

神经网络的搭建
当我们具备了TensorFlow的基本知识之后,就可以了解神经网络的实现过程了
神经网络的实现过程:
-
准备数据集,提取特征,作为输入数据喂给神经网络
-
搭建神经网络结构,从输入到输出(先搭建计算图,再用会话执行)
(NN向前传播→计算输出)
-
大量特征喂给神经网络,不断迭代优化神经网络参数
(NN反向传播→优化参数,训练模型)
-
使用训练好的模型预测和分类
基于神经网络的机器学习主要分为两个过程(训练和使用)。
训练过程是第1,2,3步的循环迭代,使用过程为第4步,在参数优化完成后就可以 固定参数,去预测和分类数据。
很多实际应用中,我们会先使用现有的成熟网络结构,喂入新的数据,训练相应模型,判断是否能对喂入的从未见过的新数据做出正确预测或分类,再适当更改网络结构,反复迭代,让机器自动训练参数找出最优结构和参数,一以此固定专用模型。
前向传播
前向传播就是搭建神经网络结构模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出
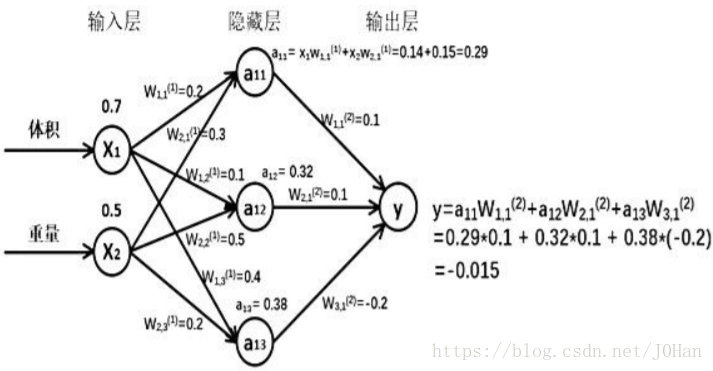
假设生成一批零件,体积为x1重量为x2,体积和重量就是选择的特征,将其喂入神经网络,当体积和重量走过神经网络后会得到一个输出。当输入特征值为:体积0.7 重量0.5时
由搭建的神经网络结构可知,隐藏节点a11=x1*w11+x2*w21=0.14+0.15=0.29,同理可算出a12=0.32,a13=0.38,最终能计算出y = -0.015,这就实现了向前传播过程。
反向传播
反向传播目的就是训练优化模型参数,在所有参数上用梯度下降,是神经网络模型在训练数据上的损失函数最小
- 损失函数(loss):计算得到的预测值y与已知标注y_的差距,损失函数有很多计算方法,均方误差MSE是比较常用的方法之一。
- 均方误差MSE:求向前传播计算结果y与已知答案y_之差的平方再求平均。
MSE(y_,y)=n∑i=1n(y−y_)2
用TensorFlow函数表示为:
loss_mse = tf.reduce_mean(tf.square(y,y_)) 反向传播训练方法:以减小 loss 值为优化目标,有:
- 梯度下降
- momentum 优化器
- adam 优化器等优化方法。
这三种优化方法用TensorFlow函数可以表示为:
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) train_step=tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss) train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss) 学习率:决定每次参数更新的幅度
优化器中都需要一个叫做学习率的参数,使用时,如果学习率选择过大会出现震荡不收敛的情况,如果学习率选择过小,会出现收敛速度慢的情况。我们可以选个比较小的值填入,比如 0.01、0.001。

 京公网安备 11010502036488号
京公网安备 11010502036488号