想回老家的潜伏者躺平又起来了
想回老家的潜伏者躺平又起来了
未归档
《强化学习》 DP动态规划
全部文章
未归档
Git(1)
Lasso(1)
Linux(1)
Python(2)
Scala(7)
SVM(1)
TensorFlow(3)
其他(1)
图表示学习(1)
工具介绍(1)
强化学习(1)
推荐系统(1)
机器学习(8)
深度学习(2)
聚类和EM算法(1)
归档
标签
去牛客网
登录
/
注册
《强化学习》 DP动态规划
825 浏览
0 回复
2018-05-30
想回老家的潜伏者躺平又起来了
+关注
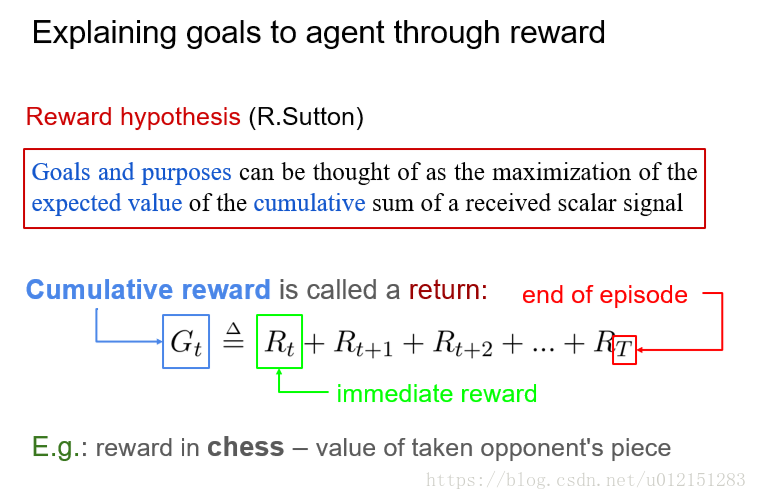
奖赏设计
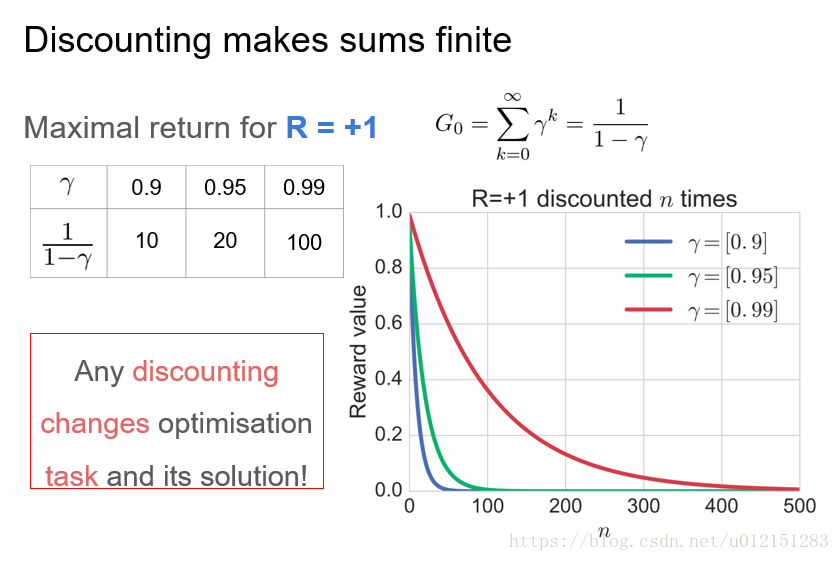
累计奖赏和折扣累计奖赏
数学上看,折扣奖赏机制可以将累计回报转化为递推的形式:
G
t
=
R
t
+
γ
(
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
)
=
R
t
+
γ
G
t
+
1
G
t
=
R
t
+
γ
(
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
)
=
R
t
+
γ
G
t
+
1
折扣是一种固定效应模型
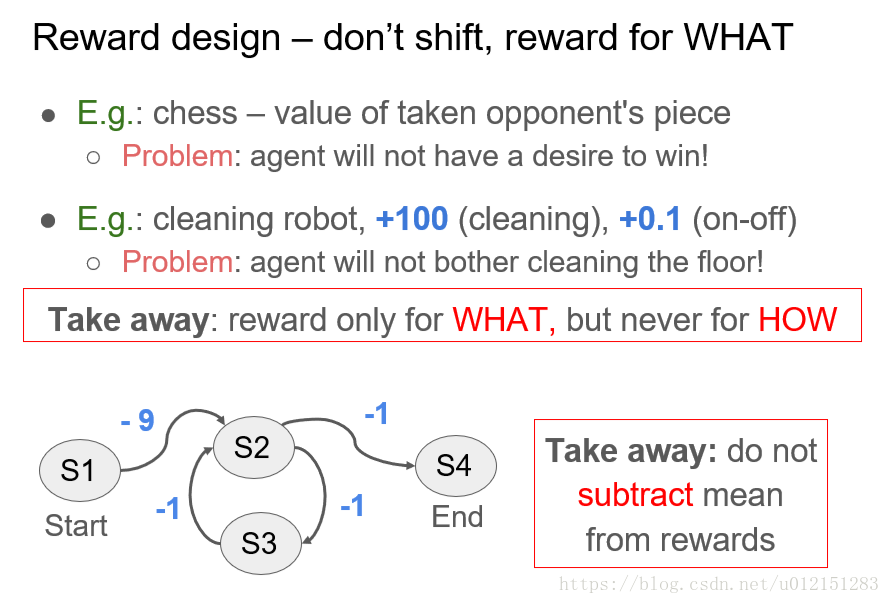
奖赏设计:不要平移,奖励做什么而不是怎么做
奖赏设计:缩放,塑形
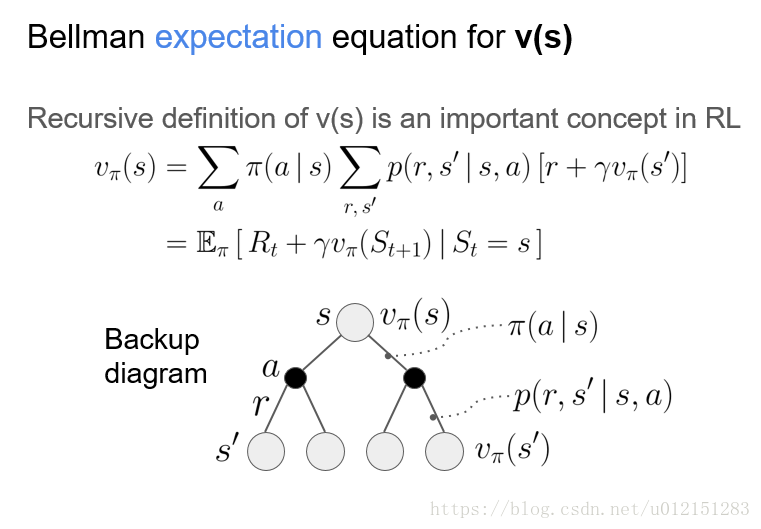
贝尔曼等式
状态值函数
值函数的贝尔曼期望等式
动作值函数
两者关系
动作值函数的贝尔曼期望等式
衡量策略优劣
贝尔曼最优等式
广义策略迭代GPI
策略评估
策略改进
GPI
策略迭代
值迭代
对比
举报
收藏
赞
评论加载中...

















 牛客博客,记录你的成长
牛客博客,记录你的成长




 京公网安备 11010502036488号
京公网安备 11010502036488号