

# Java-lambda表达式
标签(空格分隔): Java
lambda表达式是Java8中添加的一个新特性,代替匿名内部类,可以极大的减少代码冗余,提高可读性,是Java的一个语法糖。下面针对lambda表达式,一步步讲述lambda表达式的一般写法,和简洁写法(方法引用),以及Java8提供的函数式接口和Stream,配合lambda表达式写出高效代码。
1. lambda表达式
1.1 lambda表达式语法
1.1.1 一般写法
格式:
(Type1 param1, Type2 param2, ..., TypeN paramN) -> {
statment1;
statment2;
//...
return statmentM;
} 示例:
// lambda表达式一般写法
Comparator<Integer> comp = (Integer i, Integer j) -> {
return i < j;
}); 这是lambda表达式的一般写法,在一些情况下是可以继续简化,简化见下文。
1.1.2 单参数写法
格式:
param1 -> {
statment1;
statment2;
//...
return statmentM;
} 示例:
ActionListner listener = event -> {
System.out.println(event);
}; 在表达式的参数单个的时候,就可以忽略小括号。
一般来讲,参数类型是可以通过返回值推导出来的,故一般省略。
Comparator<String> comp = (first, second) -> {
return first.length() - second.length();
}; 在表达式的参数零个的时候,不可以忽略小括号。
Runnable msg = () -> {
for (int i = 100; i >= 0; --i)
System.out.println(i);
}; 1.1.3 单语句写法
格式:
param1 -> statment
示例:
Comparator<String> comp = (first, second) -> first.length() - second.length();
当lambda表达式只包含一条语句时,可以省略花括号,return关键字和结尾分号。
1.1.4 lambda表达式的变量
和匿名内部类一样,lambda表达式内部的变量有相应的规则:
如果是在表达式内部创建那么可以随意改动,但是不能和外部有同名的局部变量。
lambda表达式可以访问外部变量,但是外部变量必须不可变(final),即表达式内部不能改变它的值,外部也不能改变它的值,必须用final关键字来修饰lambda表达式访问的外部变量,java8对这个限制做了优化,可以不用显示使用final修饰,但是编译器隐式当成final来处理。
void countDown(int start, int delay) {
ActionListner listener = event -> {
start--; // compile-error
System.out.println(start);
};
} 1.2 lambda表达式的this对象
this关键字指的是表达式所在的那个类的对象,即表达式外部对象,而非表达式本身。
public class Test {
public void whatThis(){
List<String> proStrs = Arrays.asList(new String[]{"Ni"});
List<String> execStrs = proStrs.stream().map(str -> {
System.out.println(this.getClass().getName());
return str.toLowerCase();
}).collect(Collectors.toList());
execStrs.forEach(System.out::println);
}
public static void main(String[] args) {
Test wt = new Test();
wt.whatThis();
}
}
// 输出:
// lambda.Test
// Ni 2. 方法引用与构造器引用
在上述lambda表达式的基础上进一步简化写法
2.1 方法引用
object::instanceMethod
ClassName::staticMethod
ClassName::instanceMethod
前两种方式的写法类似,等同于把lambda表达式的参数当作object.instanceMethod或ClassName.staticMethod的参数:
// lambda表达式一般写法: Predicate<String> pre = str -> System.out.println(str); // object::instanceMethod ...(x, y) -> Math.max(x, y); // ClassName::staticMethod // 方法引用写法: Predicate<String> pre = System.out::println; ...Math::max;
最后一种的方式,等同于把lambda表达式的第一个参数当作instanceMethod的目标对象,其它剩余参数当成该方法的参数:
// lambda表达式一般写法: ...x -> x.toLowerCase(); // 方法引用写法: ...String::toLowerCas
2.2 构造器引用
ClassName::new
ClassName[]::new
等同于把lambda表达式的参数当成ClassName构造器的参数:
// lambda表达式一般写法: ...x->new BigDecimal(x); ...x->new BigDecimal[x]; // 构造器引用 ...BigDecimal::new ...BigDecimal[]::new
3. 函数式接口
lambda表达式的作用在于封装代码块,并可以延迟执行,而lambda表达式使用条件则在于一种接口:函数式接口。
对于只有一个抽象方法的接口,需要这种接口的对象时,就可以提供一个lambda表达式,这种接口就叫做函数式接口。
Java封装了函数式接口在java.util.Function包中,以下是常用的函数式接口:
| 函数式接口 | 参数类型 | 返回类型 | 抽象方法名 | 描述 |
|---|---|---|---|---|
| Runnable | 无 | void | run | 作为无参数或返回值的动作进行 |
| Supplier | 无 | T | get | 提供一个无参数有返回值T的函数 |
| Consumer | T | void | accept | 处理一个参数T无返回值的函数 |
| BiConsumer<T,U> | T,U | void | accept | 处理两个参数T、U无返回值的函数 |
| Function<T,R> | T | R | apply | 处理一个参数T一个返回值R的函数 |
| BiFunction<T,U,R> | T,U | R | apply | 处理两个参数T,U一个返回值R的函数 |
| UnaryOperator | T | T | apply | 类型T上的一元操作符 |
| BinaryOperator | T,T | T | apply | 类型T上的二元操作符 |
| Predicate | T | boolean | test | 布尔值函数 |
| BiPredicate<T,U> | T,U | boolean | test | 两个参数的布尔值函数 |
4. Stream
4.1 Stream概念
Stream和Function一样,都是Java8提供的,配合lambda表达式来简化代码结构。
Stream是元素的集合,这点让Stream看起来用些类似Iterator,但是是装饰后的Iterator,可以手动创建Stream或从集合中生成Stream,可以对Stream进行转换从而生成新的Stream,可以支持顺序和并行的对原Stream进行汇聚的操作。
以上的几个Stream的用法可以用下图来表示:

4.2 Stream的创建
4.2.1 通过其静态方法创建
通过Stream接口的静态工厂方法(Java8里接口可以带静态方法)。
1)of方法
两个重载方法:一个接受变长参数,一个接口单一值
Stream<Integer> integerStream = Stream.of(1, 2, 3, 5);
Stream<String> stringStream = Stream.of("taobao"); 2)generator方法
生成一个无限长度的Stream,其元素的生成是通过给定的Supplier(这个接口可以看成一个对象的工厂,每次调用返回一个给定类型的对象)
这个无限长度Stream是懒加载,一般这种无限长度的Stream都会配合Stream的limit()方法来用。
// 内部类写法
Stream.generate(new Supplier<Double>() {
@Override
public Double get() {
return Math.random();
}
});
// 方法引用写法
Stream.generate(Math::random); 3) iterate方法
生成无限长度的Stream,和generator不同的是,其元素的生成是重复对给定的种子值(seed)调用用户指定函数来生成的。其中包含的元素可以认为是:seed,f(seed),f(f(seed))无限循环。
Stream.iterate(1, item -> item + 1).limit(10).forEach(System.out::println);
4.2.2 通过Collectin子类获取
Collection接口有一个stream方法,所以其所有子类都都可以获取对应的Stream对象。
public interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
} 4.3 Stream的转换
转换Stream其实就是把一个Stream通过某些行为转换成一个新的Stream,下面介绍常用转换的方法:
1)distinct
对于Stream中包含的元素进行去重操作(去重逻辑依赖元素的equals方法)

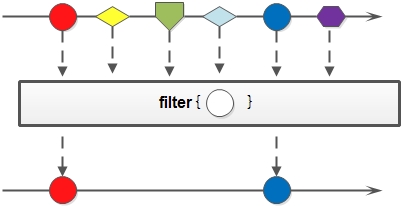
2)filter
对于Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素
3)map
对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗。
4)flatMap
原先的Stream中的每个元素都是一个Stream对象,经过转换得到的是每个Stream对象集合在一个Stream对象中,包含了所有元素。
Stream<List<Integer>> inputStream = Stream.of( Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6) ); Stream<Integer> outputStream = inputStream. flatMap((childList) -> childList.stream());
flatMap 把inputStream将最底层元素抽出来放到一起,最终output的新Stream都是直接的数字。
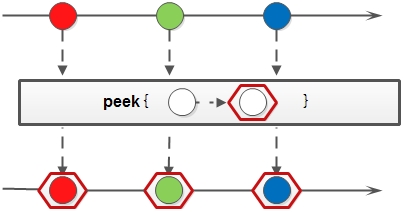
5)peek
生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer实例),新Stream每个元素被消费的时候都会执行给定的消费函数。
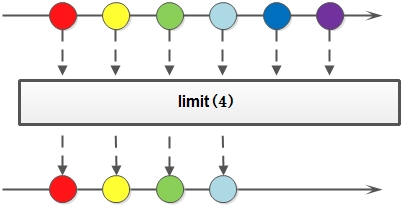
6)limit
对一个Stream进行截断操作获取前N个元素,如果原Stream中包含的元素个数小于N,那就获取其所有的元素
7)skip
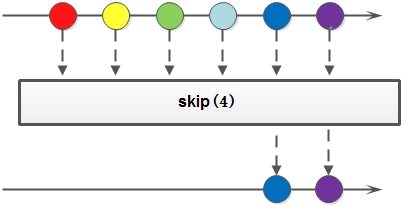
返回一个丢弃原Stream的前N个元素后剩下元素组成的新Stream,如果原Stream中包含的元素个数小于N,那么返回空Stream
关于时间复杂度的讨论:
对于一个Stream进行多次转换操作,每次都对Stream的每个元素进行转换,而且是执行多次,这样时间复杂度就是O(n^2)?其实不是这样的,转换操作都是lazy的,多个转换操作只会在汇聚操作时候融合起来,一次循环完成,是O(n)的。
4.4 Stream的汇聚
汇聚操作接受一个元素序列为输入,反复使用某个合并操作(转换操作是lazy的),把序列中的元素合并成一个汇总的结果。
汇聚操作分成两种:
- 可变汇聚:把输入的元素们累积到一个可变的容器中,比如累积到Collection或者StringBuilder;
- 其他汇聚:除可变汇聚外,一般都不是通过反复修改某个可变对象,而是通过把前一次的汇聚结果当成下一次的入参,反复如此。比如reduce,count,allMatch;
4.4.1 可变汇聚
可变汇聚对应的只有一个方法:collect,它可以把Stream中的要有元素收集到一个Collection中,一种方法是直接利用collect方法来进行构造,另外一种是Collectors工具类的toList()方法。
1)collect的函数构造:
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);
其中三个参数的定义:supplier是一个工厂函数,用来生成一个新的容器;accumulator也是一个函数,用来把Stream中的元素添加到结果容器中;combiner还是一个函数,用来把中间状态的多个结果容器合并成为一个(并发的时候会用到)。
List<Integer> nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10); List<Integer> numsWithoutNull = nums.stream().filter(num -> num != null). collect(() -> new ArrayList<Integer>(), (list, item) -> list.add(item), (list1, list2) -> list1.addAll(list2));
对Lis过滤掉全部的null,然后把剩下的元素收集到一个新的List中。collect的第一个函数生成一个新的ArrayList实例;第二个函数接受两个参数,第一个是前面生成的ArrayList对象,第二个是stream中包含的元素,函数体就是把stream中的元素加入ArrayList对象中;第二个函数被反复调用直到原stream的元素被消费完毕;
第三个函数也是接受两个参数,这两个都是ArrayList类型的,函数体就是把第二个ArrayList全部加入到第一个中;
2)Collections.toList()
List<Integer> numsWithoutNull = nums.stream().filter(num -> num != null). collect(Collectors.toList());
4.4.2 其它汇聚
其它汇聚有reduce、count等等
1)reduce
Optional<T> reduce(BinaryOperator<T> accumulator); T reduce(T identity, BinaryOperator<T> accumulator);
第一个重载方法接受一个BinaryOperator对象,第二个重载方法比第一个多了一个参数,这个参数是设置操作的初始值的。下面分别讲这两个重载方法。
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce((sum, item) -> sum + item).get()); reduce方法接受一个函数,这个函数有两个参数,第一个参数是上次函数执行的返回值(也称为中间结果),第二个参数是stream中的元素,这个函数把这两个值相加,得到的和会被赋值给下次执行这个函数的第一个参数。
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce(0, (sum, item) -> sum + item)); 第二个重载方法和第一个重载方法不同的是:它允许用户提供一个循环计算的初始值,如果Stream为空,就直接返回该值。而且这个方法不会返回Optional,因为其不会出现null值。
3)其它
- count: 获取Stream中元素的个数。比较简单,这里就直接给出例子,不做解释了。
- allMatch:是不是Stream中的所有元素都满足给定的匹配条件
- anyMatch:Stream中是否存在任何一个元素满足匹配条件
- findFirst: 返回Stream中的第一个元素,如果Stream为空,返回空Optional
- noneMatch:是不是Stream中的所有元素都不满足给定的匹配条件
- max和min:使用给定的比较器(Operator),返回Stream中的最大|最小值
5. 参考资料
- Cay S. Horstmann.JAVA核心技术(卷1)[M]. 机械工业出版社, 2008.
- Java8初体验(一)lambda表达式语法

 京公网安备 11010502036488号
京公网安备 11010502036488号