

论文原文
https://arxiv.org/pdf/1412.7062v3.pdf
模型结构
论文上的原图是这样的:
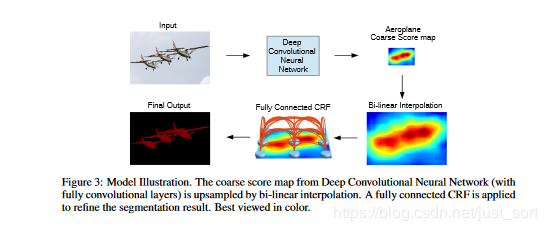
DeepLab的BackBone依赖于VGG16,具体改造方法就是:
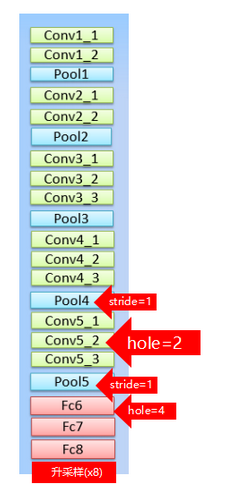
- 将最后的全连接层FC6,FC7,FC8改造成卷积层。
- pool4的stride由2变成1,则紧接着的conv5_1,conv5_2和conv5_3中hole size为2。
- 接着pool5由2变成1,则后面的fc6中的hole size为4。
- fc7,fc8为标准的卷积。
- 由于空洞卷积算法让feature map更加精细,因此网络直接采用插值上采样就能获得很好的结果,不用去学习上采样的参数了(FCN中采用了de-convolution)。
核心问题
以前的DCNN在做语义分割的时候,出现的问题一般有两个:1,多次池化,下采样使输出信号分辨率变小。2,不断下采样引起的图像分辨率变小导致的位置信息丢失。
空洞卷积
针对第一个问题,Deeplab提出了空洞卷积:空洞卷积的作用有两点,一是控制感受野,而是调整分辨率。
首先来看控制感受野,图来自:https://mp.weixin.qq.com/s?__biz=MzA3NDIyMjM1NA==&mid=2649032510&idx=1&sn=e65528e6ce1d0c31d9c7f20cdb171a90&chksm=8712b943b0653055fe820db0fb56b87d7ef4032e82261914e437e3c5bcec59d6abfd930f7e1d&scene=21#wechat_redirect
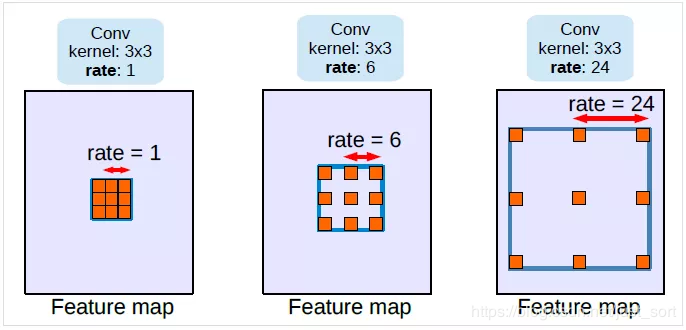
针对第二个问题,我们设置滑动的步长,就可以让空洞卷积增大感受野的同时也降低分辨率。
CRF
首先是因为图像在CNN里面通过不断下采样,原来的位置信息会随着深度减少甚至消失。最后会导致分类结果变得十分平滑,但是我们需要细节更加突出的结果,可以看下面的图:
这里引入了CRF来解决这个问题,首先CRF在传统图像处理上主要做平滑处理。对于CNN来说,short-range CRFs可能会起到反作用,因为我们的目标是恢复局部信息,而不是进一步平滑图像。本文引入了全连接CRF来考虑全局信息。

CRF的计算公式为:
E(x)=∑iθi(xi)+∑ijθij(xi,xj)
- x:对全局pixels的概率预测分布
- xi:其中一个pixel的概率预测分布
- θi:一元势函数 unary potential function
θi(xi):=−logP(xi) - θij:二元势函数
θij(xi,xj):=∑m=1Kwmkm(fi,fj)
K : Kernel数量 w : 权重
本文采用高斯核,并且任意两个像素点都有此项,故称为fully connected CRFs。
θij(xi,xj)=u(xi,xj)∑m=1Kwmkm(fi,fj),whereu(xi,xj)=1ifxi!=xj
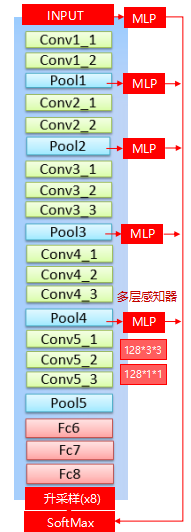
多尺度预测
- 多尺寸预测,希望获得更好的边界信息。
- 引入:与FCN skip layer类似。
- 实现:
- 在输入图片与前四个max pooling后添加MLP(多层感知机,第一层是128个3×3卷积,第二层是128个1×1卷积),得到预测结果。
- 最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=6405×128=640个通道。
- 效果不如dense CRF,但也有一定提高。最终模型是结合了Dense CRF与Multi-scale Prediction。
这里有个效果图如下(转自:https://blog.csdn.net/qq_31622015/article/details/90551107):
训练
DCNN模型采用预训练的VGG16,DCNN损失函数采用交叉熵损失函数。训练器采用SGD,batchsize设置为20。学习率初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1。权重衰减为0.9的动量, 0.0005的衰减。
DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,对CRF做交叉验证。这里使用 ω2=3 和 σγ=3 在小的交叉验证集上寻找最佳的 ω1,σα,σβ。
代码实现
https://github.com/yilei0620/RGBD-Slam-Semantic-Seg-DeepLab/blob/master/slam_deepLab/model/test.prototxt
参考博客
https://blog.csdn.net/qq_31622015/article/details/90551107

 京公网安备 11010502036488号
京公网安备 11010502036488号