

在写 Python 程序的时候,我们需要依赖一些库,所以一开始我们总是:
import xxx as xxx
from xxx import xxx
我们有时候写着写着发现需要引入新的库,就又得回到前面,再 import 一波,如果你用的是类似 jupyter 的编辑器,你添加完 import 语句之后还得再运行一下代码块。

这些操作往往都是重复性的,比如我们玩数据可视化的时候,总会这样去 import 相关的库:
import pandas as pd
import numpy as np
import seaborn as sns
...
这时候有人就想到,哇靠,真麻烦,能不能不要每次都自己导入这些库啊?你已经是个成年人了,能不能在我写代码调用到相关库的时候,你给老子自动导入啊?别报错啊!

像这样:
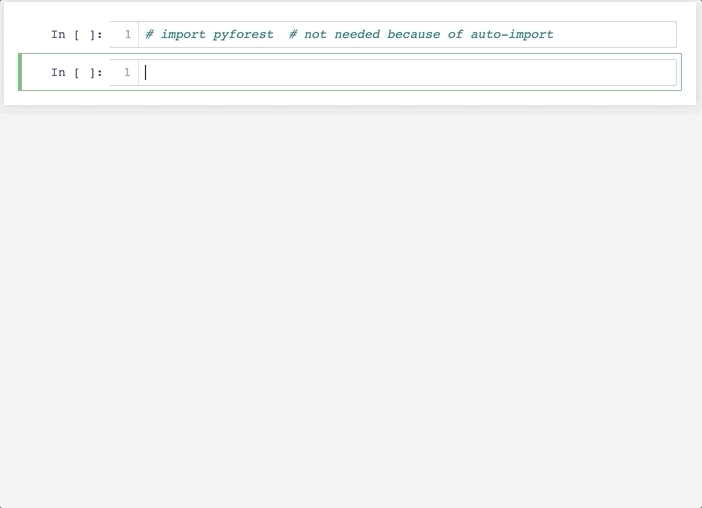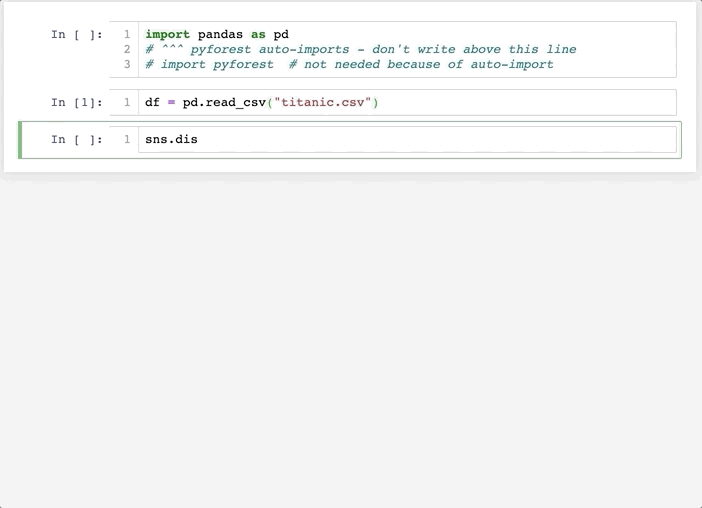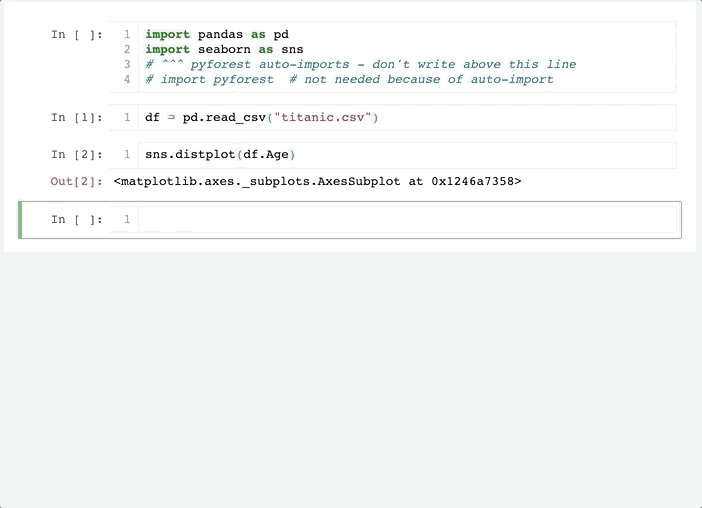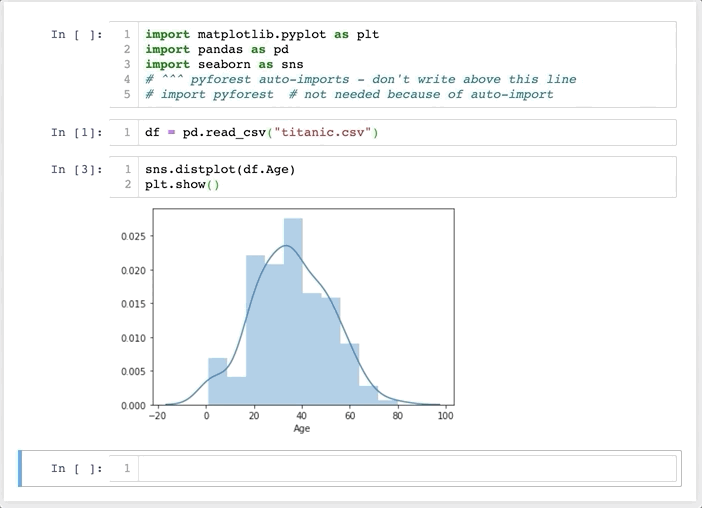
可以看到,在这里不用事先 import ,而是当使用到相关库的时候,自动在第一行帮我们 import,幸福啊!

怎么弄的咧?
接下来要给你分享的是——Pyforest,一个可以自动帮你 import 的库。
这个库把一些流行的数据分析需要的 「import 语句」都封装起来了。
它具有「懒加载」的功能,也就是说,当你安装完之后,你在代码中使用到相关的库的时候,它就会帮你自动 import。而那些封装好了的 import 语句,在你没有使用到时是不会帮你一股脑 import 进来的。
你可以通过 pip 安装一波:
python pip install --upgrade pyforest
安装完成后,你的 IPython 启动配置会默认添加 pyforest_autoimport.py,这样我们在使用 IPython 或者 Jupyter 的时候,可以直接使用它的功能,你在写代码时连它本身都不需要 import:
import pyforest
比如当你安装完之后,你可以直接打开 IPython,在不用写 import 语句的情况下,直接使用相关的库:
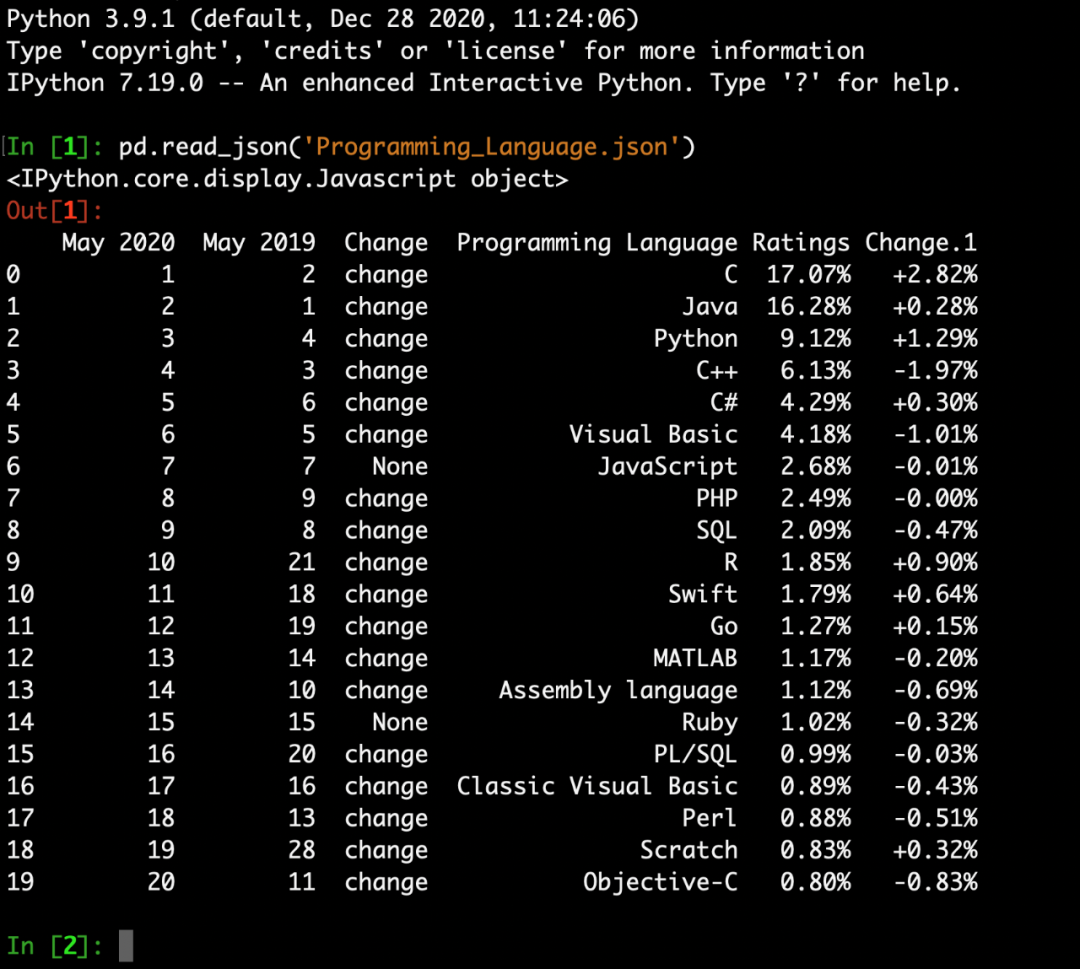
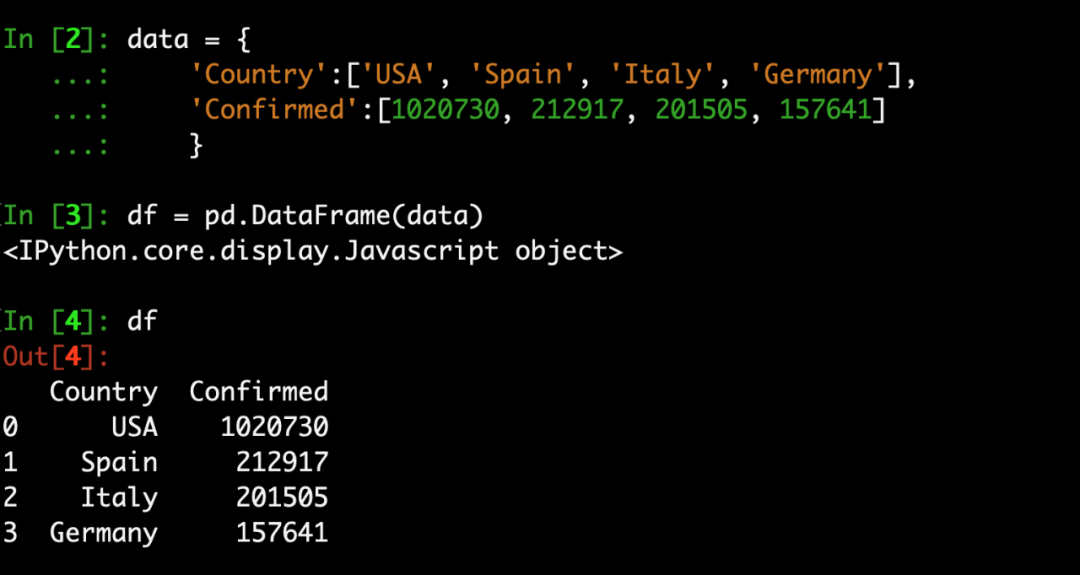
你可以看到,我这里的操作是直接使用库的简称,这是因为人家在写 LazyImport 的时候,已经按我们写代码的习惯安排好了:
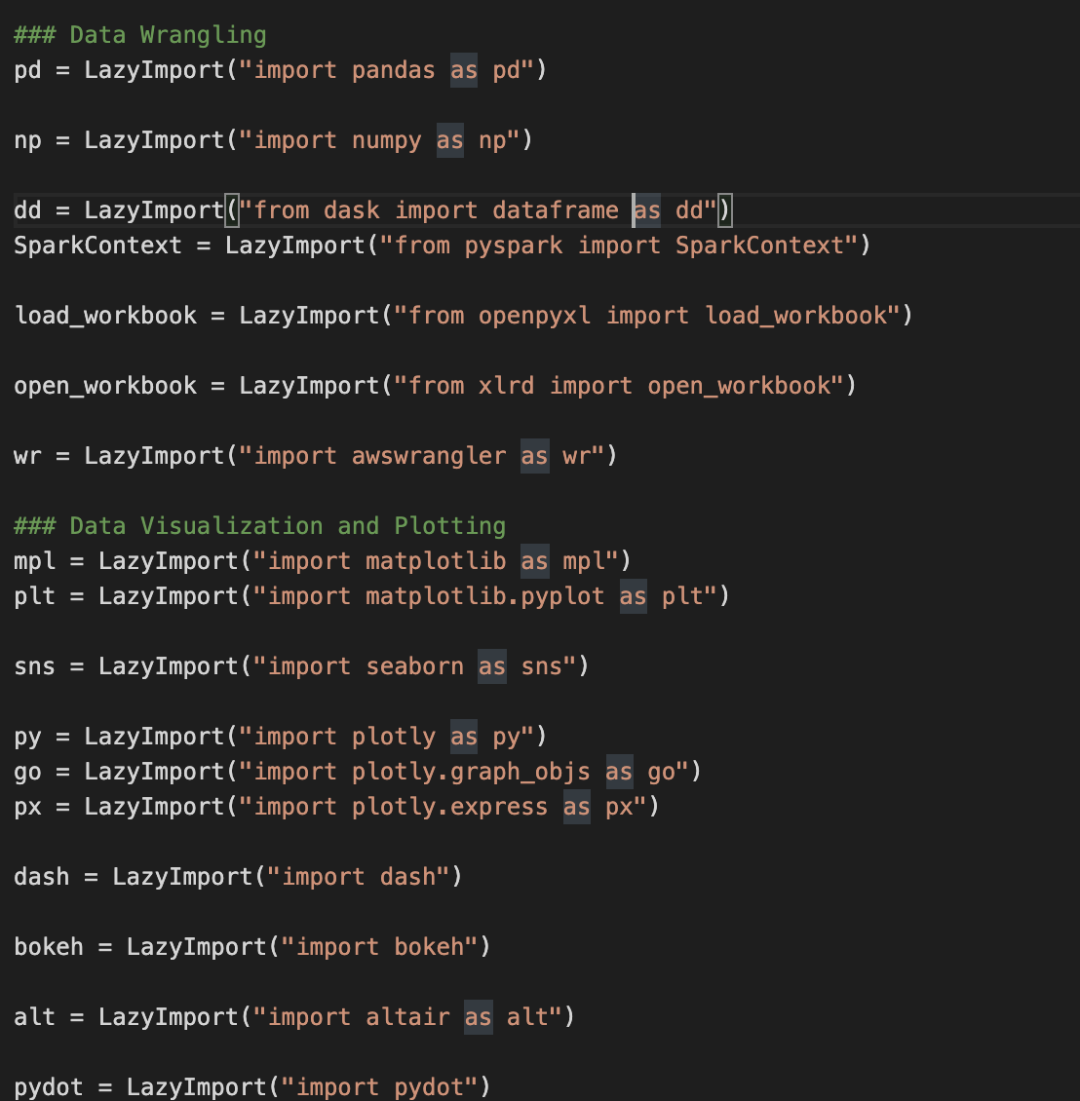
怎么样?

当然,这里面封装的 import 语句更多是做数据可视化相关的,那么如果你自己还想添加一些别的 import 语句进去,咋整呢?
很简单,进入到你安装的 pyforest 中,在 user_imports.py 中添加即可,一般路径如下:
~/.pyforest/user_imports.py
比如,我在这里添加一个 import requests 的语句:
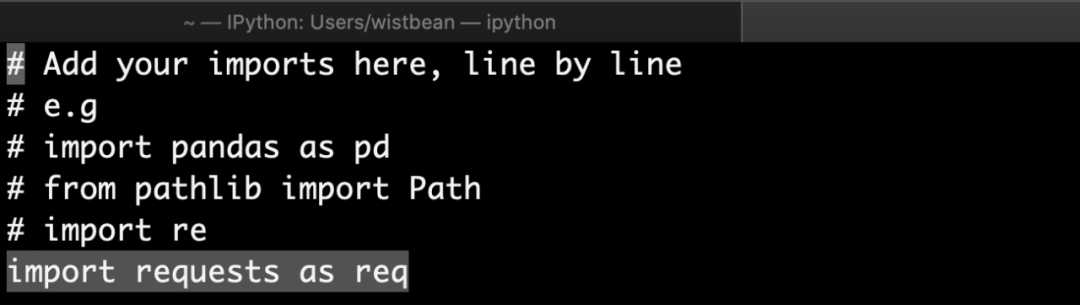
接着我就可以在不用导入 requests 的情况下,直接请求了:
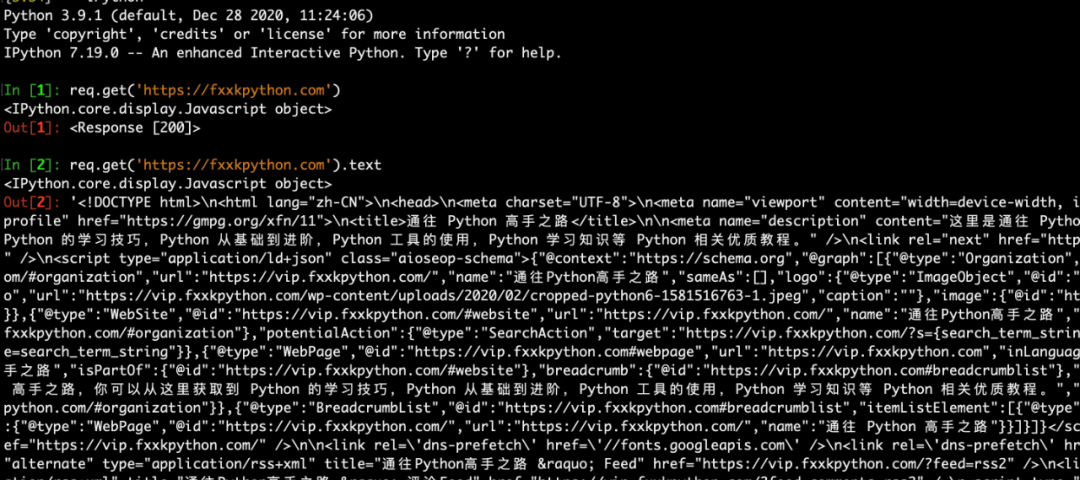
你完全可以根据你自己的习惯,在 user_imports.py 添加 import 语句。
妈妈再也不用担心,每次依赖库的时候都需要写 import 了。

这个库比较适合在Jupyter Notebook, Jupyter Lab 或者 IPython 中使用,如果你想在别的地方也使用它,可以先导入 Pyforest,接着就可以使用你已经封装好的 import 语句,像这样:


 京公网安备 11010502036488号
京公网安备 11010502036488号