


题目描述
请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。所有的IP地址划分为 A,B,C,D,E五类:
A类地址1.0.0.0~126.255.255.255;
B类地址128.0.0.0~191.255.255.255;
C类地址192.0.0.0~223.255.255.255;
D类地址224.0.0.0~239.255.255.255;
E类地址240.0.0.0~255.255.255.255
私网IP范围是:
10.0.0.0~10.255.255.255
172.16.0.0~172.31.255.255
192.168.0.0~192.168.255.255
子网掩码为前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) 本题暂时默认 以0开头的IP地址是合法的,比如0.1.1.2,是合法地址
题解
解法一: 正则表达式
实现思路:
涉及到这种字符串匹配的问题, 善于使用这些匹配的问题, 那么我们在处理这些数据上, Python这门语言更为适合
代码实现
import re
# 各类的地址的正则表达式
error_pattern = re.compile(r'1+0+')
A_pattern = re.compile(
r'((12[0-6]|1[0-1]\d|[1-9]\d|[1-9])\.)((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
B_pattern = re.compile(
r'(12[8-9]|1[3-8]\d|19[0-1])\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
C_pattern = re.compile(
r'(19[2-9]|2[0-1]\d|22[0-3])\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
D_pattern = re.compile(
r'(22[4-9]|23\d)\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
E_pattern = re.compile(
r'(24\d|25[0-5])\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
self_pattern = re.compile(
r'((10\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d))|(172\.(1[6-9]|2\d|3[0-1])\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d))|(192\.168\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)))')
escape = re.compile(
r'((0|127)\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d))')
def check(line):
# 首先全0或者是全1的是不是可以的
if line == '255.255.255.255' or line == '0.0.0.0':
return 0
tmp = line.split('.')
# 分割我们的数字
res = ''
for j in tmp:
res += '{:0>8b}'.format(int(j))
res = re.fullmatch(error_pattern, res)
if res == None:
return 0
else:
return 1
def main():
arr = [0, 0, 0, 0, 0, 0, 0]
while True:
# 多组输入
try:
line = input().split('~') # 从~分割IP地址和掩码
if line[0][0:4] == "127." or line[0][0:2] == "0.": # 优先判断127或者0开头的
continue
if check(line[1]): # 先判断掩码是否正确
# 正则比较各个IP地址
# 私有与其他的不冲突,优先单独匹配
if re.fullmatch(self_pattern, line[0]) != None:
arr[6] += 1
if re.fullmatch(A_pattern, line[0]) != None:
arr[0] += 1
elif re.fullmatch(B_pattern, line[0]) != None:
arr[1] += 1
elif re.fullmatch(C_pattern, line[0]) != None:
arr[2] += 1
elif re.fullmatch(D_pattern, line[0]) != None:
arr[3] += 1
elif re.fullmatch(E_pattern, line[0]) != None:
arr[4] += 1
elif re.fullmatch(escape, line[0]) != None:
continue
else:
arr[5] += 1 # IP地址错误
else: # 掩码错误
arr[5] += 1
except:
print(' '.join([str(i) for i in arr])) # 输出
break
if __name__ == "__main__":
main()
时空复杂度分析:
时间复杂度:
理由如下: 主要的时间花费在了我们的正则匹配上, 也可以理解为是遍历字符串检查上
空间复杂度:
理由如下: 都是常数级别的空间
解法二: 正常的一个个检验匹配
实现思路
- 我们先是正常的切割我们的字符串, 我们获取到我们的IP和我们的子网掩码
- 将我们的IP地址和我们的子网掩码切割开来, 并且转换为整型
- 判断第一位是不是0或者是不是127
- 判断我们的子网掩码是否合法
- 是否为四段
- 二进制下面是否是连续的1, 然后全是0
- 如果子网掩码合法的情况下, 我们要看IP是否合法, 然后如果合法的话我们统计我们的ABCDE五类地址和我们的私有地址
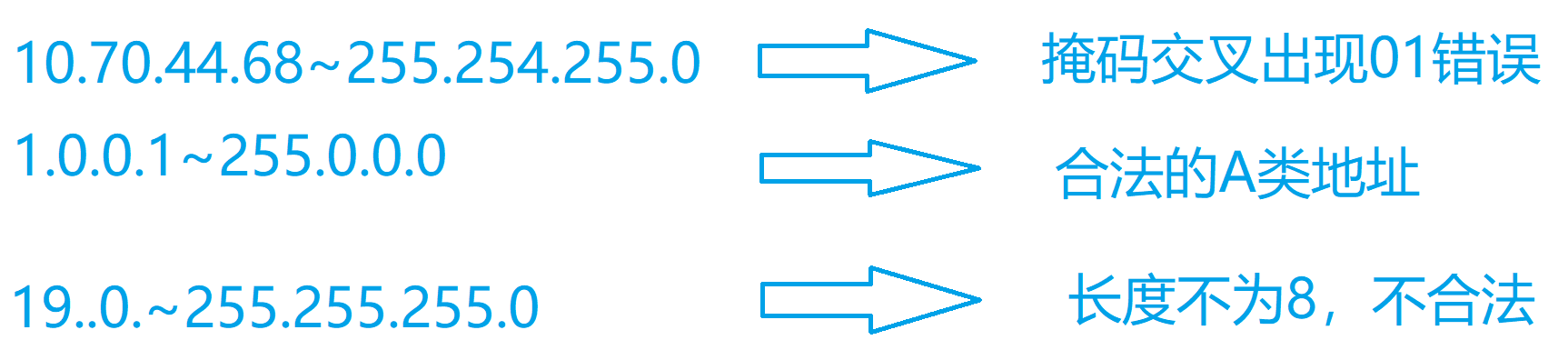
图解代码
代码实现
#include <bits/stdc++.h>
using namespace std;
signed main() {
string s;
vector<int> a(7, 0);
// 上面是我们要输出的东西
while (getline(cin, s)) {
if (s.empty()) break;
// 如果是空的字符串, 结束循环
int pos = s.find("~");
// 找到我们分割的地方
string ip = s.substr(0, pos),
ym = s.substr(pos + 1, s.size() - pos - 1);
// 把我们前后的字符串分隔开
int d1, d2, d3;
string s1, s2, s3, s4;
int i1, i2, i3, i4;
d1 = ip.find(".");
// 分割字符
s1 = ip.substr(0, d1);
i1 = stoi(s1);
if (i1 == 0 || i1 == 127) {
continue;
}
// 这个可以不用考虑0和127的
d1 = ym.find(".");
d2 = ym.find(".", d1 + 1);
d3 = ym.find(".", d2 + 1);
// 分割字符串
s1 = ym.substr(0, d1);
s2 = ym.substr(d1 + 1, d2 - d1 - 1);
s3 = ym.substr(d2 + 1, d3 - d2 - 1);
s4 = ym.substr(d3 + 1);
// cout << s1 << " " << s2 << " " << s3 << " " << s4 << endl;
i1 = stoi(s1);
i2 = stoi(s2);
i3 = stoi(s3);
i4 = stoi(s4);
// 字符串转换为数字
long long x = (long long)i1 * 256 * 256 * 256 +
(long long)i2 * 256 * 256 + (long long)i3 * 256 +
(long long)i4;
bool one = false;
int r;
bool maskErr = false;
if (i1 == 255 && i2 == 255 && i3 == 255 && i4 == 255) {
a[5]++;
// 错误的那位+1
maskErr = true;
}
if (!maskErr) {
while (x != 0) {
r = x % 2;
if (one) {
if (r == 0) {
a[5]++;
maskErr = true;
break;
}
}
if (r == 1 && one == false) {
one = true;
}
x /= 2;
}
}
// 如果我们没有错误我们执行上面的语句
if (maskErr) {
continue;
}
d1 = ip.find(".");
d2 = ip.find(".", d1 + 1);
d3 = ip.find(".", d2 + 1);
// 从点开始往后找
s1 = ip.substr(0, d1);
s2 = ip.substr(d1 + 1, d2 - d1 - 1);
s3 = ip.substr(d2 + 1, d3 - d2 - 1);
s4 = ip.substr(d3 + 1);
if (s1.empty() || s2.empty() || s3.empty() || s4.empty()) {
a[5]++;
continue;
// 这个依旧是判断错误的
}
// cout << s1 << " " << s2 << " " << s3 << " " << s4 << endl;
i1 = stoi(s1);
i2 = stoi(s2);
i3 = stoi(s3);
i4 = stoi(s4);
// 转换成为数字
if (i1 > 255 || i1 < 0 || i2 > 255 || i2 < 0 || i3 > 255 || i3 < 0 ||
i4 > 255 || i4 < 0) {
a[5]++;
continue;
}
if (i1 > 0 && i1 < 127) {
if (i1 == 10) a[6]++;
a[0]++;
} else if (i1 > 127 && i1 < 192) {
if (i1 == 172 && i2 >= 16 && i2 <= 31) {
a[6]++;
}
a[1]++;
} else if (i1 >= 192 && i1 <= 223) {
if (i1 == 192 && i2 == 168) {
a[6]++;
}
a[2]++;
} else if (i1 >= 224 && i1 <= 239) {
a[3]++;
} else if (i1 >= 240 && i1 <= 255) {
a[4]++;
}
}
// 判断各种情况
for (int i = 0; i <= 6; i++) {
cout << a[i] << " \n"[i == 6];
}
return 0;
}
时空复杂度分析
时间复杂度:
理由如下: 主要就是遍历字符串需要的时间
空间复杂度:
理由如下: 我们使用的都是常数级别的空间


 京公网安备 11010502036488号
京公网安备 11010502036488号