

From Attention to Transformer — A Leap in NLP History
Abstract
Our group adopted a text summarization model called BertSum in project. It is a deep learning model based on Google Bert which published in late 2018. Bert is huge leap in deep learning history because of its innovative neural network structure called Transformer. Armed with Transformer, people are able to train a model parallelly and with much less cost. Meanwhile, compared with original CNN or RNN, the Transformer captured more textual information even between seperated sentences or paragraphs.
In this blog, we are going to breifly discuss how this new structure evolved. We will illustrate the process using as many pictures as we can, making it vivid and readable.
Attention Mechanism
In deep learning, convolutional neural networks(CNN) and recurrent neural networks(RNN) have shined in many areas of CV and NLP. Both feedforward neural networks and recurrent neural networks have strong capabilities, but due to the limitations of optimization algorithms and computing power, when dealing with complex tasks, it is difficult to achieve universal approximation. Therefore, in order to improve the network's ability to process information, you can learn from the mechanisms that the human brain has used to process information, mainly as follows:
- Attention mechanism: filtering out a lot of irrelevant information.
- External memory: optimize the memory structure of the neural network to increase the capacity of the neural network to store information
Among them, the Attention mechanism is widely used in various tasks of natural language processing. Attention means that the human brain can intentionally or unintentionally select a small amount of useful information from a large amount of input to focus on processing, and ignore other information.
The most typical example is the cocktail party effect: when a person is at a noisy cocktail party, despite many influencing factors, he can still hear the conversation of friends and ignore the voices of others. When reading a webpage, we do not pay equal attention to the contents of each part. We may allocate most of the attention in the title or the picture, and pay less attention in the rest.

Let's take machine translation for example. A typical Encoder-Decoder model is shown below. The Encoder receives the sequence data of a sentence, and performs non-linear transformation to obtain the intermediate semantic code C. Then the Decoder decodes the C to obtain the target sequence data.

In target, each word is generated like this:
During the generation of each word, the semantic encoding used has not changed, that is, when generating , any word in source has the same influence on
, so such a model does not reflect the attention mechanism. For example, when translating She plays piano, if the model of Encoder-Decoder is used, when translating "piano-钢琴", the weight of each word in the source to "piano" is
, which is obviously unreasonable.

If the attention mechanism is introduced into the Encoder-Decoder model, the overall model structure can be simply expressed as:

At this point, the generation process of each word in Target becomes:
where f' represents some transformation function and g represents a weighted sum. Then the process of translating "She" in the above example can be expressed as:

The essence of attention can be described as a mapping from a query to a series of key-value pairs, as shown below:

There are three main steps when calculating Attention:
- Calculate the similarity of query and each key to get weights. Commonly used similarity functions are dot product, splicing, perceptron, etc.
- Normalize these weights using a softmax function
- Weight the sum of the weight and the corresponding key value to get the final Attention
Self-Attention
Self-Attention is also called Intra-Attention, that is, internal attention. In the Encoder-Decoder framework of general tasks, Source and Target content are different. For example, for English-Chinese machine translation, Source is an English sentence and Target is the corresponding translated Chinese sentence. The Attention mechanism occurs between the Query element of the Target and all elements in the Source. Self Attention refers not to the Attention mechanism between Target and Source, but to the Attention mechanism that occurs between Source internal elements or between Target internal elements.
One of the great advantages of Self-Attention is that it can capture some syntactic or semantic features between words in the same sentence. Compared with the traditional RNN and LSTM, the model after introducing Self-Attention is easier to capture the long-distance interdependent features in the sentence, so that the features existing in the sentence can be effectively used. In addition, Self-Attention's good support for computing parallelism has also become an important reason for it to gradually replace general Attention.
Transformer
Transformer was proposed by the Google in 2017. It is widely used in the current NLP field. It was proposed by Ashish Vaswani and others in the paper "Attention is all your need". Transformer's performance on machine translation tasks surpasses RNN and CNN, achieves good results using only the encoder-decoder and attention mechanisms. The biggest advantage is that it can be efficiently parallelized. So why can Transformer be parallelized efficiently? This starts with the Transformer architecture.
In fact, Transformer is a seq2seq model with a self-attention mechanism. We've mentioned the seq2seq model before, that is, the input is a sequence model, and the output is also a sequence model. The figure is the architecture of a Transformer:
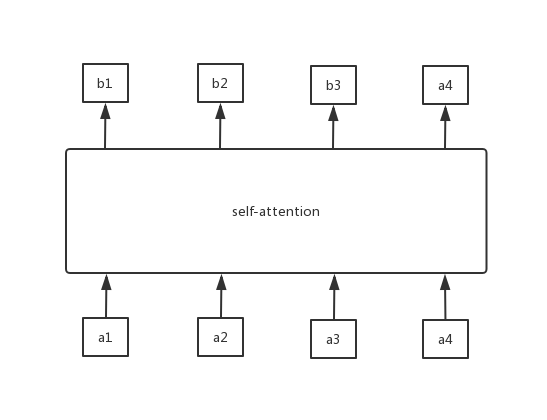
Let's assume that if we replace self-attention with RNN, then when output b2, we must read the output b1 of the previous sequence, and when output b3, we must read the outputs b1 and b2 of the previous sequence. Similarly, when outputting the current sequence, the output of the previous sequence must be used as the input, so when using RNN,the output sequence cannot be efficiently parallelized.
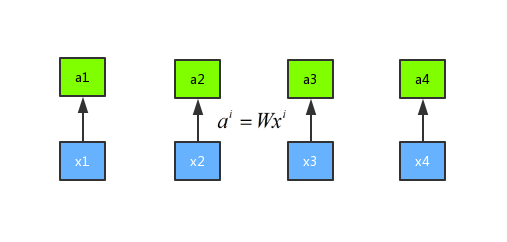
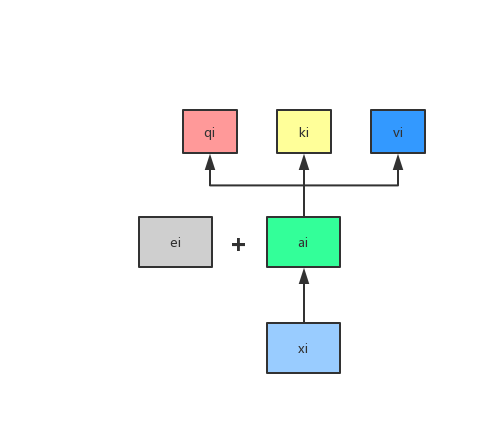
Suppose we have four sequences x1, x2, x3, and x4. First we multiply weight with sequence . Then we get new sequence a1,a2,a3,a4.
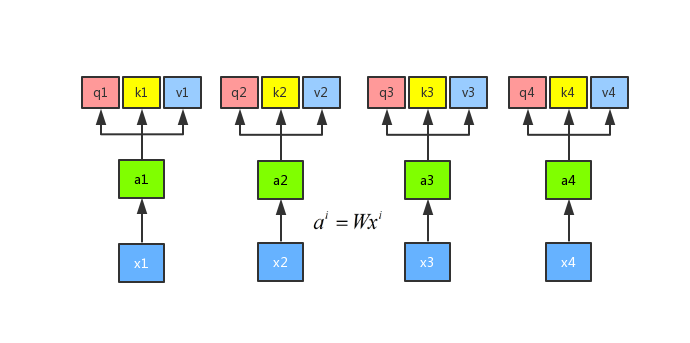
Then we multiply the input a by three different weight matrices W to get the three vectors q, k and v, that is, ,
,
. Here, q represents a query, which needs to match other vectors; k represents a key, which needs to be matched by q, v represents value, and represents information that needs to be extracted.
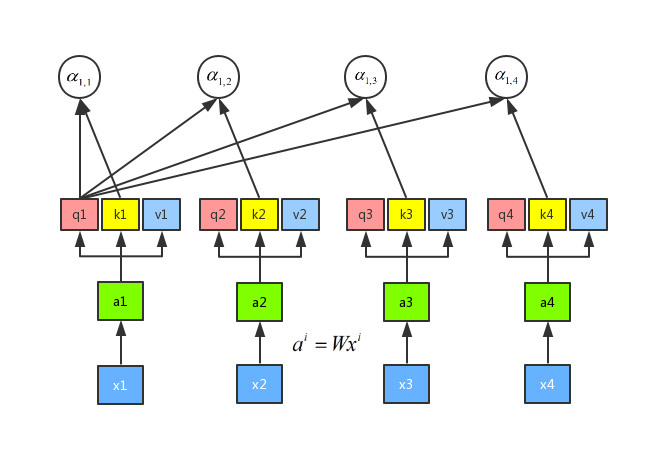
For each query q and each key k, we are going to manipulate them by attention. We want 2 vectors as input and a single number as output. We can do that by inner product. q1 and k1 -> , q1 and k2 ->
, q1 and k3 ->
, q1 and k4 ->
. Attention can be done in many ways. Here we use scaled dot product,
, d is the dimension of q and v.
Then we do a softmax on ,
,
,
, get
,
,
,
.
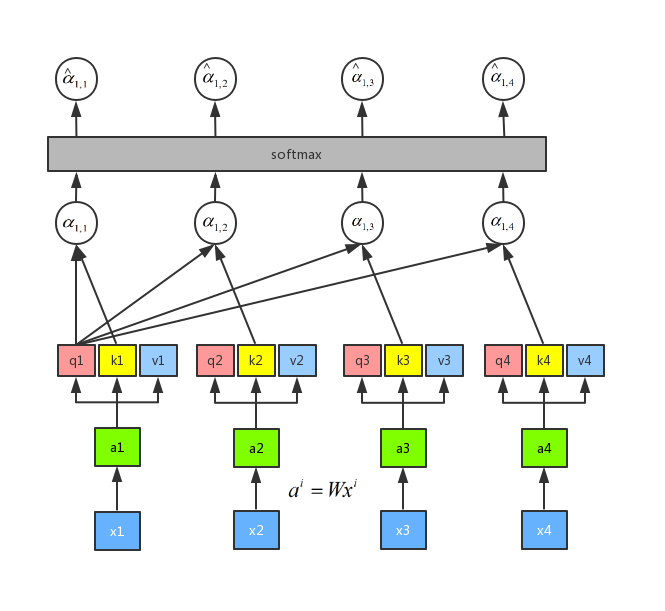
With the softmax output, then we can get b1 using .
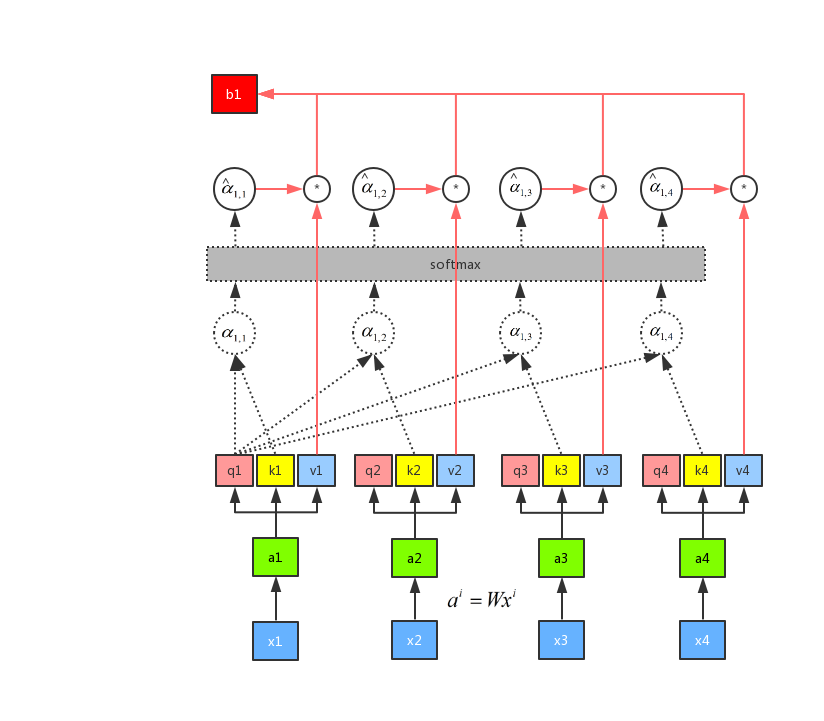
When we got b1, we saw the inputs of a2, a3, and a4. So the output at this time has a chance to browse to the entire sequence. But each output sequence has its own focus. This is the essence of the attention mechanism. We can control the weight of the sequence that our current output focuses on by controlling ,
,
,
. If a certain sequence needs to be followed, then the corresponding α values are high weighted, and vice versa. This is to use q1 as attention to get the entire output b1. Similarly, we can use q2, q3, and q4 to do attention to find b2, b3, and b4, respectively. In addition, b1, b2, b3, and b4 are calculated in parallel, and there is no sequence effect on each other. So the entire intermediate calculation process can be regarded as a self-attention layer, with inputs x1, x2, x3, and x4, and outputs b1, b2, b3, and b4.
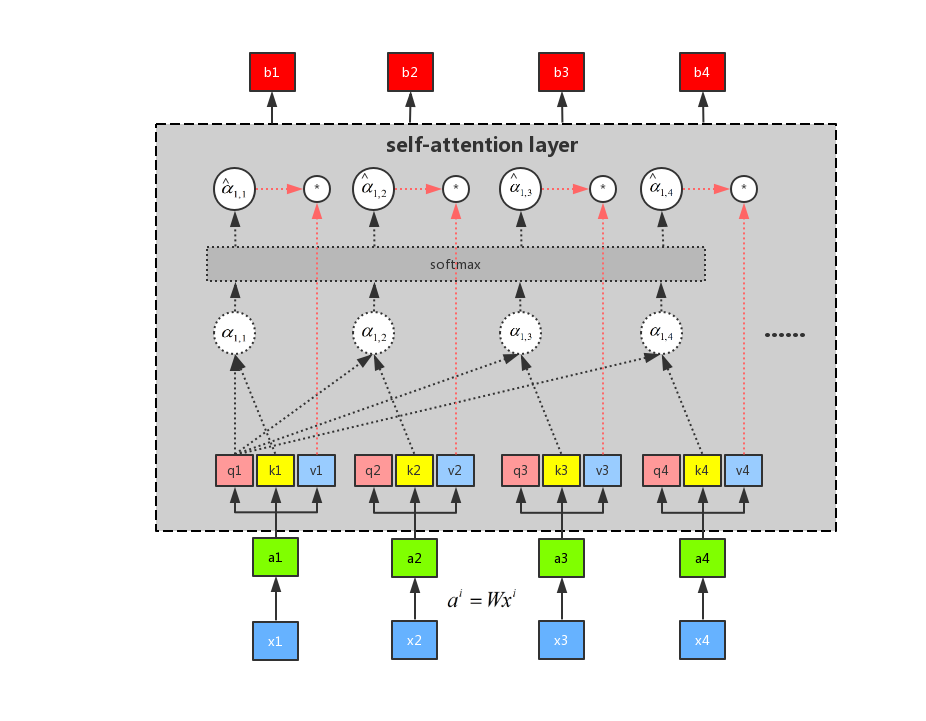
We can summarize the procedure above in one diagram.
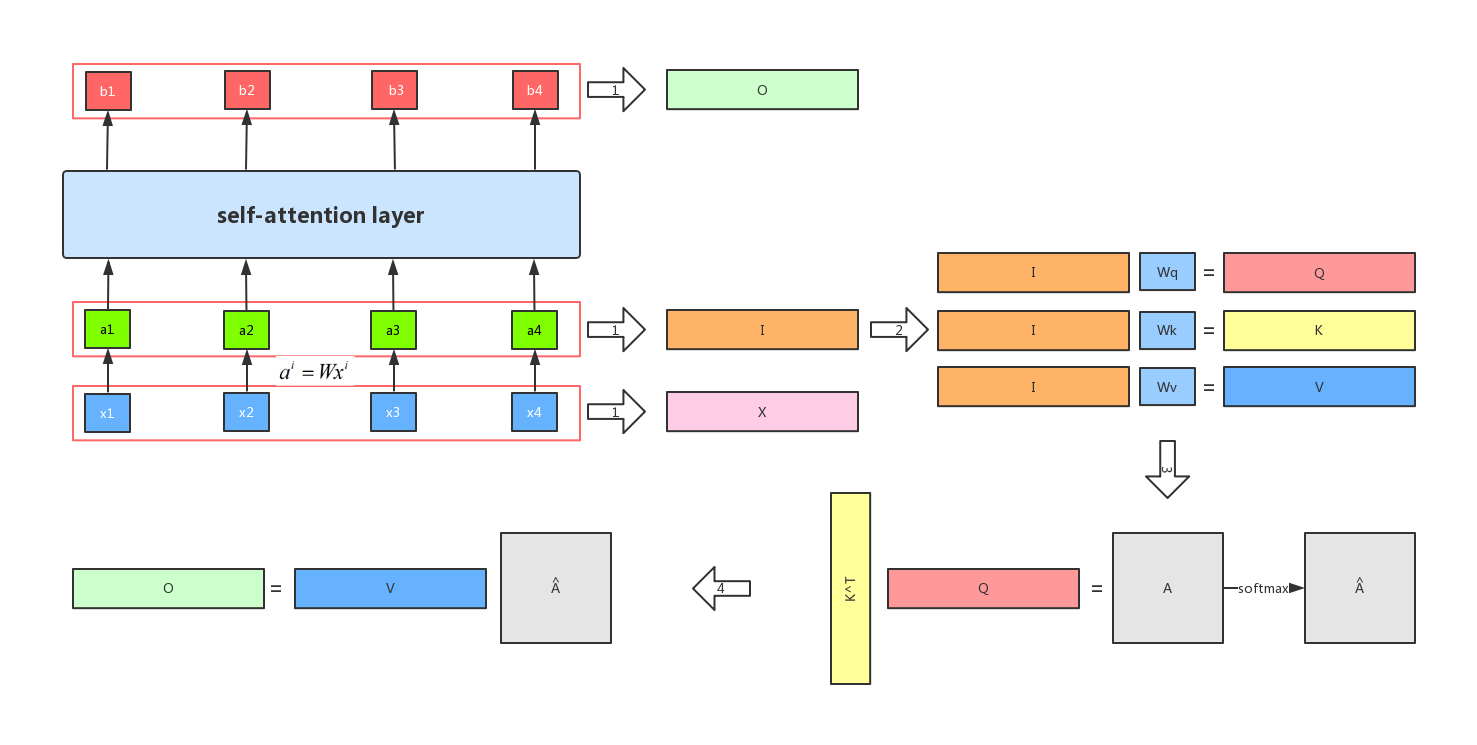
The entire transformer architecture can be divided into two parts, the left part is the encoder, and the right part is the decoder. First of all, let's look at the encoder part. First, after the input comes in from the bottom, we perform the embedding operation. After embedding, we then embed the positional encoding after embedding. The positional encoding is to add a vector ei of the same dimension to ai.
Conclusion
Transformer is completely a new architecture of neural network. Recently, most state-of-art NLP models have adopted Transformer as their base structure, like XLNet, RoBerta, ELECTRA, etc. In the future, we envision applications of Transformer to a wider set of tasks in all deep learning regions.

 京公网安备 11010502036488号
京公网安备 11010502036488号