

论文原文
https://arxiv.org/abs/1612.01105
摘要
本文提出的金字塔池化模块( pyramid pooling module)能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。实验表明这样的先验表示(即指代PSP这个结构)是有效的,在多个数据集上展现了优良的效果。
介绍
场景解析(Scene Parsing)的难度与场景的标签密切相关。先大多数先进的场景解析框架大多数基于FCN,但FCN存在的几个问题:
- Mismatched Relationship:上下文关系匹配对理解复杂场景很重要,例如在上图第一行,在水面上的大很可能是“boat”,而不是“car”。虽然“boat和“car”很像。FCN缺乏依据上下文推断的能力。
- Confusion Categories: 许多标签之间存在关联,可以通过标签之间的关系弥补。上图第二行,把摩天大厦的一部分识别为建筑物,这应该只是其中一个,而不是二者。这可以通过类别之间的关系弥补。
- Inconspicuous Classes:模型可能会忽略小的东西,而大的东西可能会超过FCN接收范围,从而导致不连续的预测。如上图第三行,枕头与被子材质一致,被识别成到一起了。为了提高不显眼东西的分割效果,应该注重小面积物体。
总的来说,FCN不能有效的处理场景之间的信息和全局信息,为了对FCN的这些缺点加以克服,提出了PSPNet。可以融合合适的全局特征,将局部和全局信息融合到一起,并提出了一个适度监督损失的优化策略,在多个数据集state of art。
论文的主要贡献为: - 提出了一个金字塔场景解析网络,能够将难解析的场景信息特征嵌入基于FCN预测框架中
- 在基于深度监督损失ResNet上制定有效的优化策略
- 构建了一个实用的系统,用于场景解析和语义分割,并包含了实施细节
相关工作
受到深度神经网络的驱动,场景解析和语义分割获得了极大的进展。例如FCN,ENet等工作。许多深度卷积神经网络为了扩大高层feature的感受野,常用空洞卷积,coarse-to-fine结构等方法。本文基于先前的工作,使用了带dilated卷积的FCN。
大多数语义分割模型的工作基于2个方面:
- 具有多尺度的特征融合,高层特征具有强的语义信息,底层特征包含更多的细节。
- 基于结构预测。例如使用CRF(条件随机场)做后端细化分割结果。
为了充分的利用全局特征层次先验知识来进行不同场景理解,本文提出的PSP模块能够聚合不同区域的上下文从而达到获取全局上下文的目的。
PSP网络
3.1 一些观察
这个在上面已经讲了,就是FCN的缺点。
3.2 PSP 模块
在CNN中感受野可以粗略的被认为是使用上下文信息的大小,论文指出在许多网络中没有充分的获取全局信息,所以效果不好。要解决这一问题,常用方法是:
- 用全局平均池化处理:但这在某些数据上上可能会失去空间关系导致模糊。
- 由金字塔池化产生不同层次的特征最后被平滑的连接层一个FC层做分类。这样可以去除CNN固定大小的图像分类约束,减少不同区域之间的信息损失。
论文提出了一个具有层次全局优先级,包含不同子区域之间的不同尺度信息,称之为pyramid pooling module。
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×11×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起。
金字塔等级的池化核大小是可以设定的,这与送到金字塔的输入有关,论文中使用的4个等级,核大小分别为 1×1, 2×2, 3×3, 6×6。还需要注意一点的是,基础层经过预训练的模型(ResNet101)和空洞卷积策略提取feature map,提取后的feature map是输入的***小。feature map经过Pyramid Pooling Module得到融合的带有整体信息的feature,再上采样并和池化前的feature map相concat。最后过一个卷积层得到最终输出。PSPNet本身提供了一个全局上下文的先验(即指代Pyramid Pooling Module这个结构),后面的实验会验证这一结构的有效性。
基于ResNet的深度监督网络

实验
训练超参数和训练细节为,学习率设置为"poly"衰减策略,即 lr=lrbase∗(1−maxiteriter)power,设置 lrbase等于0.01, power等于0.9,衰减动量设置为0.9,。在ImageNet上设置迭代次数为150K,PASCAL VOC设置迭代次数为30K,Cityscapes设置为90K。数据增强做了随机反转,尺寸在0.5-2之间的缩放,角度在-10到10之间旋转,随机的高斯滤波。batchsize设为16,辅助损失的权重为0.4,使用caffe训练。
- 测试不同配置下的ResNet的性能,找到比较好的预训练模型:
可以看到做平均池化的都比最大池化效果要好,最后将多个操作结合得到最终最好的效果。
- 测试辅助Loss的影响

- 测试预训练模型的深度:
可以看到在测试的{50,101,152,269}这四个层次的网络中,网络越深,效果越好。
- 多种技巧融合:
-在ImageNet上的表现:
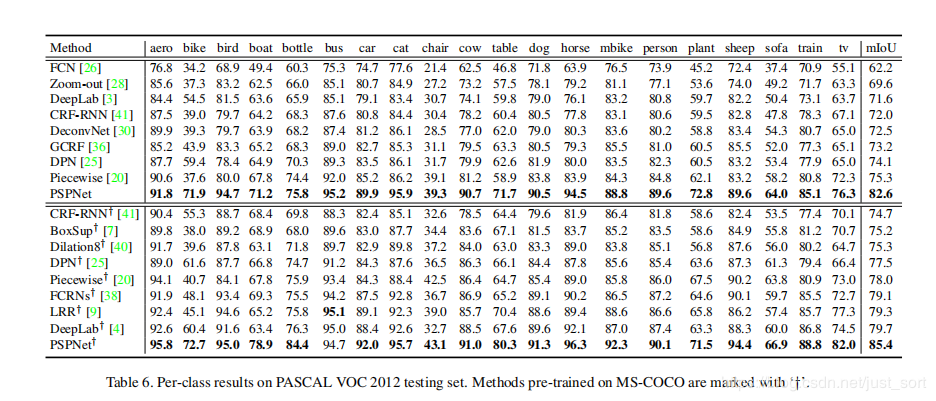
在PascalVOC上的表现:
在Cityscapes上的表现

结论
论文在结构上提供了一个pyramid pooling module,在不同层次上融合feature,达到语义和细节的融合。
代码实现
#coding=utf-8
from keras.models import *
from keras.layers import *
import keras.backend as K
def resize_image(inp, s):
return Lambda(lambda x: K.resize_images(x, height_factor=s[0], width_factor=s[1], data_format='channels_last',
interpolation='bilinear'))(inp)
def pool_block(inp, pool_factor):
h = K.int_shape(inp)[1]
w = K.int_shape(inp)[2]
pool_size = strides = [int(np.round( float(h) / pool_factor)), int(np.round( float(w )/ pool_factor))]
x = AveragePooling2D(pool_size, strides=strides, padding='same')(inp)
x = Conv2D(512, (1, 1), padding='same', use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#print(strides)
x = resize_image(x, strides)
return x
def PSPNet(nClasses, optimizer=None, input_width=384, input_height=576):
assert input_height%192 == 0
assert input_width%192 == 0
input_size = (input_height, input_width, 3)
inputs = Input(input_size)
kernel = 3
filter_size = 64
pad = 1
pool_size = 2
x = inputs
x = (ZeroPadding2D((pad, pad)))(x)
x = (Conv2D(filter_size, (kernel, kernel), padding='valid'))(x)
x = (BatchNormalization())(x)
x = (Activation('relu'))(x)
x = (MaxPooling2D((pool_size, pool_size)))(x)
f1 = x
x = (ZeroPadding2D((pad, pad)))(x)
x = (Conv2D(128, (kernel, kernel), padding='valid'))(x)
x = (BatchNormalization())(x)
x = (Activation('relu'))(x)
x = (MaxPooling2D((pool_size, pool_size)))(x)
f2 = x
x = (ZeroPadding2D((pad, pad)))(x)
x = (Conv2D(256, (kernel, kernel), padding='valid'))(x)
x = (BatchNormalization())(x)
x = (Activation('relu'))(x)
x = (MaxPooling2D((pool_size, pool_size)))(x)
f3 = x
# x = (ZeroPadding2D((pad, pad)))(x)
# x = (Conv2D(256, (kernel, kernel), padding='valid'))(x)
# x = (BatchNormalization())(x)
# x = (Activation('relu'))(x)
# x = (MaxPooling2D((pool_size, pool_size)))(x)
# f4 = x
# x = (ZeroPadding2D((pad, pad)))(x)
# x = (Conv2D(256, (kernel, kernel), padding='valid'))(x)
# x = (BatchNormalization())(x)
# x = (Activation('relu'))(x)
# x = (MaxPooling2D((pool_size, pool_size)))(x)
# f5 = x
o = f3
pool_factors = [1, 2, 3, 6]
pool_outs = [o]
for p in pool_factors:
pooled = pool_block(o, p)
pool_outs.append(pooled)
o = Concatenate(axis=3)(pool_outs)
o = Conv2D(512, (1, 1), use_bias=False)(o)
o = BatchNormalization()(o)
o = Activation('relu')(o)
o = Conv2D(nClasses, (3, 3), padding='same')(o)
o = resize_image(o, (8, 8))
o_shape = Model(inputs, o).output_shape
outputHeight = o_shape[1]
outputWidth = o_shape[2]
o = Reshape((nClasses, input_height * input_width))(o)
o = Permute((2, 1))(o)
model = Model(inputs, o)
model.outputWidth = outputWidth
model.outputHeight = outputHeight
return model

 京公网安备 11010502036488号
京公网安备 11010502036488号