

Go 中原子操作和锁哪个性能更好?更快?
铺垫
进程
程序的一次执行活动,操作系统资源分配的基本单位,线程的容器...
线程
线程(英语:thread)是操作系统能够进行运算调度的最小单位。大部分情况下,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
线程是独立调度和分派的基本单位。同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
一个进程可以有很多线程来处理,每条线程并行执行不同的任务。如果进程要完成的任务很多,这样需很多线程,也要调用很多核心,在多核或多CPU,或支持Hyper-threading的CPU上使用多线程程序设计的好处是显而易见的,即提高了程序的执行吞吐率。以人工作的样子想像,核心相当于人,人越多则能同时处理的事情越多,而线程相当于手,手越多则工作效率越高。在单CPU单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,虽然多任务比不上多核,但因为具备多线程的能力,从而提高了程序的执行效率。
上下文切换
上下文切换(英语:context switch),又称环境切换,电脑术语,是一个存储和重建CPU的状态 (内文),因此令多个进程(process)可以分享单一CPU资源的计算过程。要切换CPU上的进程时,必需先行存储目前进程的状态,再将欲运行的进程之状态读回CPU中.
上下文切换通常是计算密集型的,操作系统中的许多设计都是针对上下文切换的优化。在进程间切换需要消耗一定的时间进行相关的管理工作——包括寄存器和内存映射的保存与读取、更新各种内部的表等等。处理器或者操作系统不同,上下文切换时所涉及的内容也不尽相同。比如在Linux内核中,上下文切换需要涉及寄存器、栈指针、程序计数器的切换,但和地址空间的切换无关(虽然进程在进行上下文切换时也需要做地址空间的切换)[2][3]。用户态线程之间也会发生类似的上下文切换,但这样的切换非常轻量。 Goroutine 上下文切换就是这类。
锁的分类
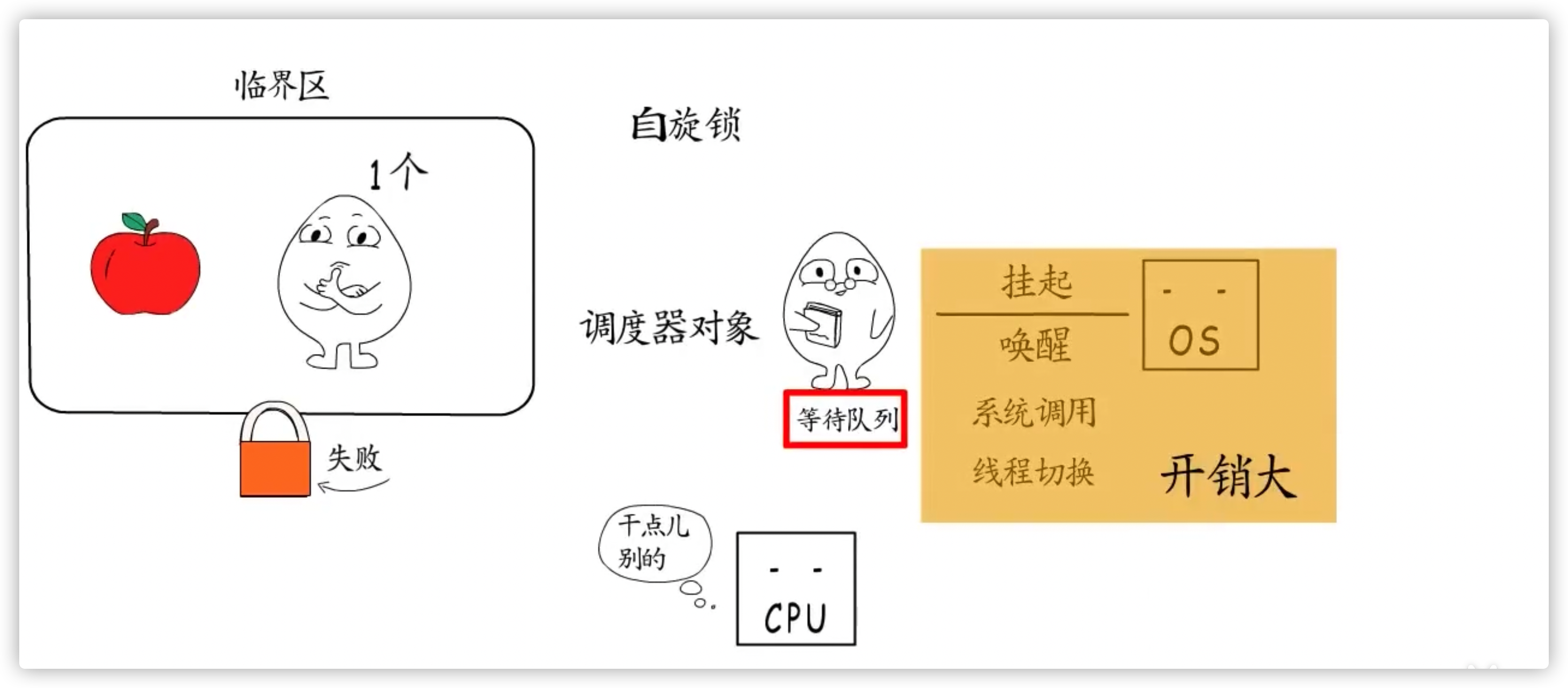
自旋锁
屡败屡战,不断重试,直到获取到锁,或者CPU时间片消耗完
调度器对象
进入阻塞队列,由操作系统进行调度,Linux 下,应用程序是通过 futex 系统调用来使用的
原子操作
概念
线性一致性(Linearizability),或称原子一致性或严格一致性指的是程序在执行的历史中在存在可线性化点P的执行模型,这意味着一个操作将在程序的调用和返回之间的某个点P起作用。这里“起作用”的意思是被系统中并发运行的所有其他线程所感知。
P.S.常见的原子操作是借助 CPU 提供的指令来实现的。
Go 中实现 & 使用
sync/atomic
Package atomic provides low-level atomic memory primitives useful for implementing synchronization algorithms.
These functions require great care to be used correctly. Except for special, low-level applications, synchronization is better done with channels or the facilities of the sync package.
Share memory by communicating; don't communicate by sharing memory.
CASThe compare-and-swap operation, implemented by the CompareAndSwapT functions, is the atomic equivalent of:if *addr == old { *addr = new return true } return false
Package sync provides basic synchronization primitives such as mutual
exclusion locks. Other than the Once and WaitGroup types, most are intended
for use by low-level library routines. Higher-level synchronization is
better done via channels and communication
官方推荐使用用封装好的 atomic.Value, 它提供了针对 Go 类型的 load/store 原子操作,基于 func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool),对使用者更友好。
官方给出了一个适用于某个配置/变量,读多写少的场景的例子,使用了 copy-on-write + atomic.Value
The following example shows how to maintain a scalable frequently read,
but infrequently updated data structure using copy-on-write idiom.
func ExampleValue_readMostly() {
type Map map[string]string
var m atomic.Value // 共享的数据
m.Store(make(Map))
var mu sync.Mutex // used only by writers
// read function can be used to read the data without further synchronization
read := func(key string) (val string) {
m1 := m.Load().(Map)
return m1[key]
}
// insert function can be used to update the data without further synchronization
insert := func(key, val string) {
mu.Lock() // synchronize with other potential writers
defer mu.Unlock()
m1 := m.Load().(Map) // load current value of the data structure
m2 := make(Map) // create a new value
for k, v := range m1 {
m2[k] = v // copy all data from the current object to the new one
}
m2[key] = val // do the update that we need
m.Store(m2) // atomically replace the current object with the new one
// At this point all new readers start working with the new version.
// The old version will be garbage collected once the existing readers
// (if any) are done with it.
}
_, _ = read, insert
} 内部实现
Example:
func ShowAtomicOpt() {
var state int64 = 0
const(
open = 1
closed = 0
)
// 维护各类状态的时候,经常会使用原则操作
// SWAP
// STORE 等
atomic.CompareAndSwapInt64(&stat,closed,open)
} ASM:
ShowAtomicOpt_pc0:
TEXT "".ShowAtomicOpt(SB), ABIInternal, $24-0
LEAQ type.int64(SB), AX
MOVQ AX, (SP)
PCDATA $1, $0
CALL runtime.newobject(SB)
MOVQ 8(SP), AX
MOVQ (AX), CX
LEAQ 1(CX), DX
MOVQ AX, BX
MOVQ CX, AX
LOCK
CMPXCHGQ DX, (BX) // CAS
SETEQ AL
MOVQ 16(SP), BP
ADDQ $24, SP
RET 适用场景
CPU 多核心,持有锁时间短,自旋次数少
追求高性能,不阻塞线程/进程,对阻塞导致的上下文切换开销比较敏感。
Mutex 互斥锁
概念
互斥锁(英语:Mutual exclusion,缩写 Mutex)是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域(critical section)达成。临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。一个程序、进程、线程可以拥有多个临界区域,但是并不一定会应用互斥锁。
Go中实现 & 使用
轻量级 sync.Mutex
协程级别的锁,go runtime 管理,由 sync.Mutex + semTable组合实现的
var mu sync.Mutex mu.Lock() mu.UnLock()
sync.RWMutex
同上,加了亿点优化
底层 runtime.mutex
线程级别的锁,主要是OS来管理
内部实现
Goroutine Level
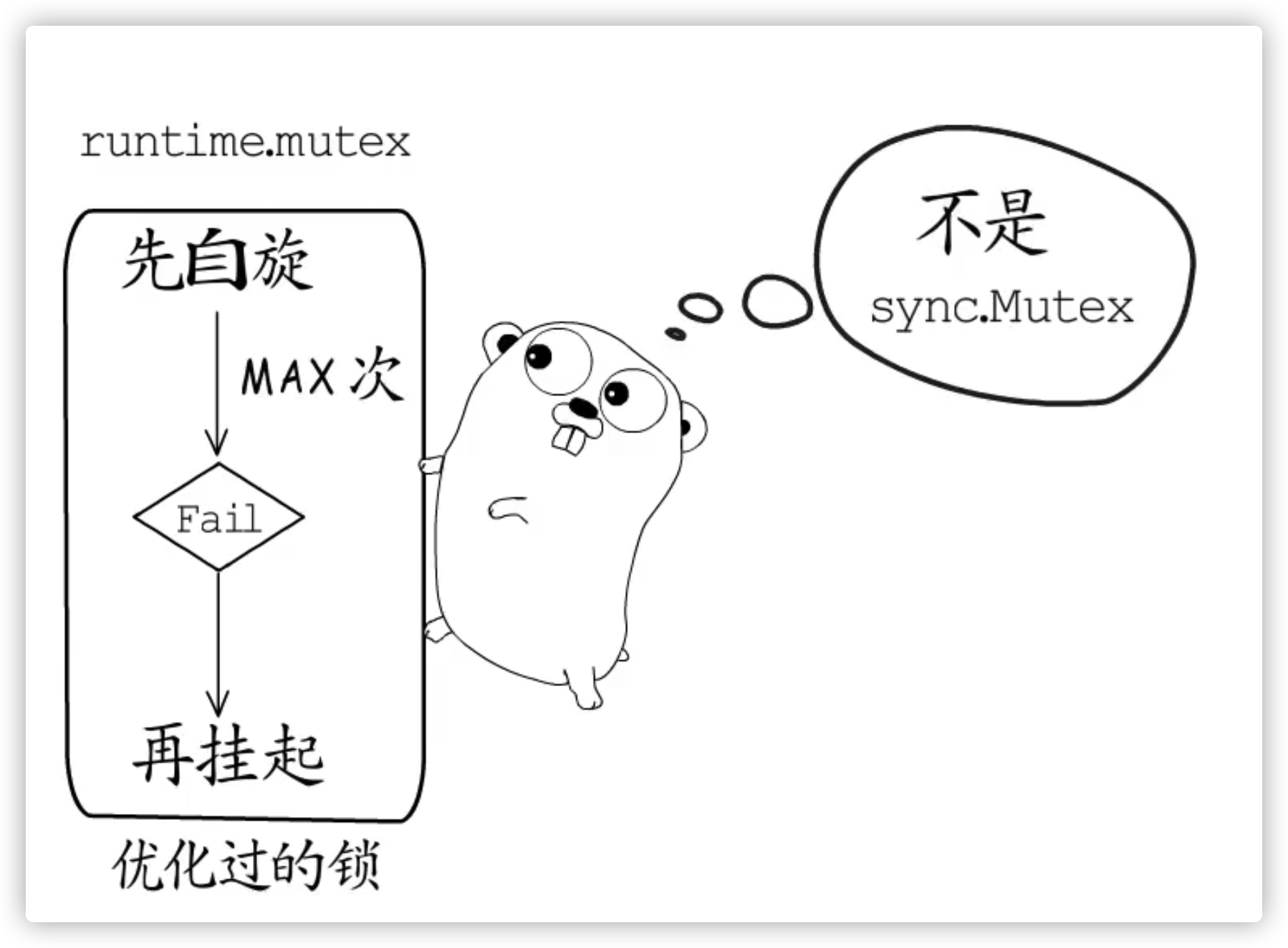
如果协程等待锁 sync.Mutex,还需要进行线程的上下文切换,就得不偿失了。所以协程级别的锁,实现尽量先采用轻量级策略:
- 先进行一次 CAS,如果成功则返回
- 进入
lockSlow逻辑,符合条件下仍然使用自旋策略,最大自旋次数 4 ,尽量避免成为线程锁 - 加入由 runtime 管理的协程级别的阻塞队列中,等待调度
- 阻塞线程,接受操作系统调度进化为【 重量级锁】
结合了CAS + block queue / notify 的优势,给 CAS 设定了最大重试次数,达到上限后,走阻塞队列+走操作系统/go runtime 调度策略
type Mutex struct {
state int32
sema uint32
}
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// Don't spin in starvation mode, ownership is handed off to waiters
// so we won't be able to acquire the mutex anyway.
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// Active spinning makes sense.
// Try to set mutexWoken flag to inform Unlock
// to not wake other blocked goroutines.
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
// new 不是 GO 的保留关键字
new := old
// Don't try to acquire starving mutex, new arriving goroutines must queue.
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// The current goroutine switches mutex to starvation mode.
// But if the mutex is currently unlocked, don't do the switch.
// Unlock expects that starving mutex has waiters, which will not
// be true in this case.
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
// The goroutine has been woken from sleep,
// so we need to reset the flag in either case.
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// If we were already waiting before, queue at the front of the queue.
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
// If this goroutine was woken and mutex is in starvation mode,
// ownership was handed off to us but mutex is in somewhat
// inconsistent state: mutexLocked is not set and we are still
// accounted as waiter. Fix that.
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
// Exit starvation mode.
// Critical to do it here and consider wait time.
// Starvation mode is so inefficient, that two goroutines
// can go lock-step infinitely once they switch mutex
// to starvation mode.
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
} Tread Level
runtime/lock_sema.go
// Active spinning for sync.Mutex.
func sync_runtime_canSpin(i int) bool {
// sync.Mutex is cooperative, so we are conservative with spinning.
// active_spin = 4, 这里限制了自旋条件和自旋次数
if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
// 这里是看本地 P 的 G 队列是否为空
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
//go:linkname sync_runtime_SemacquireMutex sync.runtime_SemacquireMutex
func sync_runtime_SemacquireMutex(addr *uint32, lifo bool, skipframes int) {
semacquire1(addr, lifo, semaBlockProfile|semaMutexProfile, skipframes)
}
// Prime to not correlate with any user patterns.
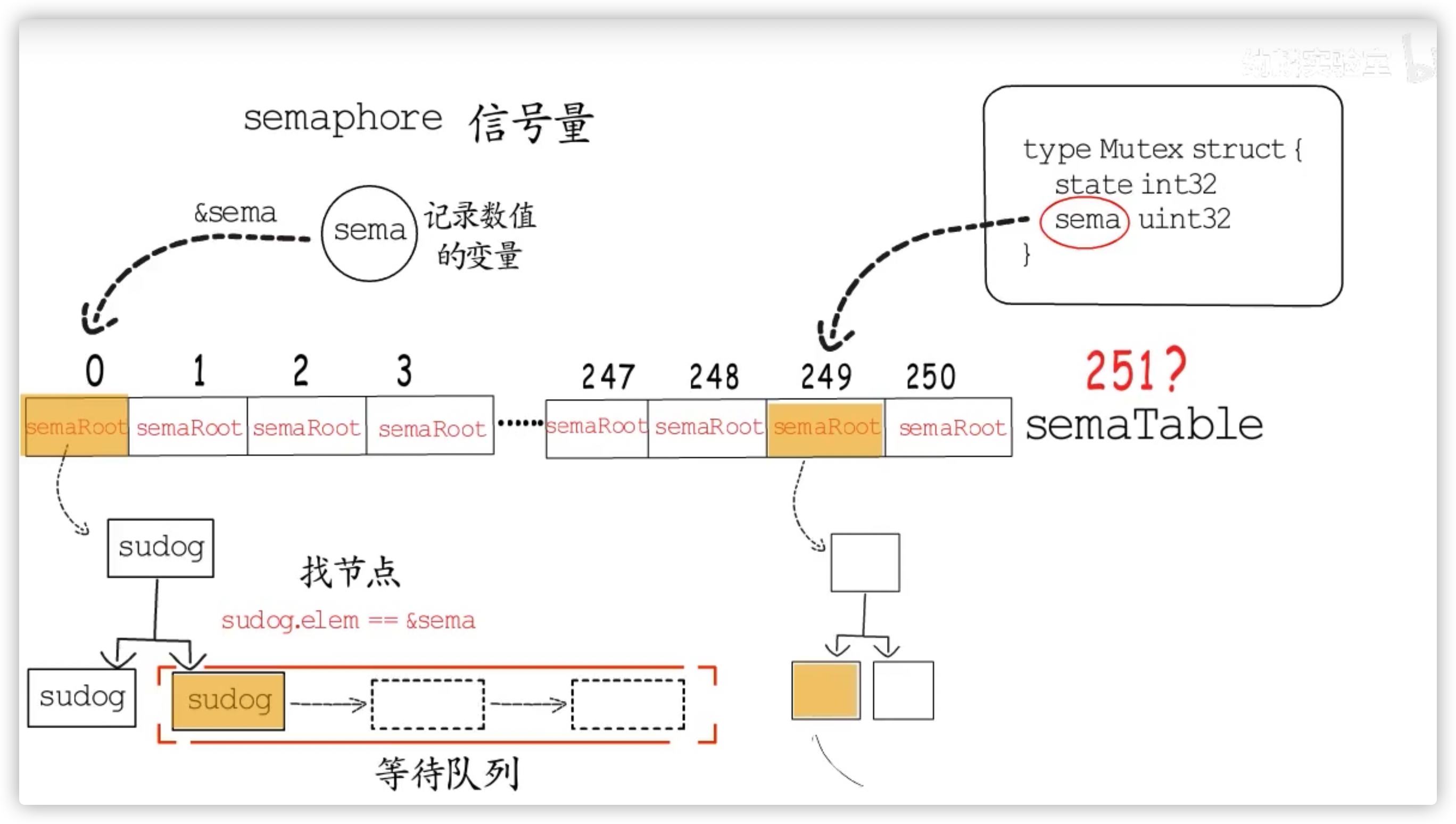
// 搞不明白这个数字的由来
const semTabSize = 251
// 从代码上来看,每个 sem 对应一颗 Treap 树堆
// 个人认为这里使用 RB-Tree 或 SkipList 效果更好
var semtable [semTabSize]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{})]byte
}
// semroot
func semroot(addr *uint32) *semaRoot {
return &semtable[(uintptr(unsafe.Pointer(addr))>>3)%semTabSize].root
}
// A semaRoot holds a balanced tree of sudog with distinct addresses (s.elem).
// Each of those sudog may in turn point (through s.waitlink) to a list
// of other sudogs waiting on the same address.
// The operations on the inner lists of sudogs with the same address
// are all O(1). The scanning of the top-level semaRoot list is O(log n),
// where n is the number of distinct addresses with goroutines blocked
// on them that hash to the given semaRoot.
type semaRoot struct {
lock mutex // 这里是 runtime.lock ,这个 lock 有可能使线程发生上下文切换
treap *sudog // 逻辑结构上是一颗树,存储结构上是一个线性表->链表 BST + Heap(堆 OR 优先队列)
nwait uint32 // Number of waiters. Read w/o the lock.
}
// 这个结构在 channel 和 mutex 等待队列中都有使用到
// sudog represents a g in a wait list, such as for sending/receiving
// on a channel.
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
} // 由 goroutine 级别的锁向线程级别的锁转变
func lock2(l *mutex) {
gp := getg()
gp.m.locks++
// Speculative grab for lock.
if atomic.Casuintptr(&l.key, 0, locked) {
return
}
// 申请系统级别信号量,pthread syscall
semacreate(gp.m)
// On uniprocessor's, no point spinning.
// On multiprocessors, spin for ACTIVE_SPIN attempts.
// ACTIVE_SPIN = 4 , 多核心情况下进行自旋
spin := 0
if ncpu > 1 {
spin = active_spin
}
Loop:
for i := 0; ; i++ {
v := atomic.Loaduintptr(&l.key)
if v&locked == 0 {
// Unlocked. Try to lock.
if atomic.Casuintptr(&l.key, v, v|locked) {
return
}
i = 0
}
if i < spin {
// 汇编代码实现 PAUSE 空耗CPU
procyield(active_spin_cnt)
} else if i < spin+passive_spin {
// 汇编代码实现 SYSCALL 让系统线程让出 CPU
osyield()
} else {
// 没理解这个场景
// Someone else has it.
// l->waitm points to a linked list of M's waiting
// for this lock, chained through m->nextwaitm.
// Queue this M.
for {
gp.m.nextwaitm = muintptr(v &^ locked)
if atomic.Casuintptr(&l.key, v, uintptr(unsafe.Pointer(gp.m))|locked) {
break
}
if v = atomic.Loaduintptr(&l.key); v&locked == 0 {
continue Loop
}
}
if v&locked != 0 {
// 无计可施了,就是拿不到锁了
// Linux 调用 futex 进入系统阻塞队列,等待调度
semasleep(-1)
i = 0
}
}
}
}
适用场景
CPU 只有单核心或业务逻辑复杂,持有锁时间长等场景
对比
读多写少,90%读,10%写
# 使用 atomic.Value goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkAtomicReadMostly BenchmarkAtomicReadMostly-12 3438235 336.3 ns/op 52 B/op 1 allocs/op PA*** sycn.RWMutex goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkRWLockReadMostly BenchmarkRWLockReadMostly-12 2700234 416.3 ns/op 62 B/op 1 allocs/op
写多读少, 90%写,10%读
# 使用 atimic.Value goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkAtomicWriteMostly BenchmarkAtomicWriteMostly-12 3221545 362.4 ns/op PA*** sycn.RWMutex goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkRWLockWriteMostly BenchmarkRWLockWriteMostly-12 770602 1453 ns/op PASS
100% 写
# 使用 atomic.Value goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkAtomicOnlyWrite BenchmarkAtomicOnlyWrite-12 3172586 371.9 ns/op PA*** sycn.Mutex goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkLockOnlyWrite BenchmarkLockOnlyWrite-12 806121 1375 ns/op PASS
100% 读
# 使用 atomic.Value goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkAtomicOnlyRead BenchmarkAtomicOnlyRead-12 3525415 333.3 ns/op PA*** sycn.RWMutex goos: darwin goarch: amd64 pkg: demo/atomic cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz BenchmarkLockOnlyRead BenchmarkLockOnlyRead-12 3335294 340.7 ns/op PASS
结论
sync.Mutex是全能型选手,通用的解决方案,但效率一般,会让多个并发的请求,强制串行执行。- 读多写少的场景下,使用
atomic.Value和sync.RWMutex都可以。 - 针对写多读少的场景,推荐使用
atomic.Value, 此时如果使用了sync.RWMutex可能会等效成为一个sync.Mutex - 最求极致性能,能驾驭系统级编程,可以使用
atomic库下的Swap,Store,Load等原子操作

 京公网安备 11010502036488号
京公网安备 11010502036488号