


前言
最近做了一个python3作业题目,涉及到:
- 网页爬虫
- 网页中文文字提取
- 建立文字索引
- 关键词搜索
涉及到的库有:
- 爬虫库:requests
- 解析库:xpath
- 正则:re
- 分词库:jieba
- …
放出代码方便大家快速参考,实现一个小demo。
题目描述
搜索引擎的设计与实现
- 输入:腾讯体育的页面链接,以列表的方式作为输入,数量不定,例如:
["http://fiba.qq.com/a/20190420/001968.htm",
"http://sports.qq.com/a/20190424/000181.htm",
"http://sports.qq.com/a/20190423/007933.htm",
"http://new.qq.com/omn/SPO2019042400075107"]
-
过程:网络爬虫,页面分析、中文提取分析、建立索引,要求应用教材中的第三方库,中间过程在内存中完成,输出该过程的运行时间;
-
检索:提示输入一个关键词进行检索;
-
输出:输入的链接列表的按照关键词的出现频率由高到低排序输出,并以JSON格式输出词频信息等辅助信息;未出现关键词的文档链接不输出,最后输出检索时间,例如:
1 "http:xxxxxx.htm" 3
2 "https:xxxx.htm" 2
3 "https:xxxxx.htm" 1
代码
代码实现的主要步骤是:
- 网页爬虫:
crawler函数 - 网页文本元素清洗:清理掉多余的英文字符和标签,
bs4_page_clean函数 - 用正则提取中文:
re_chinese函数 - 使用dict保存每个网页的中文字和词,做索引:
jieba_create_index函数 - 输入关键词进行搜索:
search函数
import requests
from bs4 import BeautifulSoup
import json
import re
import jieba
import time
USER_AGENT = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) '
'Chrome/20.0.1092.0 Safari/536.6'}
URL_TIMEOUT = 10
SLEEP_TIME = 2
# dict_result格式:{"1":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# "2":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# }
dict_result = {}
# dict_search格式:[
# [url, count]
# [url, count]
# ]
list_search_result = []
def crawler(list_URL):
for i, url in enumerate(list_URL):
print("网页爬取:", url, "...")
page = requests.get(url, headers=USER_AGENT, timeout=URL_TIMEOUT)
page.encoding = page.apparent_encoding # 防止编码解析错误
result_clean_page = bs4_page_clean(page)
result_chinese = re_chinese(result_clean_page)
# print("网页中文内容:", result_chinese)
dict_result[i + 1] = {"url": url, "word": jieba_create_index(result_chinese)}
print("爬虫休眠中...")
time.sleep(SLEEP_TIME)
def bs4_page_clean(page):
print("正则表达式:清除网页标签等无关信息...")
soup = BeautifulSoup(page.text, "html.parser")
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
reg1 = re.compile("<[^>]*>")
content = reg1.sub('', soup.prettify())
return str(content)
def re_chinese(content):
print("正则表达式:提取中文...")
pattern = re.compile(u'[\u1100-\uFFFD]+?')
result = pattern.findall(content)
return ''.join(result)
def jieba_create_index(string):
list_word = jieba.lcut_for_search(string)
dict_word_temp = {}
for word in list_word:
if word in dict_word_temp:
dict_word_temp[word] += 1
else:
dict_word_temp[word] = 1
return dict_word_temp
def search(string):
for k, v in dict_result.items():
if string in v["word"]:
list_search_result.append([v["url"], v["word"][string]])
# 使用词频对列表进行排序
list_search_result.sort(key=lambda x: x[1], reverse=True)
if __name__ == "__main__":
list_URL_sport = input("请输入网址列表:")
list_URL_sport = list_URL_sport.split(",")
print(list_URL_sport)
# 删除输入的网页双引号
for i in range(len(list_URL_sport)):
list_URL_sport[i] = list_URL_sport[i][1:-1]
print(list_URL_sport)
# list_URL_sport = ["http://fiba.qq.com/a/20190420/001968.htm",
# "http://sports.qq.com/a/20190424/000181.htm",
# "http://sports.qq.com/a/20190423/007933.htm",
# "http://new.qq.com/omn/SPO2019042400075107"]
time_start_crawler = time.time()
crawler(list_URL_sport)
time_end_crawler = time.time()
print("网页爬取和分析时间:", time_end_crawler - time_start_crawler)
word = input("请输入查询的关键词:")
time_start_search = time.time()
search(word)
time_end_search = time.time()
print("检索时间:", time_end_search - time_start_search)
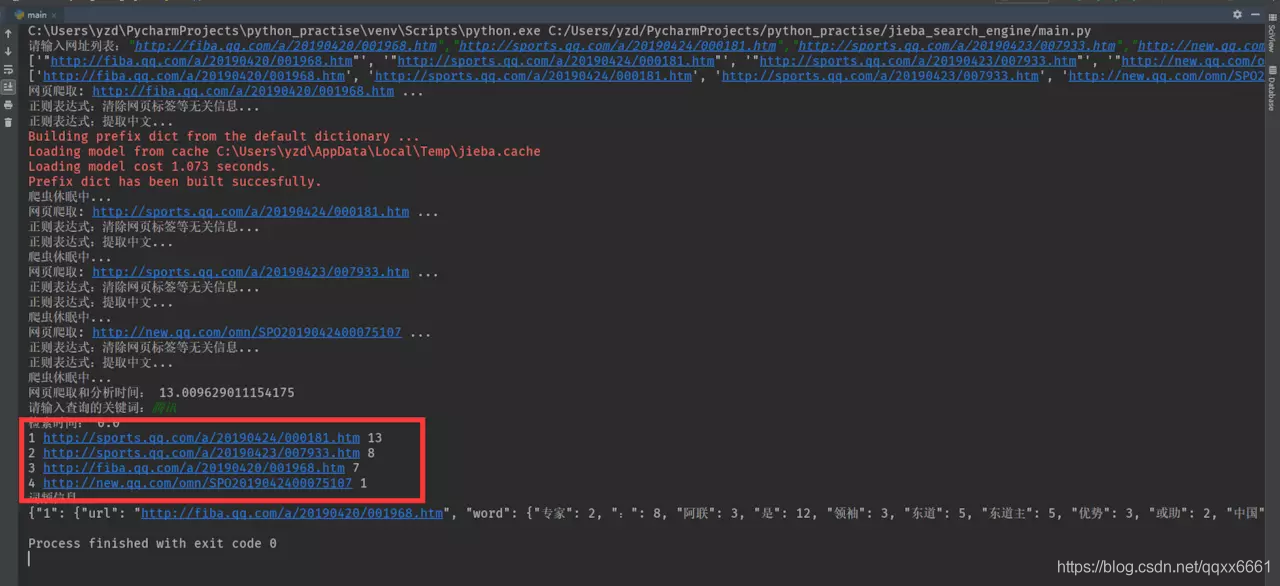
for i, row in enumerate(list_search_result):
print(i+1, row[0], row[1])
print("词频信息:")
print(json.dumps(dict_result, ensure_ascii=False))
运行结果
关注我
我目前是一名后端开发工程师。主要关注后端开发,数据安全,网络爬虫,物联网,边缘计算等方向。
微信:yangzd1102
Github:@qqxx6661
个人博客:
- CSDN:@Rude3Knife
- 知乎:@Zhendong
- 简书:@蛮三刀把刀
- 掘金:@蛮三刀把刀
原创博客主要内容
- Java知识点复习全手册
- Leetcode算法题解析
- 剑指offer算法题解析
- SpringCloud菜鸟入门实战系列
- SpringBoot菜鸟入门实战系列
- Python爬虫相关技术文章
- 后端开发相关技术文章
个人公众号:Rude3Knife

如果文章对你有帮助,不妨收藏起来并转发给您的朋友们~

 京公网安备 11010502036488号
京公网安备 11010502036488号