

论文地址
https://arxiv.org/pdf/1606.01583.pdf
摘要
无论是在GAN还是DCGAN中,我们鉴别器Discriminator输出的都是一个概率变量(float),代表输入到鉴别器的图片是真的还是假的,SGAN通过使判别器网络输出类别标签将GAN扩展为半监督的。在一个N个类别的数据集上训练生成模型G和判别模型D。训练时,D预测输入数据属于N个类别中的哪一类,加入一个额外的类对应G的输出。我们证明了,相对于普通的GAN,这种方法可以用来生成一个更有效的分类器并可以生成更高质量的样本。生成网络G和判别网络D作为对抗网络同时训练,G接受一个噪声向量作为输入,输出生成的图像(样本),D接受图像并输出该图像是否来自于G。训练G以最大化D犯错的概率,训练D以最小化自己犯错的概率。基于这种对抗,使用CNN可以生成高质量的图片。
论文的贡献:
- 我们对GAN做了一个新的扩展,允许他们同时学习一个生成器模型和一个分类器(鉴别器)。我们把这个扩展为半监督GAN或者SGAN
- 我们表明SGAN在有限的数据集上比吗诶呦生成部分基准分类器提升了分类性能
- 我们证明,SGAN可以显著的提升生成样本的质量并降低生成器的训练时间
SGAN模型
一个标准的GAN中鉴别器网络D输出一个关于输入图像来自数据生成分布中的概率。传统方法中,这由一个单个sigmoid单元结束的前馈式网络实现,但是,也可以由一个softmax输出层实现,每个类一个单元[real,fake]。一旦这样进行修改后,很容易看出D有N+1个输出单元,对应[类1,类2,…,类N, fake]。这种情况下D也可以作为一个C,我们将此网络叫做D/C。训练SGAN和训练GAN类似。SGAN的网络结构如下:
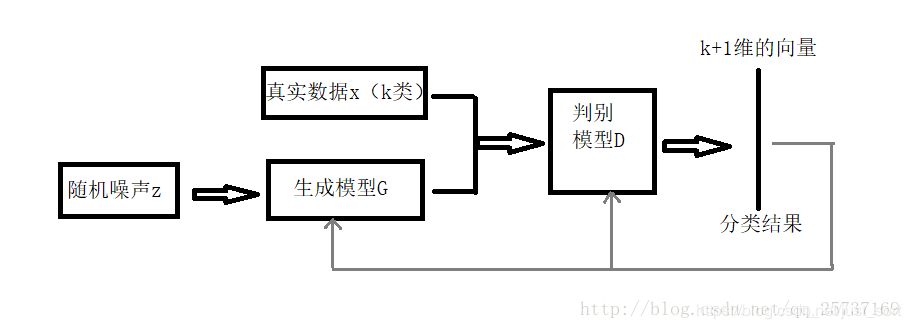
损失函数设计
网络结构确定之后就是设计损失函数,借助GAN我们就可以从无标签数据中学习,只要知道输入数据是真实数据,那就可以通过最大化 logpmodel(y∈1,...,K∣x),这个等式表示不管输入的是哪一类的真实图片(不是生成器G生成的假图片)。只要最大化输出它是真图像的概率就可以了,不需要具体分出是哪一类。由于GAN生成器的参与,训练数据中有一半都是生成的假数据。下面给出判别器D的损失函数设计,D损失函数包括监督学习损失,一个是半监督学习损失,公式为:
L=Lsupervised+Lunsupervised,其中:

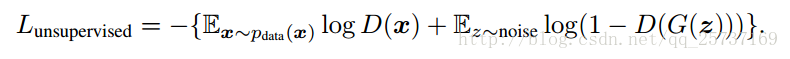
假设分类数有k个,最后的(分类器/鉴别器)输出有k+1个 l1,l2,...,lk,lk+1,那么 pmodel(y=k+1∣x)=∑j=1k+1exp(lj)exp(lk+1)代表了x为假的概率, pmodel(y=i∣x,i<k+1)=∑j=1k+1exp(lj)exp(li)代表x为真且属于第i类的概率。
除了判别器D的损失,我们这里还给出生成器的损失函数等于特征匹配损失函数加上D(x)的对数损失函数,其中

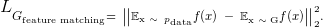

代码
#coding=utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import time
import os
from matplotlib import pyplot as plt
# 超参数设置
x_height, x_width = [28, 28]
num_channels = 1
num_classes = 10
latent_size = 100
labeled_rate = 0.1
# 设置训练参数保存和模型保存的路径
log_path = './SS_GAN_log.csv'
model_path = './SS_GAN_model.ckpt'
# 数据准备
def normalize(x):
x = (x - 127.5) / 127.5
return x.reshape((-1, x_height, x_width, 1))
def get_data():
mnist_data = input_data.read_data_sets("MNIST", one_hot=True)
return mnist_data
# 定义鉴别器结构
def D(x, dropout_rate, is_training, reuse = True, print_summary = True):
# discriminator (x -> n + 1 class)
with tf.variable_scope('Discriminator', reuse=reuse) as scope:
#鉴别器的第一层不使用BN
conv1 = tf.layers.conv2d(x, 32, [5, 5], strides=[2, 2], padding='same')
lrelu1 = tf.maximum(0.2 * conv1, conv1) #leaky relu
dropout1 = tf.layers.dropout(lrelu1, dropout_rate)
# layer2
conv2 = tf.layers.conv2d(dropout1, 64, [3, 3],
strides=[2, 2],
padding='same')
batch_norm2 = tf.layers.batch_normalization(conv2, training=is_training)
lrelu2 = tf.maximum(0.2 * batch_norm2, batch_norm2)
# layer3
conv3 = tf.layers.conv2d(lrelu2, 128, [2, 2],
strides=[2, 2],
padding='same')
batch_norm3 = tf.layers.batch_normalization(conv3, training=is_training)
lrelu3 = tf.maximum(0.2 * batch_norm3, batch_norm3)
dropout3 = tf.layers.dropout(lrelu3, dropout_rate)
# layer 4
conv4 = tf.layers.conv2d(dropout3, 128, [2, 2],
strides=[2, 2],
padding='same')
# do not use batch_normalization on this layer - next layer, "flatten5",
# will be used for "Feature Matching"
lrelu4 = tf.maximum(0.2 * conv4, conv4)
# layer 5
flatten_length = lrelu4.get_shape().as_list()[1] * \
lrelu4.get_shape().as_list()[2] * lrelu4.get_shape().as_list()[3]
flatten5 = tf.reshape(lrelu4, (-1, flatten_length)) # used for "Feature Matching"
fc5 = tf.layers.dense(flatten5, (num_classes + 1))
output = tf.nn.softmax(fc5)
assert output.get_shape()[1:] == [num_classes+1]
if print_summary:
print('Discriminator summary:\n x: %s\n' \
' D1: %s\n D2: %s\n D3: %s\n D4: %s\n' % (x.get_shape(),
dropout1.get_shape(),
lrelu2.get_shape(),
dropout3.get_shape(),
lrelu4.get_shape()))
return flatten5, fc5, output
# 定义生成器模型
def G(z, is_training, reuse = False, print_summary = False):
# generator (z -> x)
with tf.variable_scope('Generator', reuse = reuse) as scope:
# layer 0
z_reshaped = tf.reshape(z, [-1, 1, 1, latent_size])
# layer 1
deconv1 = tf.layers.conv2d_transpose(z_reshaped,
filters = latent_size,
kernel_size = [2, 2],
strides = [1, 1],
padding = 'valid')
batch_norm1 = tf.layers.batch_normalization(deconv1, training = is_training)
relu1 = tf.nn.relu(batch_norm1)
# layer 2
deconv2 = tf.layers.conv2d_transpose(relu1,
filters = 64,
kernel_size = [3, 3],
strides = [2, 2],
padding = 'valid')
batch_norm2 = tf.layers.batch_normalization(deconv2, training = is_training)
relu2 = tf.nn.relu(batch_norm2)
# layer 3
deconv3 = tf.layers.conv2d_transpose(relu2,
filters = 32,
kernel_size = [4, 4],
strides = [2, 2],
padding = 'valid')
batch_norm3 = tf.layers.batch_normalization(deconv3, training = is_training)
relu3 = tf.nn.relu(batch_norm3)
# layer 4 - do not use Batch Normalization on the last layer of Generator
deconv4 = tf.layers.conv2d_transpose(relu3,
filters = num_channels,
kernel_size = [6, 6],
strides = [2, 2],
padding = 'valid')
tanh4 = tf.tanh(deconv4)
assert tanh4.get_shape()[1:] == [x_height, x_width, num_channels]
if print_summary:
print('Generator summary:\n z: %s\n' \
' G0: %s\n G1: %s\n G2: %s\n G3: %s\n G4: %s\n' %(z.get_shape(),
z_reshaped.get_shape(),
relu1.get_shape(),
relu2.get_shape(),
relu3.get_shape(),
tanh4.get_shape()))
return tanh4
# 定义SSGAN模型
def build_model(x_real, z, label, dropout_rate, is_training, print_summary = False):
# build model
D_real_features, D_real_logit, D_real_prob = D(x_real, dropout_rate, is_training,
reuse = False, print_summary = print_summary)
x_fake = G(z, is_training, reuse = False, print_summary = print_summary)
D_fake_features, D_fake_logit, D_fake_prob = D(x_fake, dropout_rate, is_training,
reuse = True, print_summary = print_summary)
return D_real_features, D_real_logit, D_real_prob, D_fake_features, D_fake_logit, D_fake_prob, x_fake
# 为假数据(D生成的)准备标签全0
def prepare_labels(label):
extended_label = tf.concat([label, tf.zeros([tf.shape(label)[0], 1])], axis=1)
return extended_label
# 按照论文计算损失函数和准确率
def loss_accuracy(D_real_features, D_real_logit, D_real_prob, D_fake_features,
D_fake_logit, D_fake_prob, extended_label, labeled_mask):
# 避免损失函数变为nan
epsilon = 1e-8 # used to avoid NAN loss
# *** 鉴别器Loss***
# 监督学习Loss
# 二元交叉熵损失函数D_L_supervised,这是针对前K类而言的
tmp = tf.nn.softmax_cross_entropy_with_logits(logits = D_real_logit,
labels = extended_label)
D_L_supervised = tf.reduce_sum(labeled_mask * tmp) / tf.reduce_sum(labeled_mask)
# 无监督学习Loss
# 真实数据为真的概率
prob_real_be_real = 1 - D_real_prob[:, -1] + epsilon
tmp_log = tf.log(prob_real_be_real)
D_L_unsupervised1 = -1 * tf.reduce_mean(tmp_log)
# 假数据为假的概率
prob_fake_be_fake = D_fake_prob[:, -1] + epsilon
tmp_log = tf.log(prob_fake_be_fake)
D_L_unsupervised2 = -1 * tf.reduce_mean(tmp_log)
# 鉴别器损失函数
D_L = D_L_supervised + D_L_unsupervised1 + D_L_unsupervised2
# ***生成器Loss***
# 假的看成真的概率
prob_fake_be_real = 1 - D_fake_prob[:, -1] + epsilon
tmp_log = tf.log(prob_fake_be_real)
G_L1 = -1 * tf.reduce_mean(tmp_log)
# 特征的匹配损失函数,相当于Encode-Decoder网络中的特征向量的差距损失
tmp1 = tf.reduce_mean(D_real_features, axis = 0)
tmp2 = tf.reduce_mean(D_fake_features, axis = 0)
G_L2 = tf.reduce_mean(tf.square(tmp1 - tmp2))
# 生成器的损失
G_L = G_L1 + G_L2
# 计算准确率
correct_prediction = tf.equal(tf.argmax(D_real_prob[:, :-1], 1),
tf.argmax(extended_label[:, :-1], 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 返回上面的值
return D_L_supervised, D_L_unsupervised1, D_L_unsupervised2, D_L, G_L, accuracy
# 定义优化器
def optimizer(D_Loss, G_Loss, D_learning_rate, G_learning_rate):
# D and G optimizer
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
all_vars = tf.trainable_variables()
D_vars = [var for var in all_vars if var.name.startswith('Discriminator')]
G_vars = [var for var in all_vars if var.name.startswith('Generator')]
D_optimizer = tf.train.AdamOptimizer(D_learning_rate).minimize(D_Loss, var_list = D_vars)
G_optimizer = tf.train.AdamOptimizer(G_learning_rate).minimize(G_Loss, var_list = G_vars)
return D_optimizer, G_optimizer
# 可视化生成器产生的数据
def plot_fake_data(data, grid_size = [5, 5]):
# visualize some data generated by G
_, axes = plt.subplots(figsize = grid_size, nrows = grid_size[0], ncols = grid_size[1],
sharey = True, sharex = True)
size = grid_size[0] * grid_size[1]
index = np.int_(np.random.uniform(0, data.shape[0], size = (size)))
figs = data[index].reshape(-1, x_height, x_width)
for idx, ax in enumerate(axes.flatten()):
ax.axis('off')
ax.imshow(figs[idx], cmap = 'gray')
plt.tight_layout()
plt.show()
# 保存模型
def save_model_on_imporvemnet(file_path, sess, cv_acc, cv_accs):
# # save model when there is improvemnet in cv_acc value
if cv_accs == [] or cv_acc > np.max(cv_accs):
saver = tf.train.Saver(max_to_keep = 1)
saver.save(sess, file_path)
print('Model saved')
print('')
# 生成label_mask, 只有占比前labeled_rate可以作为真实样本输入到网络
def get_labled_mask(labeled_rate, batch_size):
# get labeled mask to mask some data unlabeled
labeled_mask = np.zeros([batch_size], dtype = np.float32)
labeled_count = np.int(batch_size * labeled_rate)
labeled_mask[range(labeled_count)] = 1.0
#np.random.shuffle(labeled_mask)
return labeled_mask
# 'a' 代表给文件追加信息
def log_loss_acc(file_path, epoch, train_loss_D, train_loss_G, train_Acc,
cv_loss_D, cv_loss_G, cv_Acc, log_mode = 'a'):
# log train and cv losses as well as accuracy
mode = log_mode if epoch == 0 else 'a'
with open(file_path, mode) as f:
if mode == 'w':
header = 'epoch, train_loss_D, train_loss_G,' \
'train_Acc, cv_loss_D, cv_loss_G, cv_Acc\n'
f.write(header)
line = '%d, %f, %f, %f, %f, %f, %f\n' %(epoch, train_loss_D, train_loss_G, train_Acc, cv_loss_D, cv_loss_G, cv_Acc)
f.write(line)
# 训练SGAN
def train_SS_GAN(batch_size, epochs):
# train Semi-Supervised Learning GAN
train_D_losses, train_G_losses, train_Accs = [], [], []
cv_D_losses, cv_G_losses, cv_Accs = [], [], []
# 重置default graph
tf.reset_default_graph()
# 输入数据占位
x = tf.placeholder(tf.float32, name = 'x', shape = [None, x_height, x_width, num_channels])
# 标签占位符
label = tf.placeholder(tf.float32, name = 'label', shape = [None, num_classes])
# label_mask占位
labeled_mask = tf.placeholder(tf.float32, name = 'labeled_mask', shape = [None])
# 图像编码隐空间长度
z = tf.placeholder(tf.float32, name = 'z', shape = [None, latent_size])
# dropout的概率
dropout_rate = tf.placeholder(tf.float32, name = 'dropout_rate')
# 控制是否训练的参数
is_training = tf.placeholder(tf.bool, name = 'is_training')
# 生成器的学习率
G_learning_rate = tf.placeholder(tf.float32, name = 'G_learning_rate')
# 判别器的学习率
D_learning_rate = tf.placeholder(tf.float32, name = 'D_learning_rate')
# 创建SSGAN模型
model = build_model(x, z, label, dropout_rate, is_training, print_summary = True)
D_real_features, D_real_logit, D_real_prob, D_fake_features, D_fake_logit, D_fake_prob, fake_data = model
# 输入的标签都为真,所以表示为[i, 0],i代表第i(0-9)类,0用prepare_label拼接上去
extended_label = prepare_labels(label)
# 计算损失函数和准确率并复制
loss_acc = loss_accuracy(D_real_features, D_real_logit, D_real_prob,
D_fake_features, D_fake_logit, D_fake_prob,
extended_label, labeled_mask)
_, _, _, D_L, G_L, accuracy = loss_acc
# 定义生成器和鉴别器的优化器
D_optimizer, G_optimizer = optimizer(D_L, G_L, G_learning_rate, D_learning_rate)
print('training....')
with tf.Session() as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
# 获得数据
mnist_set = get_data()
# epochs次循环
for epoch in range(epochs):
t_total = 0
# 一个epoch需要这么多轮,根据batch_size计算
for iter in range(int(mnist_set.train.images.shape[0] / batch_size) + 1):
# 记录时间
t_start = time.time()
# 获得训练数据的一个batch的数据,这里将shuffle设为false,代表从数据集中依次取batch张图片
batch = mnist_set.train.next_batch(batch_size, shuffle = False)
# 申请一个shape为[batch_size, latent_size]的隐变量z
batch_z = np.random.uniform(-1.0, 1.0, size = (batch_size, latent_size))
# 生成labeled_mask
mask = get_labled_mask(labeled_rate, batch_size)
# 训练参数
train_feed_dictionary = {x: normalize(batch[0]),
z: batch_z,
label: batch[1],
labeled_mask: mask,
dropout_rate: 0.5,
G_learning_rate: 1e-5,
D_learning_rate: 1e-5,
is_training: True}
# 开始训练
D_optimizer.run(feed_dict = train_feed_dictionary)
G_optimizer.run(feed_dict = train_feed_dictionary)
# 获取D_loss, G_loss, Acc
train_D_loss = D_L.eval(feed_dict = train_feed_dictionary)
train_G_loss = G_L.eval(feed_dict = train_feed_dictionary)
train_accuracy = accuracy.eval(feed_dict = train_feed_dictionary)
t_total += (time.time() - t_start)
print('epoch: %d, time: %f | train_G_Loss: %f, ' \
'train_D_loss: %f, train_acc: %f' %(epoch, t_total,
train_G_loss, train_D_loss,
train_accuracy), end = '\r')
# 将每个epoch的train_D_loss, train_G_loss, train_accuracy加入到列表中
train_D_losses.append(train_D_loss)
train_G_losses.append(train_G_loss)
train_Accs.append(train_accuracy)
# 交叉验证
# 交叉验证数据
cv_size = mnist_set.test.labels.shape[0]
# 交叉验证噪声向量cv_batch_z
cv_batch_z = np.random.uniform(-1.0, 1.0, size = (cv_size, latent_size))
# 同样生成交叉验证数据的labeled_mask
mask = get_labled_mask(1, cv_size)
cv_feed_dictionary = {x: normalize(mnist_set.test.images),
z: cv_batch_z,
label: mnist_set.test.labels,
labeled_mask: mask,
dropout_rate: 0.0,
is_training: False}
# 获取交叉验证集合的D_loss, G_loss, Acc
cv_D_loss = D_L.eval(feed_dict = cv_feed_dictionary)
cv_G_loss = G_L.eval(feed_dict = cv_feed_dictionary)
cv_accuracy = accuracy.eval(feed_dict = cv_feed_dictionary)
#
log_loss_acc(log_path, epoch, train_D_loss, train_G_loss, train_accuracy,
cv_D_loss, cv_G_loss, cv_accuracy, log_mode = 'w')
print('\ncv_G_Loss: %f, cv_D_loss: %f, cv_acc: %f' %(cv_G_loss,
cv_D_loss,
cv_accuracy))
save_model_on_imporvemnet(model_path, sess, cv_accuracy, cv_Accs)
cv_D_losses.append(cv_D_loss)
cv_G_losses.append(cv_G_loss)
cv_Accs.append(cv_accuracy)
if epoch % 10 == 0:
fakes = fake_data.eval(feed_dict = cv_feed_dictionary)
plot_fake_data(fakes, [5, 5])
return train_D_losses, train_G_losses, train_Accs, cv_D_losses, cv_G_losses, cv_Accs
loss_acc = train_SS_GAN(512, 1001)


 京公网安备 11010502036488号
京公网安备 11010502036488号