

1. 摘要
本文的模型采用了 5 层的卷积,一些层后面还紧跟着最大池化层,和 3 层的全连接,最后是一个 1000 维的 softmax 来进行分类。
为了减少过拟合,在全连接层采取了 dropout,实验结果证明非常有效。
2. 数据集
ImageNet 数据集包含了超过 15,000,000 大约 22,000 类标记好的高分辨率图片,ILSVRC 包含 ImageNet 中 1000 类每类大约 1000 张图片,总共大约有 1,200,000 张训练图片,50,000 张验证图片和 150,000 张测试图片。由于之只有 ILSVRC-2010 的测试集标签可以获得,本文的大部分实验都是基于此数据集。
数据集中的图片分辨率各不相同,但是网络需要固定的输入维度,因此,作者将图片统一下采样到一个固定的分辨率 256×256。给定一个长方形的图片,先将较短的一边调整为 256,然后裁剪出中间的 256×256 区域作为训练数据。除了减去所有像素的均值,作者未作其它预处理。
3. 网络结构
3.1. ReLU
采取 ReLU 作为激活函数的深度卷积网络训连起来要比采取 Tanh 的快好几倍,因此作者采用 ReLU 作为激活函数。

3.2. 多 GPU 训练
单个 GTX 580 GPU 的显存只有 3 GB,限制了网络的最大容量,因此作者利用两个 GPU 并行计算来进行训练。其中,每个 GPU 上分配一半的神经元,而且两个 GPU 间只在特定的层才进行数据同步。
3.3. 局部响应归一化
尽管 ReLU 不会遇到输出饱和的问题,但是作者仍然发现局部响应归一化有助于网络的泛化。设定 ax,yi 为位置 (x,y) 处第 i 个卷积核的响应,那么归一化后的响应 bx,yi 为:
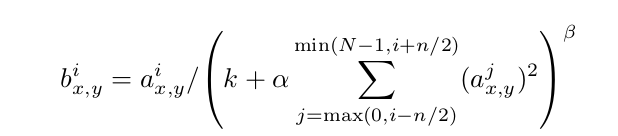
其中求和在相同空间位置的 n 个“相邻”内核映射上进行, N 是这一层卷积核的总数。这种响应归一化实现了一种横向抑制,这是受到真实神经元中发现的类型所启发,从而在使用不同内核计算的神经元输出之间产生大的竞争。其中, k,n,α,β 都是超参数,需要根据验证集来设定。采用局部响应归一化后,top-1 错误率和 top-5 错误率分别下降了1.4% 和 1.2%。
3.4. 重叠池化
传统的池化步长 s 和池化区域大小 z∗z 相等,即 s=z。在本文中,作者设定 s<z,这也就是重叠池化。通过采用 s=2,z=3,top-1 错误率和 top-5 错误率分别下降了 0.4% 和 0.3%。
3.5. 整体结构

第一层和第二层网络具有卷积、池化和局部归一化,第三四五层网络只有卷积
4. 减少过拟合
4.1. 数据增广
作者采取了两种方式来进行数据增广,扩充的图片是在 CPU 上进行的,同时 GPU 在进行上一个批次图片的训练,这两个过程并行进行,不引入额外的计算。
第一种方法是将图片进行平移和水平翻转,从 256×256 的图片中随机裁剪出 224×224 的区域以及它们的水平翻转作为训练图片,这使作者的训练数据扩大了 2048 倍。在测试的时候,从图片中裁出 5 个 224×224 小片(四角和中间)以及它们的水平翻转总共 10 张图片,然后对 10 个输出取平均来进行预测。
第二种方法是改变图片 RGB 通道的强度。在整个 ImageNet 训练集上对 RGB 通道的像素使用 PCA,然后为每张训练图片添加主成分的倍数,这个幅度正比于特征值和一个从零均值 0.1 标准差的高斯分布中产生的随机变量的乘积。
[IxyR,IxyG,IxyB]T=[p1,p2,p3][α1λ1,α2λ2,α3λ3]T
pi 和 λi 代表第 i 个特征值和特征向量, αi 是随机变量。对于一张训练图片,所有位置的像素共用同一组 αi,直到下次这张图片再被用来训练就再产生一个随机变量。该方案近似地捕获自然图像的重要特性,即,某个物体对于光照的强度和颜色的变化是不变的。 采用此方案后, top-1 错误率降低了 1% 以上。
4.2. Dropout
通过采取 Dropout,每次有一半的神经元被丢弃,它们因此就不再参与前向和后向过程。也即是每次的网络结构都是不一样的,但这些结构的权重是共享的。这个技术减少了神经元之间的互相依赖,因为某一个神经元并不能依赖其他神经元的出现,其他神经元可能随机被丢弃。因此,它被迫学习更强大的特征,这些特征与其它神经元的许多不同随机子集组合起来非常有用。
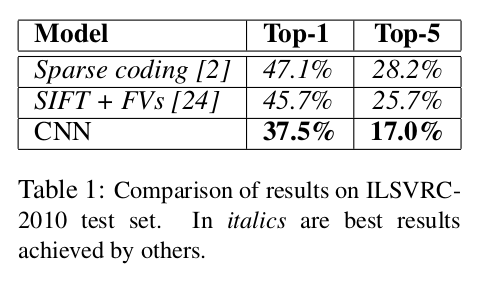
5. 实验结果

获取更多精彩,请关注「seniusen」!


 京公网安备 11010502036488号
京公网安备 11010502036488号