

算法能解决的问题
- 求解最长公共前缀 l c p lcp lcp
- 在短时间内将 n n n个后缀按照字典序排序
算法原理
倍增法 O ( n log n ) O(n \log n) O(nlogn)

对于一个字符串有很多后缀, 第 i i i个后缀
- s a sa sa数组, s a ( i ) sa(i) sa(i)表示排名第 i i i位的后缀
- r k rk rk数组, r k ( i ) rk(i) rk(i)表示第 i i i个后缀的排名
- * h e i g h t ( i ) height(i) height(i)表示 s a ( i ) sa(i) sa(i)与 s a ( i − 1 ) sa(i - 1) sa(i−1)两个后缀的最长公共前缀
假设当前字符串 a a b a b b aababb aababb, 后缀如下
- a a b a b b aababb aababb
- a b a b b ababb ababb
- b a b b babb babb
- a b b abb abb
- b b bb bb
- b b b
第一次只关注每个后缀的第一个字符按照字典序排序, 如果没字符用 n u l l null null表示, 比任意字符都小
第一次排序的结果, 第一个字符相同相对顺序不变
- a a b a b b aababb aababb
- a b a b b ababb ababb
- a b b abb abb
- b a b b babb babb
- b b bb bb
- b b b
可以用基数排序算法时间复杂度 O ( n ) O(n) O(n)

假设执行某一轮后已经按照前 k k k个字符排好序了, 考虑前 2 k 2k 2k个字符
-
将每个后缀的前 k k k个字符当作第一关键字, 将后 k k k个字符当作第二关键字进行排序, 双关键字排序
-
每一轮结束之后, 将第一关键字离散化为一个整数方便排序, 也是按照基数排序来排
实现细节
基数排序范围 1 ∼ n 1 \sim n 1∼n
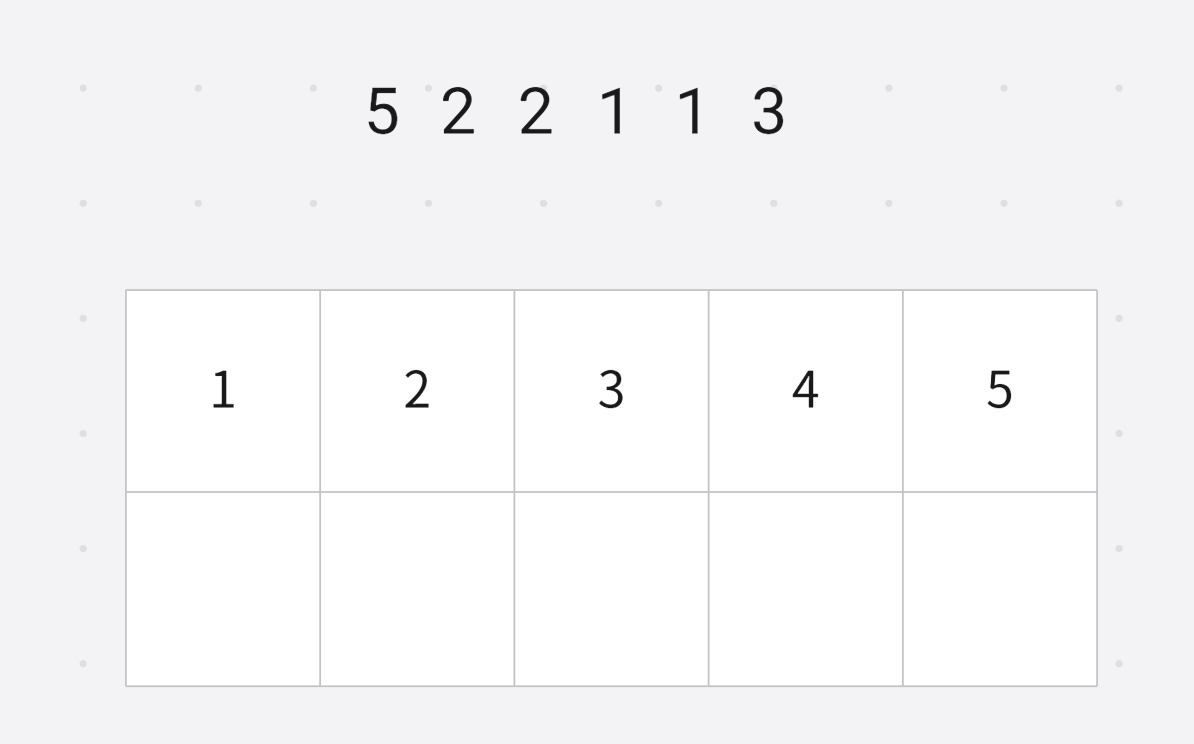
统计每个数出现次数
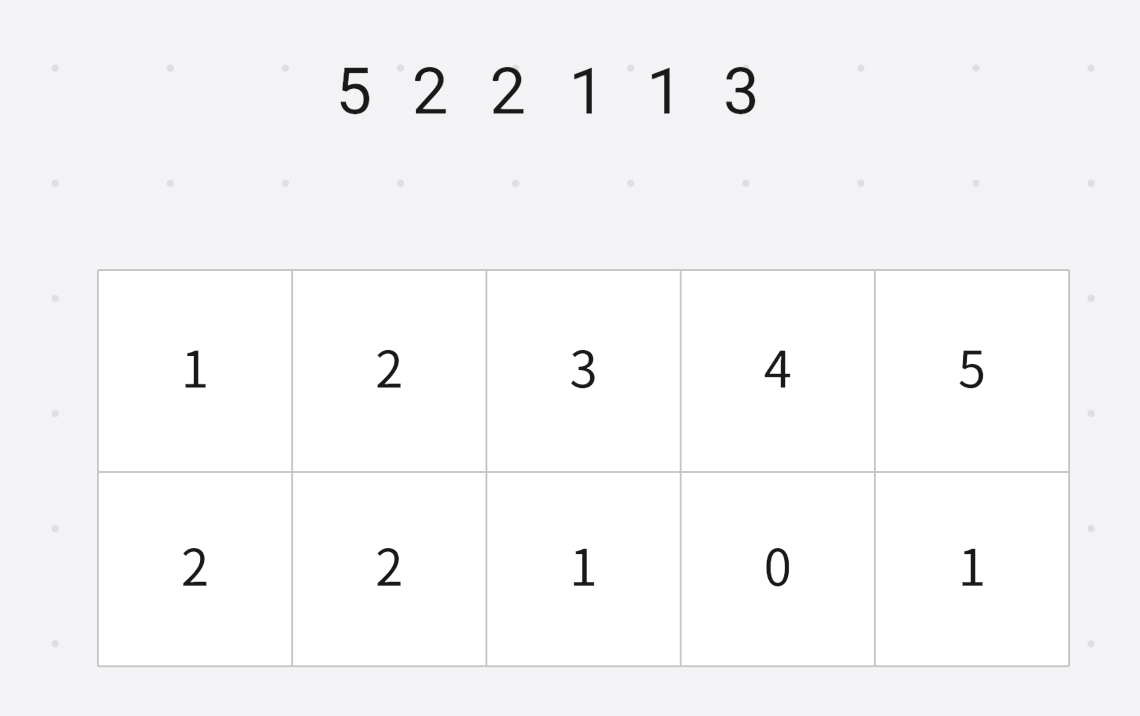
因为求的是排名, 求的是 ≤ w \le w ≤w的数字个数, 就是对出现次数求前缀和
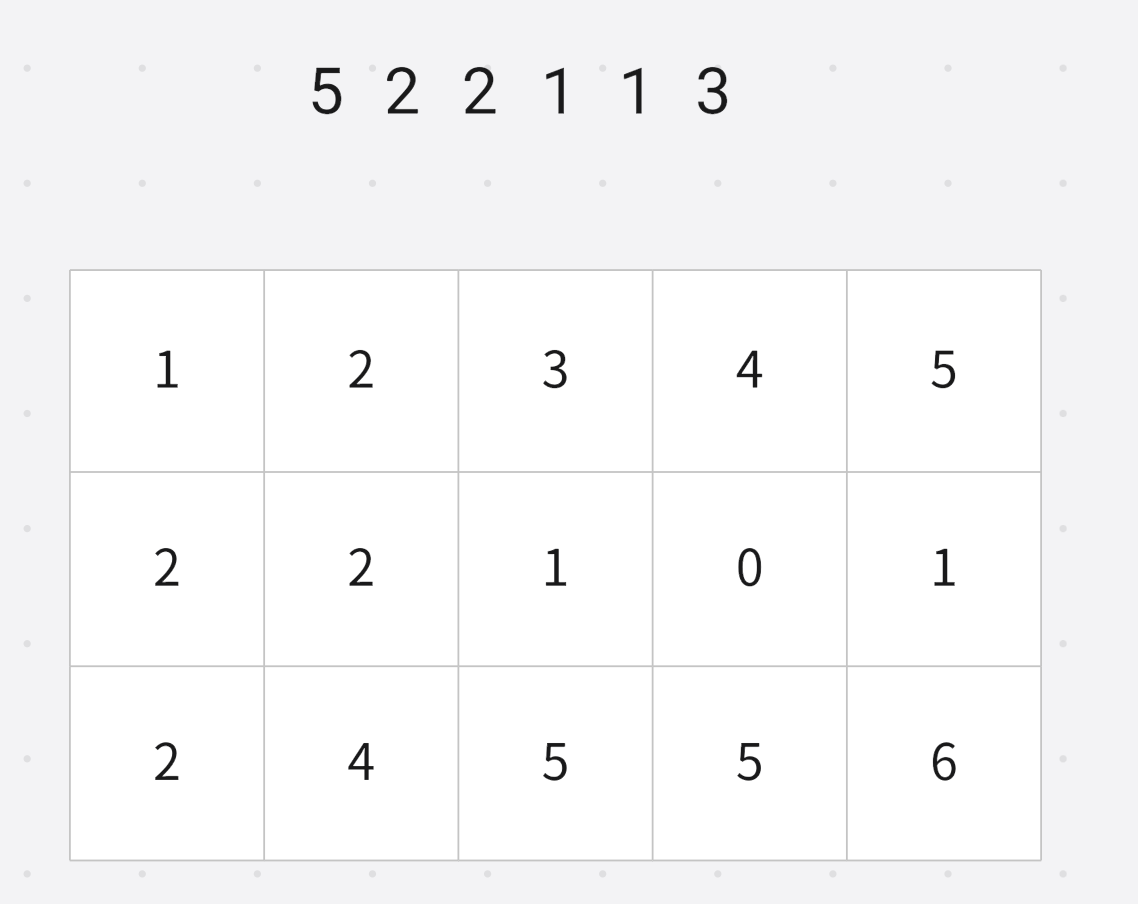
然后倒序枚举每个数字"(为了保证相同值的先后顺序不发生变化)
小于等于 3 3 3的数字个数是 5 5 5, 然后对应位置 − 1 -1 −1
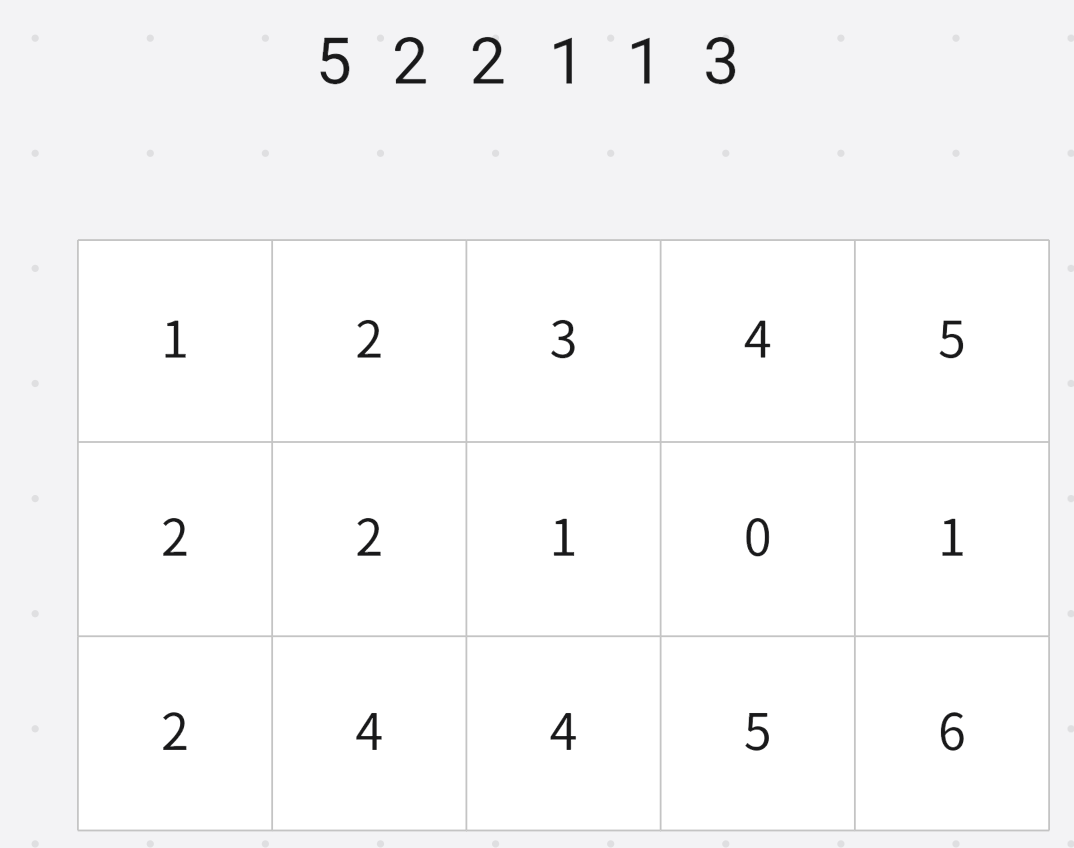
小于等于 1 1 1的数字个数 2 2 2
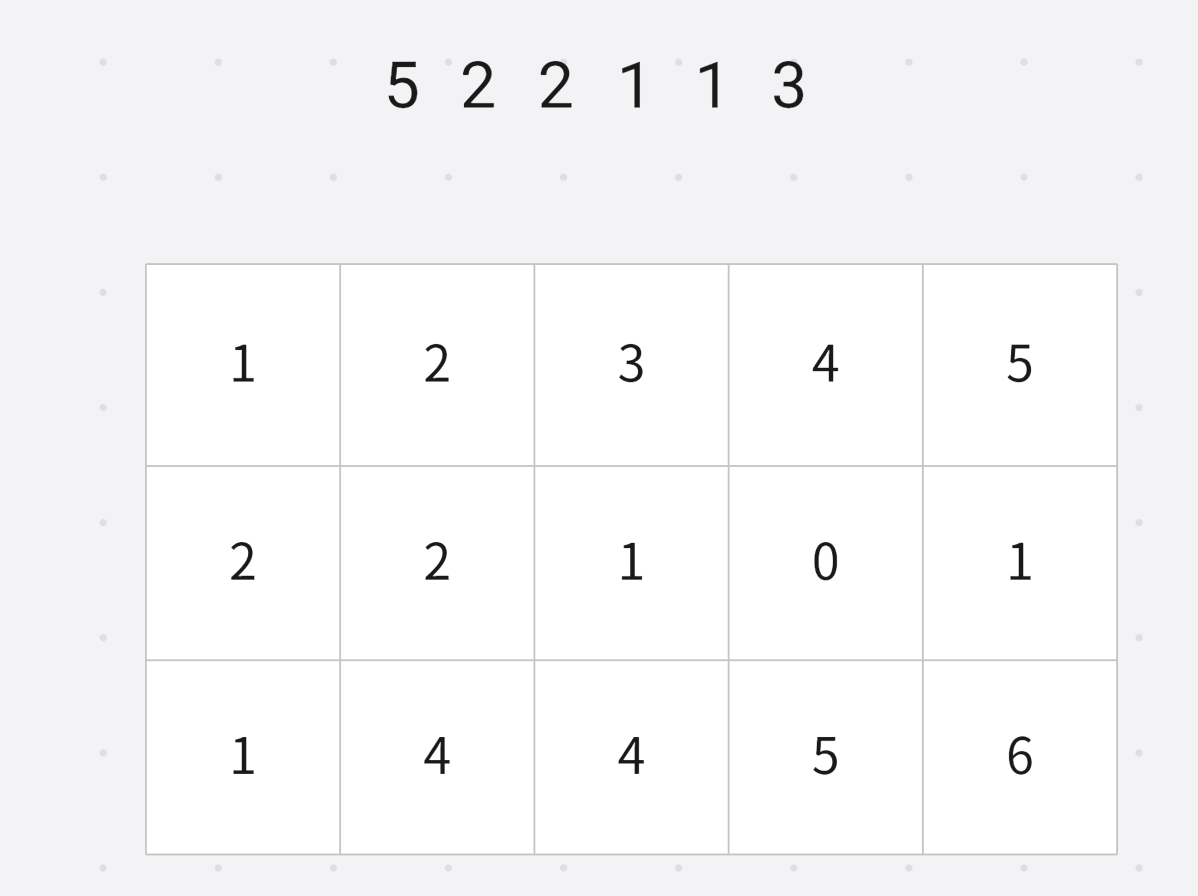
小于等于 1 1 1的数字个数 1 1 1
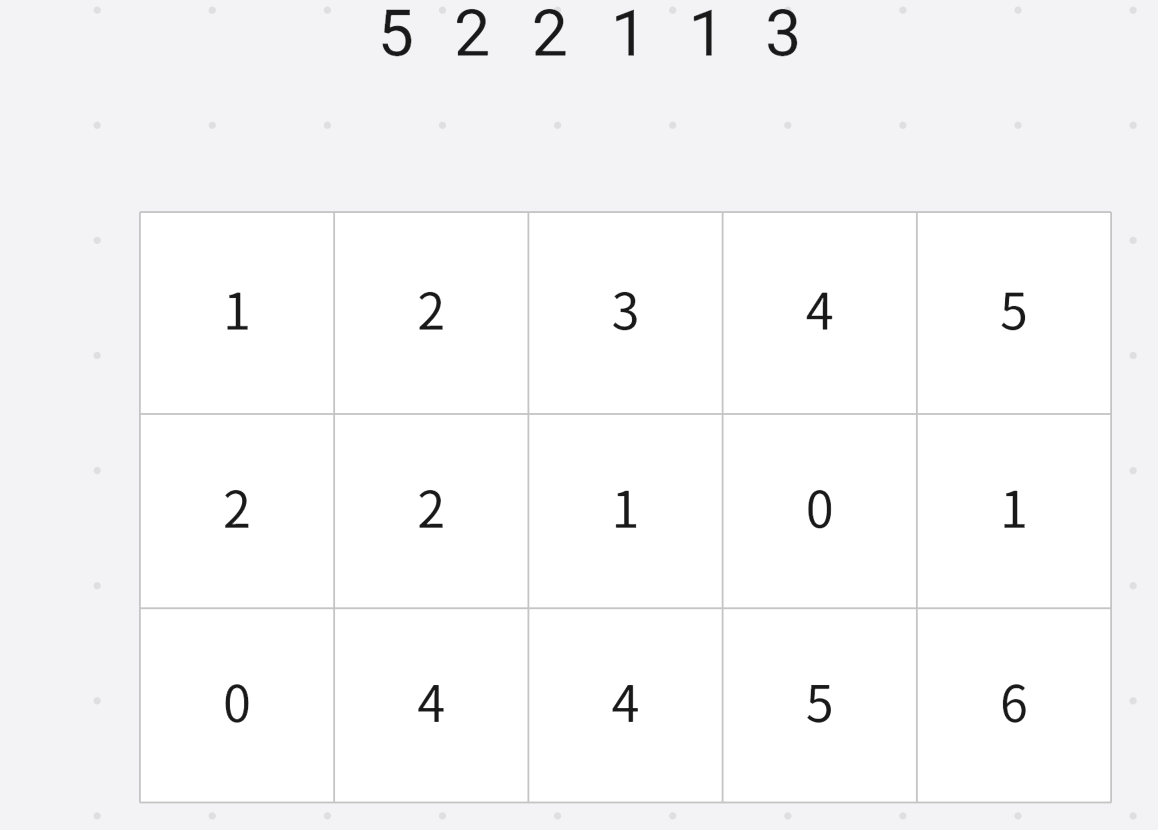
小于等于 2 2 2的数字个数 4 4 4
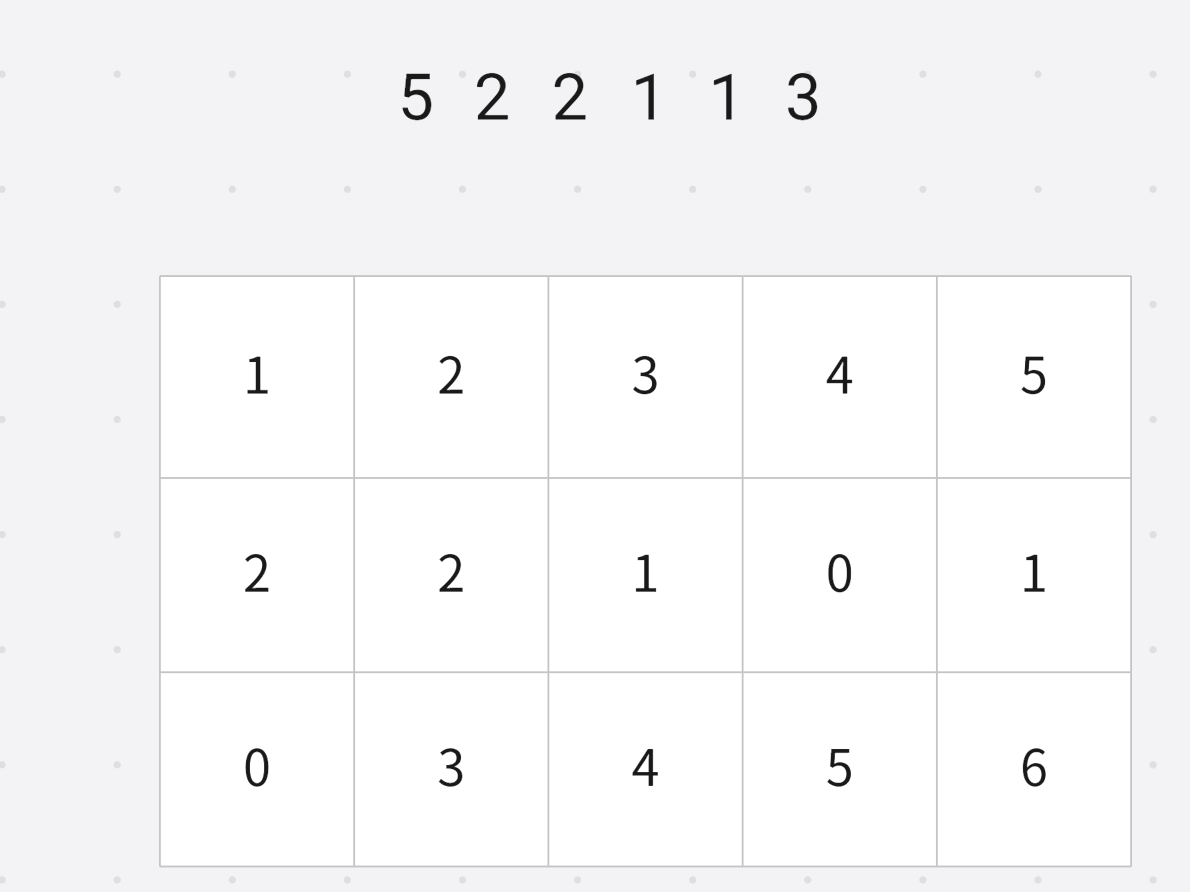
小于等于 2 2 2的数字个数 3 3 3
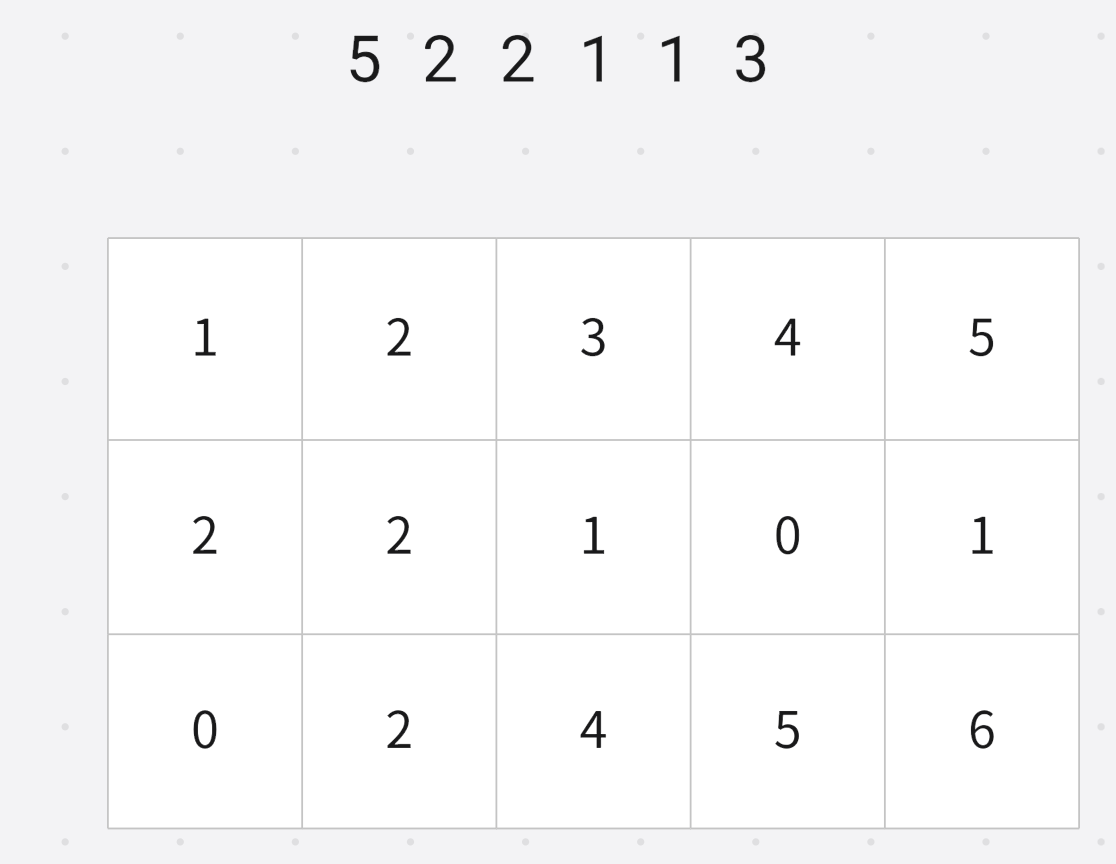
小于等于 5 5 5的数字个数 6 6 6
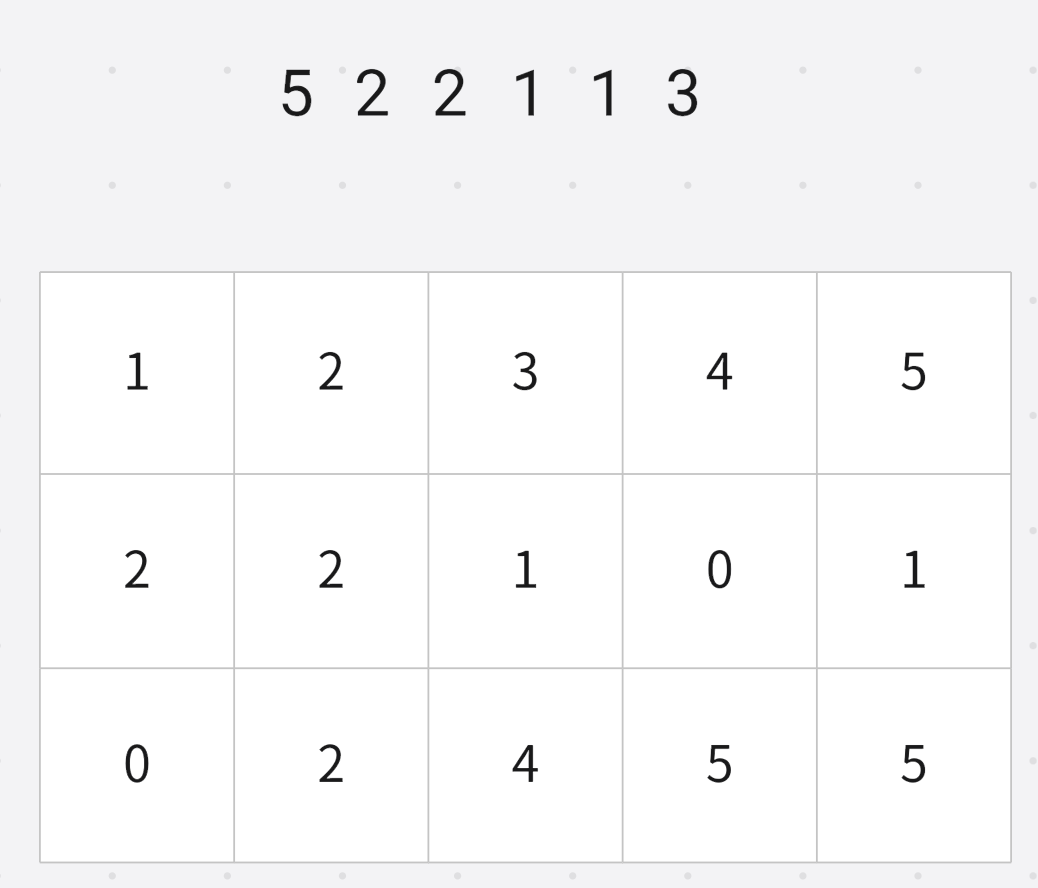
这样就得到了小于等于某个数的排名
双关键字类似, 为了保证排序是稳定的
- 现将所有元素按照第二关键字排序
- 从后往前再按照第一关键字排, 保证第二关键字相对顺序不变
注意到
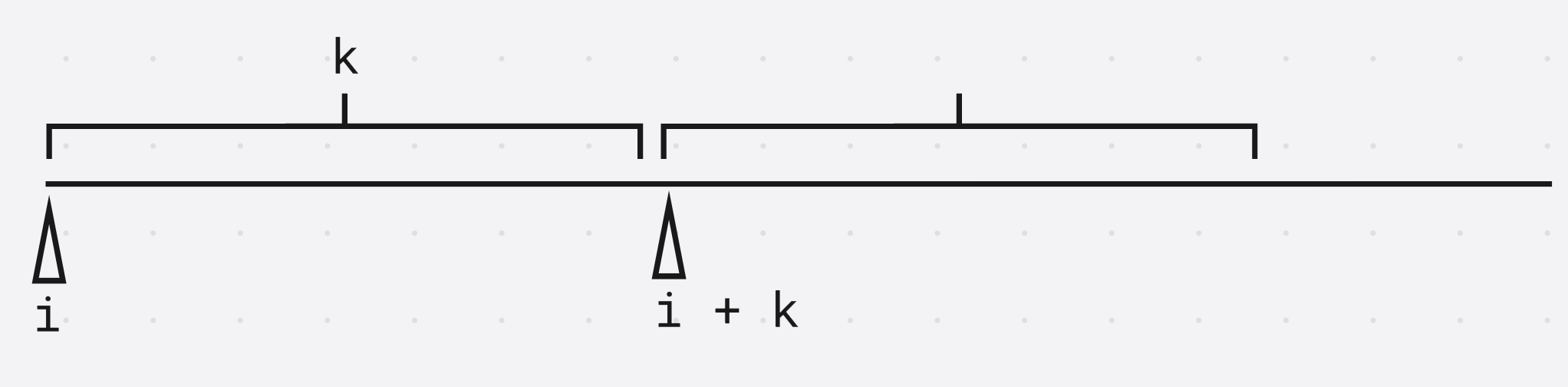
第 i i i个后缀的第二关键字就是第 i + k i + k i+k后缀的第一关键字
基数排序部分
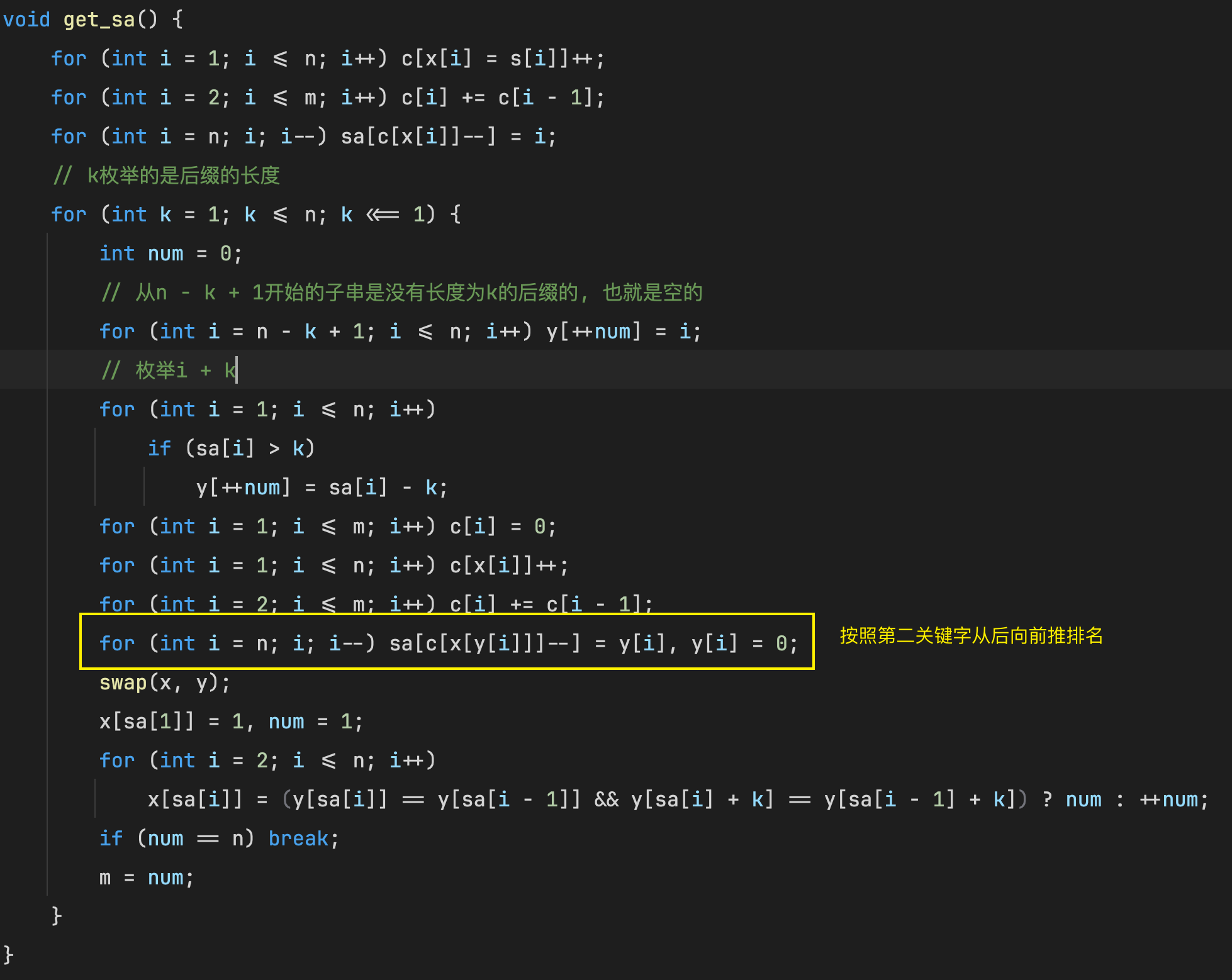
将 y y y清空, 将 x x x信息存在 y y y中
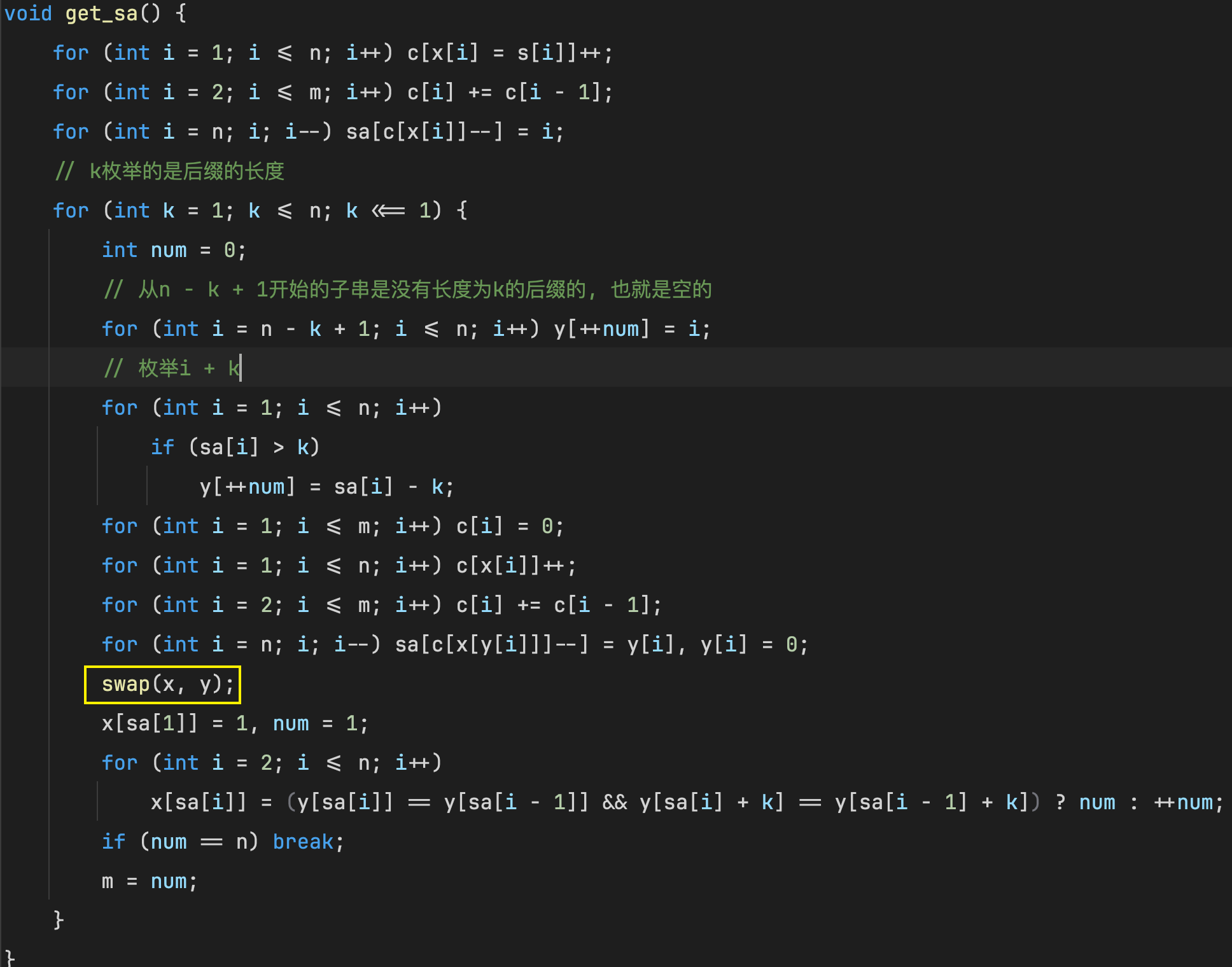
然后对前 2 k 2k 2k的字符进行离散化, 离散化范围是 1 ∼ n 1 \sim n 1∼n
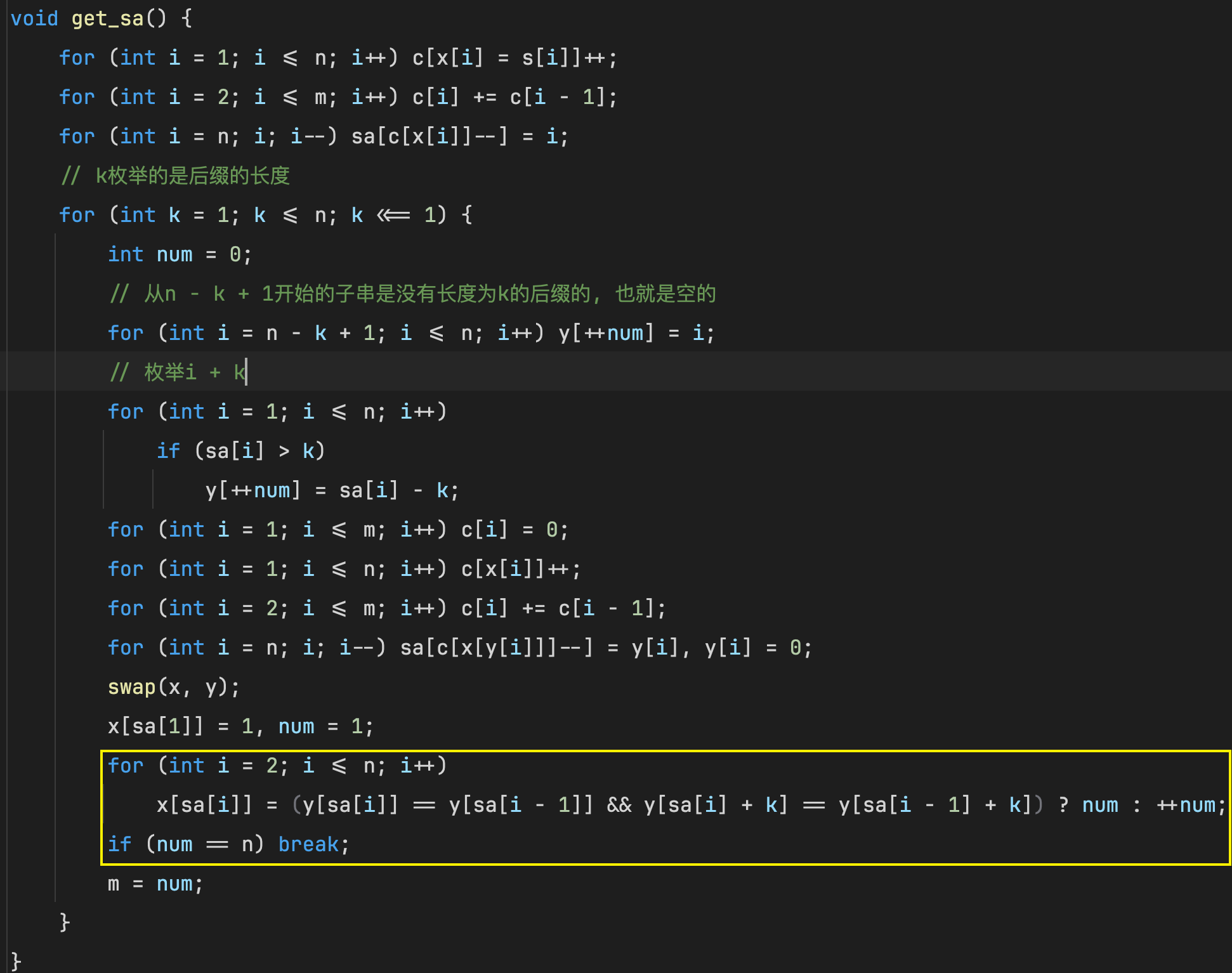
s a ( i ) sa(i) sa(i)个后缀的第二关键字是 s a ( i + k ) sa(i + k) sa(i+k)后缀的第一关键字
逻辑很简单, 如果当前离散化的值和前一个字符串离散化后的值相等, 直接复制过来
如果比前面的值大则 + 1 + 1 +1
这样就可以在 O ( n log n ) O(n \log n) O(nlogn)时间复杂度内求出 s a sa sa数组
现在问题变成如何求 h e i g h t height height数组?
假设已经将后缀排好序, h e i g h t ( i ) height(i) height(i)表示
排名第 i i i位的后缀和排名第 i − 1 i - 1 i−1位的后缀的最长公共前缀的长度, 也就是
h e i g h t ( i ) = l c p ( i , i − 1 ) height(i) = lcp(i, i - 1) height(i)=lcp(i,i−1)
i , j i, j i,j是排名第 i , j i, j i,j的后缀
l c p lcp lcp的一些性质
- l c p ( i , j ) = l c p ( j , i ) lcp(i, j) = lcp(j, i) lcp(i,j)=lcp(j,i)
- l c p ( i , i ) = l e n ( i ) lcp(i, i) = len(i) lcp(i,i)=len(i)
- l ≤ k ≤ j l \le k \le j l≤k≤j有
l c p ( i , j ) = min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) = \min(lcp(i, k), lcp(k, j)) lcp(i,j)=min(lcp(i,k),lcp(k,j))
证明:
(1) 首先证明 l c p ( i , j ) ≥ min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) \ge \min(lcp(i, k), lcp(k, j)) lcp(i,j)≥min(lcp(i,k),lcp(k,j))
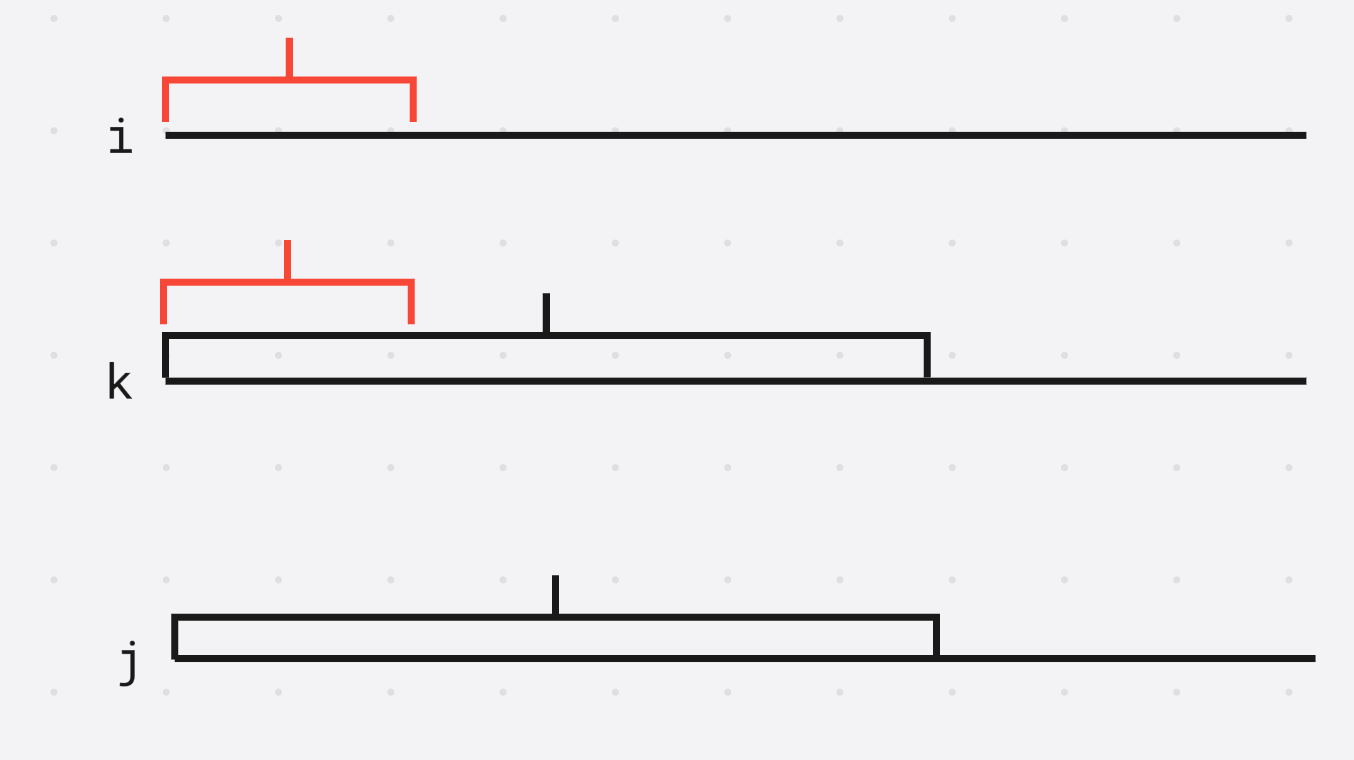
黑色部分是 k , j k, j k,j前缀的最长公共前缀, 红色部分是 i , k i, k i,k部分的最长公共前缀
因为 l c p lcp lcp是最长的, 因此 l c p ( i , j ) ≥ min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) \ge \min(lcp(i, k), lcp(k, j)) lcp(i,j)≥min(lcp(i,k),lcp(k,j)), (1)证毕
(2) 再证明 l c p ( i , j ) ≤ min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) \le \min(lcp(i, k), lcp(k, j)) lcp(i,j)≤min(lcp(i,k),lcp(k,j))
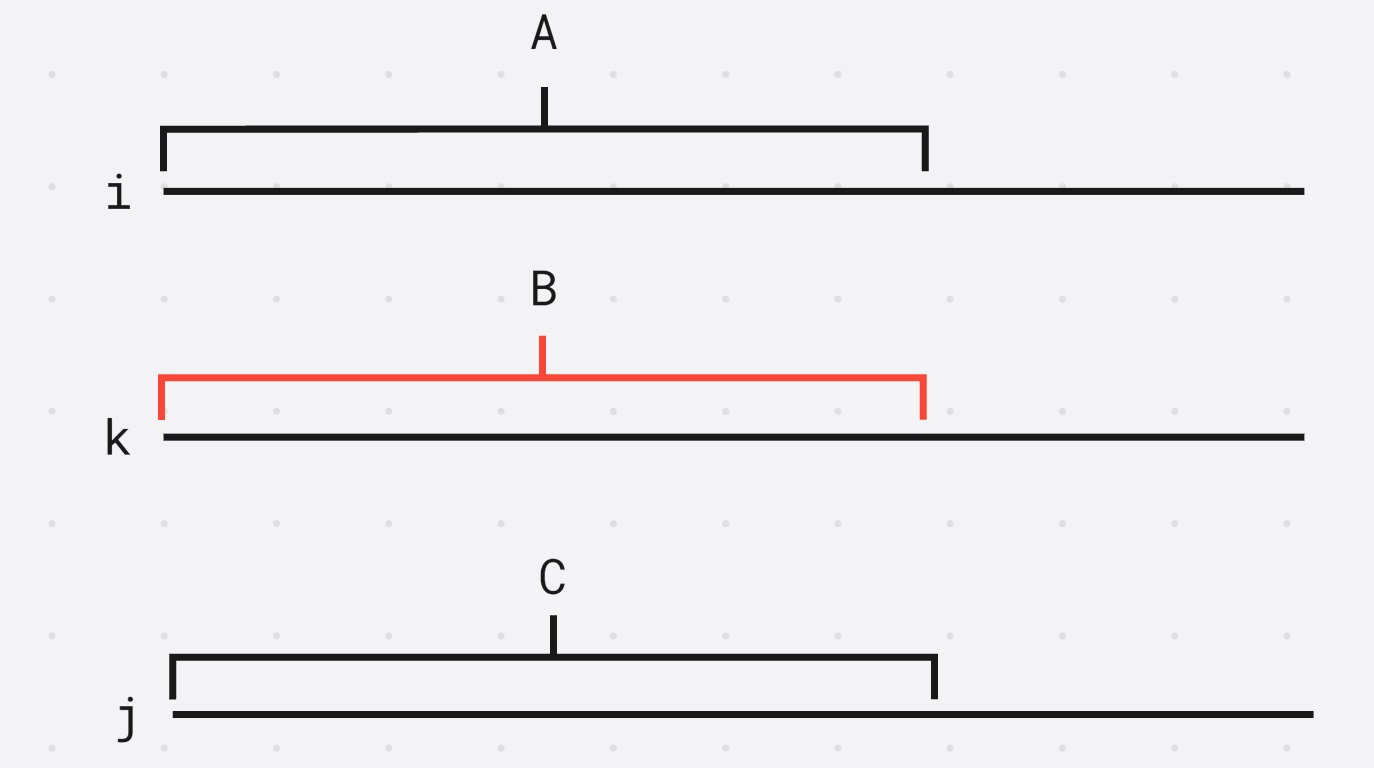
假设排名 i , j i, j i,j的后缀的最长公共前缀是 A , C A, C A,C, 那么有 A = C A = C A=C, 再取出排名 k k k的后缀的前缀是 B B B
因为 i , k , j i, k, j i,k,j是按照字典序排名的, 因此 A ≤ B ≤ C A \le B \le C A≤B≤C
因为 A = C A = C A=C, 夹逼定理得到 A = B = C A = B = C A=B=C
得到 l c p ( i , k ) ≥ A lcp(i, k) \ge A lcp(i,k)≥A, 并且 l c p ( k , j ) ≥ C lcp(k, j) \ge C lcp(k,j)≥C, 也就是 min ( l c p ( i , k ) , l c p ( k , j ) ) ≥ l c p ( i , j ) \min(lcp(i, k), lcp(k, j)) \ge lcp(i, j) min(lcp(i,k),lcp(k,j))≥lcp(i,j), (2)证毕
由(1)和(2)得到 l c p ( i , j ) = min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) = \min(lcp(i, k), lcp(k, j)) lcp(i,j)=min(lcp(i,k),lcp(k,j)), 证毕

暴力的计算
l c p ( i , j ) = min ( l c p ( i , i + 1 ) , l c p ( i , i + 2 ) , . . . , l c p ( i , j − 1 ) ) lcp(i, j) = \min(lcp(i, i + 1), lcp(i, i + 2), ..., lcp(i, j - 1)) lcp(i,j)=min(lcp(i,i+1),lcp(i,i+2),...,lcp(i,j−1))
算法时间复杂度 O ( n 2 ) O(n ^ 2) O(n2)非常慢
优化
h [ i ] = h e i g h t [ r k [ i ] ] h[i] = height[rk[i]] h[i]=height[rk[i]], 第 i i i个后缀和排名在第 i i i个后缀前一名的后缀的最长公共前缀的长度
猜想(1): h [ i ] ≥ h [ i − 1 ] − 1 h[i] \ge h[i - 1] - 1 h[i]≥h[i−1]−1
如果这个猜想是正确的, 那么枚举的时候直接从 i − 1 i - 1 i−1开始枚举
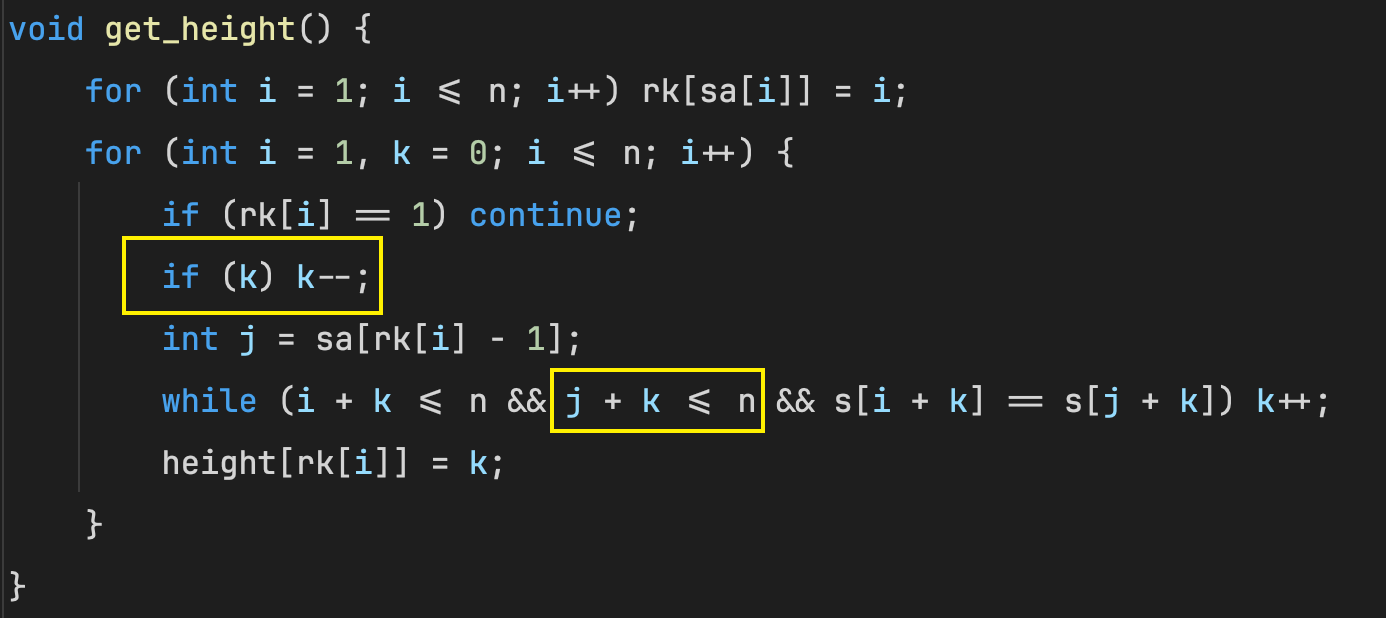
对于每个 i i i来说 k k k最多减 1 1 1, k ≤ n k \le n k≤n, k k k移动的范围是 [ − n , n ] [-n, n] [−n,n], 移动次数最多是 2 n 2n 2n, 因此算法时间复杂度降低到 O ( n ) O(n) O(n)
设字典序第 i i i个后缀在第 i − 1 i - 1 i−1个后缀的下方

分为两种情况
-
如果 k k k和 i − 1 i - 1 i−1没有公共前缀, 那么 h [ i − 1 ] = 0 h[i - 1] = 0 h[i−1]=0, h [ i ] ≥ − 1 h[i] \ge -1 h[i]≥−1显然成立
-
假设第一个字母相同
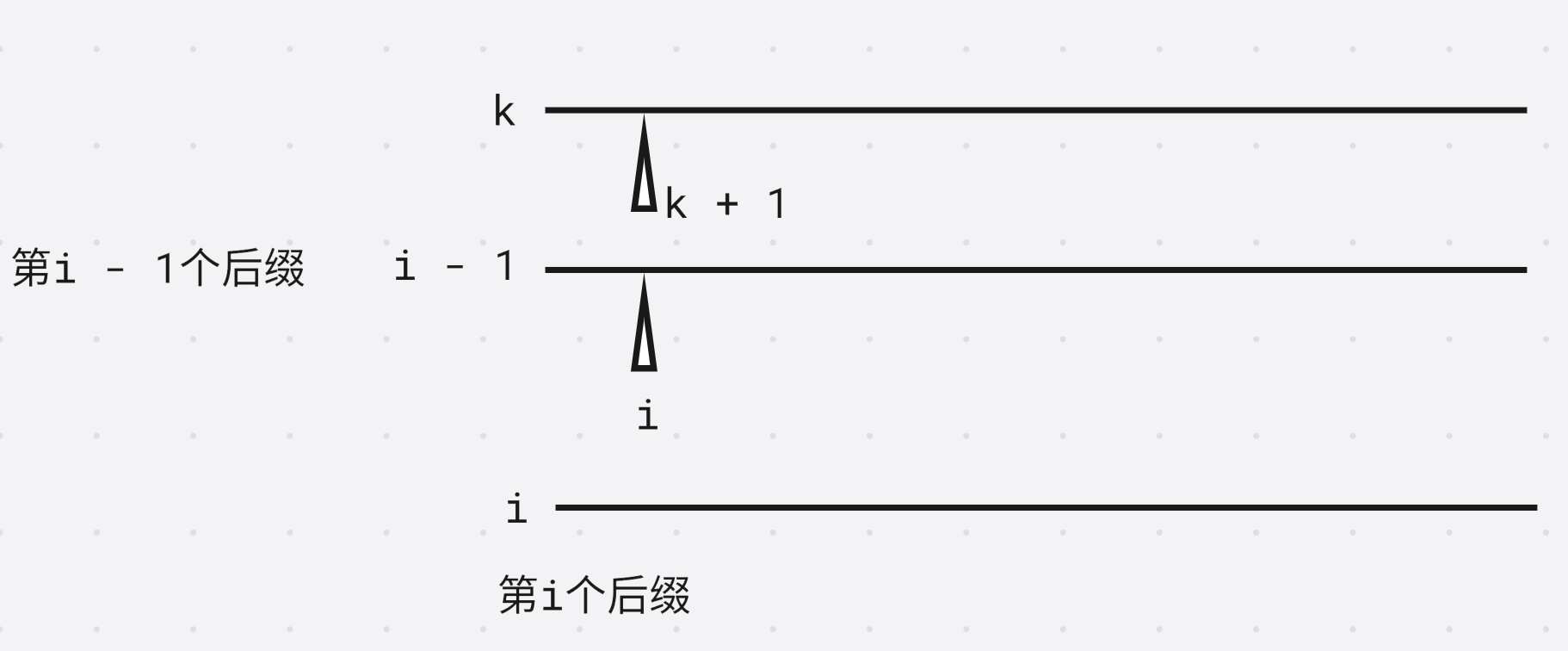
第 k + 1 k + 1 k+1个后缀在第 i i i个后缀的上面
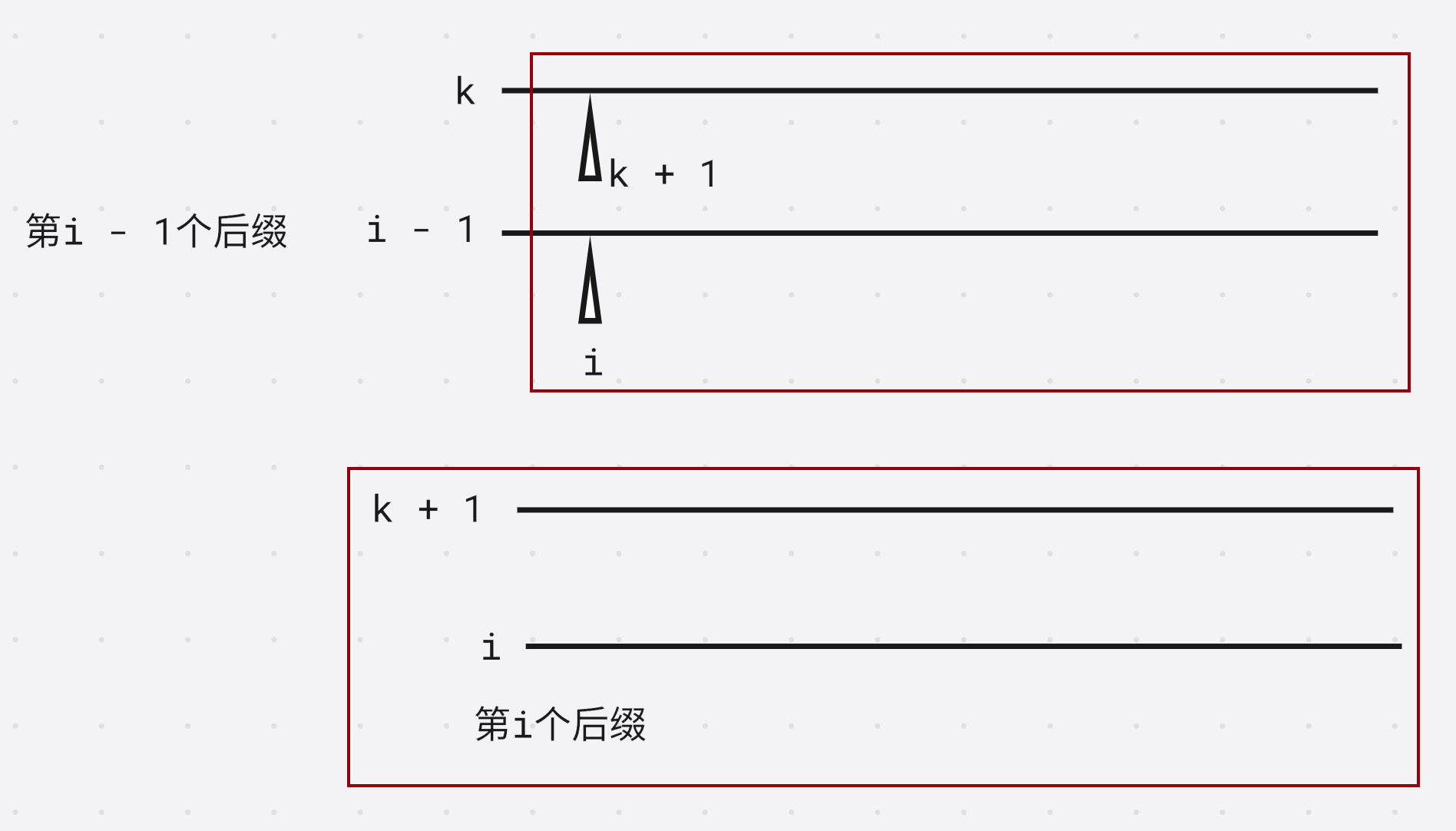
第 k + 1 k + 1 k+1个后缀和第 i i i个后缀的最长公共前缀等于, 第 i − 1 i - 1 i−1个后缀和第 k k k个后缀的最长公共前缀去掉第一个字符
因此第 k + 1 k + 1 k+1个后缀和第 i i i个后缀的最长公共前缀的长度就是 h [ i − 1 ] − 1 h[i - 1] - 1 h[i−1]−1

但是中间的后缀数量未知, 我们设中间某个后缀是 t t t, 那么由 l c p ( i , j ) = min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) = \min(lcp(i, k), lcp(k, j)) lcp(i,j)=min(lcp(i,k),lcp(k,j))可知 l c p ( k + 1 , i ) = min ( l c p ( t , i ) ) lcp(k + 1, i) = \min(lcp(t, i)) lcp(k+1,i)=min(lcp(t,i))
因为 l c p ( k + 1 , i ) lcp(k + 1, i) lcp(k+1,i)是取的最小值因此
l c p ( t , i ) ≥ l c p ( k + 1 , i ) lcp(t, i) \ge lcp(k + 1, i) lcp(t,i)≥lcp(k+1,i), 也就是有
h [ i ] ≥ h [ i − 1 ] − 1 h[i] \ge h[i - 1] - 1 h[i]≥h[i−1]−1
证毕
核心代码
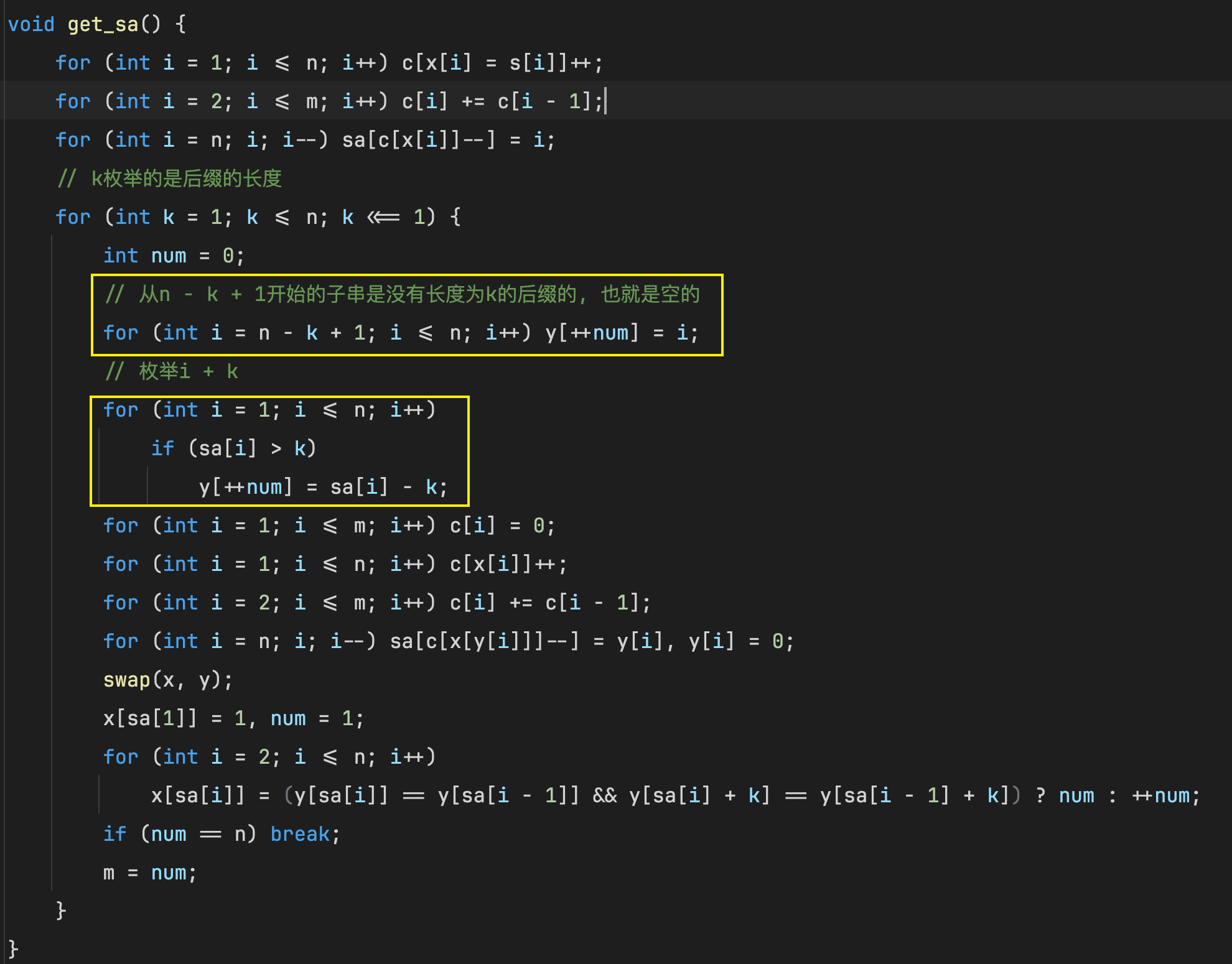
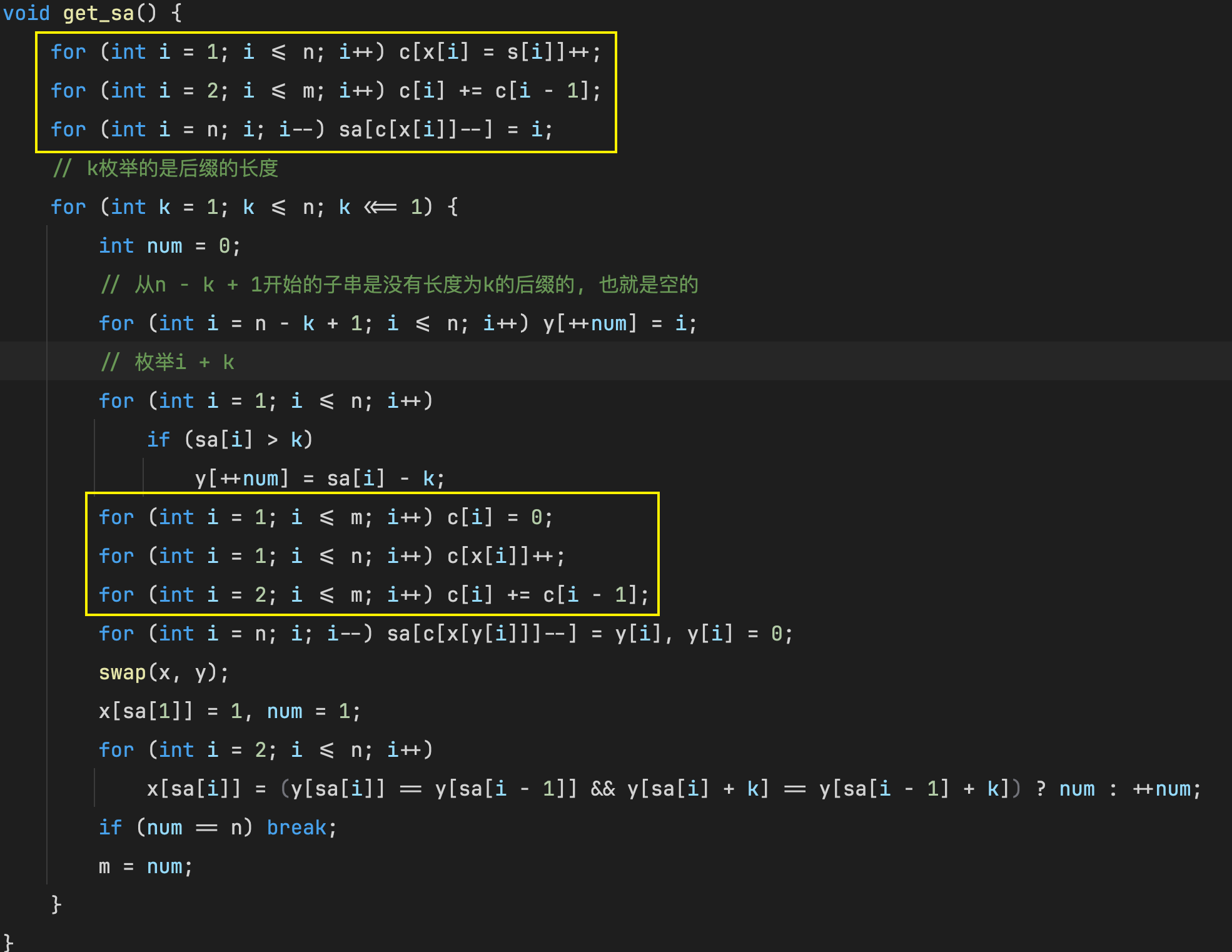
void get_sa() {
for (int i = 1; i <= n; ++i) c[x[i] = s[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
for (int i = n; i; --i) sa[c[x[i]]--] = i;
for (int k = 1; k <= n; k <<= 1) {
int num = 0;
for (int i = n - k + 1; i <= n; ++i) y[++num] = i;
// 希望求出排名为t的第二关键字, 实际求是求排名t + k的第一关键字, 枚举排名为t + k的后缀
for (int i = 1; i <= n; ++i) {
if (sa[i] > k) y[++num] = sa[i] - k;
}
// 清空基数排序数组, 再按照第一关键字排序
for (int i = 1; i <= m; ++i) c[i] = 0;
for (int i = 1; i <= n; ++i) c[x[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
// y存放t + k的第一关键字, 实际就是t的第二关键字, c是基数排序的桶, 获取到排名后数量减少
for (int i = n; i; --i) sa[c[x[y[i]]]--] = y[i], y[i] = 0;
// 将x信息存在y中
swap(x, y);
x[sa[1]] = 1, num = 1;
// 现在已经将前2k个字符排好序了, 然后将每个后缀的前2k个字符构成的子串离散化在下一轮排序的时候可以作为关键字参与排名
for (int i = 2; i <= n; ++i) {
x[sa[i]] = y[sa[i]] == y[sa[i - 1]] && y[sa[i] + k] == y[sa[i - 1] + k] ? num : ++num;
}
if (num == n) break;
m = num;
}
}
求 h e i g h t height height数组的代码
void get_height() {
for (int i = 1; i <= n; ++i) rk[sa[i]] = i;
for (int i = 1, k = 0; i <= n; ++i) {
if (rk[i] == 1) continue;
if (k) k--;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k]) k++;
height[rk[i]] = k;
}
}
算法步骤
-
将所有后缀按照第一个字符排序
-
枚举后缀长度 k k k, k k k每次倍增
-
对于当前后缀 t t t需要先按照第二关键字排序, t t t的第二关键字就是 t + k t + k t+k的第一关键字, 枚举 t + k t + k t+k
-
再按照第二关键字逆序排第一关键字, 得到的相对顺序不会发生改变
-
这样就处理好了前 2 k 2k 2k个字符, 将前 2 k 2k 2k个字符的后缀离散化
-
重复该过程直到所有的后缀的排好序
示例代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int n, m;
string s;
int sa[N], x[N], y[N], c[N], rk[N], height[N];
void get_sa() {
for (int i = 1; i <= n; ++i) c[x[i] = s[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
for (int i = n; i; --i) sa[c[x[i]]--] = i;
for (int k = 1; k <= n; k <<= 1) {
int num = 0;
for (int i = n - k + 1; i <= n; ++i) y[++num] = i;
// 希望求出排名为t的第二关键字, 实际求是求排名t + k的第一关键字, 枚举排名为t + k的后缀
for (int i = 1; i <= n; ++i) {
if (sa[i] > k) y[++num] = sa[i] - k;
}
// 清空基数排序数组, 再按照第一关键字排序
for (int i = 1; i <= m; ++i) c[i] = 0;
for (int i = 1; i <= n; ++i) c[x[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
// y存放t + k的第一关键字, 实际就是t的第二关键字, c是基数排序的桶, 获取到排名后数量减少
for (int i = n; i; --i) sa[c[x[y[i]]]--] = y[i], y[i] = 0;
// 将x信息存在y中
swap(x, y);
x[sa[1]] = 1, num = 1;
// 现在已经将前2k个字符排好序了, 然后将每个后缀的前2k个字符构成的子串离散化在下一轮排序的时候可以作为关键字参与排名
for (int i = 2; i <= n; ++i) {
x[sa[i]] = y[sa[i]] == y[sa[i - 1]] && y[sa[i] + k] == y[sa[i - 1] + k] ? num : ++num;
}
if (num == n) break;
m = num;
}
}
void get_height() {
for (int i = 1; i <= n; ++i) rk[sa[i]] = i;
for (int i = 1, k = 0; i <= n; ++i) {
if (rk[i] == 1) continue;
if (k) k--;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k]) k++;
height[rk[i]] = k;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> s;
n = s.size();
s = ' ' + s;
m = 122;
get_sa();
get_height();
for (int i = 1; i <= n; ++i) cout << sa[i] << ' ';
cout << '\n';
for (int i = 1; i <= n; ++i) cout << height[i] << ' ';
cout << '\n';
return 0;
}
*NOIP2015品酒大会


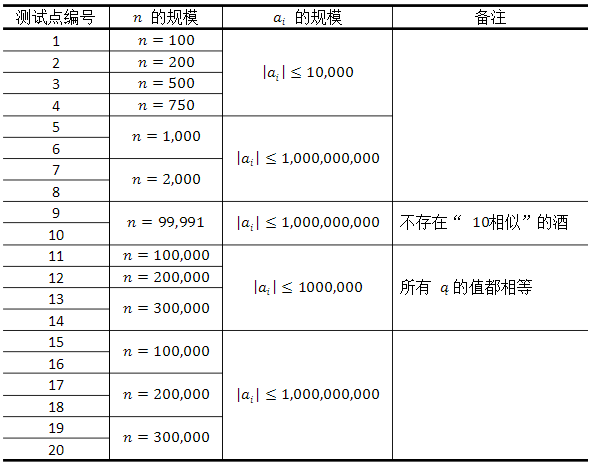
两个问, 第一个是有多少对 r r r相似的酒对, 第二问是在所有 r r r相似的酒对中的美味度乘积的最大值
n ≤ 3 × 1 0 5 n \le 3 \times 10 ^ 5 n≤3×105
对 h e i g h t height height分段
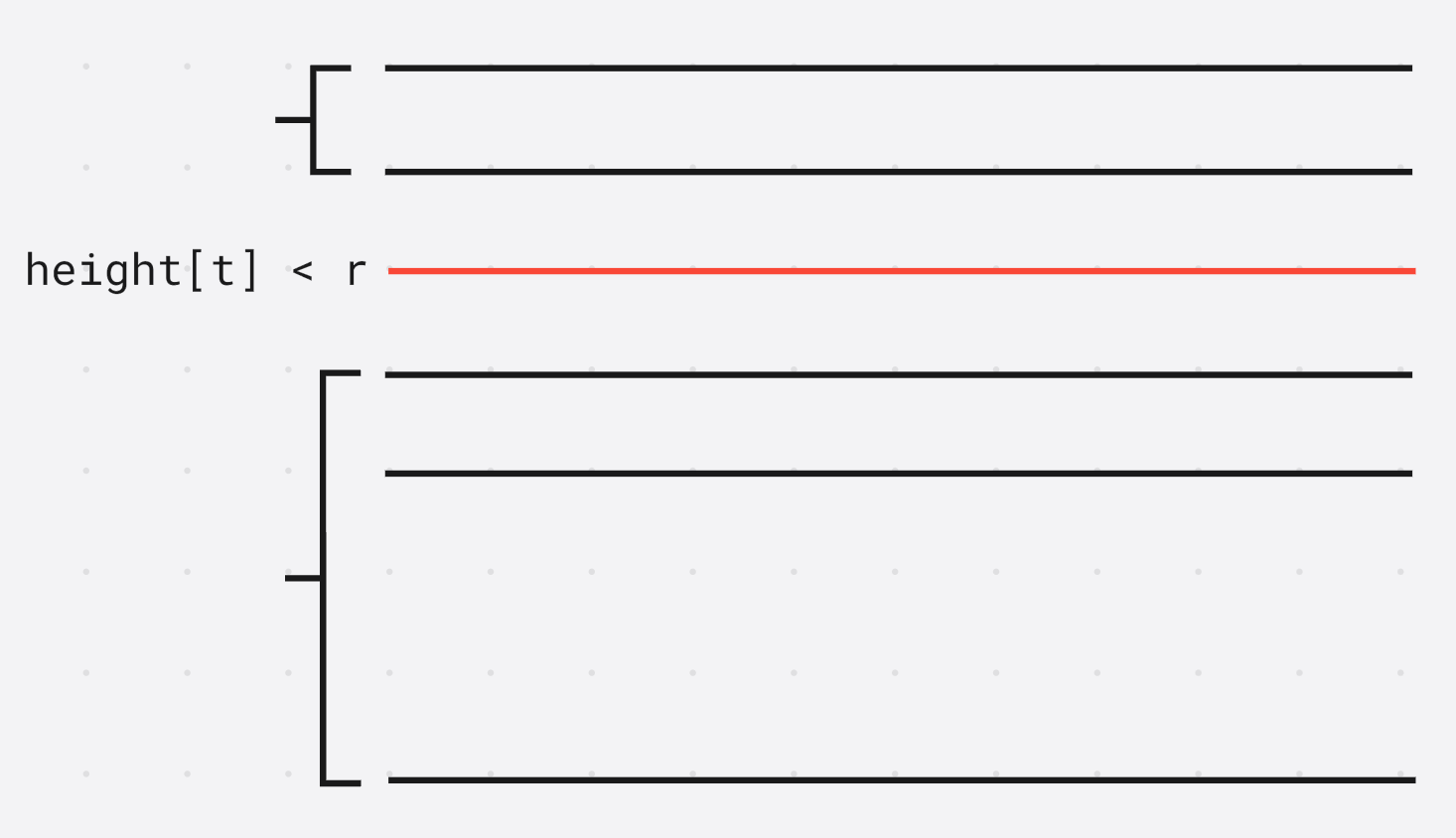
对于 h e i g h t [ i ] < r height[i] < r height[i]<r的情况作为分界线, 将真个数组进行分段
因为 l c p ( i , j ) = min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) = \min(lcp(i, k), lcp(k, j)) lcp(i,j)=min(lcp(i,k),lcp(k,j)), r r r相似的酒只能发生在段内, 如果跨段就会导致最小值 < r < r <r
假设分段之后每段的数量是 s s s, 那么答案就是 ∑ C s 2 \sum C_s ^ 2 ∑Cs2
乘积最大化三种情况
- 两个正数相乘, 最大 × \times ×次大
- 负数相乘, 最小 × \times ×次小
- 一正一负只有两个数, 最大 × \times ×次大
维护每一个段内的最大值, 次小值, 最小值, 次小值
因为 r r r如果从 0 0 0开始枚举, 最开始所有 h e i g h t height height都可以考虑, 但是随着 r r r增大需要分裂, 不好操作
r r r需要枚举所有情况, 按照从大到小枚举所有 r r r, 每次变小需要合并一些段, 这样就好维护最大值, 次小值, 最小值, 次小值
动态维护集合的合并可以用并查集维护
算法时间复杂度 O ( n log n ) O(n \log n) O(nlogn)
#include <bits/stdc++.h>
#define x first
#define y second
using namespace std;
typedef long long LL;
typedef pair<LL, LL> PLL;
const int N = 3e5 + 10;
const LL INF = 2e18;
int n, m;
string s;
int sa[N], rk[N], x[N], y[N], c[N], height[N];
int w[N], p[N], sz[N];
LL max1[N], max2[N], min1[N], min2[N];
vector<int> hs[N];
PLL ans[N];
int find(int x) {
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
void get_sa() {
for (int i = 1; i <= n; ++i) c[x[i] = s[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
for (int i = n; i; --i) sa[c[x[i]]--] = i;
for (int k = 1; k <= n; k <<= 1) {
int num = 0;
for (int i = n - k + 1; i <= n; ++i) y[++num] = i;
for (int i = 1; i <= n; ++i) {
if (sa[i] > k) y[++num] = sa[i] - k;
}
for (int i = 1; i <= m; ++i) c[i] = 0;
for (int i = 1; i <= n; ++i) c[x[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
for (int i = n; i; --i) sa[c[x[y[i]]]--] = y[i], y[i] = 0;
swap(x, y);
x[sa[1]] = 1, num = 1;
for (int i = 2; i <= n; ++i) {
x[sa[i]] = y[sa[i]] == y[sa[i - 1]] && y[sa[i] + k] == y[sa[i - 1] + k] ? num : ++num;
}
if (num == n) break;
m = num;
}
}
void get_height() {
for (int i = 1; i <= n; ++i) rk[sa[i]] = i;
for (int i = 1, k = 0; i <= n; ++i) {
if (rk[i] == 1) continue;
if (k) k--;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k]) k++;
height[rk[i]] = k;
}
}
LL C(LL a) {
return (a - 1ll) * a / 2ll;
}
PLL solve(int r) {
static LL cnt = 0, maxv = -INF;
for (auto x : hs[r]) {
int a = find(x - 1), b = find(x);
cnt -= C(sz[a]) + C(sz[b]);
p[a] = b, sz[b] += sz[a];
cnt += C(sz[b]);
vector<LL> tmp = {
max1[a], max2[a], max1[b], max2[b]};
sort(tmp.begin(), tmp.end(), greater<LL>());
max1[b] = tmp[0], max2[b] = tmp[1];
tmp.clear();
tmp = {
min1[a], min2[a], min1[b], min2[b]};
sort(tmp.begin(), tmp.end());
min1[b] = tmp[0], min2[b] = tmp[1];
maxv = max({
maxv, max1[b] * max2[b], min1[b] * min2[b]});
}
if (maxv == -INF) return {
cnt, 0};
return {
cnt, maxv};
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n, m = 122;
cin >> s;
s = ' ' + s;
for (int i = 1; i <= n; ++i) cin >> w[i];
get_sa();
get_height();
for (int i = 2; i <= n; ++i) hs[height[i]].push_back(i);
for (int i = 1; i <= n; ++i) {
p[i] = i, sz[i] = 1;
max1[i] = min1[i] = w[sa[i]];
max2[i] = -INF, min2[i] = INF;
}
for (int r = n - 1; r >= 0; --r) ans[r] = solve(r);
for (int i = 0; i < n; ++i) cout << ans[i].x << ' ' << ans[i].y << '\n';
return 0;
}
*生成魔咒

动态的过程
- 每次对字符串结尾添加一个字符
- 查询当前字符串子串的数量
首先考虑如何枚举子串, 首先枚举起点, 再枚举终点, 其实就是每个后缀 i i i的所有前缀的集合就是子串的集合, 因此可以使用后缀数组
首先考虑简单的情况, 对于固定的字符串, 有多少个不同的子串

因此对于固定的字符串, 结果就是
∑ l e n ( i ) − h e i g h t ( i ) \sum len(i) - height(i) ∑len(i)−height(i)
但是当前问题讨论的是有修改的情况, 如果在后面加一个字符, 会影响所有的后缀
但是可以反向考虑, 将字符串反转因为原串的不同子串的数量等价于反转之后的不同子串的数量
这样的好处是, 每次在前面添加一个字符, 最多添加一个后缀, 对已有的后缀是没有影响的
然后反向做这个问题, 先将所有串找出, 每次删除前面一个字符, 也就是删除一个前缀, 需要边删除边维护 h e i g h t height height数组
问题变为如何动态维护 h e i g h t ( i ) height(i) height(i)?
每次删除一个后缀相当于在排好序的后缀中删除一个序列
s a sa sa数组可以用一个双链表维护, 支持在 O ( 1 ) O(1) O(1)时间内删除
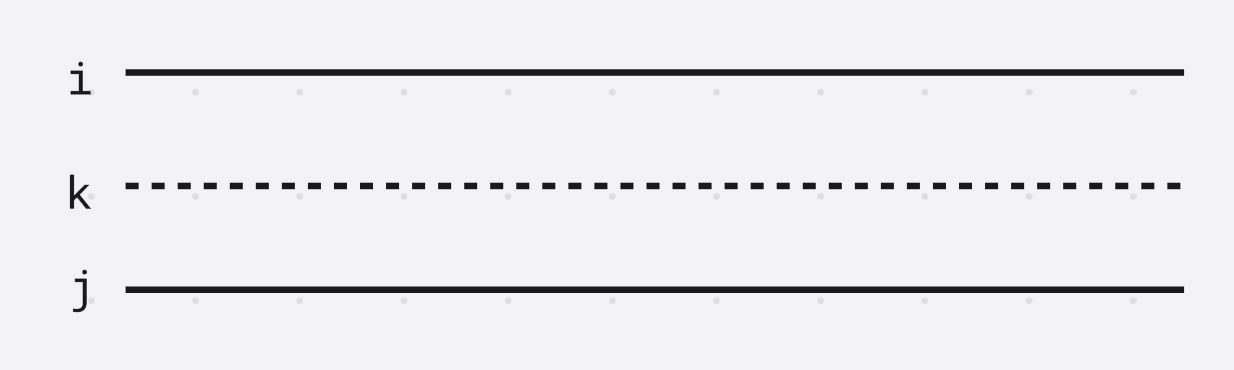
假设希望删除的序列是虚线部分 k k k, 对于 h e i g h t ( j ) = l c p ( j , k ) height(j) = lcp(j, k) height(j)=lcp(j,k), h e i g h t ( k ) = l c p ( k , i ) height(k) = lcp(k, i) height(k)=lcp(k,i)
现在要删除 k k k, h e i g h t ( j ) = l c p ( j , i ) height(j) = lcp(j, i) height(j)=lcp(j,i), 由性质 l c p ( i , j ) = min ( l c p ( i , k ) , l c p ( k , j ) ) lcp(i, j) = \min(lcp(i, k), lcp(k, j)) lcp(i,j)=min(lcp(i,k),lcp(k,j))可知, 新的 l c p ( j , i ) = min ( l c p ( k , i ) , l c p ( j , k ) ) lcp(j, i) = \min(lcp(k, i), lcp(j, k)) lcp(j,i)=min(lcp(k,i),lcp(j,k)), 也可以在 O ( 1 ) O(1) O(1)时间复杂度内计算出
示例代码
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n, m;
int s[N];
int sa[N], x[N], y[N], c[N], rk[N], height[N];
int u[N], d[N];
LL ans[N];
int get(int x) {
static unordered_map<int, int> hash;
if (!hash.count(x)) hash[x] = ++m;
return hash[x];
}
void get_sa() {
for (int i = 1; i <= n; ++i) c[x[i] = s[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
for (int i = n; i; --i) sa[c[x[i]]--] = i;
for (int k = 1; k <= n; k <<= 1) {
int num = 0;
for (int i = n - k + 1; i <= n; ++i) y[++num] = i;
for (int i = 1; i <= n; ++i) {
if (sa[i] > k) y[++num] = sa[i] - k;
}
for (int i = 1; i <= m; ++i) c[i] = 0;
for (int i = 1; i <= n; ++i) c[x[i]]++;
for (int i = 2; i <= m; ++i) c[i] += c[i - 1];
for (int i = n; i; --i) sa[c[x[y[i]]]--] = y[i], y[i] = 0;
swap(x, y);
x[sa[1]] = 1, num = 1;
for (int i = 2; i <= n; ++i) {
x[sa[i]] = y[sa[i]] == y[sa[i - 1]] && y[sa[i] + k] == y[sa[i - 1] + k] ? num : ++num;
}
if (num == n) break;
m = num;
}
}
void get_height() {
for (int i = 1; i <= n; ++i) rk[sa[i]] = i;
for (int i = 1, k = 0; i <= n; ++i) {
if (rk[i] == 1) continue;
if (k) k--;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k]) k++;
height[rk[i]] = k;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
for (int i = n; i; --i) cin >> s[i], s[i] = get(s[i]);
get_sa();
get_height();
LL res = 0;
for (int i = 1; i <= n; ++i) {
res += n - sa[i] + 1 - height[i];
u[i] = i - 1, d[i] = i + 1;
}
d[0] = 1, u[n + 1] = n;
for (int i = 1; i <= n; ++i) {
ans[i] = res;
int k = rk[i], j = d[k];
res -= n - sa[k] + 1 - height[k];
res -= n - sa[j] + 1 - height[j];
height[j] = min(height[j], height[k]);
res += n - sa[j] + 1 - height[j];
d[u[k]] = d[k], u[d[k]] = u[k];
}
for (int i = n; i; --i) cout << ans[i] << '\n';
return 0;
}

 京公网安备 11010502036488号
京公网安备 11010502036488号