


总体设计
[TOC]
背景
每个系统都有自己的负载能力上限,当访问超过这个能力上限的时候,系统就会变得不稳定,甚至无法正常响应。因此,无论是对外请求还是对内的请求,都存在着流量控制的需要。防止自身被外部流量冲垮,防止自身外部请求过多压垮外部系统。Sentinel 就是这样的一个负责流量控制的组件。
流量控制是一个大的概念,从流量控制的角度出发,会有不同的场景,包括但不限于限流,流量整形、熔断降级等。
重点概念
在介绍 Sentinel 的实现思路前,先需要了解 Sentinel 中几个重要的概念定义,分别是资源、条目、节点。Sentinel 的流量控制就是在这几个概念上执行。
资源
资源是一个抽象的指代,所有需要被限流保护的内容都可以看成是资源。从代码的角度来说,资源可以看成是某一段可以执行的代码。比方说需要用限流来保护一个下游服务提供者暴露的 Http 的接口。那么可以将这个接口看成是资源,也可以将调用这个接口本身的一部分代码看成是资源,都是可以的,效果也都是相同的。
在 Sentinel 中,资源是使用ResourceWrapper类来表示,其核心属性如下
protected final String name; protected final EntryType entryType; protected final int resourceType;
分别是资源的名称,该资源的访问方向,该资源的类型。
名称不用解释,资源类型就是用户自行定义的整型变量,方便在需要的时候进行识别。
资源的访问方向是一个枚举类型,有两个取值:
- IN ,入站流量。
- OUT,出站流量。
入站流量,代表着从外部发起的对内部的访问;出站流量,代表着是从本地发起的,对外部或内部的访问。
条目
条目,即Entry,代表着具体一次对某个资源的访问。其持有的属性如下
private final long createTimestamp; private long completeTimestamp; private Node curNode; private Throwable error; private BlockException blockError; protected final ResourceWrapper resourceWrapper;
构造方法中完成了createTimestamp创建时间和resourceWrapper资源描述的初始化。
如果资源访问被限流了,则blockError会被设置值。如果发生了业务异常,则error会被设置值。
curNode属性,是该资源对应的统计节点指向。该属性会在处理链条NodeSelectorSlot槽位中被设置。
节点
节点,即Node,功能是持有某个资源的访问统计信息。来看下类图
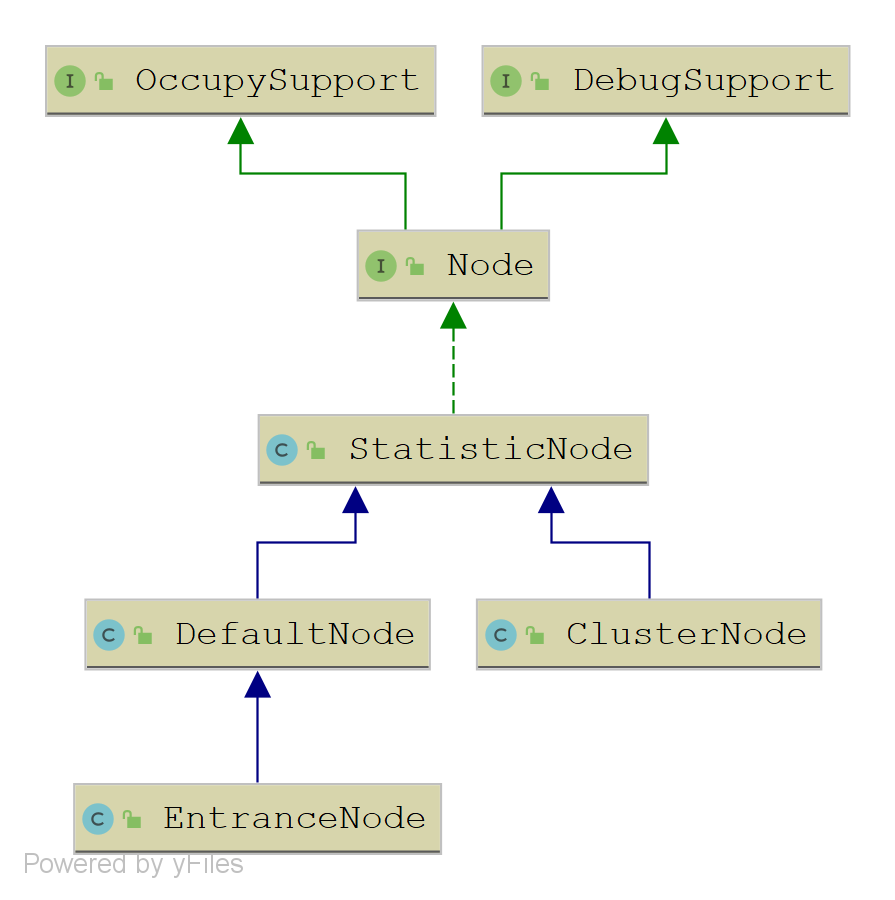
访问统计是在StatisticNode中实现的,其采用高效的滑动窗口算法实现访问数据统计。
DefaultNode相比StatisticNode增加了2个功能:
- 存储资源对应的聚集节点,也就是属性
clusterNode。DefaultNode是被资源名称和上下文唯一区分的。而聚集结点ClusterNode则是被资源名称唯一区分。也就是说两者统计的范围是不一样的。聚集节点统计的就是资源的访问情况,而默认节点统计的是在某个上下文中资源的访问情况。 - 存储后续访问节点,也即是属性
childList。在一个访问之中,可能会顺序访问多个资源,形成一个资源的调用树。比如在 A 资源之后访问 B 资源,则 A 资源对应的节点 a 的孩子节点就包含 B 资源对应的节点 b 。这意味着通过节点访问树的关系可以看出系统中资源的访问关系。
ClusterNode没有增加新的功能,只是用于存储资源的访问情况,用以和DefaultNode区分。访问统计在StatisticNode中实现,但是不直接使用,而是使用DefaultNode和ClusterNode,主要就是为了明确其不同的统计范围场景。
EntranceNode用于表示调用树的入口。在最简单的情况下,访问一个资源会形成如下的调用树
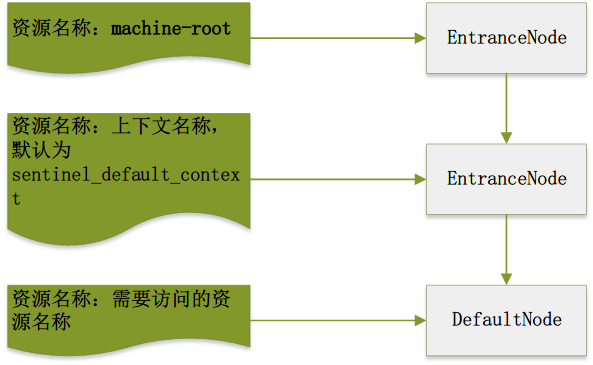
第一个层级,machine-root 这个 EntranceNode 节点是一个静态全局变量,JVM 内唯一,并且资源名称是框架直接指定的。
第二个层级,对应的是标识上下文的 EntranceNode 节点,其资源名称就是上下文的名称。在框架中,如果不指定的话,框架会使用默认的上下文名称,也就是 sentinel_default_context 。
第三个层级,对应的是标识需要访问资源的 DefaultNode 节点。框架中规定了,只有 Root 节点和上下文节点使用 EntranceNode 来标识,资源都是使用 DefaultNode 来标识。
调用树最短是三个层级,长则没有限制。因为在一个调用路径中,可能会访问多个需要受限制的资源。也就是 DefaultNode 的后面,还可以有其他的 DefaultNode 。
上下文
上下文,即 Contenxt。Entry 代表的是对某个资源的一次访问。而 Context 代表是的一次请求访问,范围更大,因为一个请求访问中可能会访问线性嵌套的访问多个 Entry 。
既然 Context 代表的是一次完整请求访问,并且在这之中有可能会访问到多个资源,则必然须有一个属性,指向当前正在访问的资源,也就是指向当前正在请求的 Entry 。所以 Context 对象有一个属性curEntry存储着当前正在访问的 Entry 。每一个资源的访问都有 Entry 标识,其统计信息也有 Node 来标识, 不过这个 Node 是直接设置在curEntry对应的属性之中,不需要存储在 Context 上的。
Context 代表的是一个完整的请求访问,而访问必然有一个最初的入口,从上面 Node 的调用树可以看到,一个访问的入口节点就是非 machine-root 的 EntranceNode 。因此 Context 也会持有这个 EntranceNode 的指向。
在微服务之中,系统的访问往往来自外部,请求也是如此。因此 Context 还有一个属性origin用于标识该请求的来源,该值通常可以是服务消费者的 AppId,又或者是服务消费者的 IP 。
Sentenil 中之所以又是区分条目,又是区分上下文的,实际上是为了更精细化的流控规则考虑的。有了这些属性,流控规则就可以做到更细,而不是直观上考虑的只能针对某一个资源做全局控制。网络上有一些文章说到 Context 似乎没有作用,实际上 Context 就是体现在origin属性和entranceNode属性上的。
设计思路
先来看下官网对其描述的功能特性图
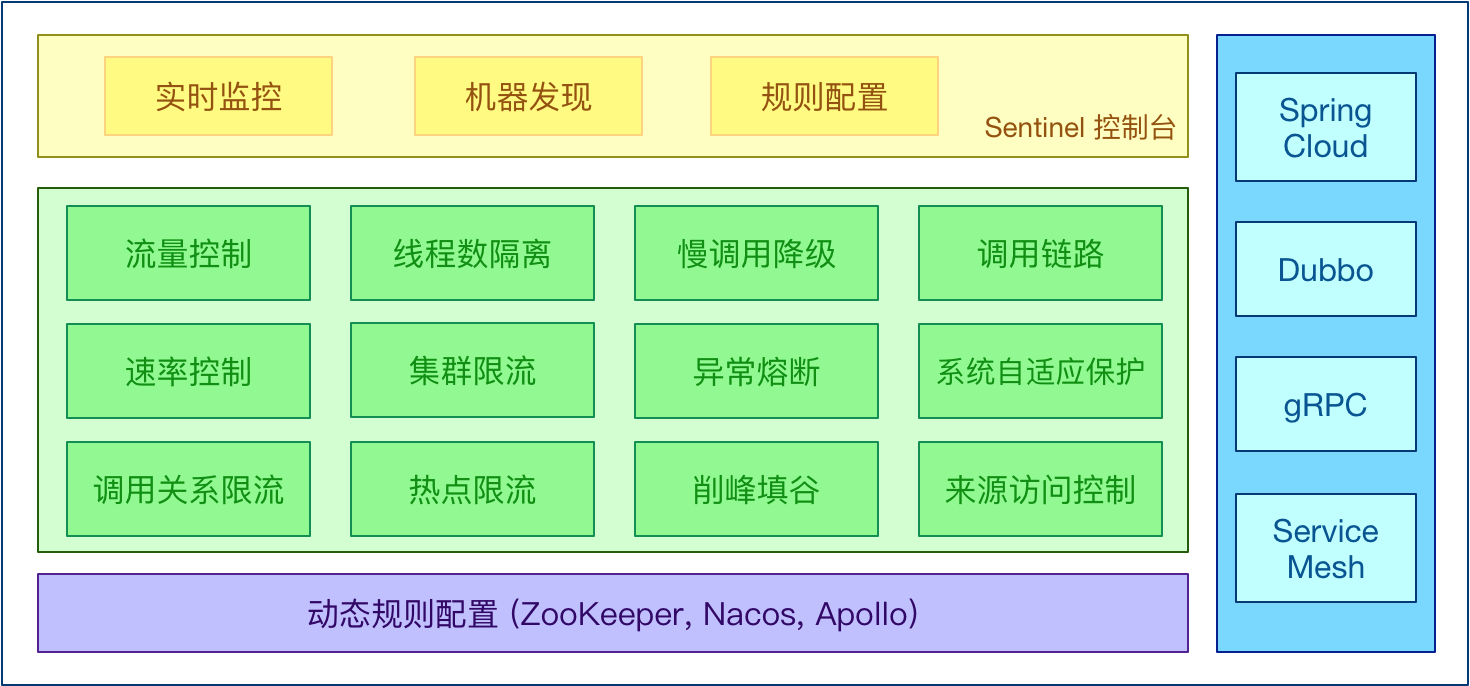
官网的框架图如下
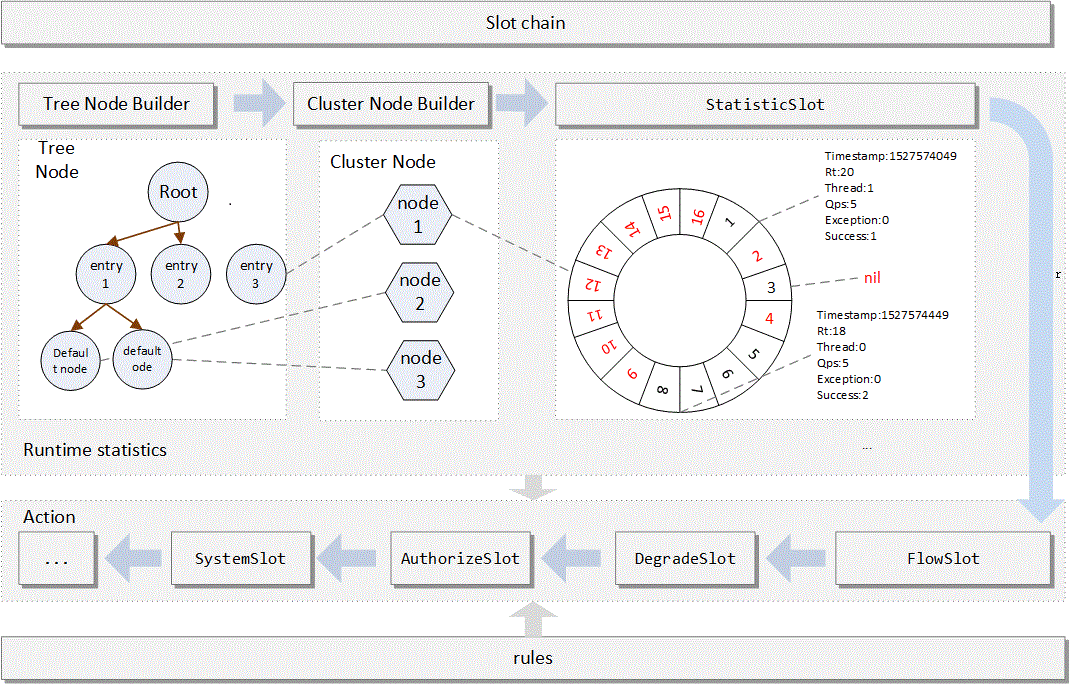
不过发现这个图已经有点旧了了,TreeNodeBuilder应该是更名为了NodeSelectorSlot。但是感觉这个架构图看着还是有点不好理解。实际上,Sentinel 从架构的角度来说是很简单的,就是一个责任链模式的处理链条,如下

图很简单,实际上 Sentinel 的复杂功能都是因为不同的 Slot 实现的。本身上它的架构就是个单纯的责任链,将对资源的访问包装为一个 Entry 对象,并且通过责任链对 Entry 对象进行处理。如果本次访问触发了限流规则,责任链终止执行,并且抛出 BlockException ,代表着本次访问被限制。
责任链模式的好处就是良好的扩展性,通过增加责任链中的处理节点,可以新增功能和逻辑。Sentinel 对这块采用 SPI 的方式进行扩展,开发者只需要实现ProcessorSlot接口,并且按照 SPI 的方式进行定义,在 Sentinel 启动的时候就可以将自己的处理节点新增到处理链条中,从而实现定制化的功能。
Sentinel 中内置了 8 个处理器,类图如下

Sentinel 主要的功能就是依靠着内置的 8 个处理器实现的。其中流控就是依靠FlowSlot实现的,而流控需要的统计数据来源则是依靠StatisticSlot提供的。而统计需要数据存储节点则是依靠NodeSelectorSlot和ClusterBuilderSlot提供的。系统自适应保护是依靠SystemSlot实现的。可以看到,通过不同的Slot,Sentinel 实现了丰富的流控场景。
实际上,这种通过责任链形式,实现不同功能的设计思路,是十分通用,在各种框架中都能见到其应用,比如在 Netty 中,责任链的处理模式,就能很方便的实现入站出站数据的处理。
在明确了总体设计之后,接下来就来看看具体的代码实现吧。


 京公网安备 11010502036488号
京公网安备 11010502036488号