


文章目录
第三章、多进程——操作系统最核心的视图
一、CPU的工作机理和非多进程的缺陷
1.CPU的工作机理
CPU的工作机理是不断地取址执行
我们将需要执行的指令放入内存中,然后用PC指向该段内存的首地址,CPU将自动开始取址——执行的过程
2.非多进程CPU的缺陷
指令在CPU上只可以顺序进行,可以看作许多指令依次排列在队列中等待当前程序执行完毕,这样看起来有条不紊,但是实际上效率很低,对CPU的利用率也是极低的。
因为,一条I/O指令的执行时间约等于一百万条计算指令的执行时间,而如果顺序执行指令的话,在CPU执行I/O指令的时候,就必须等待I/O指令执行完毕,如果一段程序中有一百万条计算指令和一条,那还是可以接受的,这样的CPU的利用率还是50%,但是如果每数条指令就会有一条I/O,那么CPU的利用率几乎为0,CPU是在漫长的等待中度过的。
二、并发和多进程——提高CPU利用率的关键
1.什么是并发
并发就是多个程序同时开始进行,并且他们可以交替进行,当一个程序遇到I/0时,就跳转到另一条程序执行,当这条程序又遇到I/O时,再返回源程序执行。
当然在这种跳转中,我们需要保存源程序的关键信息(寄存器的值)
这就引出了进程的概念
2.什么是进程
进程就是用来描述一个程序以及其执行过程中的信息的概念
进程是描述程序以及反应程序执行信息的数据结构的总和
这个数据结构叫做进程控制块**(PCB)**
三、多进程视图
什么是多进程视图呢,CPU在执行的过程中,会产生许多的进程,这些进程组成的分支结构,就是多进程视图**(用户眼中的)**
上层应用每做一件事,如编译一个.c文件、浏览一个网页等,就会创建一个进程,但是shell进程不会退出,会一直执行,当一个进程执行完了以后,就退出掉。
当关机时,所有进程都会被杀死

源进程在wait()位置等待当前进程结束
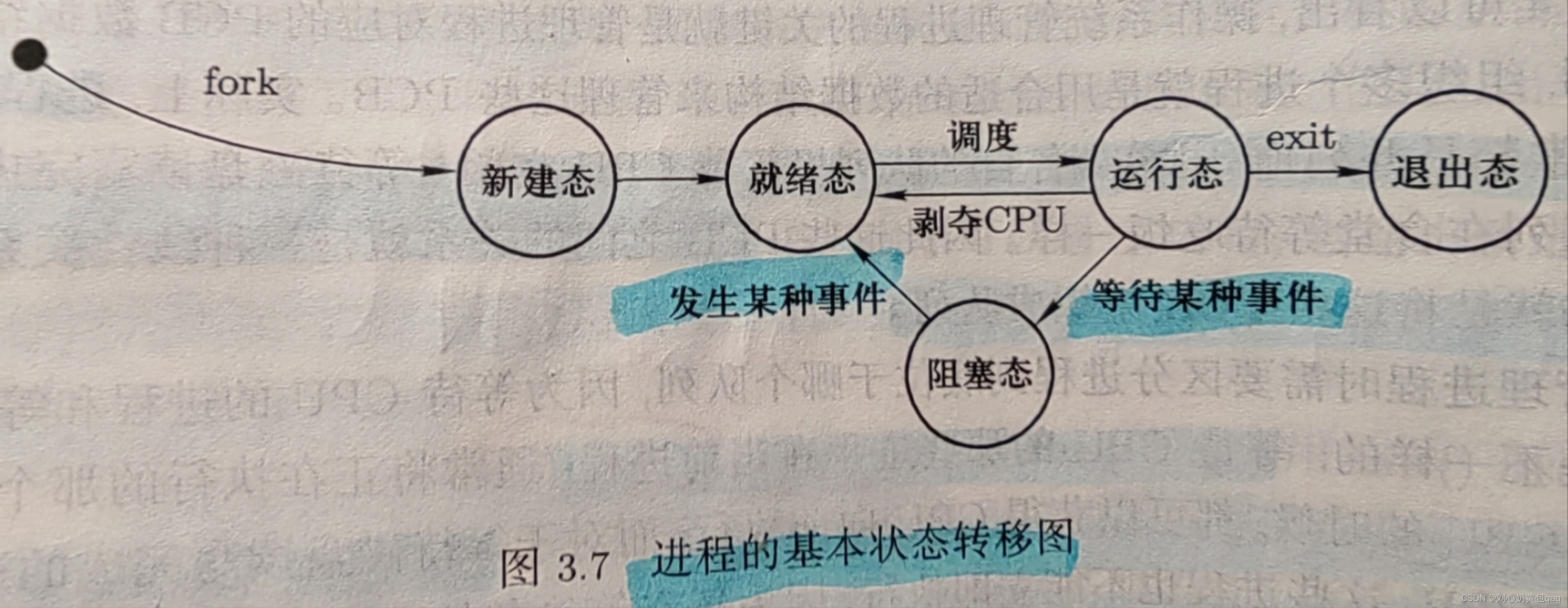
四、进程的状态
(1)运行态
即正在执行的进程状态
(2)就绪态
已经具备了所有可执行的条件——放在就绪队列中
(3)阻塞态
不具备可执行的条件——根据阻塞的种类(磁盘阻塞、键盘阻塞……)放在相应的阻塞队列中
在单CPU的情况下,只能同时进行一个进程,意味着只有一条就绪队列和多条阻塞队列
1.进程的基本状态调度图
五、多个进程的切换和调度
当当前进程变为阻塞态后,CPU就被空闲出来,就使用schedule()函数进行切换
这些空闲点又称调度点
1.调度点代码实现
//某个进程
{
pCur.state='W';
schedule();
}
2.schedule()代码实现
schedule(){
pNew=getNext(ReaadyQueue);
switch_to(pCur,pNew);
}
switch_to(pCur,pNew){
pCur.ax=CPU.ax;
pCur.bx=CPU.bx;
…………
pCur.cs=CPU.cs;
pCur.ip=CPU.ip;
CPU.ax=pNew.ax;
…………
CPU.cs=pNew.cs;
CPU.ip=pNew.ip;
}
然而这种切换只是最基础的切换,因为进程也有不同的优先级,所以如何选择pNew将会是一个精心设计的算法。
六、多个进程切换的问题以及解决
1.问题
因为事实上,所有程序都是分块顺序存放在内存中的,虽然进程的切换跳来跳去,这就会出现当前进程的执行地址可能错误的跳转到其他程序的地址处,并且对其他程序进行了修改
2.解决方式
采用地址隔离的方式,也就是,一个进程中的地址操作不是真实的物理地址,而是通过一个映射表对应到真实的物理地址,而这个地址往往很远并且保证其他程序的安全。这就将程序存放的地址和执行地址隔离开了
事实上,这就是页表和GDT表来翻译CS:EIP的真实原因

七、进程间的通信与合作
1.基本合作模型
一个进程要往一个缓存中写入数据,另一个进程要往缓存中读出数据。
这就引出了问题,那么什么时候开始读呢?
如果在写入的同时读出数据,就会造成可怕的情况,两个进程间的合作并不同步。我们从基本的进程合作模型——“生产者–消费者”模型来描述
2.生产者——消费者模型
#define BUFFER_SIZE 10
typedef struct{
…………
}item;
item buffer[BUFFER_SIZE];
int in=out=counter=0;
//生产者进程
while(true){
while(counter==BUFFER_SIZE);
buffer[in]=item;
in=(in+1)%BUFFER_SIZE;
counter++;
}
//消费者进程
while(true){
while(counter==0);
item=buffer[out];
out=(out+1)%BUFFER_SIZE;
counter--;
}
分析可知,整个合作的核心就是这个counter,如果在生产者进程还没有完成操作时,就进入消费者进程,那么,消费者进程再返回生产者进程后,二者的counter必然是不会同步的。
所以,合作机制的核心在于进程同步
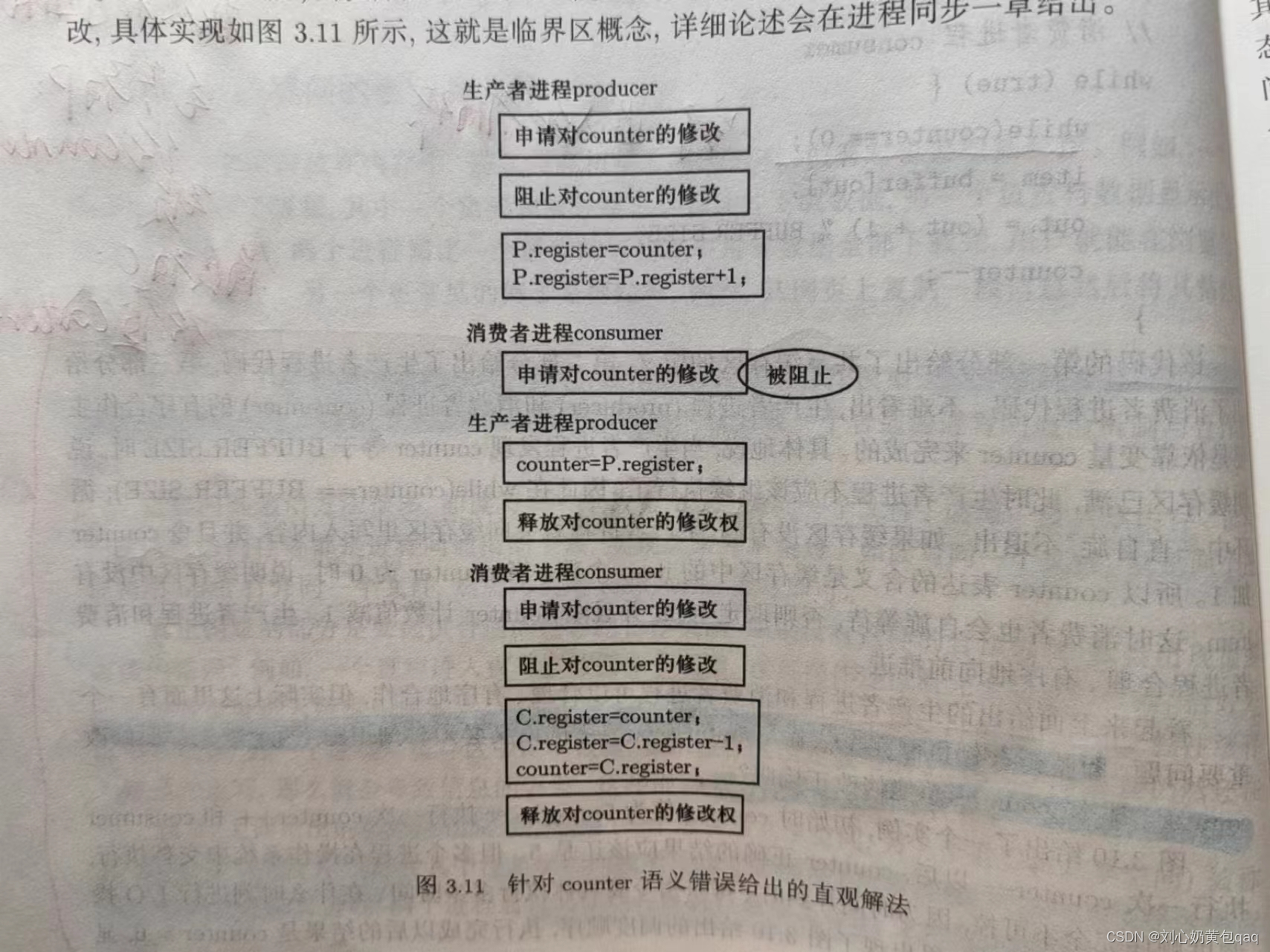
(1)如何实现进程同步
以生产者——消费者模型为例
可以将couter上锁,消费者需要检查couter锁的情况才可以实现切换。
要么couter全部修改完成,要么就一点也不改,这就是临界区概念



 京公网安备 11010502036488号
京公网安备 11010502036488号