

一. 图的概念
1.定义
某类具体事物(顶点)和这些事物之间的联系(边),由顶点(vertex)和边(edge)组成, 顶点的集合V,边的集合E,图记为G = (V,E)
2.分类
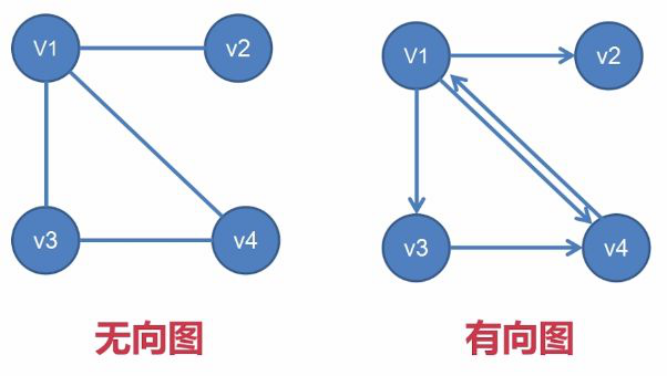
1、无向图 Def:边没有指定方向的图
2、有向图 Def:边具有指定方向的图 (有向图中的边又称为弧,起点称为弧头,终点称为 弧尾)
3.带权图 Def: 边上带有权值的图。(不同问题中,权值意义不同,可以是距离、时间、价格、代价等不同属性)

3.无向图的术语
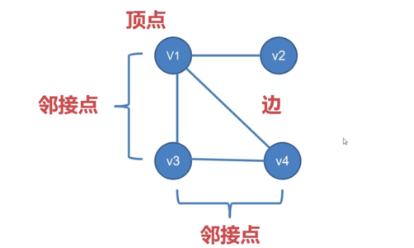
两个顶点之间如果有边连接,那么就视为两个顶点相邻。
路径:相邻顶点的序列。
圈:起点和终点重合的路径。
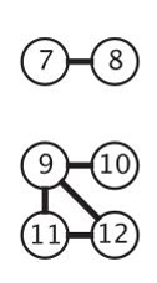
连通图:任意两点之间都有路径连接的图。
度:顶点连接的边数叫做这个顶点的度。
树:没有圈的连通图。
森林:没有圈的非连通图。
连通图 非连通图
4.有向图的术语
在有向图中,边是单向的:每条边所连接的两个顶点是一个有序对,他们的邻接性是单向的。
有向路径:相邻顶点的序列。
有向环:一条至少含有一条边且起点和终点相同的有向路径。
有向无环图(DAG):没有环的有向图。
度:一个顶点的入度与出度之和称为该顶点的度。
1)入度:以顶点为弧头的边的数目称为该顶点的入度
2)出度:以顶点为弧尾的边的数目称为该顶点的出度
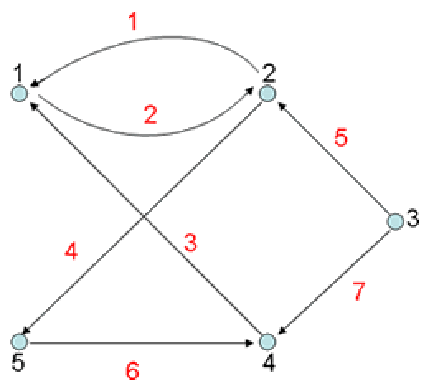
eg.
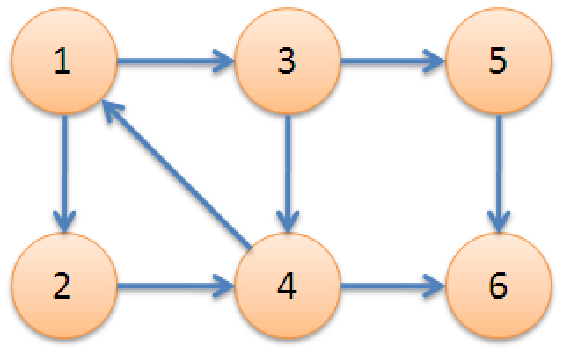
1->3->5->6 :有向路径 1->3->4->1 :有向环 (3、4、5、6) :无环有向图
节点1的度:3 节点1的入度:1 节点1的出度:2
二.图的表示
引入:如何用计算机来存储图的信息(顶点、边),这是图的存储结构要解决的问题?

1、邻接矩阵
对于一个有V的顶点的图而言,可以使用V*V的二维数组表示。G[i][j] 表示的是顶点i与顶点j的关系。
如果顶点i和顶点j之间 有边相连, G[i][j]=1
如果顶点i和顶点j之间 无边相连, G[i][j]=0
对于无向图:G[i][j]=G[j][i]
在带权图中,如果在边不存在的情况下,将G[i][j]设置为0,则无法与权值为0的情况分开,因此选择较大的常数INF即可。
邻接矩阵的优点:可以在常数时间内判断两点之间是否有边存在。
邻接矩阵的缺点:表示稀疏图时,浪费大量内存空间。表示稠密图还是很划算。
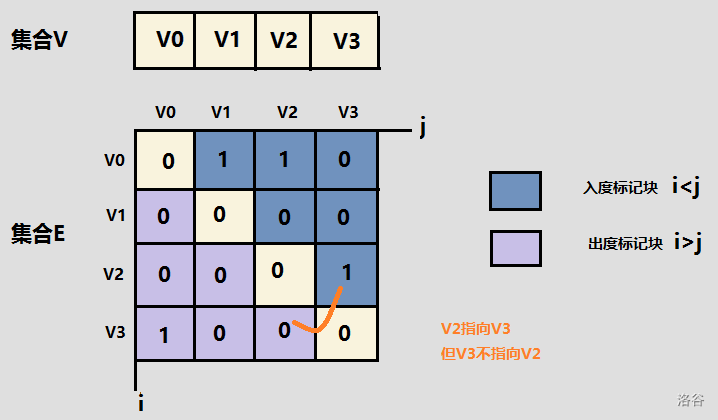
eg. 邻接矩阵存储图
code
#include<bits/stdc++.h>
using namespace std;
int a[1005][1005];
int main(){
int n,m;
scanf("%d%d",&n,&m);
int u,v;
for(int i=1;i<=m;i++){
scanf("%d%d",&u,&v);
a[u][v]=a[v][u]=1;
}
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(a[i][j])
printf("%d ",j);
}
printf("\n");
}
return 0;
}2、邻接表
通过把“从顶点0出发有到顶点2,3,5的边”这样的信息保存在链表中来表示图。
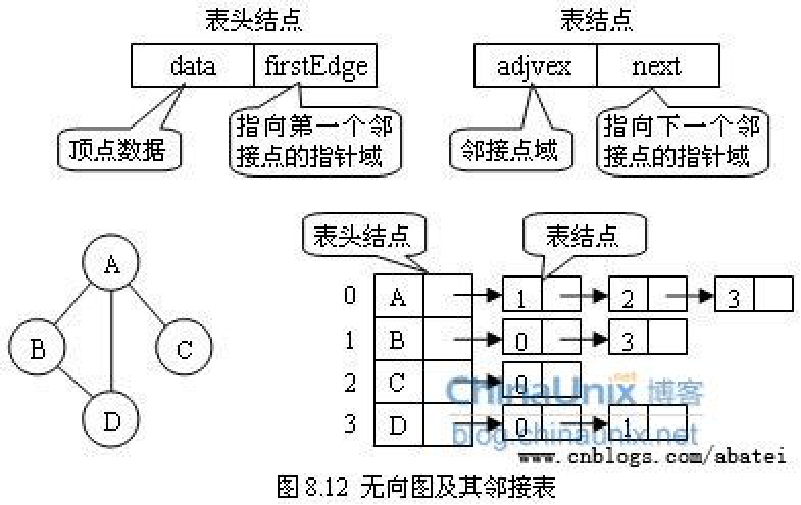
出边表的表结点存放的是从表头结点出发的有向边所指的尾顶点
入边表的表结点存放的则是指向表头结点的某个头顶点
带权图的邻接表 :在表结点中增加一个存放权的字段
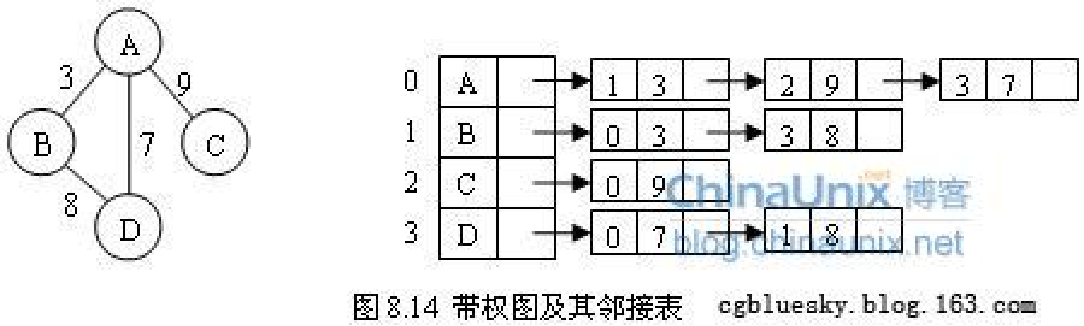
eg.
将如下的图利用邻接表进行表示,并输出每个顶点的度。
Code(伪)
#include<vector> //存边(编号和边权) struct edge{ int v,w; edge(){} //构造函数 edge(int V,int W){ v=V; w=W; } }; vector<edge> G[maxn];void addEdge(int u,int v,int w){ G[u].push_back(edge(v,w)); }
for(int i=1;i<=N;++i){ int u,v,w; cin>>u>>v>>w; addEdge(u,v,w); addEdge(v,u,w); }
3.链式前向星
如果说邻接表是不好写但效率好,邻接矩阵是好写但效率低的话,前向星就是一个相对中庸的数据结构。前向星固然好写,但效率并不高。而在优化为链式前向星后,效率也得到了较大的提升。虽然说,世界上对链式前向星的使用并不是很广泛,但在不愿意写复杂的邻接表的情况下,链式前向星也是一个很优秀的数据结构。 ——摘自《百度百科》
链式前向星其实就是静态建立的邻接表,时间效率为O(m),空间效率也为O(m)。遍历效率也为O(m)。
对于下面的数据,第一行5个顶点,7条边。接下来是边的起点,终点和权值。也就是边1 -> 2 权值为1。
样例
5 7
1 2 1
2 3 2
3 4 3
1 3 4
4 1 5
1 5 6链式前向星存的是以【1,n】为起点的边的集合,对于上面的数据输出就是:
1 //以1为起点的边的集合 1 5 6 1 3 4 1 2 12 //以2为起点的边的集合 2 3 2
3 //以3为起点的边的集合 3 4 3
4 //以4为起点的边的集合 4 5 7 4 1 5
5 //以5为起点的边不存在
由此可见对于每一个节点,输出的顺序为输入时的逆序
我们先对上面的7条边进行编号第一条边是0以此类推编号【0~6】,然后我们要知道两个变量的含义:
- Next:表示与这个边起点相同的上一条边的编号。
- head[ i ]数组,表示以 i 为起点的最后一条边的编号。
加边函数是这样的:
void add_edge(int u, int v, int w)//加边,u起点,v终点,w边权
{
edge[cnt].to = v; //终点
edge[cnt].w = w; //权值
edge[cnt].next = head[u];//以u为起点上一条边的编号,也就是与这个边起点相同的上一条边的编号
head[u] = cnt++;//更新以u为起点上一条边的编号
}遍历函数是这样的:
for(int i = 1; i <= n; i++)//n个起点
{
cout << i << endl;
for(int j = head[i]; j != -1; j = edge[j].next)//遍历以i为起点的边
{
cout << i << " " << edge[j].to << " " << edge[j].w << endl;
}
cout << endl;
}第一层for循环是找每一个点,依次遍历以【1,n】为起点的边的集合。第二层for循环是遍历以 i 为起点的所有边,k首先等于head[ i ],注意head[ i ]中存的是以 i 为起点的最后一条边的编号。然后通过edge[ j ].next来找下一条边的编号。我们初始化head为-1,所以找到你最后一个边(也就是以 i 为起点的第一条边)时,你的edge[ j ].next为 -1做为终止条件。
Code
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1005;//点数最大值
int n, m, cnt;//n个点,m条边
struct Edge
{
int to, w, next;//终点,边权,同起点的上一条边的编号
}edge[maxn];//边集
int head[maxn];//head[i],表示以i为起点的第一条边在边集数组的位置(编号)
void init()//初始化
{
for (int i = 0; i <= n; i++) head[i] = -1;
cnt = 0;
}
void add_edge(int u, int v, int w)//加边,u起点,v终点,w边权
{
edge[cnt].to = v; //终点
edge[cnt].w = w; //权值
edge[cnt].next = head[u];//以u为起点上一条边的编号,也就是与这个边起点相同的上一条边的编号
head[u] = cnt++;//更新以u为起点上一条边的编号
}
int main()
{
cin >> n >> m;
int u, v, w;
init();//初始化
for (int i = 1; i <= m; i++)//输入m条边
{
cin >> u >> v >> w;
add_edge(u, v, w);//加边
/*
加双向边
add_edge(u, v, w);
add_edge(v, u, w);
*/
}
for (int i = 1; i <= n; i++)//n个起点
{
cout << i << endl;
for (int j = head[i]; j != -1; j = edge[j].next)//遍历以i为起点的边
{
cout << i << " " << edge[j].to << " " << edge[j].w << endl;
}
cout << endl;
}
return 0;
}
三.图的遍历
从图中的某个顶点出发,按某种方法对图中的所有顶点访问且仅访问一次。为了保证图中的顶点在遍历过程中仅访问一次,要为每一个顶点设置一个访问标志。
1.DFS
概念
深度优先搜索(Depth-First Search)遍历类似于树的先根遍历,是树的先根遍历的推广。假设初始状态是图中所有顶点未曾被访问,则深度优先搜索可从图中某
个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访
问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。 Code(邻接矩阵)
#include<bits/stdc++.h>
#define Maxn 205
using namespace std;
int n, m;
bool a[Maxn][Maxn], vis[Maxn];
void DFS(int i) {
cout << i << ' ';
vis[i] = 1;
for (int j = 1; j <= n; j++) {
if (a[i][j]) {
if (!vis[j]) {
vis[j] = 1;
DFS(j);
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
a[x][y] = 1;
}
for (int i = 1; i <= n; i++) {
if (!vis[i])
DFS(i);
}
return 0;
}2.BFS
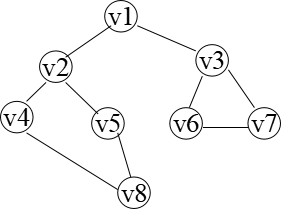
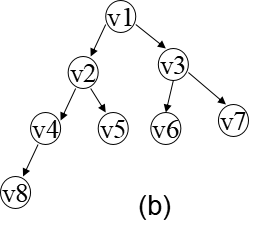
对(a)进行广度优先搜索 遍历的过程如图(b)所示, 得到的顶点访问序列为: v1->v2->v3->v4->v5->v6->v7->v8
概念
广度优先搜索(Breadth-First Search)遍历类似于树的按层次遍历的过程。
假设从图中某顶点v出发,在访问v之后依次访问v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接
点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的
顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程是以v为起始点,由近至远,依次访问和v有路径相通
且路径长度为1,2,…的顶点。Code
#include<bits/stdc++.h>
using namespace std;
int n,m;
int a[205][205],vis[205];
void bfs(int x){
queue<int> Q;
Q.push(x);
printf("%d ",x);
vis[x]=1;
while(!Q.empty()){
int now=Q.front();
Q.pop();
for(int i=1;i<=n;i++){
if(a[now][i]&&!vis[i]){
Q.push(i);
printf("%d ",i);
vis[i]=1;
}
}
}
}
int main() {
scanf("%d%d",&n,&m);
int u,v;
for(int i=1;i<=m;i++){
scanf("%d%d",&u,&v);
a[u][v]=a[v][u]=1;
}
int k;
scanf("%d",&k);
bfs(k);
return 0;
} 3.欧拉路径和欧拉回路
欧拉路是指存在这样一种图 , 可以从其中一点出发 , 不重复地走完其所有的边 . 如果欧拉路的起点与终点相同 则称之为欧拉回路
欧拉路存在的充要条件 : 图是连通的 ,因为若不连通不可能一次性遍历所有边。
对于无向图有且仅有两个点 ,与其相连的边数为奇数 ,其他点相连边数皆为偶数 ;对于两个奇数点 , 一个为起点 , 一个为终点 . 起点需要出去 ,终点需要进入 ,故其必然与奇数个边相连 .
对于有向图 除去起点和终点 , 所有点的出度与入度相等 。且起点出度比入度大 1。终点入度比出度大 1。 若起点终点出入度也相同 ,则称为欧拉回路。
可参见鸽巢原理
eg.一笔画问题
Code
#include <bits/stdc++.h>
using namespace std;
int g[1005][1005], ans[1005], num[1005], idx = 0, n, m, st = 1;
;
void dfs(int i) {
for (int j = 1; j <= n; j++) {
if (g[i][j]) {
g[i][j] = g[j][i] = 0;
dfs(j);
}
}
ans[++idx] = i;
}
int main() {
memset(g, 0, sizeof(g));
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++) {
int x, y;
scanf("%d%d", &x, &y);
g[x][y] = g[y][x] = 1;
num[x]++;
num[y]++;
}
for (int i = 1; i <= n; i++) {
if (num[i] % 2)
st = i;
}
dfs(st);
for (int i = 1; i <= idx; i++) {
printf("%d ", ans[i]);
}
return 0;
}4.哈密顿路
哈密顿路径也称作哈密顿链,指在一个图中沿边访问每个顶点恰好一次的路径。
(待填充……)
四.最短路问题
最短路径问题是图论研究中的一个经典算法问题, 旨在寻找图(由结点和路径组成的)中两结点之间的最短路径。
1.Floyd
佛洛伊德是最简单的最短路径算法,可以计算图中任意两点间的最短路径。时间复杂度为O(N3),适用于出现负边权的情况。
算法描述:
(a)初始化:点u、v如果有边相连,则F[u][v]=w[u][v]
如果不相连,则
for(int k=1;k<=n;k++) {
for(int i=1;i<=n;i++) {
for(int j=1;j<=n;j++) {
F[i][j]=max(F[i][j],F[i][k]+F[k][j]);
}
}
}(c)算法结束:F[i][j]得出的就是任意起点i到任意终点j的最短路径。
疑问:为什么枚举中间点的循环k要放在最外层?
Answer
可以从一定不经过k点与一定经过k点的三维数组比较中推导出来
动态规划以”途径点集大小”为阶段?
决策需要枚举中转点,不妨考虑也以中转点集为阶段
F[k,i,j]表示”可以经过标号≤k的点中转时”从i到j的最短路
F[0,i,j]=W[i,j],W为前面定义的邻接矩阵
F[k,i,j]=min{F[k-1,i,j] , F[k-1,i,k]+F[k-1,k,j]},O(N^3)
k这一维空间可以省略,变成F[i,j]
就成为了我们平时常见的Floyd算法
由于k是DP的阶段循环,所以k循环必须要放在最外层多源最短路
2.Dijkstra
预备知识:松弛操作
原来用一根橡皮筋连接a,b两点,现在有一点k,使得a->k->b比a->b的距离更短,则把橡皮筋改为a->k->b,这样橡皮筋更加松弛。这样说或许不好理解,毕竟两点之间线段最短是常识。可以这样想,如果今天我要去罗马,有很多种选择。当然选择最短的路。但如果最短的那条路太堵了,还不如选远一点但不堵的呢,就可以试着转站。这就是带权的最短路问题。
if(dis[b]<dis[k]+w[k][b])
dis[b]=dis[k]+w[k][b]算法描述
设起点为S,dis[v] 表示从指定起点S到V的最短路径,pre[v] 为v的前驱

Code
#include <bits/stdc++.h>
using namespace std;
int n,m,s,t;
const int N =100001;
int dis[N];//从起始点到i的最短路
int vis[N];//是否确定最短路
struct edge {
int v,w;
};
struct node {
int u,dis;//下标,距离
bool operator<(const node &tmp)
const {
return dis>tmp.dis;//让还没有确定最短路的数以距离 从小到大,每一次选最小的作为松弛点
}
};
priority_queue<node> Q;
vector<edge> G[N];
int Dijkstra(int S,int T) {
memset(vis,0,sizeof(vis));
memset(dis,0x3f,sizeof(dis));
dis[S]=0;
Q.push((node){S,0});//将起点压入队列
while(!Q.empty()) {
int u=Q.top().u;//取出起点下标
Q.pop();
if(vis[u]) continue;//如果已经确定最短路径,continue
vis[u]=1;
int v,w,siz=G[u].size();
for(int i=0;i<siz;i++) {//枚举与u相邻的点
v=G[u][i].v,w=G[u][i].w;//取出与它相邻点下的标,与它的距离
if(dis[v]>dis[u]+w) {//将起点到此相邻点的距离 与将u作为起点到v的松弛点比较(进行松弛操作)
dis[v]=dis[u]+w;
Q.push((node){v,dis[v]}); //如果进行松弛操作,压入队列
}
}
}
return dis[T];
}
int main()
{
int u,v,w;
scanf("%d %d %d %d",&n,&m,&s,&t);
for(int i=0;i<m;i++) {
scanf("%d %d %d",&u,&v,&w);
G[u].push_back((edge){v,w});
G[v].push_back((edge){u,w});
}
cout<<Dijkstra(s,t);
return 0;
}

 京公网安备 11010502036488号
京公网安备 11010502036488号