

最近不是校招,刚好晚上睡不着,就随便整理一下numpy的东西啊,结果写嗨了。。直接写到四点,应该是把numpy讲差不多了,整体框架肯定是完整的,细节那么多,肯定不会刻意去涉及,不过核心点,大致都说了。建议小白读者跟着一块敲。 如果下载anconda,会自带numpy,如果没有的话,就直接
pip install numpy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
numpy类似于list,但与list对象有区别
- list可以存储多种数据类型,而numpy只能同时存储一种数据类型。
- numpy可以做到线性代数中的矩阵运算,list不可以。
- numpy由c语言实现,它的速度即使经过python解释器后在某些时候都可以直接与c语言比肩。而list作为python最基本的数据结构,它本身并不高效。
import numpy as np
a = np.arange(10,20,0.1)
print(a)
np.arange(): 生成一个numpy.array对象,参数类似于python中的range迭代器。
a = np.random.random((2,3))
print(a)
a = np.random.randint(1,10,(3,3))
print(a)
[[0.70153953 0.32359607 0.94127114]
[0.2967885 0.66102347 0.37332759]]
[[2 4 8]
[8 3 9]
[5 6 4]]
np.random. 随机生成np.array对象。
a = np.zeros((2,3))
print(a)
a = np.ones((2,3))
print(a)
a = np.full((2,3), 10)
print(a)
a = np.eye(3,3)
print(a)
[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]]
[[10 10 10]
[10 10 10]]
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
几个特殊函数生成几个特殊的np.array对象
np.array对象具有非常丰富的数据类型.
windows环境下,默认数据类型为np.uint32 mac与linux则需要看系统环境。
# np.asdtype()
a = np.array([1,2,3])
print(a.dtype)
a = a.astype(np.int64)
print(a.dtype)
int32
int64
a = np.random.randint(0,10,(2,3))
print(a,a.dtype)
# size获取元素个数,size是np.array的属性之一。
print(a.size)
# ndim获取对象的维度,ndim是np.array的属性之一。
print(a.ndim)
# shape获取对象整体维度,shape是np.array的属性之一。
print(a.shape)
# reshape进行维度转化
print(a.reshape(6,))
# itemsize获取对象每个元素占据的字节,这个4=32/8,每个字节8位总共32位。
print(a.itemsize)
[[2 3 1]
[3 7 0]] int32
6
2
(2, 3)
[2 3 1 3 7 0]
4
## numpy.array可以进行矩阵运算的原因是因为它具有广播机制。
a = np.random.randint(0,10,(2,3))
print(a)
print(a*10)
print(a/2)
# round(n)对象保留n位小数
print((a/3).round(2))
# 这种独特的广播机制甚至可以进行不同行不同列的运算,(在同列的情况下,多行和一行的运算,在同行的情况下,多列和一列的运算。np.array对象的
# 广播机制是通过默缘维度来进行计算的。)
[[1 4 8]
[8 1 6]]
[[10 40 80]
[80 10 60]]
[[0.5 2. 4. ]
[4. 0.5 3. ]]
[[0.33 1.33 2.67]
[2.67 0.33 2. ]]
维度转换的两种方法
reshape与resize
# reshape进行一份copy返回,改变后的数据,但不影响原数据
# resize直接改变原数据,调用方法。
a = np.random.randint(0,10,(2,3))
print(a)
a_1 = a.reshape(6,)
print(a)
print(a_1)
a.resize(6,)
print(a)
[[8 8 1]
[2 7 2]]
[[8 8 1]
[2 7 2]]
[8 8 1 2 7 2]
[8 8 1 2 7 2]
# flatten和ravel
# flatten是拷贝返回
# ravel是视图返回,两者区别在于对返回值的操作是否影响到原对象
a = np.random.randint(0,10,(2,3))
print(a)
b = a.flatten()
b[1] = 3
print(a)
# 可以看到a不受影响
[[4 1 0]
[4 3 8]]
[[4 1 0]
[4 3 8]]
a = np.random.randint(0,10,(2,3))
print(a)
b = a.ravel()
b[1] = 3
print(a)
# 可以观察到a直接受到了影响。
[[1 0 9]
[7 7 7]]
[[1 3 9]
[7 7 7]]
## np.array的对象拼接。
# vstack与hstack与concatenate
a1 = np.random.randint(0,10,size=(3,5))
a2 = np.random.randint(0,10,size=(1,5))
a3 = np.vstack([a1,a2])
print(a3)
[[6 4 9 8 2]
[6 3 0 3 0]
[2 0 7 9 6]
[2 8 1 3 0]]
# hstack行拼接
a1 = np.random.randint(0,10,size=(3,2))
a2 = np.random.randint(0,10,size=(3,1))
a3 = np.hstack([a1,a2])
print(a3)
[[1 3 1]
[4 2 4]
[8 2 6]]
# concatenate利用axio这个参数进行拼接方向的确定。
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
c = np.concatenate((a, b), axis=0)
print(c)
[[1 2]
[3 4]
[5 6]]
## 数组分割,利用hsplit,vsplit,该操作可以直接实现多重分割。
a = np.arange(16.0).reshape(4, 4)
print(a)
b,c = np.hsplit(a,2)
print(b)
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
[[ 0. 1.]
[ 4. 5.]
[ 8. 9.]
[12. 13.]]
a = np.arange(16.0).reshape(4, 4)
print(a)
b,c,d = np.hsplit(a,np.array([1,2]))
print(b)
print(c)
print(d)
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
[[ 0.]
[ 4.]
[ 8.]
[12.]]
[[ 1.]
[ 5.]
[ 9.]
[13.]]
[[ 2. 3.]
[ 6. 7.]
[10. 11.]
[14. 15.]]
做个小测试对比一下list与np.array的速度。
- 构建一个很大的数组。
- 构建一个计算函数时间的函数。 2.1 time库 2.2 函数装饰器
- 将两种分割方法封装到函数中。 3.1 传入可控默认参数
- 计算同样条件下的时间差,并可视化(绘图) 3.2 利用matplotlib
def func_time(func):
from time import time
def init_func(*args,**kwargs):
start = time()
func_return = func(*args,**kwargs)
end = time()
return func_return, end-start
return init_func
def get_num(n=10000):
re_num = np.arange(n)
return re_num
@func_time
def h_split_list(data,n = 5000):
np.hsplit(data,[i for i in range(n)])
return None
@func_time
def h_split_np(data,n = 5000):
np.hsplit(data,np.arange(0,n,1))
return None
from tqdm import tqdm
# 直接选取一百万数据
data = get_num(1000000)
time_np = np.zeros((10000,2)).astype(np.float64)
for i in tqdm(range(50000,60000)):
time_l = h_split_list(data, i)[1]
time_n = h_split_np(data, i)[1]
time_np[i-50000] = np.array([time_l, time_n])
100%|████████████████████████████████████████████████████████████████████████████| 10000/10000 [25:28<00:00, 6.54it/s]
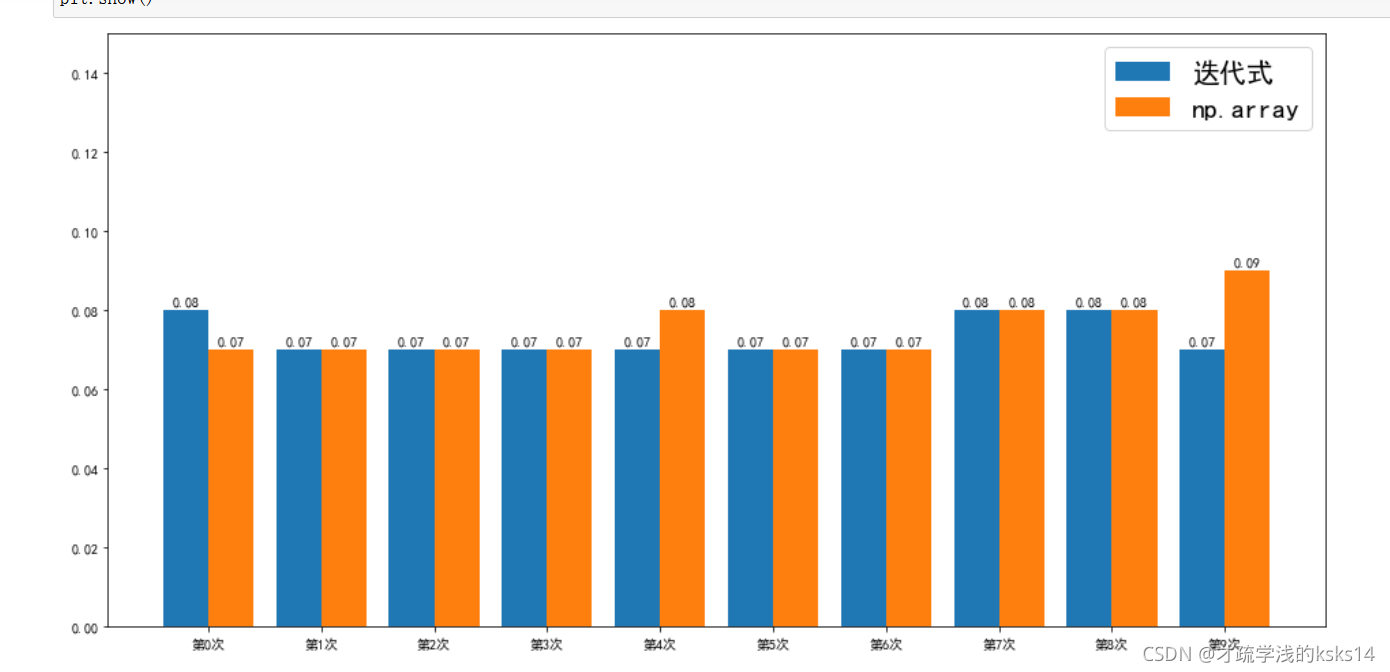
## 经过测试发现,在一维的情况下,迭代式和np.arange的速度并不会相差太多。但循环的速度却明显慢于他们,根据数据所得:
## 循环<迭代式 and 循环<np.array and 迭代式≈np.array
array([[0.07489157, 0.08552456],
[0.07862067, 0.08474588],
[0.08583903, 0.07922769],
[0.07734418, 0.08843541],
[0.0754838 , 0.09528446],
[0.08944893, 0.07870269],
[0.08104563, 0.08205676],
[0.08094621, 0.08138871],
[0.08068252, 0.07709312],
[0.07414293, 0.0772562 ]])
print(['第'+str(i+1)+'次' for i in range(0,10000,1000)])
['第1次', '第1001次', '第2001次', '第3001次', '第4001次', '第5001次', '第6001次', '第7001次', '第8001次', '第9001次']
len(time_np)
10000
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['figure.figsize'] = (16.0, 8.0) # 设置figure_size尺寸
plt.rcParams['image.interpolation'] = 'nearest' # 设置 interpolation style
plt.rcParams['image.cmap'] = 'gray' # 设置 颜色 style
res_1 = plt.bar([i for i in range(10)],np.hsplit(time_np[0:10000:1000], 2)[0].flatten().round(2),width=0.4, label="迭代式")
res_2 = plt.bar([i+0.4 for i in range(10)],np.hsplit(time_np[0:10000:1000], 2)[1].flatten().round(2),width=0.4, label='np.array')
plt.ylim(0, 0.15)
plt.xticks([i + 0.2 for i in range(10)], ['第{}次'.format(i) for i in range(10)])
plt.legend(fontsize=20)
for rect in res_1:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+0.001, str(height), ha="center", va="bottom")
for rect in res_2:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+0.001, str(height), ha="center", va="bottom")
plt.show()
# 不拷贝,即简单的复制,类似于a = b
a = np.arange(16.0).reshape(4, 4)
b = a
print(b)
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
# 浅拷贝或者叫视图,即复制,但指向同一内存,
a = np.arange(16.0).reshape(4, 4)
b = a.view()
print(b)
b[0][0] = 1
print(a)
# 可以看到改变b的同时改变了a,这说明他们指向同一内存空间。
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
[[ 1. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
# 深拷贝,复制这个变量的一切,包括空间,通过.copy()完成。
a = np.arange(16.0).reshape(4, 4)
print(a)
b = a.copy()
b[0][0] = 5
print(a)
# 可以观察到赋值并不影响到a。
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
现在再来分析之前flatten和ravel它们的区别就在于浅拷贝和深拷贝。ravel()方法就是视图操作,而flatten就是深拷贝操作。
numpy中有一种独特的存储np.array对象的文件类型。如下:
fname = 'test_np.npy'
a = np.arange(16.0).reshape(4, 4)
np.save(fname,a)
# 加载
data = np.load(fname)
print(data)
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
这种结构的出现无疑是加快了numpy对于文件操作的速度。
csv文件处理
import csv
with open('stock.csv','r',newline='') as fp:
reader = csv.reader(fp)
header = next(reader)
print(header)
for line in reader:
#print(line)
continue
['index', 'secID', 'ticker', 'secShortName', 'exchangeCD', 'tradeDate', 'preClosePrice', 'openPrice', 'highestPrice', 'lowestPrice', 'closePrice', 'turnoverVol']
观察可知,csv读取后,每一行得到的值是一个列表,之前就已经说过,这并不高效,因此其实对于更大的数据,应该是采用pandas处理的,不过csv也是必修。列表中显然都是字符串数据,其实csv也是纯文本文件,所以才会这样。
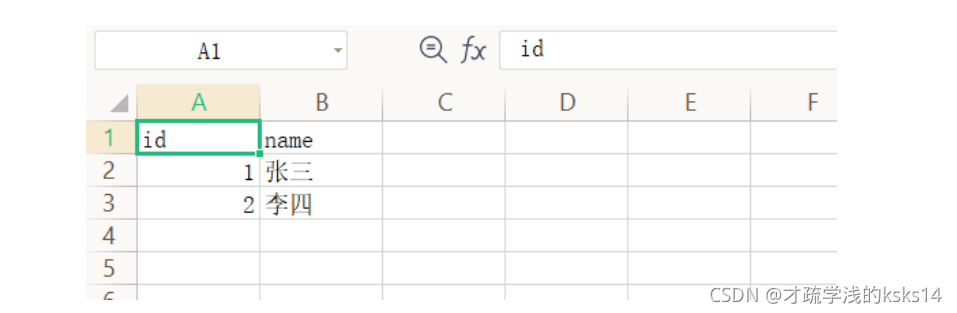
# 写入csv文件,在基本的结构中,可以利用两种文件格式,列表或者字典:[] or {},但是要注意创建写入对象的方式不同。举例如下:
header = ['id','name']
with open('test_1.csv','w',newline='',encoding='utf-8') as fp:
values = [
('1','张三'),
('2','李四'),
]
writer = csv.writer(fp)
writer.writerow(header)
writer.writerows(values)
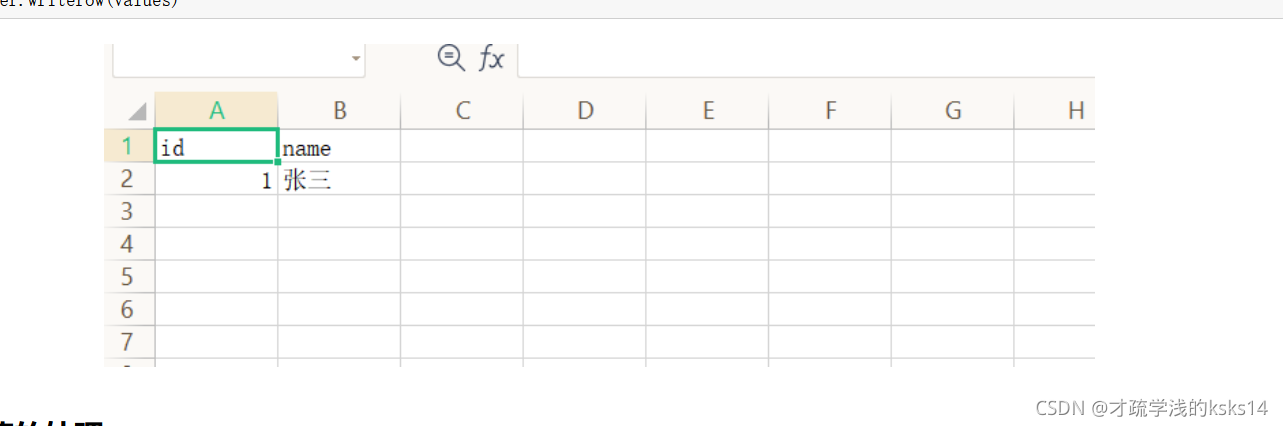
header = ['id','name']
with open('test_2.csv','w',newline='',encoding='utf-8') as fp:
values = {'id':'1', 'name':'张三'}
writer = csv.DictWriter(fp,header)
# 这里注意创建对象之后一定要先写入头部,否则后续不会写入,这里有个问题,为什么,在创建对象的时候没有把头部写进去,我也不是很明白,应该是
# 设计的时候产生了一些漏洞。
writer.writeheader()
writer.writerow(values)
特殊值的处理
# NAN与INF,NAN将其视为缺失值,INF将其视为无穷大。
# NAN与NAN是不相等的,如下:
if np.NAN != np.NAN :
print('测试')
测试
# 在进行数据分分析前,往往要先对缺失值做处理。可利用逻辑运算和np.array.isnan进行处理。
data = np.random.randint(0,10,size=(3,5)).astype(np.float64)
data[0,1] = np.nan
print(data)
data = data[~np.isnan(data)]
# 由于产生了缺失值,因此np.array对象成为了一维。
print(data)
[[ 6. nan 9. 6. 7.]
[ 1. 3. 1. 9. 2.]
[ 3. 7. 2. 1. 5.]]
[6. 9. 6. 7. 1. 3. 1. 9. 2. 3. 7. 2. 1. 5.]
# 可以通过删除行,但是同样会导致数据缺失,该方法可适用于,仅对于完整行的计算,删除无效行。
# 删除NAN所在的行
data = np.random.randint(0,10,size=(3,5)).astype(np.float64)
# 将第(0,1)和(1,2)两个值设置为NAN
data[[0,1],[1,2]] = np.NAN
print(data)
# 获取哪些行有NAN
lines = np.where(np.isnan(data))[0]
# 使用delete方法删除指定的行,axis=0表示删除行,lines表示删除的行号,一般情况下axis=0表示对行级别操作,axis=1表示对列级别操作。
data1 = np.delete(data,lines,axis=0)
print(data1)
[[ 2. nan 7. 9. 1.]
[ 4. 8. nan 1. 3.]
[ 2. 3. 0. 4. 6.]]
[[2. 3. 0. 4. 6.]]
最好的方法是利用其他值进行替代,例如提取列均值或者行均值填充。
scores = np.loadtxt("nan_scores.csv",skiprows=1,delimiter=",",encoding="utf-8",dtype=np.str_)
# 对空字符进行操作
scores[scores == ""] = np.NAN
print(scores)
# 转化数据格式
scores = scores.astype(np.float64)
# 求出每一列的sum或者均值
scores1=scores.copy()
# 求出每门成绩的平均分
scores2 = scores.copy()
for x in range(scores2.shape[1]):
score = scores2[:,x]
non_nan_score = score[score == score]
score[score != score] = non_nan_score.mean()
print(scores2.mean(axis=0))
[['59' '89']
['90' '32']
['78' '45.5']
['34' 'nan']
['nan' '56']
['23' '56']]
[56.8 55.7]
如上就是利用np.array对象和逻辑对NAN值进行了一个巧妙的处理并计算了他们的均值。
# 查看NAN与INF的类型
print(type(np.NAN))
print(type(np.Inf))
# 这里查看得到显然,它们的类型都是float。但是注意它们都是不可以取dtype属性的。
<class 'float'>
<class 'float'>
random模块
random模块随机库,不论是python还是numpy都是必修,方法必须掌握,它甚至在后期的机器学习中都非常重要。 这里有一点属于常识,不论是什么random,java也好,c++也好,python也好,他们的随机都是伪随机,并非我们在日常生活中蒙着眼睛去蒙那样的真随机。 这点由计算机决定,没有办法改变,至少目前是没有什么办法做到真随机。不过有一个特别有意思呀,就是,咱不都说什么遇事不决,量子力学,还真可以 真随机可以在量子世界中产生,为啥呢,因为理论上量子世界中有些东西在原则是无法预测的,而我们的计算机产生随机数的原理,就是通过一个数字进行 一系列的运算,这就很有意思呀,因为只要是一样的数据,经过成千上万次运算他也还是那样,所以只能通过不断改变引入的这个数字,但是改变的过程也 是可计算的呀,所以目前的计算机做不到真随机啊。
# 就肯定有人不相信呀,说吹牛,怎么不能随机呀,理论搁那摆着了,试一下就知道啦。
# 设置随机数种子
np.random.seed(1)
print(np.random.rand())
print(np.random.rand())
# 这段代码可以一直跑呀,我打包票它的值不会变呀。
0.417022004702574
0.7203244934421581
# np.random.rand()最常用的随机,它的产生符合正态分布,但是范围默认规定到了0~1之间,正态分布在下个代码块。
print(np.random.rand(1,2))
print(np.random.rand(2,2))
[[0.14675589 0.09233859]]
[[0.18626021 0.34556073]
[0.39676747 0.53881673]]
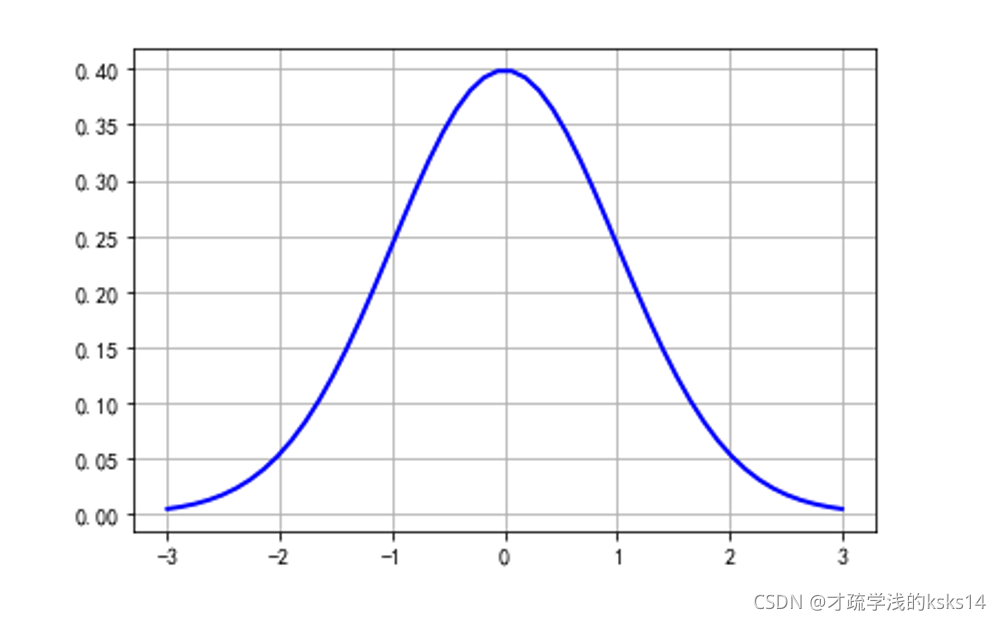
import math
import numpy as np
import matplotlib.pyplot as plt
u = 0 # 均值μ
sig = math.sqrt(1) # 标准差δ
# 规范定义域
x = np.linspace(u - 3*sig, u + 3*sig, 50)
# 正太分布函数曲线
y = np.exp(-(x - u) ** 2 / (2 * sig ** 2)) / (math.sqrt(2*math.pi)*sig)
plt.plot(x, y, "b", linewidth=2) # 加载曲线
plt.grid(True) # 网格线
plt.show() # 显示
# random.randint():随机产生整形数据的np.array
data1 = np.random.randint(10,size=(3,5))
print(data1)
[[5 2 4 2 4]
[7 7 9 1 7]
[0 6 9 9 7]]
# 随机采样,抽取数据
data = [4,65,6,3,5,73,23,5,6]
result1 = np.random.choice(data,size=(2,3)) #从data中随机采样,生成2行3列的数组
print(result1)
result2 = np.random.choice(data,3) #从data中随机采样3个数据形成一个一维数组
print(result2)
result3 = np.random.choice(10,3) #从0-10之间随机取3个值
print(result3)
[[65 3 5]
[ 6 65 5]]
[4 3 6]
[0 4 9]
# 随机打乱
a = np.arange(10)
print(a)
np.random.shuffle(a)
print(a)
[0 1 2 3 4 5 6 7 8 9]
[6 0 2 8 1 3 4 5 9 7]
以上演示的其实都是很重要的呀,但它不代表其他不重要,总之能记还是尽量多记一些呀,都是码农嘛,记得越多越好。

可能有人会问正态分布到底是个啥哈。。。这个。。就不解释了,直接上个公式吧,一个密度函数,一个分布函数,推导过程写到这,大家自己把。如下图:


 京公网安备 11010502036488号
京公网安备 11010502036488号