本篇核心内容为数据清洗。
数据清洗
数据工作的步骤应该为:
- 数据获取
- 数据清洗
- 数据分析
- 数据可视化与建模
因此,上一篇博文中,本人说过,下一篇博文会讲一下数据分析中重要的一步
我们要知道,数据清洗本着为下一步数据分析服务的目的进行,因此,数据处理要根据数据分析确定它是否需要处理,需要怎样的处理,才能适应接下来的分析工作和挖掘工作。
整体分为几个不同的步骤来看。
import pandas as pd
import numpy as np
一. 缺失数据的处理
整体的处理方法在理论上我们可以采用填补或者丢弃。选择哪种依情况而定。总体工作对于pandas来说,就利用四个方法:
- fillna():填充
- dropna():根据条件筛选过滤
- isnull():判断是否为空
- notnull():判断是否不为空
如上四个函数,加上我们其他的语法,逻辑等,基本可以完成这一步工作。如下做演示,这几个方法不需要特别讲解
df = pd.DataFrame([np.random.rand(3),np.random.rand(3),np.random.rand(3)],columns=['A','B','C'])
df
|
A |
B |
C |
| 0 |
0.902598 |
0.598310 |
0.169824 |
| 1 |
0.425368 |
0.805950 |
0.677491 |
| 2 |
0.830366 |
0.305227 |
0.487216 |
df['A'][0] = np.NAN
print(df)
df.fillna(1)
A B C
0 NaN 0.598310 0.169824
1 0.425368 0.805950 0.677491
2 0.830366 0.305227 0.487216
|
A |
B |
C |
| 0 |
1.000000 |
0.598310 |
0.169824 |
| 1 |
0.425368 |
0.805950 |
0.677491 |
| 2 |
0.830366 |
0.305227 |
0.487216 |
df['A'][0] = np.NAN
print(df)
df.dropna()
A B C
0 NaN 0.598310 0.169824
1 0.425368 0.805950 0.677491
2 0.830366 0.305227 0.487216
|
A |
B |
C |
| 1 |
0.425368 |
0.805950 |
0.677491 |
| 2 |
0.830366 |
0.305227 |
0.487216 |
# 根据参数确定丢失行或列
df['A'][0] = np.NAN
print(df)
df.dropna(axis=1)
A B C
0 NaN 0.598310 0.169824
1 0.425368 0.805950 0.677491
2 0.830366 0.305227 0.487216
|
B |
C |
| 0 |
0.598310 |
0.169824 |
| 1 |
0.805950 |
0.677491 |
| 2 |
0.305227 |
0.487216 |
# 获取bool值对应的dataframe。
bool_df_t = df.isnull()
bool_df_t
|
A |
B |
C |
| 0 |
True |
False |
False |
| 1 |
False |
False |
False |
| 2 |
False |
False |
False |
# 与上者相反
bool_df = df.notnull()
bool_df
|
A |
B |
C |
| 0 |
False |
True |
True |
| 1 |
True |
True |
True |
| 2 |
True |
True |
True |
当然它也可以完成类似于numpyarray中的操作,不过没啥意义。
print(df[bool_df_t])
print(df[bool_df])
A B C
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
A B C
0 NaN 0.598310 0.169824
1 0.425368 0.805950 0.677491
2 0.830366 0.305227 0.487216
二. 重复值的处理
考虑到某些数据不符合我们的分析要求,或者输入建模的问题,需要在某种情况下对数据进行重复值的处理
# 构建包含重复值的数据
df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4,
'data2' : np.random.randint(0, 4, 8)})
print(df_obj)
## df.duplicated():判断重复数据,默认是判断全部列,可指定列数判断。我们可以根据得出的结果分析,方***记录第一次出现的数据,标记为false,但
## 之后再出现的数据就会被标记为True,表示重复。
print(df_obj.duplicated())
data1 data2
0 a 1
1 a 2
2 a 2
3 a 0
4 b 1
5 b 1
6 b 1
7 b 1
0 False
1 False
2 True
3 False
4 False
5 True
6 True
7 True
dtype: bool
## 我们也可以利用它判断某一列。
print(df_obj.duplicated('data2'))
0 False
1 False
2 True
3 False
4 True
5 True
6 True
7 True
dtype: bool
判断之后,可以利用drop_duplicates()方法删除重复的行。
# 它可以删除掉已经重复的数据,保留第一次出现的数据。
df_obj.drop_duplicates()
|
data1 |
data2 |
| 0 |
a |
1 |
| 1 |
a |
2 |
| 3 |
a |
0 |
| 4 |
b |
1 |
三. 数据格式转化
考虑到部分数据格式的存在可能不符合后期数据分析的标准,或者不适合作为模型的输入,我们要对某些数据做对应的处理。
- 利用函数进行映射。
- 直接指定值进行替换处理。
# 生成随机数据
ser_obj = pd.Series(np.random.randint(0,10,10))
ser_obj
0 0
1 0
2 7
3 3
4 0
5 8
6 6
7 7
8 8
9 9
dtype: int32
# 进行函数映射,利用lamdba表达式,map函数与numpy中的applymap相似,与python基础语法的map也相似。可以认为相同
ser_obj.map(lambda x : x ** 2)
0 0
1 0
2 49
3 9
4 0
5 64
6 36
7 49
8 64
9 81
dtype: int64
# 进行值的替换,replace方法
# 生成一个随机的series
data = pd.Series(np.random.randint(0,100,10))
print(data)
0 73
1 18
2 48
3 27
4 1
5 60
6 59
7 38
8 66
9 53
dtype: int32
# 单一替换
data = data.replace(73,100)
data
0 100
1 18
2 48
3 27
4 1
5 60
6 59
7 38
8 66
9 53
dtype: int32
# 多对对替换
data = data.replace([100,18],[-1,-1])
data
0 -1
1 -1
2 48
3 27
4 1
5 60
6 59
7 38
8 66
9 53
dtype: int64
字符串操作,可直接继承python基本语法的字符串操作,这里不在浪费时间。
四. 数据合并
根据不同的条件将数据进行联合。主要使用的方法是pd.merge
pd.merge:(left, right, how='inner',on=None,left_on=None, right_on=None )
left:合并时左边的DataFrame
right:合并时右边的DataFrame
how:合并的方式,默认'inner', 'outer', 'left', 'right'
on:需要合并的列名,必须两边都有的列名,并以 left 和 right 中的列名的交集作为连接键
left_on: left Dataframe中用作连接键的列
right_on: right Dataframe中用作连接键的列
四种连接方式非常重要,它们分别为内连接,全连接,左连接,右连接。
- 内连接:根据指定键的交集进行连接。
- 外连接:根据指定键的并集进行连接。
- 左连接:根据指定left的dataframe键进行连接。
- 右连接:根据指定right的dataframe的键进行连接。
import pandas as pd
import numpy as np
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
left
|
key |
A |
B |
| 0 |
K0 |
A0 |
B0 |
| 1 |
K1 |
A1 |
B1 |
| 2 |
K2 |
A2 |
B2 |
| 3 |
K3 |
A3 |
B3 |
right
|
key |
C |
D |
| 0 |
K0 |
C0 |
D0 |
| 1 |
K1 |
C1 |
D1 |
| 2 |
K2 |
C2 |
D2 |
| 3 |
K3 |
C3 |
D3 |
pd.merge(left,right,on='key') #指定连接键key
|
key |
A |
B |
C |
D |
| 0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K1 |
A1 |
B1 |
C1 |
D1 |
| 2 |
K2 |
A2 |
B2 |
C2 |
D2 |
| 3 |
K3 |
A3 |
B3 |
C3 |
D3 |
## 可以看到left和right数据都有key键,他们的值都有k0,k1,k2,k3,进行连接后,指定为key后,他们连接起来,数据拼接没有丢失任何数据。
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
left
|
key1 |
key2 |
A |
B |
| 0 |
K0 |
K0 |
A0 |
B0 |
| 1 |
K0 |
K1 |
A1 |
B1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
| 3 |
K2 |
K1 |
A3 |
B3 |
right
|
key1 |
key2 |
C |
D |
| 0 |
K0 |
K0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
C1 |
D1 |
| 2 |
K1 |
K0 |
C2 |
D2 |
| 3 |
K2 |
K0 |
C3 |
D3 |
pd.merge(left,right,on=['key1','key2']) #指定多个键,进行合并
|
key1 |
key2 |
A |
B |
C |
D |
| 0 |
K0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
A2 |
B2 |
C1 |
D1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
C2 |
D2 |
look,如上所示,内连接的方法是连接交集,对于k1 k0这个序列,在right中,显然存在两组数据,而left中只存在一组数据,根据交集来看,这两组数据与那一组数据都属于交集,因此,拼接为两组数据。那如果是left中存在两组呢,我们来看看结果。
left = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(pd.merge(left,right,on=['key1','key2']))
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A1 B1 C1 D1
2 K1 K0 A1 B1 C2 D2
3 K1 K0 A2 B2 C1 D1
4 K1 K0 A2 B2 C2 D2
我们来思考一下合并的规则,对于如上数据,我们最终得到5条数据,实际上left和right匹配的数据仅仅只有,一组k0 k0,两组k1 k0罢了,但是这两组k1 k0却进行了交集运算,将数据合并为四组,这种交集运算其实不难理解,但是初次接触也需要思考这其实是数据库交集的计算。可以从如下例子入手。
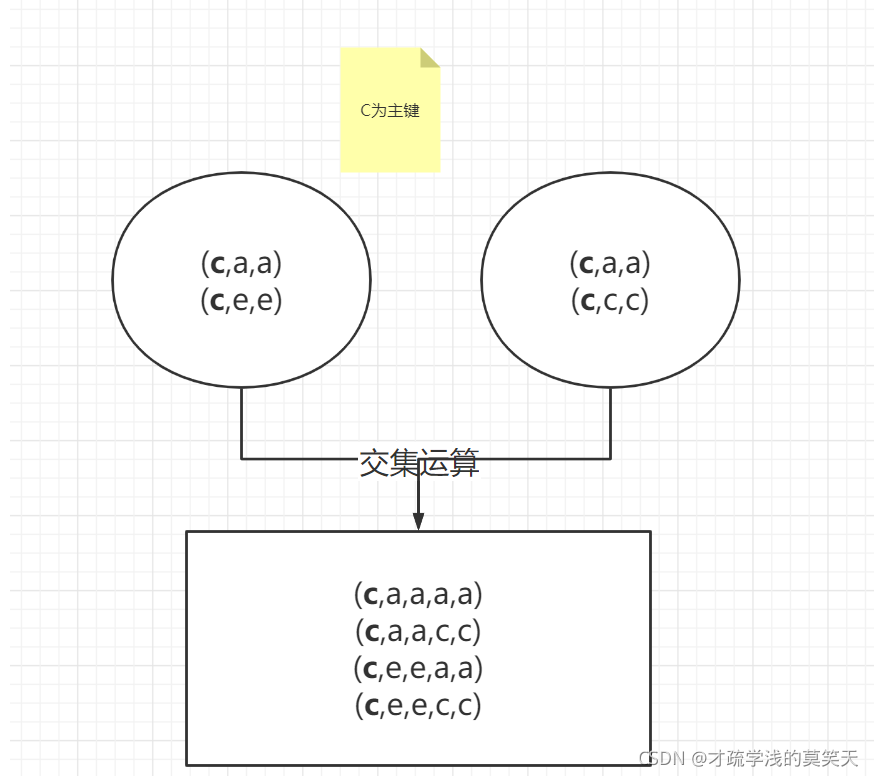
left = pd.DataFrame(
{'key':['c','d','c'],
'A':['a','b','e'],
'B':['a','b','e']},
)
right = pd.DataFrame(
{'key':['c','d','c'],
'C':['a','b','c'],
'D':['a','b','c']},
)
left
|
key |
A |
B |
| 0 |
c |
a |
a |
| 1 |
d |
b |
b |
| 2 |
c |
e |
e |
right
|
key |
C |
D |
| 0 |
c |
a |
a |
| 1 |
d |
b |
b |
| 2 |
c |
c |
c |
pd.merge(left,right,on=['key'])
|
key |
A |
B |
C |
D |
| 0 |
c |
a |
a |
a |
a |
| 1 |
c |
a |
a |
c |
c |
| 2 |
c |
e |
e |
a |
a |
| 3 |
c |
e |
e |
c |
c |
| 4 |
d |
b |
b |
b |
b |
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(pd.merge(left, right, how='left', on=['key1', 'key2']))
## 匹配left数据框内有的所有键对,right没有则不匹配。
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
print(pd.merge(left, right, how='right', on=['key1', 'key2']))
## 匹配right数据框内所有的键对,left没有则不匹配。
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
外连接,所有值,不存在则用na填充(并集)
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(pd.merge(left,right,how='outer',on=['key1','key2']))
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
处理列名重复数据
# 处理重复列名
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data' : np.random.randint(0,10,3)})
df_obj1
|
key |
data |
| 0 |
b |
4 |
| 1 |
b |
5 |
| 2 |
a |
3 |
| 3 |
c |
0 |
| 4 |
a |
4 |
| 5 |
a |
5 |
| 6 |
b |
4 |
df_obj2
|
key |
data |
| 0 |
a |
8 |
| 1 |
b |
7 |
| 2 |
d |
8 |
print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))
key data_left data_right
0 b 4 7
1 b 5 7
2 b 4 7
3 a 3 8
4 a 4 8
5 a 5 8
# 按索引连接
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'data2' : np.random.randint(0,10,3)}, index=['a', 'b', 'd'])
key data1 data2
0 b 4 8
1 b 0 8
6 b 1 8
2 a 6 1
4 a 4 1
5 a 2 1
df_obj1
|
key |
data1 |
| 0 |
b |
4 |
| 1 |
b |
0 |
| 2 |
a |
6 |
| 3 |
c |
1 |
| 4 |
a |
4 |
| 5 |
a |
2 |
| 6 |
b |
1 |
df_obj2
# 指以left的键为主键,按索引连接。
pd.merge(df_obj1, df_obj2, left_on='key', right_index=True)
|
key |
data1 |
data2 |
| 0 |
b |
4 |
8 |
| 1 |
b |
0 |
8 |
| 6 |
b |
1 |
8 |
| 2 |
a |
6 |
1 |
| 4 |
a |
4 |
1 |
| 5 |
a |
2 |
1 |
pd.concat()方法
类似于np.concat,连接数组,这里则是连接dataframe。
df1 = pd.DataFrame(np.arange(6).reshape(3,2),index=list('abc'),columns=['one','two'])
df2 = pd.DataFrame(np.arange(4).reshape(2,2)+5,index=list('ac'),columns=['three','four'])
df1
|
one |
two |
| a |
0 |
1 |
| b |
2 |
3 |
| c |
4 |
5 |
df2
## 默认连接方式为外连接,也就是所谓的并集。
pd.concat([df1,df2])
|
one |
two |
three |
four |
| a |
0.0 |
1.0 |
NaN |
NaN |
| b |
2.0 |
3.0 |
NaN |
NaN |
| c |
4.0 |
5.0 |
NaN |
NaN |
| a |
NaN |
NaN |
5.0 |
6.0 |
| c |
NaN |
NaN |
7.0 |
8.0 |
## 当然亦如之前的方法,都可以指定参数axis,这便类似于上面的操作。merge()方法
pd.concat([df1,df2],axis=1)
|
one |
two |
three |
four |
| a |
0 |
1 |
5.0 |
6.0 |
| b |
2 |
3 |
NaN |
NaN |
| c |
4 |
5 |
7.0 |
8.0 |
## 同样也可以指定连接方式 比如'inner'内连接(交集)
pd.concat([df1,df2],axis=1,join='inner')
|
one |
two |
three |
four |
| a |
0 |
1 |
5 |
6 |
| c |
4 |
5 |
7 |
8 |
数据的重塑
# 1. 将列索引转化为行索引:stack方法
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
stacked = df_obj.stack()
data1 data2
0 5 3
1 7 4
2 5 7
3 7 2
4 9 5
0 data1 5
data2 3
1 data1 7
data2 4
2 data1 5
data2 7
3 data1 7
data2 2
4 data1 9
data2 5
dtype: int32
df_obj
|
data1 |
data2 |
| 0 |
5 |
3 |
| 1 |
7 |
4 |
| 2 |
5 |
7 |
| 3 |
7 |
2 |
| 4 |
9 |
5 |
stacked
0 data1 5
data2 3
1 data1 7
data2 4
2 data1 5
data2 7
3 data1 7
data2 2
4 data1 9
data2 5
dtype: int32
如上,数据索引变成了层级索引。
print(type(df_obj))
# 可以看到数据格式发生了变化,从dataframe转化到了series
print(type(stacked))
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.series.Series'>
# 2. 将层级索引展为行索引unstack()方法
stacked.unstack()
|
data1 |
data2 |
| 0 |
5 |
3 |
| 1 |
7 |
4 |
| 2 |
5 |
7 |
| 3 |
7 |
2 |
| 4 |
9 |
5 |
整体再来整理一下。
为什么要进行数据清洗?是为了后续的数据分析,建模等操作的方便执行。
数据清洗在数据分析工作的哪一步?在数据分析工作前,为数据分析,模型服务。
数据清洗的流程?
分为几大类:
1. 进行缺失值处理
2. 进行重复值处理
3. 进行数据格式转化
4. 进行数据合并
ok,今天到这里了,本人不准备专门为时间序列结构出一篇博客,所以打算直接将它渗透到后期的实战中,在实战之前还需要补充一些统计学的知识,感谢大家的关注。同学习python的同学可以博主微信,有问题直接交流。



 京公网安备 11010502036488号
京公网安备 11010502036488号