

对于哈弗曼编码
我的题库:https://blog.csdn.net/L_Y_T020321/article/details/83152606



说句实话,哈夫曼编码在初赛里真的是十分的常见的.
那么,什么是哈夫曼编码呢?
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
如此难懂…一看就来自我萌信赖的百度百科
那我们就来简略的说明一下
说明之前,我先放一个链接以免自己理解的不对误人子弟…
哈夫曼编码其实是用到了贪心的思想(划重点!!),这一点是十分重要的,甚至比哈夫曼是啥都重要!!
它实际上是构建一颗二叉树,构建方法就是每次取出两个权值最小的两个点进行合并,合并之后的新点就是两个点的权值和
最后,如果根节点的深度为0的话,那么这个编码的长度就是这个点的深度
比如,2011年提高组初赛的第15题(的改版)
现有一段文言文,要通过二进制哈夫曼编码进行压缩。简单起见,假设这段文言文只由
4 个汉字“之”、“乎”、“者”、“也”组成,它们出现的次数分别为 700、600、300、200。那
么,“也”字的编码长度可能是( )。
A.1 B.2 C.3 D.4
什么玩意之乎者也??
这道题是选C的
至于为什么选C,我们来构建一棵树
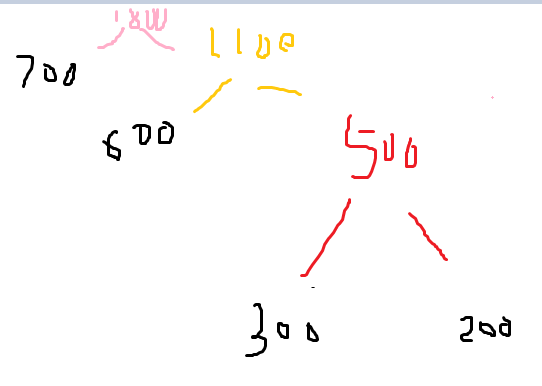
就是这个样子
黑色是原数,红色是第一步,黄色是第二步,粉色第三.
也的深度就是200的也就是4(根节点为0) .
当然原题是选BC的啊
完结散花!!!

 京公网安备 11010502036488号
京公网安备 11010502036488号