

什么是 Cassandra
Apache Cassandra起初由 Facebook 研发,2008 年被开源。![]()
它是一个分布式的 NoSQL 数据库,特点是集 Google BigTable(Apache HBase 的原型)的数据模型和 Amazon Dynamo 的完全分布式架构一身,而且是面向列的,可扩展、容错的,具有最终一致性。
CAP 指 Consistency、Availability 和 Partition-tolerance 三种属性。根据 CAP 定理,对于任何分布式系统,你最多只能获得其中任意二者,而 Cassandra 是专注于 Availability 和 Partition-tolerance 的解决方案。
Architecture
Cassandra 是一个P2P的分布式 NoSQL数据库。
具体来说,Cassandra 采用半结构化的数据模型(面向列),原生的去中心化分布式架构。每个节点存储一部分元数据信息和数据本身,没有 master/leader node。
Data model
一条记录的有很多级键:< keyspace : column family : key : super column : column key >(super column 这级有时没有),如下图:
Storage
大致上,数据存储时是以 MemTable 和 SSTable 的形式,构成一个 LSM-tree(Log Structured Merge Tree)。
其中,CF 充当映射到 MemTable/SSTable 上的键,SSTable 内部按照 row key 对记录进行排序。
Consistency
最终一致性,QUORUM 机制。
Fault Tolerance
带虚拟节点的 Consistent Hashing 机制(Cassandra 1.2 版本以后使用),把哈希值空间看成一个环(ring),把各个服务器节点哈希映射到多个环上节点,将两个节点之间的数据化为邻近一个服务器节点负责。如果一个服务器失效了,就删除它在环上的节点,按之前的规则调整数据分布。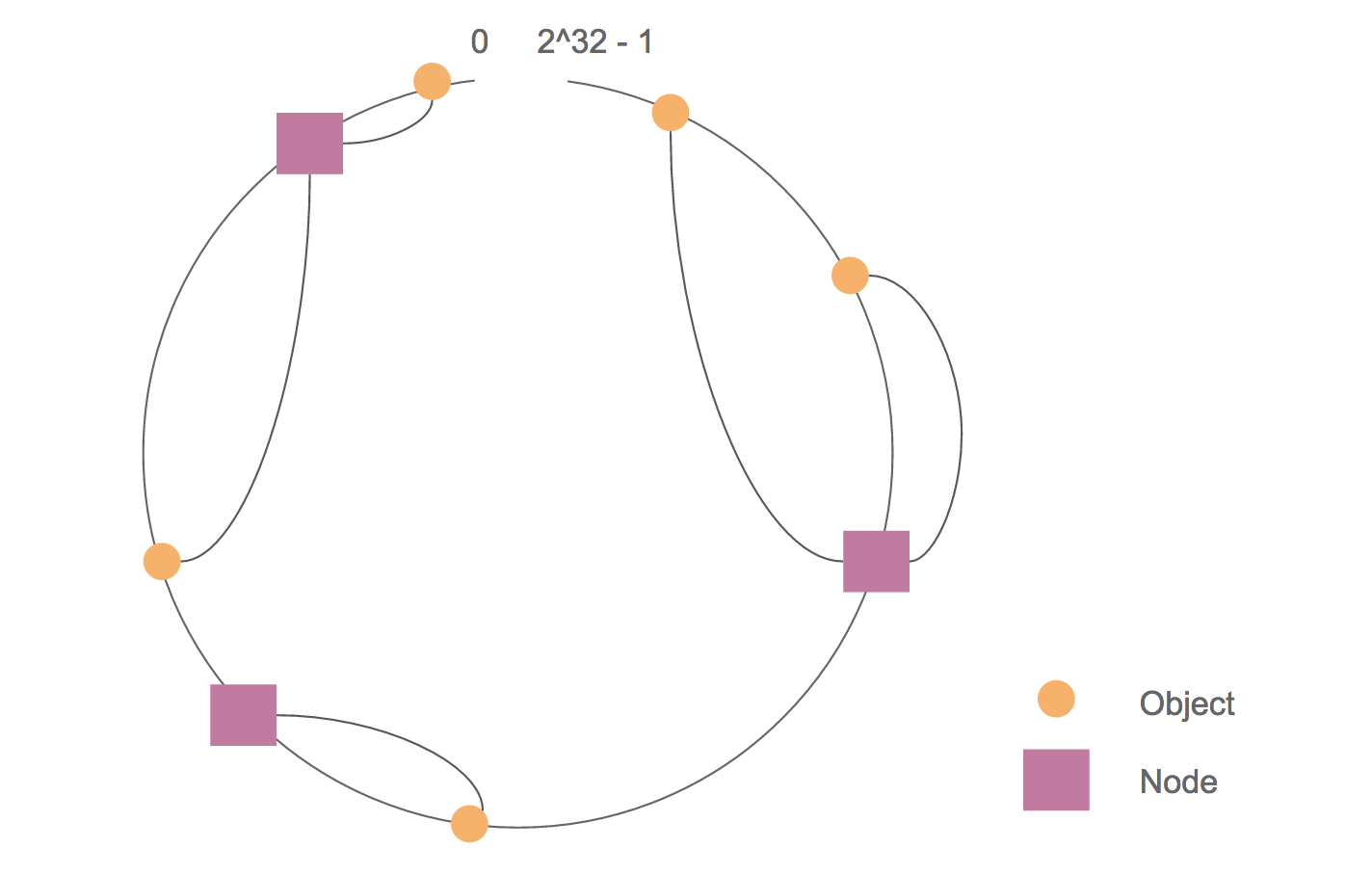
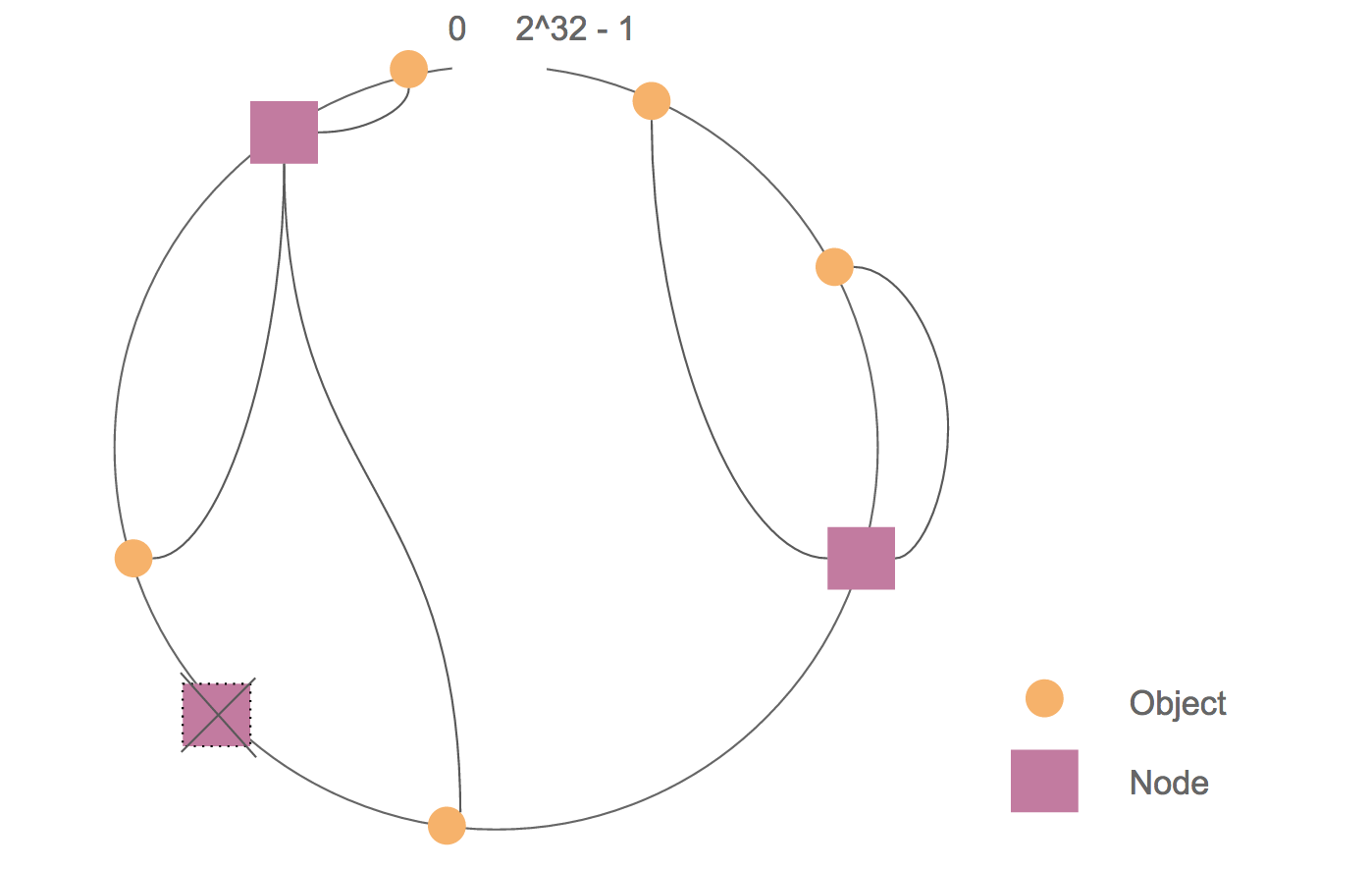
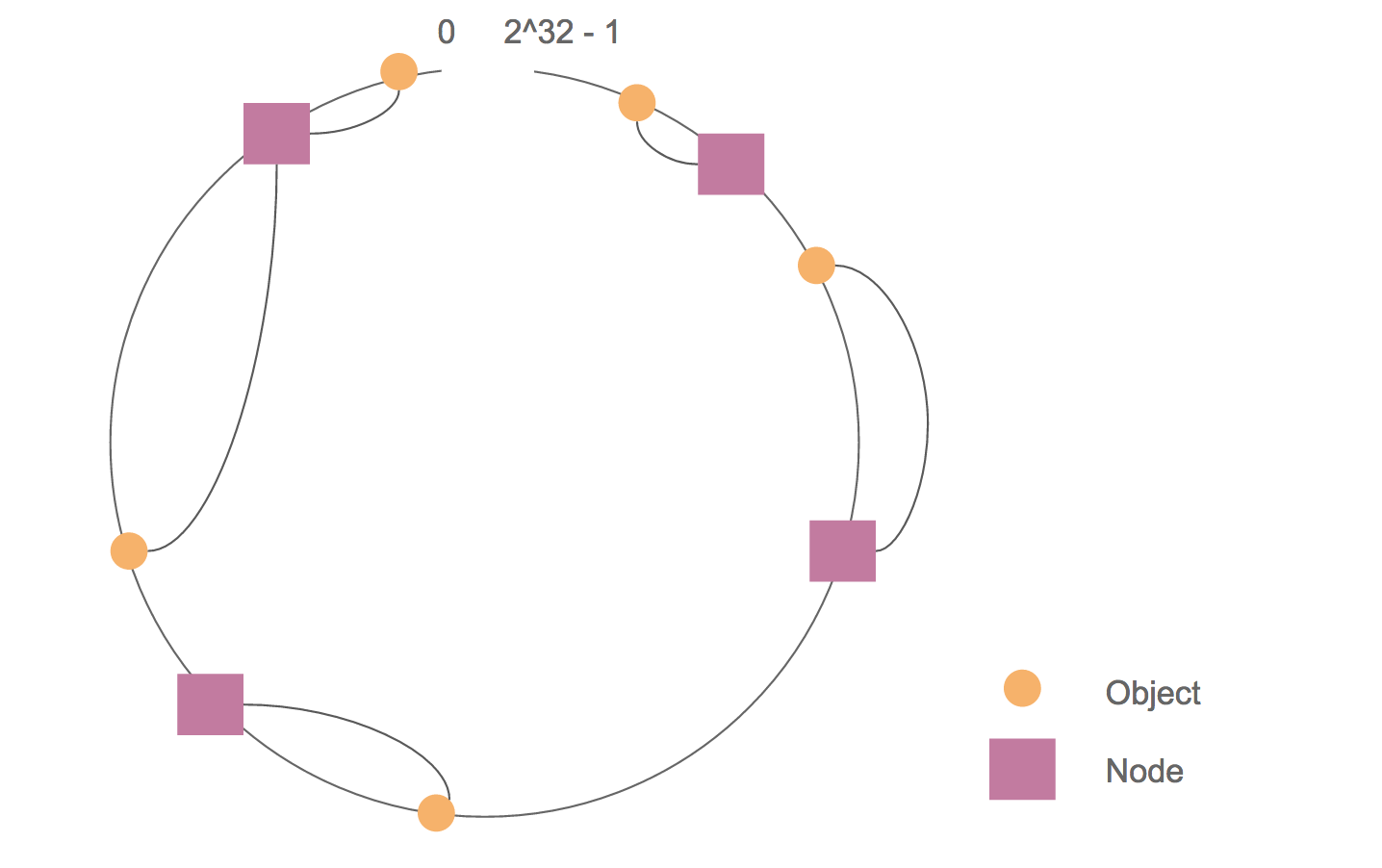
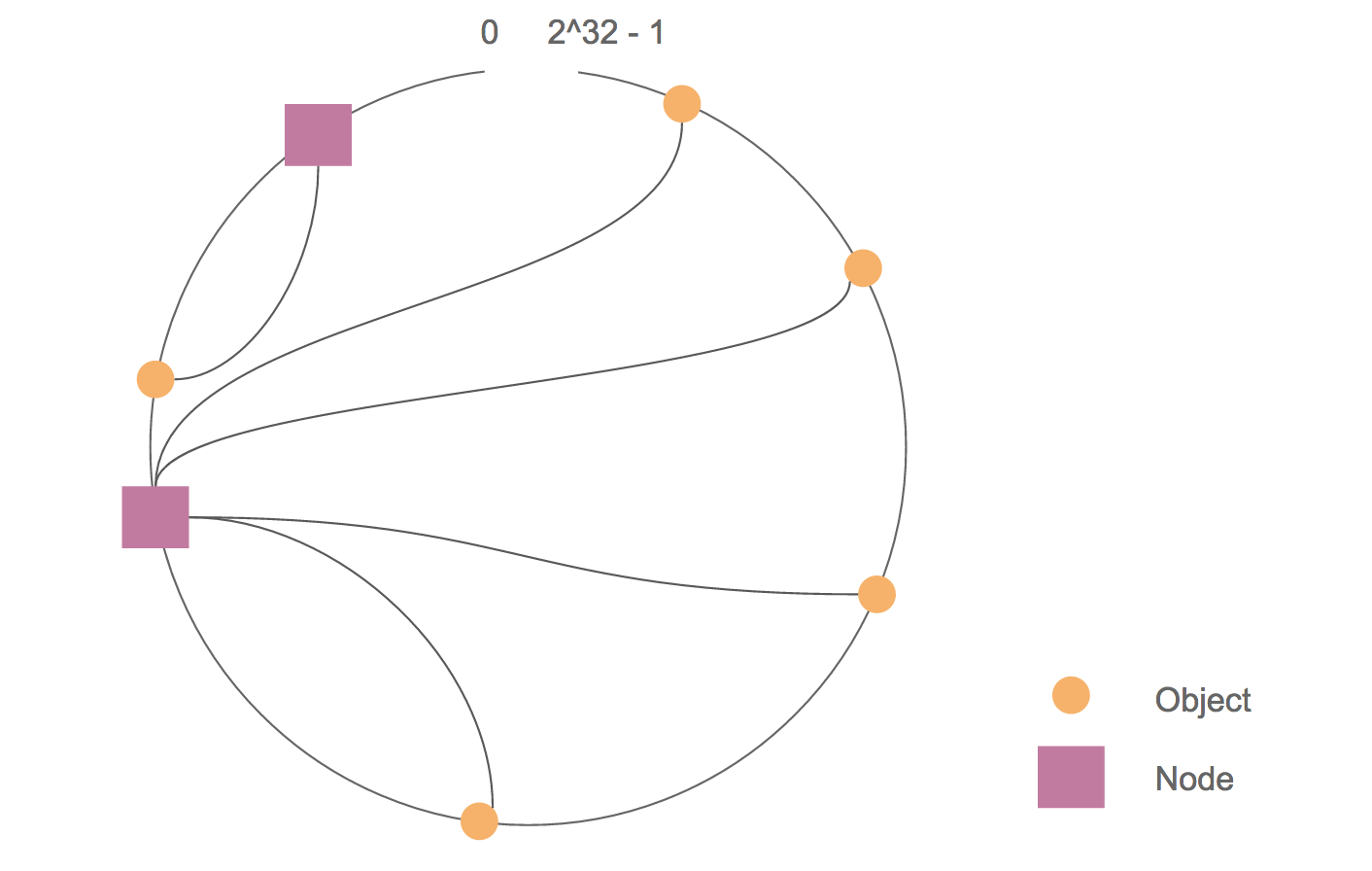
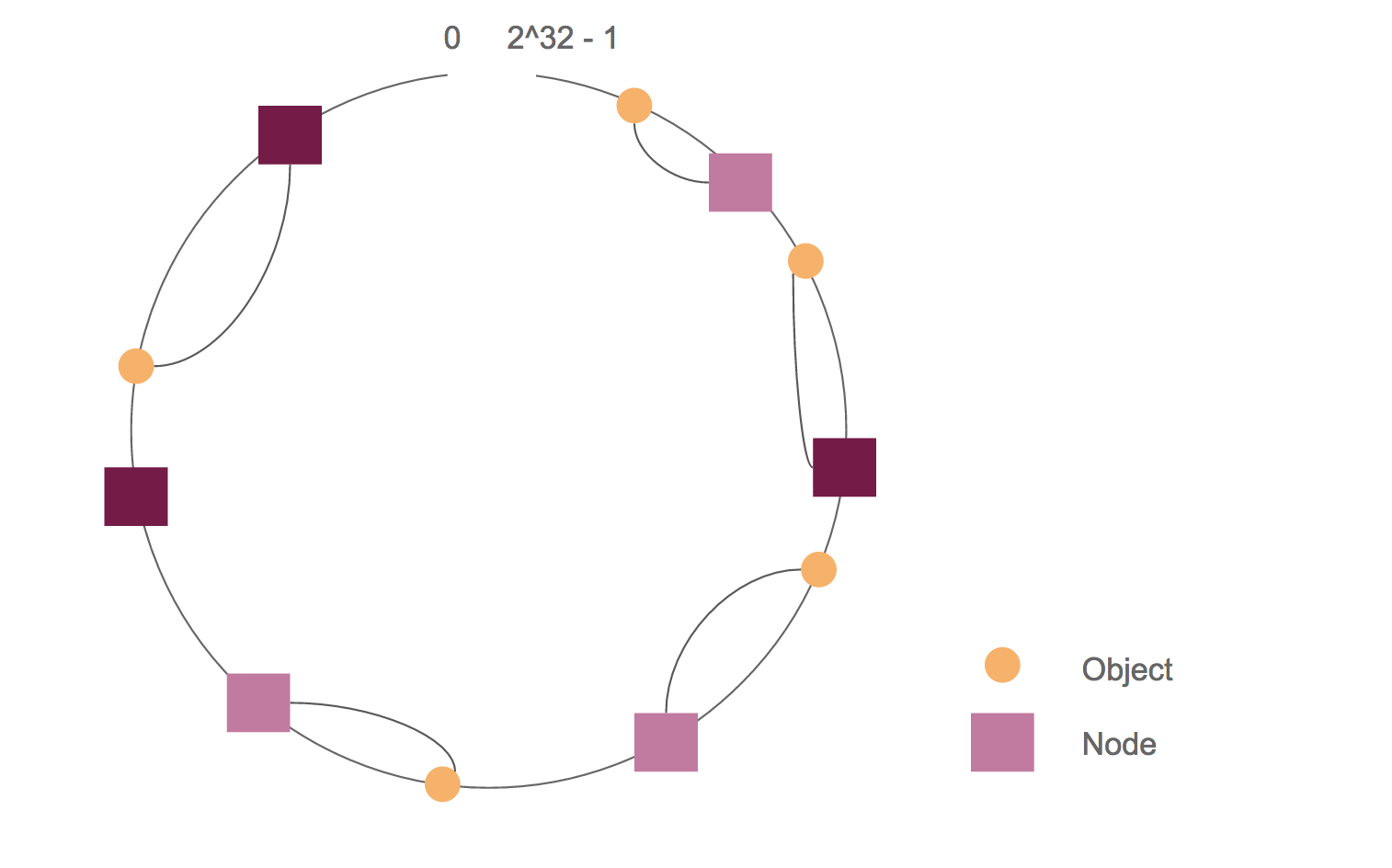
设置了副本参数时,一份数据会被放置到多个节点上,分配的策略有多种选择。
这样,即通过冗余备份避免了单点失效问题,也使数据分布更均匀。
Easy-to-Use
实现了 CQL(Cassandra Query Language),语法和 SQL 语句类似,但查询能力受限于数据模型(比如,只能针对特定的列进行查询)。
ps. CQL3 里把 CF 直接叫做 table 了。
# 创建keyspace,指定replication factor
CREATE KEYSPACE patient WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
# 建表
CREATE TABLE patient.exam (
patient_id int,
id int,
date timeuuid,
details text,
PRIMARY KEY (patient_id, id));
# 插入数据
INSERT INTO exam (patient_id,id,date,details) values (1,1,now(),'first exam patient 1');
INSERT INTO exam (patient_id,id,date,details) values (1,2,now(),'second exam patient 1');
INSERT INTO exam (patient_id,id,date,details) values (2,1,now(),'first exam patient 2'); Discussion
Cassandra 的优势在于:
- 与 RDBMS(比如 MySQL)相比:伸缩性强;避免了单点失效;可用性更高
- 与其他 NoSQL 数据库相比:易用性强;去中心化;单行查询性能优异
也有一些受限于设计的不足:
- Scan 操作只能作用于部分列,不支持跨行的聚合
- 不适用于 OLTP
- 读写延迟与一致性语义的级别有关,严格一致性(Quorum)下读性能不如 HBase
Cassandra 在DB-Engines Ranking中排名第 10 左右。目前,国内的是 360 使用 Cassandra 较多。国外的 DataStax 公司做了许多 Cassandra 的推广,Facebook 当初想用 Cassandra 实现其消息系统,但后来发现 Cassandra 的最终一致性模型不适合,所以一度“弃用”Cassandra。目前 Facebook 的 inbox search 系统和移动应用开发平台使用 Cassandra,其他的见 Cassandra 官方描述:
Cassandra is in use at Constant Contact, CERN, Comcast, eBay, GitHub, GoDaddy, Hulu, Instagram, Intuit, Netflix, Reddit, The Weather Channel, and over 1500 more companies that have large, active data sets.
定位接近的对手是 HBase,之前 HBase 的最大优势是与 Hadoop 的无缝衔接。随着 Spark 的兴起,Cassandra+Spark 可能会是一类常用的数据分析解决方案,多数据中心是它的优势(这方面信息不多,仍待收集)。
Commericial Offerings
DataStax
“提供‘现代的’云数据平台的零操作‘智能服务’”,同时提供发行版、云平台、托管服务。产品线是这几个里最广的。
- DataStax Enterprise
- DataStax Distribution of Apache Cassandra
- DataStax Constellation
- DataStax Managed Services
- Apache Cassandra™
- DataStax for Developers
- Product Offerings
其中,前 2 个是发行版的形式;
第 3 个是云平台的形式,和 instaclustr 的服务形式类似,可以选把服务建在哪个公有云,选择云服务器的规格;
第 4 个是完全托管,需要使用用户的 AWS/Azure/GCP 账号,然后交由 DataStax 的工程师管理,并适配用户需要的数据库服务规格;
第 6 个算是开发者工具,下面包含了 DataStax Studio、Kafka Connector、DataStax Bulk Loader、Enterprise Driver、Free training on DataStax Academy 这五个部分,其中前三个算产品,第一个类似 MySQL Workbench 这种,提供了 DataStax Cassandra 服务的数据可视化、监控服务,第二个是用来和 DataStax Enterprise 做数据消费的(据称因为是基于 kafka connect 做的,做了针对 Cassandra 的设计,所以性能比一般的自定义解决方案更好,也更易用、安全),第三个是一个 DataStax Enterprise 上的数据加载、数据卸载工具(说是性能比其他命令、工具快,但因为是在自己产品的基础上做的开发,个人觉得这种说法的效果有限)。
DataStax Enterprise 产品本身没有附带上述的开发工具,因为有DataStax Distribution vs. DataStax Enterprise vs. DataStax Enterprise + Advanced Workload Pack的存在。
DataStax 应该并没有使用 k8s 集群来编排 Cassandra,只是提供了 docker image;它的云服务可能是直接运行在云服务器上的,像 DataStax Enterprise 中给出的 Install Guide,启动 Cassandra 是以启动DSE service的形式完成的。
ScyllaDB
声称是最快的分布式数据库,本质上是用 C++重写了 Cassandra,完全兼容 Cassandra,提供的报表中显示性能优势明显,据称其拥有 10X Java 版的吞吐量。
ScyllaDB 也提供云服务。主要有 3 个产品:Scylla Enterprise, Scylla Cloud, _Scylla Manager_。
第一个应该是面向企业的客制化服务。
第二个是类似于DataStax Constellation和Instaclustr的云服务,在公有云上部署好 ScyllaDB,然后使用它的管理界面。
第三个是整合了一些数据库管理客户端的发行版。
据说在较高数据量下的稳定性可能存在问题。
Instaclustr
基于 k8s operator 做的 Cassandra 服务,主要是提供公有云上的部署服务、可定制的服务、预部署(on-premise)服务。点击试用,能看到让你选择部署的公有云平台和服务器规格,其中 on-premise 服务不支持直接试用,需要联系公司。
Instaclustr 的更多功能特性还在探索中,目前已知的是:它除了为 Cassandra 做了operator,包含了 Cassandra 的生命周期管理服务;还做了 Kafka 和 Spark 的服务,在云平台上部署 Cassandra 时就已经默认集成了 Spark,它的云服务相当于提供 Cassandra+Spark 的数据分析解决方案,用其原话叫做An Integrated Data Layer。
Open Source Alternatives
Instaclustr: cassandra-operator
Orange-Opensource: cassandra-operator
Rook: cassandra-operator
Comparison
| Name | Instaclustr | Orange | Rook |
|---|---|---|---|
| Deploy & Clean Up | Yes | Yes | Yes |
| Scale Up & down | Yes | Yes | Yes |
| Backup | Yes | Yes | - |
| Restore | Yes | Yes | - |
| Upgrade | - | Yes | - |
| Monitoring | - | Yes | - |
| License | Apache 2.0 | Apache 2.0 | Apache 2.0 |
| Status | alpha | alpha | alpha |
| Remarks | not recommended in production | based on CoreOS operator-sdk | support Scylla |
ps. 以上的 backup & restore 可参考Backup Restore Guide - Orange/cassandra-operator。
Others
sky-uk/cassandra-operator
Alpha version,已实现的功能和 Orange 的类似,文档较少。pantheon-systems/cassandra-operator
Alpha version,支持的 Lifecycle Management 功能较少(deploy, scale up/down, delete)。jetstack/navigator
Also alpha version. Support ES & Cassandra.Rook: Navigator is aspiring to be a managed DBaaS platform on top of Kubernetes. Their model they promote is very similar to the one proposed here (CRD + Controller + Sidecar) and has been an inspiration while designing the model for Cassandra Operator. They currently provide operators for Cassandra and Elasticsearch.
(相较原版,略有删减)

 京公网安备 11010502036488号
京公网安备 11010502036488号