

链表
单链表
为了追求效率, 这里使用数组模拟链表中的节点, 使用idx分配链表节点索引, 使用w数组记录节点数值, ne数组记录当前节点索引下一个节点的索引

#include <iostream>
using namespace std;
const int N = 1e5 + 10;
//使用idx和w分配链表节点, 使用ne数组维护链表节点位置
int head, ne[N], w[N], idx;
void add_to_head(int val) {
w[idx] = val;
ne[idx] = head;
head = idx++;
}
// 在第K个插入位置后插入val
void add(int k, int val) {
w[idx] = val;
ne[idx] = ne[k];
ne[k] = idx++;
}
void remove(int k) {
ne[k] = ne[ne[k]];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
head = -1;
int q;
cin >> q;
char op[2];
while (q--) {
cin >> op;
if (*op == 'H') {
int val;
cin >> val;
add_to_head(val);
}
else if (*op == 'D') {
int k;
cin >> k;
if (!k) head = ne[head];
else remove(k - 1);
}
else {
int k, val;
cin >> k >> val;
add(k - 1, val);
}
}
for (int i = head; ~i; i = ne[i]) cout << w[i] << ' ';
cout << '\n';
return 0;
}
双向链表
双链表相较于单链表区别就是需要指向前驱节点的指针, 那么新建一个fe数组记录当前节点的前驱节点索引, 剩余与单链表操作类似

#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int h, t, ne[N], fe[N], w[N], idx;
void push_left(int val) {
w[idx] = val;
if (h == -1) {
fe[idx] = ne[idx] = -1;
h = t = idx++;
}
else {
fe[idx] = -1;
ne[idx] = h;
fe[h] = idx;
h = idx++;
}
}
void push_right(int val) {
w[idx] = val;
if (t == -1) {
h = t = idx;
fe[idx] = ne[idx] = -1;
h = t = idx++;
}
else {
ne[idx] = -1;
fe[idx] = t;
ne[t] = idx;
t = idx++;
}
}
void remove(int k) {
// 当整个链表中只有一个节点需要特殊处理, 将链表置空
if (h == t) {
h = t = -1;
}
else if (k == h) {
h = ne[h];
fe[h] = -1;
}
else if (k == t) {
t = fe[t];
ne[t] = -1;
}
else {
int pre = fe[k], nxt = ne[k];
ne[pre] = nxt, fe[nxt] = pre;
}
}
void add_k_left(int k, int val) {
w[idx] = val;
if (k == h) {
fe[idx] = -1, ne[idx] = h;
fe[h] = idx;
h = idx++;
}
else {
int pre = fe[k];
fe[idx] = pre, ne[idx] = k;
ne[pre] = idx, fe[k] = idx;
idx++;
}
}
void add_k_right(int k, int val) {
w[idx] = val;
if (k == t) {
ne[idx] = -1, fe[idx] = t;
ne[t] = idx;
t = idx++;
}
else {
int nxt = ne[k];
fe[idx] = k, ne[idx] = nxt;
ne[k] = idx, fe[nxt] = idx;
idx++;
}
}
void init() {
h = t = -1;
idx = 0;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
init();
int m;
char op[3];
cin >> m;
while (m--) {
cin >> op;
if (op[0] == 'L') {
int val;
cin >> val;
push_left(val);
}
else if (op[0] == 'R') {
int val;
cin >> val;
push_right(val);
}
else if (op[0] == 'D') {
int k;
cin >> k;
remove(k - 1);
}
else if (op[0] == 'I' && op[1] == 'L') {
int k, val;
cin >> k >> val;
add_k_left(k - 1, val);
}
else if (op[0] == 'I' && op[1] == 'R') {
int k, val;
cin >> k >> val;
add_k_right(k - 1, val);
}
}
for (int i = h; ~i; i = ne[i]) cout << w[i] << ' ';
cout << '\n';
return 0;
}
栈

#include <iostream>
#include <cstring>
using namespace std;
const int N = 1e5 + 10;
int m;
int stk[N], top = -1;
void push(int val) {
stk[++top] = val;
}
int pop() {
int val = stk[top--];
return val;
}
bool is_ept() {
return top == -1;
}
int query() {
return stk[top];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
char op[10];
cin >> m;
while (m--) {
cin >> op;
if (!strcmp(op, "push")) {
int val;
cin >> val;
push(val);
}
else if (!strcmp(op, "pop")) pop();
else if (!strcmp(op, "empty")) cout << (is_ept() ? "YES" : "NO") << '\n';
else cout << query() << '\n';
}
return 0;
}
队列

#include <iostream>
#include <cstring>
using namespace std;
const int N = 1e5 + 10;
int n;
int q[N], h, t;
void init() {
h = 0, t = -1;
}
void push(int val) {
q[++t] = val;
}
void pop() {
h++;
}
bool is_ept() {
return h > t;
}
int query() {
return q[h];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
init();
char op[10];
cin >> n;
while (n--) {
cin >> op;
if (!strcmp(op, "push")) {
int val;
cin >> val;
push(val);
}
else if (!strcmp(op, "pop")) pop();
else if (!strcmp(op, "empty")) cout << (is_ept() ? "YES" : "NO") << '\n';
else cout << query() << '\n';
}
return 0;
}
单调队列, 单调栈
单调栈解决的问题是对于序列的当前位置求上一个最大值或者最小值的问题, 或者当前元素作为最大值最小值的影响范围
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int stk[N], top;
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
while (n--) {
int val;
cin >> val;
while (top && stk[top] >= val) top--;
if (top == 0) cout << -1 << ' ';
else cout << stk[top] << ' ';
stk[++top] = val;
}
cout << '\n';
return 0;
}
单调栈解决当前位置作为最大值或者最小值的影响
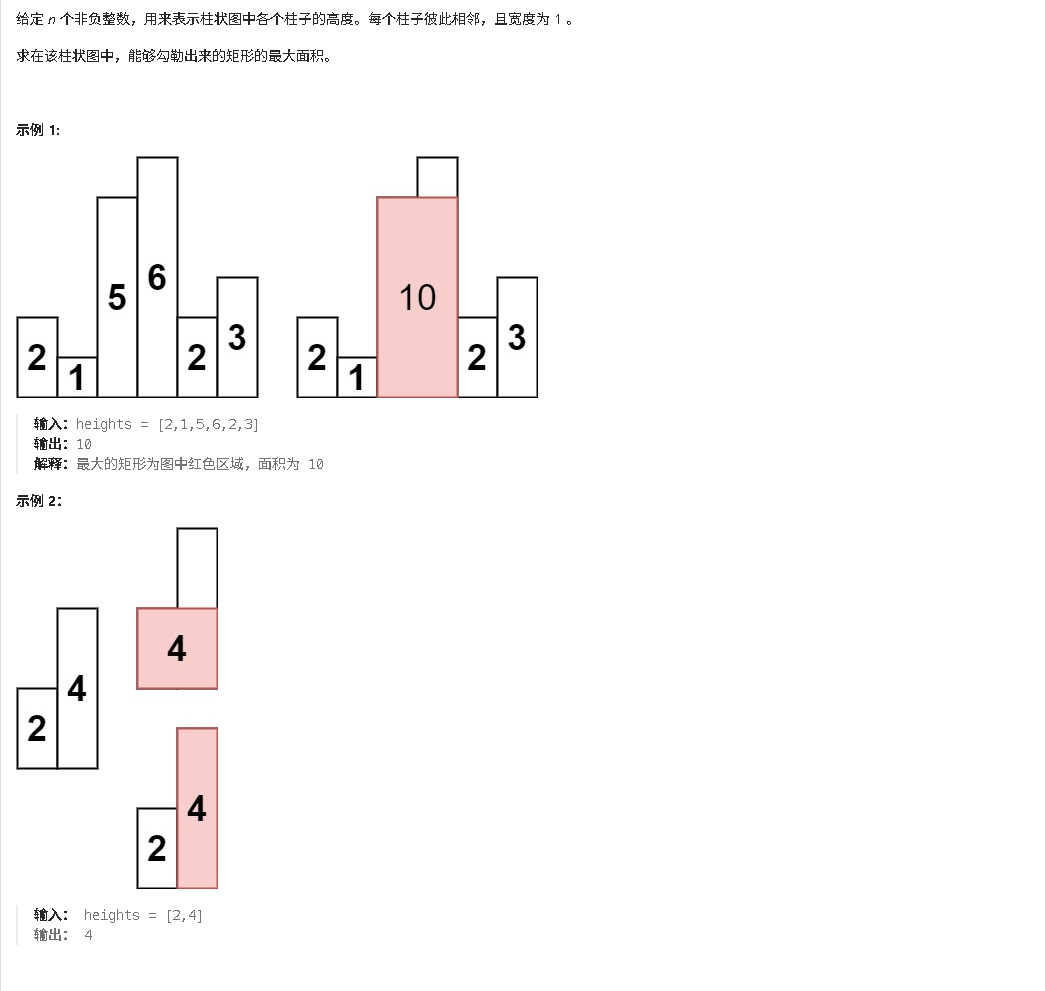
84. 柱状图中最大的矩形
对于该问题因为矩形是由宽和高组成的, 因此可以枚举高, 对于当前位置向左找到第一个比它矮的柱子, 同理向右也找到第一个比它矮的柱子, 枚举高度计算统计最大矩形的面积, 算法时间复杂度 O ( n ) O(n) O(n), 注意边界问题的计算
核心边界计算: 因为 l [ i ] l[i] l[i]和 r [ i ] r[i] r[i]分别计算左右两侧$ < h[i]$的柱子的位置, 那么之间的就是 ≥ h [ i ] \ge h[i] ≥h[i]的柱子, 当前柱子就是高度的下限值
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
class Solution {
public:
int l[N], r[N];
int stk[N], top;
int largestRectangleArea(vector<int> &heights) {
for (int i = 0; i < heights.size(); ++i) {
while (top && heights[stk[top]] >= heights[i]) top--;
l[i] = top ? stk[top] : -1;
stk[++top] = i;
}
top = 0;
for (int i = heights.size() - 1; i >= 0; --i) {
while (top && heights[stk[top]] >= heights[i]) top--;
r[i] = top ? stk[top] : heights.size();
stk[++top] = i;
}
int ans = 0;
for (int i = 0; i < heights.size(); ++i) {
int area = heights[i] * (r[i] - l[i] - 1);
ans = max(ans, area);
}
return ans;
}
};
42. 接雨水
从栈底到栈顶单调递减, 当height[stk[top]] < height[i], 也就是栈顶的高度小于当前柱子高度, 每次从栈中弹出一个idx, 计算形成的水柱大小

#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
class Solution {
public:
int trap(vector<int>& height) {
int n = height.size();
int stk[N], top = 0;
int ans = 0;
for (int i = 0; i < n; ++i) {
while (top && height[stk[top]] < height[i]) {
int idx = stk[top--];
if (top == 0) break;
int d = i - stk[top] - 1;
int h = min(height[i], height[stk[top]]) - height[idx];
ans += d * h;
}
stk[++top] = i;
}
return ans;
}
};
单调队列解决的问题是滑动窗口中求最大值或者最小值, 维护队头最大值或者最小值, 实现整体的队列是单调的

#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int n, k, w[N];
int q[N], h = 0, t = -1;
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> k;
for (int i = 0; i < n; ++i) cin >> w[i];
for (int i = 0; i < n; ++i) {
while (h <= t && i - q[h] + 1 > k) h++;
while (h <= t && w[i] <= w[q[t]]) t--;
q[++t] = i;
if (i >= k - 1) cout << w[q[h]] << ' ';
}
h = 0, t = -1;
cout << '\n';
for (int i = 0; i < n; ++i) {
while (h <= t && i - q[h] + 1 > k) h++;
while (h <= t && w[i] >= w[q[t]]) t--;
q[++t] = i;
if (i >= k - 1) cout << w[q[h]] << ' ';
}
return 0;
}
KMP
KMP算法实现原理

然后将字符串的所有非空前缀全部列出来
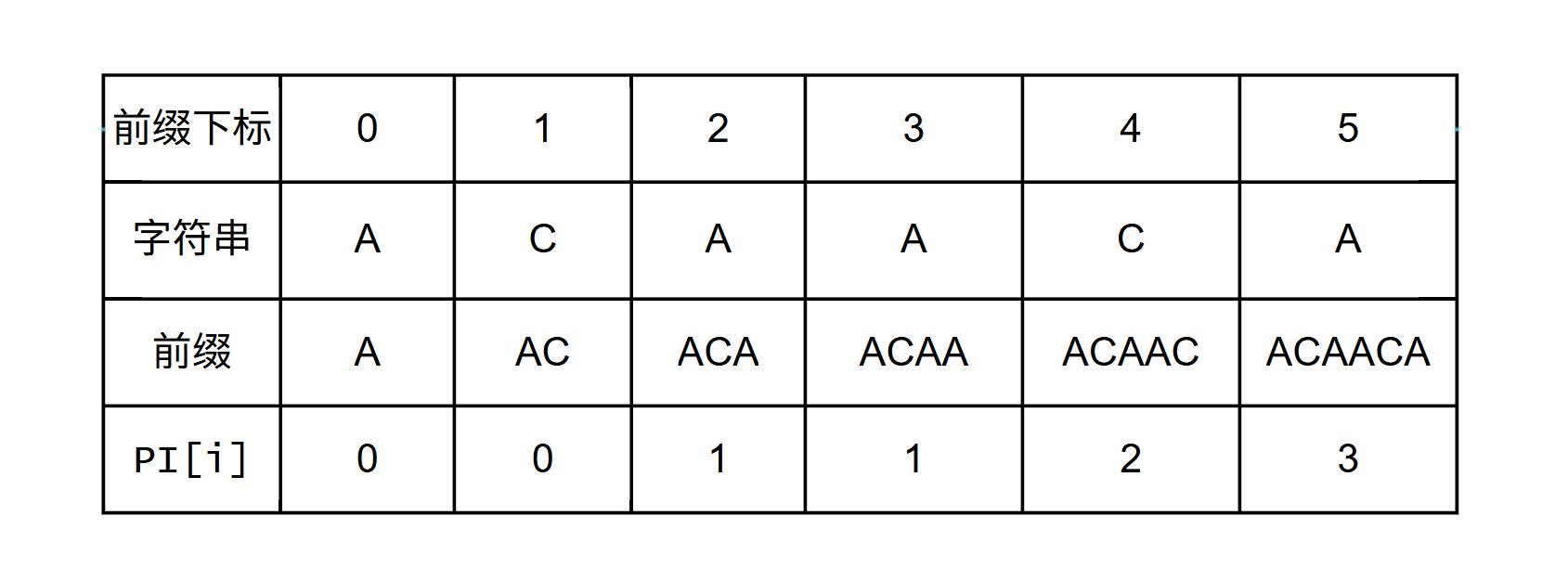
如果直接暴力求 π \pi π, 算法时间复杂度 O ( n 2 ) O(n ^ 2) O(n2), 需要进行优化
假设已经计算出了 π 0 π i − 1 \pi_{0} ~ \pi_{i - 1} π0 πi−1, 当前希望计算 π i \pi_{i} πi
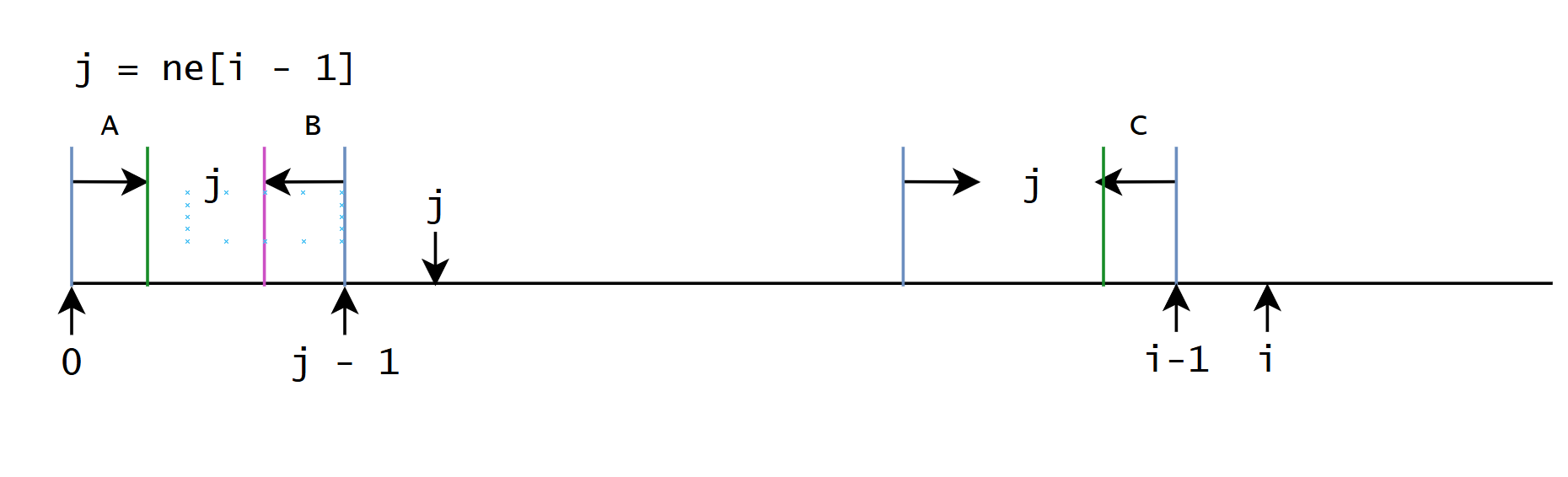
对于当前情况, 如果 S [ p i i − 1 + 1 ] = S [ i ] S[pi_{i - 1} + 1] = S[i] S[pii−1+1]=S[i], 那么 π i = π i − 1 + 1 \pi_{i} = \pi_{i - 1} + 1 πi=πi−1+1
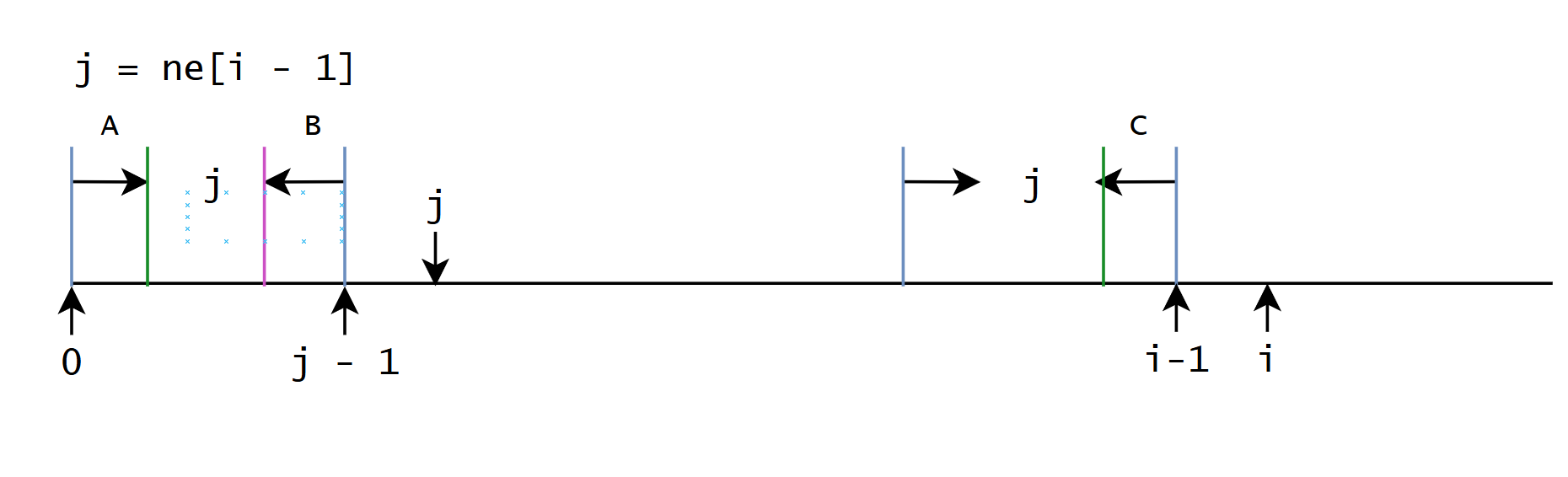
如果不相等, 找第二长的公共前后缀, 假设位置是 t t t, 如果相等 π i = π t + 1 \pi_{i} = \pi_{t} + 1 πi=πt+1, 如果不相等继续找第三长的
那么问题就变成了, 如何根据当前最长公共的前后缀找到第二长的公共前后缀
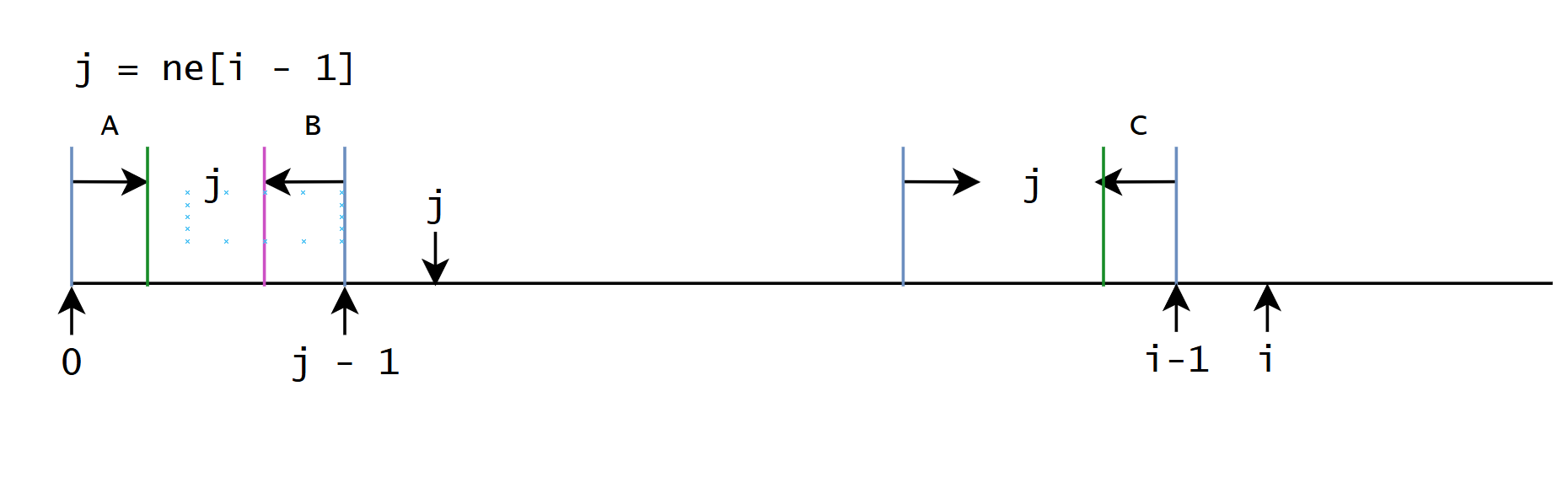
A , B , C A, B, C A,B,C三段相等, 也就是
int j = ne[i - 1];
if (s[j] != s[i]) {
j = ne[j - 1];
}
这样就可以在线性的时间复杂度内处理出 π i \pi_{i} πi数组
那么如何使用 π i \pi_{i} πi来解决字符串匹配的问题?
假设目标串是 S S S, 给定的模式串是 P P P, 可以进行拼接操作S' = P + # + S, 对新的字符串求一遍 π i \pi_{i} πi, 当 π i = P . s i z e ( ) \pi_{i} = P.size() πi=P.size(), 说明找到了模式串
还有一个点忘记说了, 为什么将一个循环分为两个循环之后需要将
j清零? 实际上拼接字符串过程中的添加的特殊字符就是在 i i i遍历到 S S S串的时候, j j j需要重新指向 P P P串的第一个前缀位置进行比对, 将一个循环拆分成两个之后, 需要手动的将 j j j置零
#include <bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10;
class Solution {
public:
int strStr(string haystack, string needle) {
int m = needle.size();
int ne[N] = {
0};
string new_s = needle + '@' + haystack;
for (int i = 1; i < new_s.size(); ++i) {
int j = ne[i - 1];
while (j && new_s[j] != new_s[i]) j = ne[j - 1];
if (new_s[j] == new_s[i]) ne[i] = j + 1;
if (ne[i] == m) {
return i - 2 * m;
}
};
return -1;
}
};
拆分写法
因为拆分之前两个字符串直接使用特殊字符连接, 拆分之后特殊字符消失, j j j需要清零, 其实特殊字符的作用就是将 j j j移动到初始位置
#include <bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10;
class Solution {
public:
int strStr(string s, string p) {
int n = s.size(), m = p.size();
int ne[N] = {
0};
for (int i = 1; i < m; ++i) {
int j = ne[i - 1];
while (j && p[j] != p[i]) j = ne[j - 1];
if (p[j] == p[i]) ne[i] = j + 1;
}
for (int i = 0, j = 0; i < n; ++i) {
while (j && p[j] != s[i]) j = ne[j - 1];
if (p[j] == s[i]) j++;
if (j == m) return i - m + 1;
}
return -1;
}
};
字符串偏移写法
#include <bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10;
class Solution {
public:
int strStr(string s, string p) {
s = ' ' + s, p = ' ' + p;
int n = s.size(), m = p.size();
int ne[N] = {
0};
for (int i = 2; i < m; ++i) {
int j = ne[i - 1];
while (j && p[j + 1] != p[i]) j = ne[j];
if (p[j + 1] == p[i]) ne[i] = j + 1;
}
for (int i = 1, j = 0; i < n; ++i) {
while (j && p[j + 1] != s[i]) j = ne[j];
if (p[j + 1] == s[i]) j++;
if (j == m - 1) return i - m + 1;
}
return -1;
}
};
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int n, m;
string p, s;
int ne[N];
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> p;
p = ' ' + p;
cin >> m >> s;
s = ' ' + s;
//预处理ne数组
for (int i = 2, j = 0; i <= n; ++i) {
while (j && p[j + 1] != p[i]) j = ne[j];
if (p[j + 1] == p[i]) j++;
ne[i] = j;
}
// 枚举主串
for (int i = 1, j = 0; i <= m; ++i) {
while (j && p[j + 1] != s[i]) j = ne[j];
if (p[j + 1] == s[i]) j++;
if (j == n) {
cout << i - n << ' ';
j = ne[j];
}
}
cout << '\n';
return 0;
}
Trie字典树
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int n;
int tr[N][26], cnt[N], idx;
void insert(string &s) {
int p = 0;
for (int i = 0; s[i]; ++i) {
int val = s[i] - 'a';
if (!tr[p][val]) tr[p][val] = ++idx;
p = tr[p][val];
}
cnt[p]++;
}
int query(string &s) {
int p = 0;
for (int i = 0; s[i]; ++i) {
int val = s[i] - 'a';
if (!tr[p][val]) return 0;
p = tr[p][val];
}
return cnt[p];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
char op[2];
cin >> n;
while (n--) {
string s;
cin >> op;
cin >> s;
if (*op == 'I') insert(s);
else cout << query(s) << '\n';
}
return 0;
}
Trie树解决最大异或对问题
将数字倒叙插入到Trie中, 在路径中寻找尽可能不同的值也就是异或值为1的路线走, 算法时间复杂度 O ( 30 × n ) O(30 \times n) O(30×n), 如果存在异或值为1的节点, 将树的指针移动到该位置, 否则只能走相同节点
#include <bits/stdc++.h>
using namespace std;
const int N = 3e6 + 10;
int n, w[N];
int tr[N][2], idx;
// 贪心思想从高位向低位插入
void insert(int x) {
int p = 0;
for (int i = 30; i >= 0; --i) {
int &u = tr[p][x >> i & 1];
if (!u) u = ++idx;
p = u;
}
}
//计算x与其他值的最大异或结果
int calc(int x) {
int p = 0, res = 0;
for (int i = 30; i >= 0; --i) {
int val = x >> i & 1;
if (tr[p][!val]) res += 1 << i, p = tr[p][!val];
else p = tr[p][val];
}
return res;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
for (int i = 0; i < n; ++i) cin >> w[i], insert(w[i]);
int res = 0;
for (int i = 0; i < n; ++i) res = max(res, calc(w[i]));
cout << res << '\n';
return 0;
}
DSU并查集
并查集路径压缩算法时间复杂度接近于常数

#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int n, m;
int p[N];
int find(int u) {
if (p[u] != u) p[u] = find(p[u]);
return p[u];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
for (int i = 0; i <= n; ++i) p[i] = i;
char op[2];
while (m--) {
cin >> op;
int a, b;
cin >> a >> b;
int fa1 = find(a);
int fa2 = find(b);
if (*op == 'M') {
if (fa1 == fa2) continue;
p[fa1] = fa2;
}
else cout << (fa1 == fa2 ? "Yes" : "No") << '\n';
}
return 0;
}
并查集的扩展应用在路径压缩过程中可以维护集合的信息, 例如食物链问题
数据范围 1 0 5 10 ^ 5 105级别, 时间复杂度不能超过 O ( n log n ) O(n \log n) O(nlogn), 将所有动物放到一个集合当中, 只要知道两个动物之间的关系, 那么第一个关系就能确定, 就能确定两两直接的关系
记录每个点和根节点之间的关系, 那么就知道了任意两个点之间的关系, 因为三种动物互相吃, 使用每个点到根节点的距离表示与根节点的关系

所有距离根节点d % 3 == 1, 的节点都可以吃根节点, 所有d % 3 == 2的节点都是被根节点吃的节点, d % 3 == 0 与根节点是同类的节点
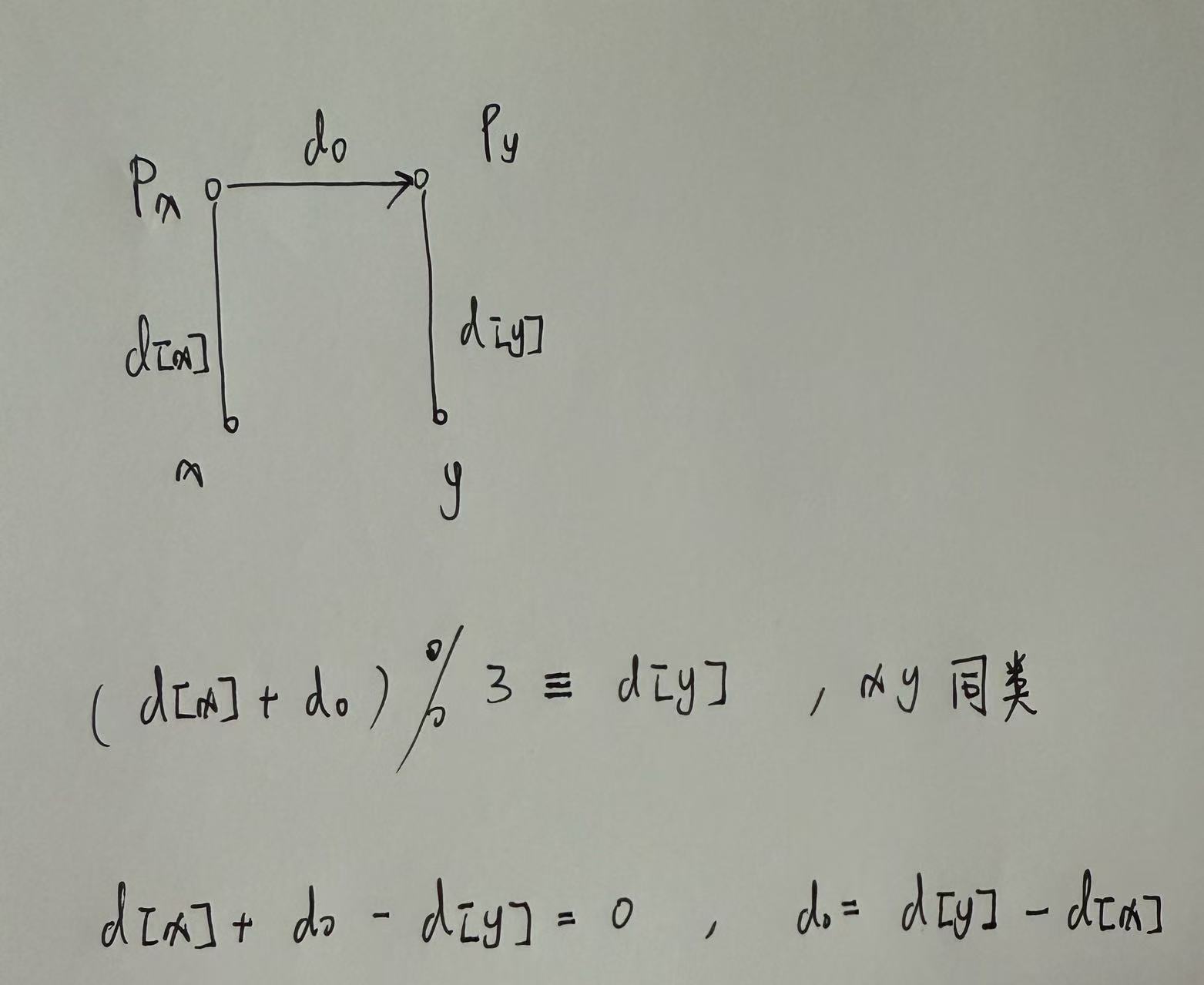
X吃Y说明Y到X的距离是1, 维护每个点到根节点的距离的模数, 在路径压缩过程中, 将每个点到父节点的距离更新为到根节点的距离, 路径压缩后路径就会累加
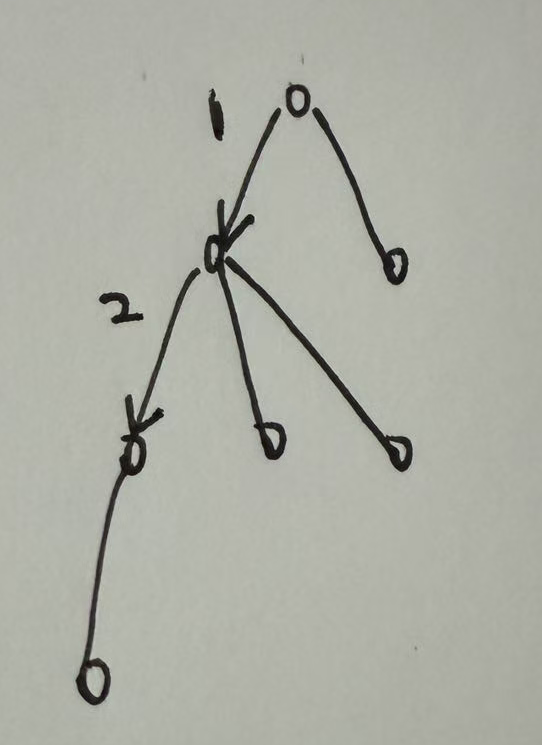
累计距离的方式

如果两个动物的祖先不在一个集合当中, 合并两个集合, 更新完d[p[x]]后, 在下一次find过程中使用路径压缩算法, 所有子节点的距离都会进行更新, 类似于延迟标记
#include <bits/stdc++.h>
using namespace std;
const int N = 5e4 + 10;
int n, m;
int p[N], d[N];
int find(int x) {
if (p[x] != x) {
int fa = p[x];
p[x] = find(p[x]);
d[x] += d[fa];
}
return p[x];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
for (int i = 0; i <= n; ++i) p[i] = i;
int res = 0;
while (m--) {
int op, x, y;
cin >> op >> x >> y;
int px = find(x), py = find(y);
if (x > n || y > n) res++;
else if (op == 1){
if (px == py && (d[x] - d[y] + 3) % 3 != 0) res++;
else {
int tmp = (d[y] - d[x] + 3) % 3;
d[px] += tmp;
p[px] = py;
}
}
else {
if (x == y) res++;
else if (px == py && (d[x] - d[y] + 2) % 3 != 0) res++;
else {
int tmp = (d[y] + 1 - d[x] + 3) % 3;
d[px] += tmp;
p[px] = py;
}
}
}
cout << res << '\n';
return 0;
}
并查集也可以解决区间染色问题, 例如疯狂的馒头问题
核心思想是倒叙的馒头染色后不会进行改变, 如果有区间重叠, 直接指向最后区间的根节点n + 1
用P[i]记录当前位置i下一个未被染色的位置, 初始化每个位都未被染***r> 
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int n, m, p, q;
int fa[N], res[N];
int find(int x) {
if (fa[x] != x) fa[x] = find(fa[x]);
return fa[x];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m >> p >> q;
for (int i = 1; i <= n + 1; ++i) fa[i] = i;
for (int i = m; i >= 1; --i) {
int val1 = (i * p + q) % n + 1;
int val2 = (i * q + p) % n + 1;
int l = min(val1, val2), r = max(val1, val2);
// 找到l开始下一个未染色的位置
int idx = find(l);
while (idx <= r) {
res[idx] = i;
fa[idx] = find(idx + 1);
idx = find(idx);
}
}
for (int i = 1; i <= n; ++i) cout << res[i] << '\n';
return 0;
}
二叉堆(优先队列)
堆排序
递归定义, 每个点的值都是小于等于其子节点的值
使用数组实现堆的存储
堆的基本操作
- down(x), 从当前节点向下调整
- up(x), 从当前节点向上调整
比如修改了头节点的值, 需要向下调整也就是down操作, 每次选择一个最小子树的节点交换, 递归进行
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int n, m;
int heap[N], sz;
void down(int u) {
if (u > sz) return;
int curr = u;
int l = u << 1, r = u << 1 | 1;
if (l <= sz && heap[l] < heap[curr]) curr = l;
if (r <= sz && heap[r] < heap[curr]) curr = r;
if (u != curr) {
swap(heap[u], heap[curr]);
down(curr);
}
}
void del_top() {
heap[1] = heap[sz];
sz--;
down(1);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
for (int i = 1; i <= n; ++i) cin >> heap[i];
sz = n;
for (int i = n; i >= 1; --i) down(i);
for (int i = 1; i <= m; ++i) {
cout << heap[1] << ' ';
del_top();
}
return 0;
}
一定要注意将数字插入到堆中后需要进行初始化堆, 也就是从下到上进行
down操作
数组实现堆的数据结构
难点在随机的修改和删除,需要存储第k个插入的点对应堆的下标ph[i], 同时存储堆里面的下标对应第几个插入的数hp[i], 考虑如下的情况
如果两个节点索引进行交换, 那么需要交换ph[j]和ph[j]
假设在堆中需要交换(u, v)两个节点, 需要交换指向他们的节点索引ph[hp[u]]和ph[hp[v]], 因此需要反向记录


#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int n;
int heap[N], sz;
int ph[N], hp[N], idx;
void heap_swap(int u, int v) {
swap(ph[hp[u]], ph[hp[v]]);
swap(hp[u], hp[v]);
swap(heap[u], heap[v]);
}
void down(int u) {
int t = u;
int l = u << 1, r = u << 1 | 1;
if (l <= sz && heap[l] < heap[t]) t = l;
if (r <= sz && heap[r] < heap[t]) t = r;
if (t != u) {
heap_swap(u, t);
down(t);
}
}
void up(int u) {
while (u >> 1 && heap[u >> 1] > heap[u]) {
heap_swap(u, u >> 1);
u >>= 1;
}
}
void insert(int val) {
idx++, sz++;
ph[idx] = sz, hp[sz] = idx;
heap[sz] = val;
up(sz);
}
int get_min() {
return heap[1];
}
void del_min() {
heap_swap(1, sz);
sz--;
down(1);
}
void del_k(int k) {
int u = ph[k];
heap_swap(u, sz);
sz--;
up(u), down(u);
}
void modify_k(int k, int val) {
int u = ph[k];
heap[u] = val;
up(u), down(u);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
char op[5];
while (n--) {
cin >> op;
if (op[0] == 'I') {
int val;
cin >> val;
insert(val);
}
else if (op[0] == 'P' && op[1] == 'M') cout << get_min() << '\n';
else if (op[0] == 'D' && op[1] == 'M') del_min();
else if (op[0] == 'D') {
int k;
cin >> k;
del_k(k);
}
else if (op[0] == 'C') {
int k, val;
cin >> k >> val;
modify_k(k, val);
}
}
return 0;
}
哈希表
模拟拉链法散列表, 对于产生的哈希冲突使用头插法插入单链表
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10, MOD = 2e5 + 7;
const int M = 1e9;
int n;
int tab[N], ne[N], idx;
int w[N];
int get_hash(int val) {
return val % 998244353 % MOD;
}
void insert(int val) {
w[idx] = val;
if (val < 0) val = M + val;
int p = get_hash(val);
int t = tab[p];
ne[idx] = t;
tab[p] = idx++;
}
bool contain(int val) {
if (val < 0) val = M + val;
int p = get_hash(val);
for (int i = tab[p]; ~i; i = ne[i]) {
if ((w[i] == val) || (M + w[i] == val)) return true;
}
return false;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
memset(tab, -1, sizeof tab);
char op[5];
while (n--) {
cin >> op;
int val;
cin >> val;
if (*op == 'I') insert(val);
else {
cout << (contain(val) ? "Yes" : "No") << '\n';
}
}
return 0;
}
字符串哈希
字符串前缀哈希法, 可以实现 O ( 1 ) O(1) O(1)的时间复杂度进行字符串比较, 在下面问题上处理速度远超于KMP算法
对输入的字符串进行前缀哈希

如何通过前缀哈希计算出子串哈希
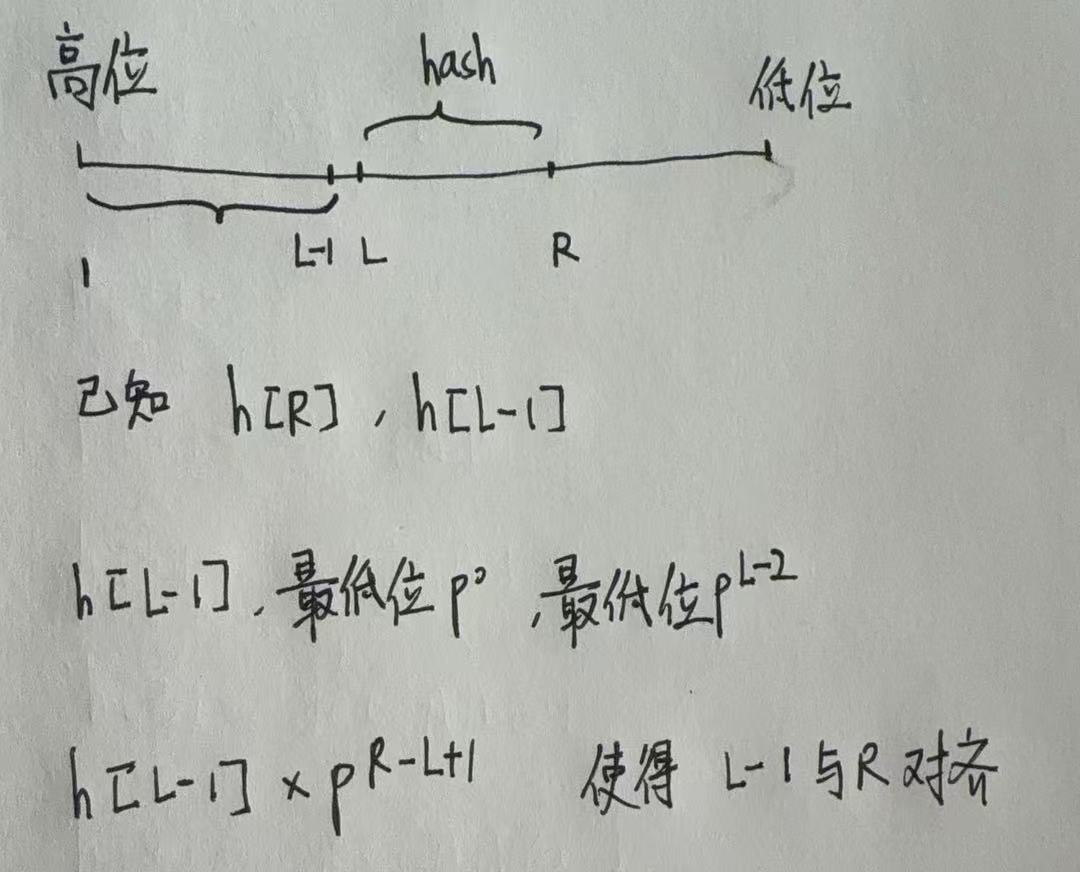
因为最低位是 在右侧, 因此根据前缀和的思想将[1, L - 1]段移动到与右侧R对齐的位置上, 这样相减得到的就是子串[L, R]的哈希值
注意虽然最高位在左侧, 但是计算哈希值是从左向右计算的, 因此将左侧字串移动到右侧需要 × p [ r − l + 1 ] \times p[r - l + 1] ×p[r−l+1]
规定将字符串看作是P进制数, P设定为131, 131是个经验上产生哈希冲突概率比较小的选择
#include <bits/stdc++.h>
using namespace std;
typedef unsigned long long ULL;
const int N = 1e5 + 10, P = 131;
int n, m;
string s;
ULL h[N], p[N];
void calc_hash() {
p[0] = 1;
for (int i = 1; i <= n; ++i) {
h[i] = h[i - 1] * P + s[i];
p[i] = p[i - 1] * P;
}
}
ULL sub_hash(int l, int r) {
return h[r] - h[l - 1] * p[r - l + 1];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
cin >> s;
s = ' ' + s;
calc_hash();
while (m--) {
int l1, r1, l2, r2;
cin >> l1 >> r1 >> l2 >> r2;
ULL val1 = sub_hash(l1, r1), val2 = sub_hash(l2, r2);
cout << (val1 == val2 ? "Yes" : "No") << '\n';
}
return 0;
}

 京公网安备 11010502036488号
京公网安备 11010502036488号