


"##[[TOC]] MySQL数据库基础知识"
最近整理一份关于MySQL常见面试题的,也会根据自己的经验, 标注一些出现的概率,最高5颗★出现的概率最高。比如这样:
百万级别或以上的数据如何删除
出现概率: ★★★
一般来讲在面试当中, 关于数据库相关的面试题频率出现比较高的几个关键词是SQL优化、索引、存储引擎、事务、死锁、乐观锁、悲观锁、关系型数据库和非关系数据库对比等等。 把这几个点问完基本也差不多10~20分钟了(一般一轮面试1小时左右), 基本这些可以让面试官对你的数据库知识有一定的了解了。
如果你线上运维经验, 一般也会问一些比如数据库扩容, 如何给大表加索引, 如何在业务高峰是给一个大表添加字段等。
也欢迎关注我的公众号: 漫步coding, 回复: mysql免费获取最新Mysql面试题汇总(含答案)。 一起交流, 在coding的世界里漫步。

也可以通过我的博客在线阅读
目录
-
一、数据库基础知识
- 1、平时MySQL主要用哪个版本
- 2、数据库三大范式是什么
- 3、MySQL有关权限的表都有哪几个
- 4、MySQL的binlog有有几种录入格式?分别有什么区别?
- 5、平时用到哪些关系型数据库和非关系数据库, 可以谈谈你对它们的理解吗?
- 6、可以简单说说你对MySQL的逻辑架构了解吗?
- 7、了解MySQL中的MVCC是什么?
- 8、PostgreSQL相对于MySQL的优势
- 9、PostgreSQL和MySQL的一些区别
-
二、索引
- 1、索引有哪些使用场景(重点)
- 2、索引的数据结构(b树,hash)
- 3、创建索引的原则是什么?(重中之重)
- 4、使用索引查询一定能提高查询的性能吗?为什么
- 5、索引有哪些优缺点?
- 6、讲一讲聚簇索引与非聚簇索引?
- 7、百万级别或以上的数据如何删除
- 8、什么是最左前缀原则?什么是最左匹配原则
- 9、数据库为什么使用B+树而不是B树
- 10、非聚簇索引一定会回表查询吗?
- 11、有哪些情况, 索引会失效, 可以简单说说吗?
-
三、MySQL存储引擎
- 1、可以简单谈谈MySQL存储引擎MyISAM与InnoDB区别
- 2、MyISAM索引与InnoDB索引的区别?
- 3、InnoDB引擎的4大特性
-
四、MySQL事务
- 1、什么是数据库事务?
- 2、事物的四大特性(ACID)介绍一下?
- 3、什么是脏读?幻读?不可重复读?
- 4、什么是事务的隔离级别?MySQL的默认隔离级别是什么?
- 5、隔离级别的实现原理
- 6、事务延伸点: 分布式事务
-
五、MySQL数据库读写锁
- 1、谈一谈MySQL的读写锁
- 2、隔离级别与锁的关系
- 3、按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
- 4、从锁的类别上分MySQL都有哪些锁呢?像上面那样子进行锁定岂不是有点阻碍并发效率了
- 5、MySQL中InnoDB引擎的行锁是怎么实现的?
- 6、InnoDB存储引擎的锁的算法有三种
- 7、什么是死锁?怎么解决?
- 8、数据库的乐观锁和悲观锁是什么?怎么实现的?
-
六、MySQL视图
- 1、为什么要使用视图?什么是视图?
- 2、视图有哪些特点?
- 3、视图的使用场景有哪些?
- 4、视图的优点
- 5、视图的缺点
- 6、存储过程与函数
-
七、MySQL触发器
- 1、什么是触发器?触发器的使用场景有哪些?
- 2、MySQL中都有哪些触发器?
-
八、MySQL数据库优化
- 1、为什么要优化
- 2、数据库结构优化
- 3、MySQL数据库cpu飙升到500%的话他怎么处理?
- 4、大表怎么优化?某个表有近千万数据,CRUD比较慢,如何优化?
- 5、垂直分表的适用场景和优缺点
- 6、水平分表的适用场景和优缺点
- 7、MySQL的复制原理以及流程
- 8、读写分离有哪些解决方案?
- 9、数据表损坏的修复方式有哪些?
-
九、MySQL部署和运维
- 1、如何更新给一个大表建索引
- 2、如何批量删除N行记录, 有什么注意事项
- 3、如何删除表?
- 4、MySQL如何扩容
- 5、如何排查因为MySQL导致CPU占用高的问题?
- 6、MySQL数据库磁盘IO使用高,请问如何进行排查?
- 7、如何批量插入大量数据?
- 8、数据备份和恢复
0、概要
- 1、平时MySQL主要用哪个版本
- 2、数据库三大范式是什么
- 3、MySQL有关权限的表都有哪几个
- 4、MySQL的binlog有有几种录入格式?分别有什么区别?
- 5、平时用到哪些关系型数据库和非关系数据库, 可以谈谈你对它们的理解吗?
- 6、可以简单说说你对MySQL的逻辑架构了解吗?
- 7、了解MySQL中的MVCC是什么?
- 8、PostgreSQL相对于MySQL的优势
- 9、PostgreSQL和MySQL的一些区别
1、平时MySQL主要用哪个版本
出现概率: ★★★★
可以说说自己用的MySQL版本, 比如我自己用的版本是5.7版本,然后可以也简单聊聊这个版本的一些特点:
1)、安全性
在MySQL 5.7中,有不少安全性相关的改进。包括:
MySQL数据库初始化完成以后,会产生一个 root@localhost 用户,从MySQL 5.7开始,root用户的密码不再是空,而是随机产生一个密码,这也导致了用户安装5.7时发现的与5.6版本比较大的一个不同点。
MySQL官方已经删除了test数据库,默认安装完后是没有test数据库的,就算用户创建了test库,也可以对test库进行权限控制了 MySQL 5.7版本提供了更为简单SSL安全访问配置,并且默认连接就采用SSL的加密方式。
可以为用户设置密码过期策略,一定时间以后,强制用户修改密码。
2)、灵活性
MySQL 5.7的两个全新的功能,即JSON和generate column
CREATE TABLE t1 (jdoc JSON);
INSERT INTO t1 VALUES('{"key1": "value1", "key2": "value2"}');
3)、可用性
在线设置复制的过滤规则,不再需要重启MySQL,只需要停止SQL thread,修改完成以后,启动SQL thread
这个主要大致谈谈你自己的理解, 也可以根据自己的理解多延展一些, 提高面试的加分。
2、数据库三大范式是什么
出现概率: ★★★
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
3、MySQL有关权限的表都有哪几个
出现概率: ★★★
MySQL服务器通过权限表来控制用户对数据库的访问,权限表存放在mysql数据库里,由mysql_install_db脚本初始化。这些权限表分别user,db,table_priv,columns_priv和host。下面分别介绍一下这些表的结构和内容:
user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
db权限表:记录各个帐号在各个数据库上的操作权限。
table_priv权限表:记录数据表级的操作权限。
columns_priv权限表:记录数据列级的操作权限。
host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和REVOKE语句的影响。
4、MySQL的binlog有有几种录入格式?分别有什么区别?
出现概率: ★★★
MySQL的binlog有三种格式: statement,row和mixed。
1)、statement模式下,每一条会修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
2)、row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。
3)、mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
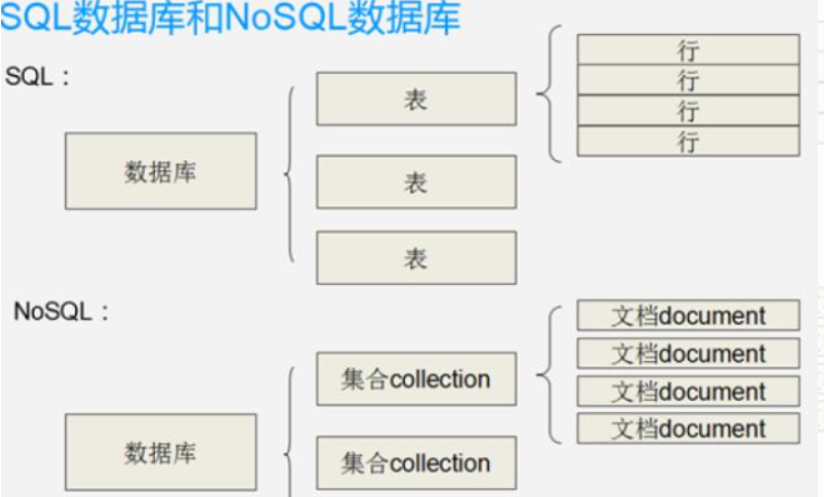
平时用到哪些关系型数据库和非关系数据库, 可以谈谈你对它们的理解吗?
出现概率: ★★★★★
主要讲讲你用过的关系型数据库比如MySQL, 非关系数据库(NoSql数据库)比如Redis, MongoDB等等。
1)、事务方面
关系型数据库的最大特点就是事务的一致性, 所以对于订单模型 对一致性要求比较高的还是建议用MySQL。
2)、关系数据库的另一个特点就是其具有固定的表结构
其实在业务模型中, 表结构固定反而是一件好事, 没有约束的模型 更容易出问题。
3)、复杂SQL,特别是多表关联查询
NoSql是不支持JOIN 这种查询的。
4)、索引方式
关系型数据库:B树、哈希等
NoSql:键值索引
5)、并发支持
关系型数据库:通过事务和锁来支持并发,高并发情况下,执行效率较低。
NoSql:打破了传统关系型数据库范式的约束和事务一致性,因此并发性能高。
当然自己也可以多延伸看一下, 毕竟这个面试出现的概率还是蛮高的。
5、可以简单说说你对MySQL的逻辑架构了解吗?
出现概率: ★★★
第一层是服务器层,主要提供连接处理、授权认证、安全等功能。
第二层实现了 MySQL 核心服务功能,包括查询解析、分析、优化、缓存以及日期和时间等所有内置函数,所有跨存储引擎的功能都在这一层实现,例如存储过程、触发器、视图等。
第三层是存储引擎层,存储引擎负责 MySQL 中数据的存储和提取。服务器通过 API 与存储引擎通信,这些接口屏蔽了不同存储引擎的差异,使得差异对上层查询过程透明。除了会解析外键定义的 InnoDB 外,存储引擎不会解析 SQL,不同存储引擎之间也不会相互通信,只是简单响应上层服务器请求。
6、了解MySQL中的MVCC是什么?
出现概率: ★★★
MVCC 是多版本并发控制,在很多情况下避免加锁,大都实现了非阻塞的读操作,写操作也只锁定必要的行。
InnoDB 的MVCC 通过在每行记录后面保存两个隐藏的列来实现,这两个列一个保存了行的创建时间,一个保存行的过期时间间。不过存储的不是实际的时间值而是系统版本号,每开始一个新的事务系统版本号都会自动递增,事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
MVCC 只能在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作,因为 READ UNCOMMITTED 总是读取最新的数据行,而不是符合当前事务版本的数据行,而 SERIALIZABLE 则会对所有读取的行都加锁。
7、PostgreSQL相对于MySQL的优势
出现概率: ★★★★
- 在SQL的标准实现上要比MySQL完善,而且功能实现比较严谨;
- 存储过程的功能支持要比MySQL好,具备本地缓存执行计划的能力;
- 对表连接支持较完整,优化器的功能较完整,支持的索引类型很多,复杂查询能力较强;
- PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
- PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制,数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小。
8、PostgreSQL和MySQL的一些区别
出现概率: ★★★★
这个其实出现的概率还比较高, 自己可以说几点就行了
MySQL不支持地理数据类型。
从9.2开始,PG支持json数据类型。相对于MySQL来说,PG对json的支持比较先进。他有一些json指定的操作符和函数,是的搜索json文本非常高效。9.4开始,可以以二进制的格式存储json数据,支持在该列上进行全文索引(GIN索引),从而在json文档中进行快速搜索。
从5.7开始,MySQL支持json数据类型,比PG晚。也可以在json列上建立索引。然而对json相关的函数的支持比较有限。不支持在json列上全文索引。由于MySQL对SQL支持的限制,在存储和处理json数据方面,MySQL不是一个很好的选择。
也欢迎关注我的公众号: 漫步coding, 回复: mysql免费获取最新Mysql面试题汇总(含答案)。 一起交流, 在coding的世界里漫步。

希望这篇文章可以帮助大家, 也希望大家都能找到找到的好工作。

 京公网安备 11010502036488号
京公网安备 11010502036488号