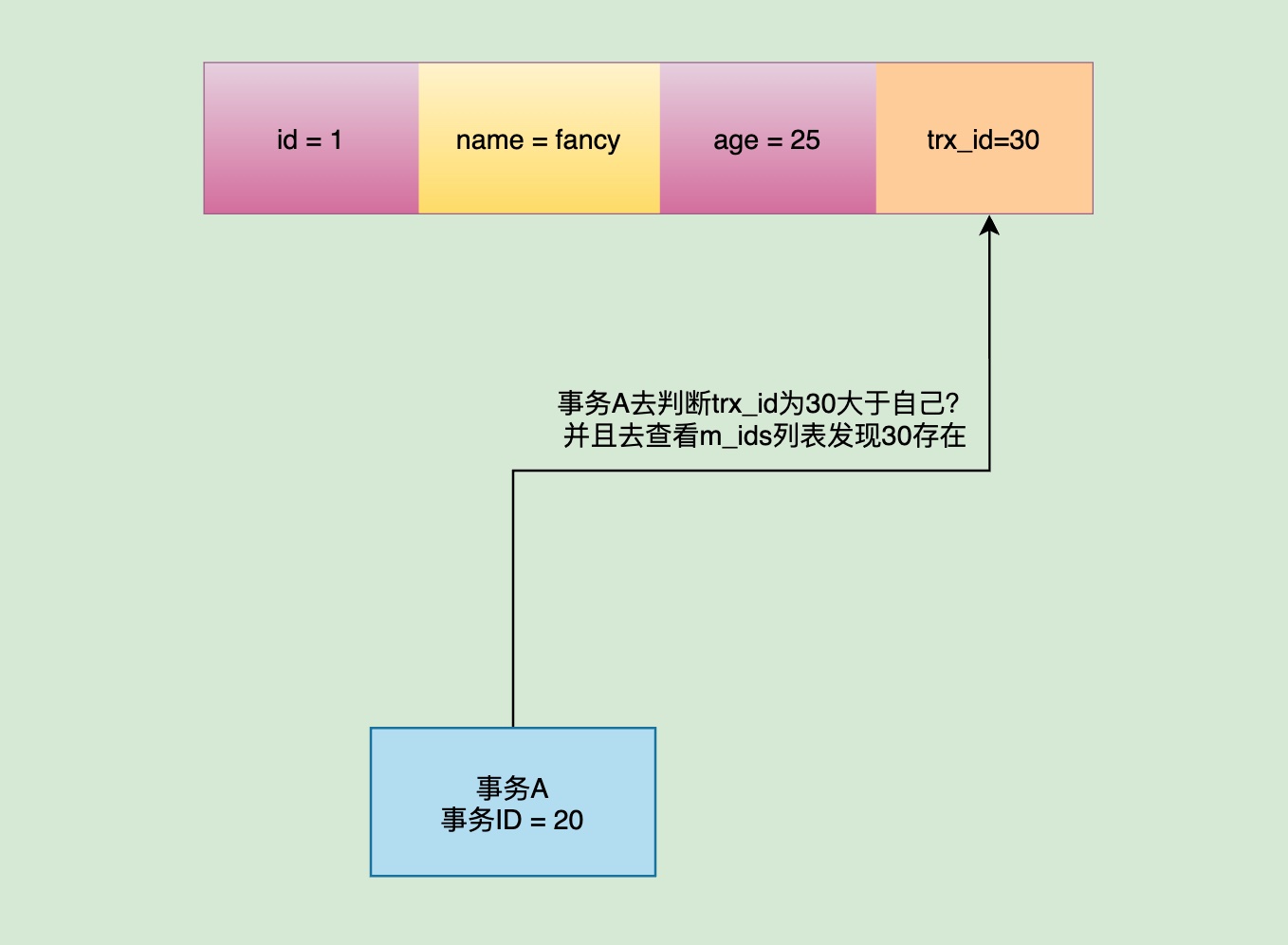
过了一会,如果事务A再次去读取主键id=1这行的值,发现这条记录的trx_id已经变成了30,就会再次进行值的区间比较:发现自己.trx_id(20)<主键id=1这条记录.trx_id(30)<max_trx_id(31),并且trx_id为30的值存在于m_ids中,就代表自己读取到的是和自己同一时间范围内一块启动的另一个未提交的活跃事务所修改的值。
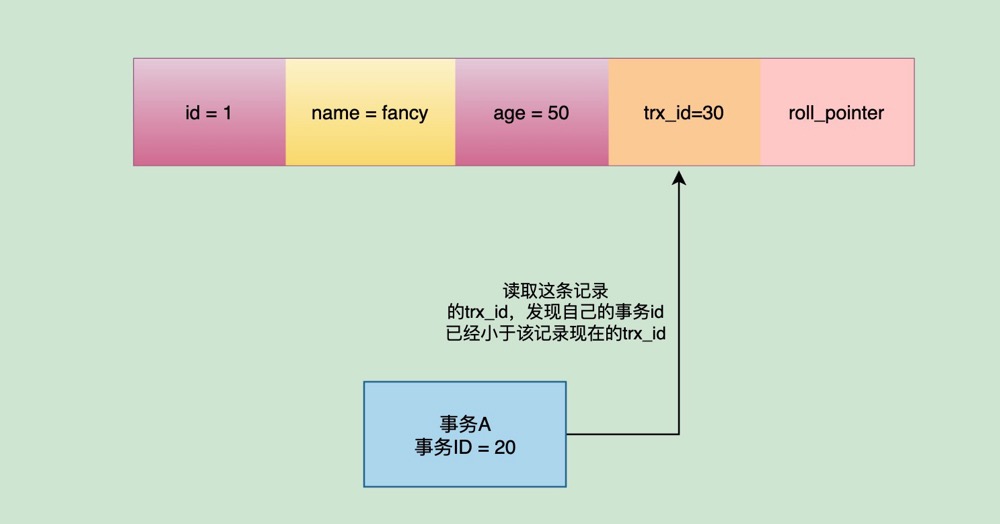
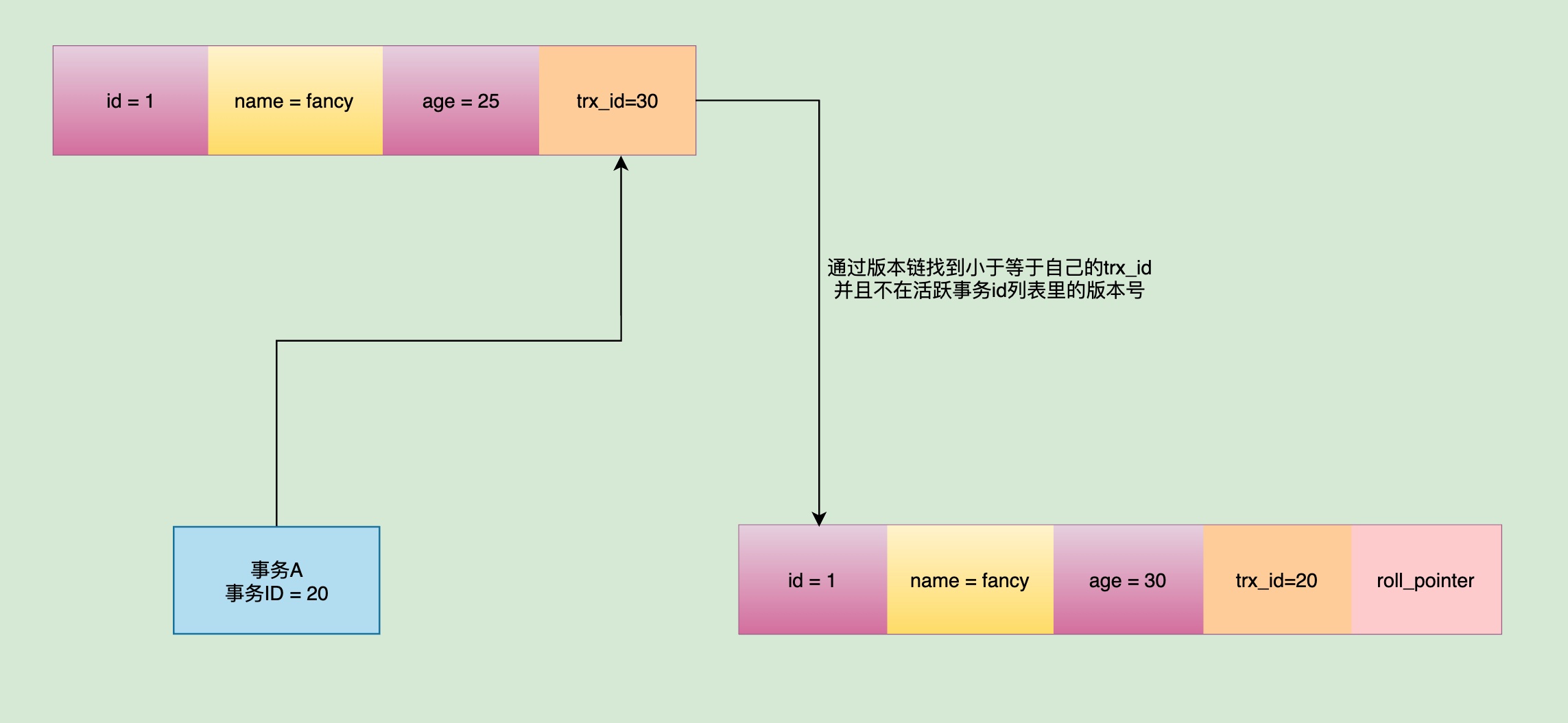
那么此时事务A是不会去读取这条记录对应的数据的,它会通过Undo Log上的roll_pointer指向的地址去查找上一个旧版本的记录,直到找到第一条trx_id小于等于自己的事务id并且不存在于m_ids列表中的记录,代表是别的事务已经提交的最后一条记录,然后读取它。

这样子,每一个事务去读取或者修改同一个记录时,只能操作已经提交了的数据,未提交的数据是不能读取到的。可重复,就这样实现了。
其实就是通过Read View的字段判断这行记录对自己是否可见,如果不可见的话再去找Undo Log里面记录的对自己可见的数据,然后操作就完事了。
怎么样,是不是很简单?
那么,我们再来看看MVCC如何实现提交读。
MVCC如何实现提交读?
我们先来回顾一下什么是提交读,提交读能够解决脏读这个并发一致性问题。脏读问题本质上就是一个事务读取到了另一个事务没有提交的内容。那么Read View要如何解决这个问题呢?道理其实一样的。
假设事务A和事务B依然同一时刻启动,事务B将同一行的记录,也就是fancy的年龄又改成了25,但是并没有提交哦,所以此时事务A就会去读取这条记录的trx_id。
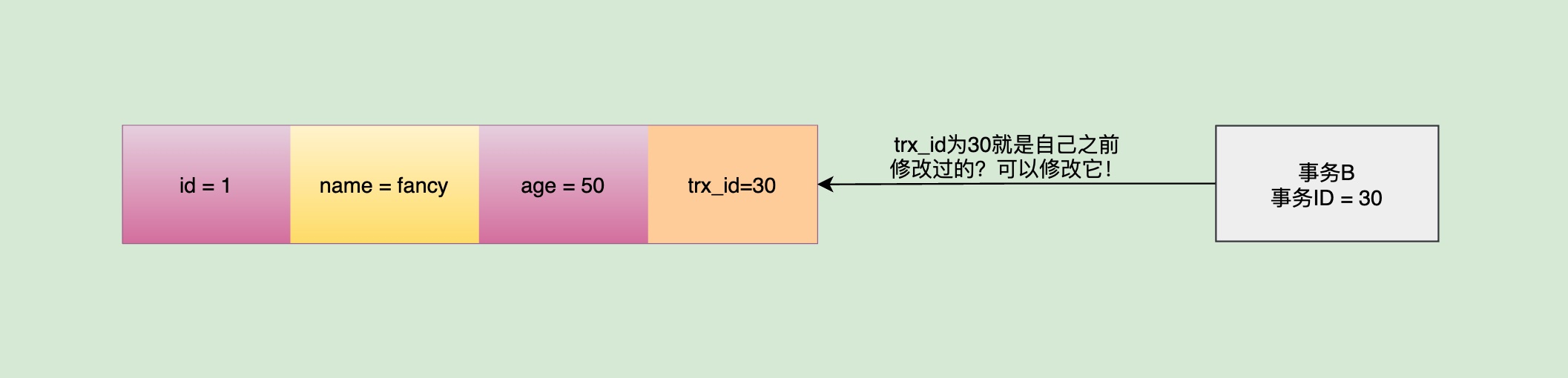

事务A查看到该记录的trx_id居然比事务A的Read View列表里面的creator_trx_id值大,并且修改这条记录的事务的trx_id存在于自己的m_ids列表里面,那么事务A就可以判断得到该记录是被另一条没有提交的事务修改的,所以它不会去读取这条数据的内容,事务A会继续通过Undo Log往下找第一条trx_id小于等于自己的事务id并且不在活跃事务列表m_ids里面的数据。由此,便不会看到别的事务正在修改的数据,脏数据也不会产生。

总结
通过以上描述,我们就可以清楚的知道:InnoDB 中,MVCC 就是通过 Undo Log + Read View 进行数据读取,Undo Log 保存了历史快照,而 Read View 规则帮我们判断当前版本的数据是否可见。从而不需要通过加锁的方式,就可以实现提交读和可重复读这两种隔离级别。
总的来说,MVCC本质上就是一种数据结构。已提交读和可重复读都是使用了Read View这种策略通过区间判断获取自己能够读取的内容,然后展示。InnoDB通过MVCC,解决了脏读、不可重复读。但是InnoDB如何去解决幻读呢?光靠MVCC其实是不够的,InnoDB通过MVCC + Next-Key Lock(临键锁)来解决幻读,那么下一篇文章,我们就来详细聊聊InnoDB的各种相关的锁,再说说InnoDB是如何解决幻读的。

 京公网安备 11010502036488号
京公网安备 11010502036488号