

一,翻译
参考翻译文献:https://baijiahao.baidu.com/s?id=1566004753349359&wfr=spider&for=pc
文中不懂的知识现在用:粗体标注了
摘要
我们为移动和嵌入式视觉应用提供了一类名为MobileNets的高效模型。 MobileNets基于流线型架构,使用深度可分离卷积来构建轻量级深度神经网络。 我们介绍了两个简单的全局超参数,可以在时间和准确性之间进行有效折中。 这些超参数允许模型构建者根据问题的约束为其应用程序选择合适大小的模型。 我们在资源和精度折中方面提出了大量实验,并且与ImageNet分类上的其他流行模型相比显示出强大的性能。 然后,我们演示MobileNets在广泛的应用和用例(包括对象检测,精细分类,人脸属性提取和大规模地理定位)中的有效性。
1.Introduction(介绍)
自从AlexNet赢得ImageNet挑战赛(ILSVRC2012)推广深度卷积神经网络以后,卷积神经网络在计算机视觉领域变得普遍存在。总得趋势是使用更深层更复杂的网络来实现更高的准确度。然而,这些提高准确率的进步并不一定会使网络在尺寸和速度方面更有效率。在许多现实世界的应用中,例如机器人,自动驾驶汽车和AR技术,识别任务需要及时地在有限计算资源的平台上进行。本文介绍了一种高效的网络结构和两个超参数,以便构建非常小的,快速度的模型,可以轻松匹配移动和嵌入式视觉应用的设计要求。第二节回顾了之前在构建小模型的工作。第三节描述了MobileNets架构和两个超参数(widthmultiplier和resolutionmultiplier),以便定义更小更高效的MobileNets。第四节介绍了ImageNet上的实验以及各种不同的应用和用例。第五节以汇总和结论来结束论文。
2. Prior Work(先验工作)
在最近的文献中,关于建立小型高效的神经网络的兴趣日益增加。一般来说,这些不同的方法可以归为两类,压缩训练好的模型和直接训练小网络模型。本文提出了一类网络结构,允许模型开发人员选择与其应用程序的资源限制(延迟,大小)相匹配的小型网络。MobileNets主要侧重于优化延迟,但也能够产生小型网络。很多关于小型网络的论文只关注大小,却不考虑速度。
MobileNets主要由深度可分离卷积构建(最初在一篇论文有提及,随后用于Inception模型以减少前面几层的运算)。扁平化的网络通过完全分解的卷积建立,并显示出极大的因式分解网络的潜力。独立于本文的FactorizedNetworks论文,引入了类似于因式分解卷积以及拓扑连接的使用。随后,Xception网络展示了如何将深度可分离的过滤器扩展到比InceptionV3网络还优秀。另一个小型网络是SqueezeNet,它采用瓶颈方法来设计一个非常小的网络。其他减少计算量的网络包括structured transform networks和deep fried convnets。
获取小型网络的另一个办法是缩小,分解或者压缩训练好的模型。文献中基于压缩的方法有product quantization,哈希法与pruning,vector quantization和霍夫曼编码压缩。此外,各种各样的因式分解方法被提出来用于加速训练好的网络。训练小型网络的另一种方法是distillation(蒸馏法),使用更大的网络来教授小一点的网络。它在我们方法的补充,并在第四节的一些使用案例中有所涉及。另一种新兴的方法是low bit networks。

图1:MobileNet模型可以应用于各种识别任务,以实现设备智能化。
3.MobileNet Architecture 结构
在本节中,我们首先描述MobileNet构建的核心层,它们是深度可分离的过滤器。然后我们介绍MobileNet网络结构,并以两个模型缩小参数(widthmultiplier和resolutionmultiplier)作为总结。
3.1 Deep-wise Separabe 深度可分离卷积
MobileNet模型是基于深度可分离卷积,它是factorized convolutions的一种,而factorized convolutions将标准化卷积分解为深度卷积和1x1卷积(pointwise convolution)。对于MobileNets,深度卷积将单个滤波器应用到每一个输入通道。然后,pointwise convolution用1x1卷积来组合不同深度卷积的输出。在一个步骤,一个标准的卷积过程将输入滤波和组合成一组新的输出。深度可分离卷积将其分成两层,一层用于滤波,一层用于组合。这种分解过程能极大减少计算量和模型大小。图2展示了如何将一个标准卷积分解为深度卷积和1x1的pointwise convolution。
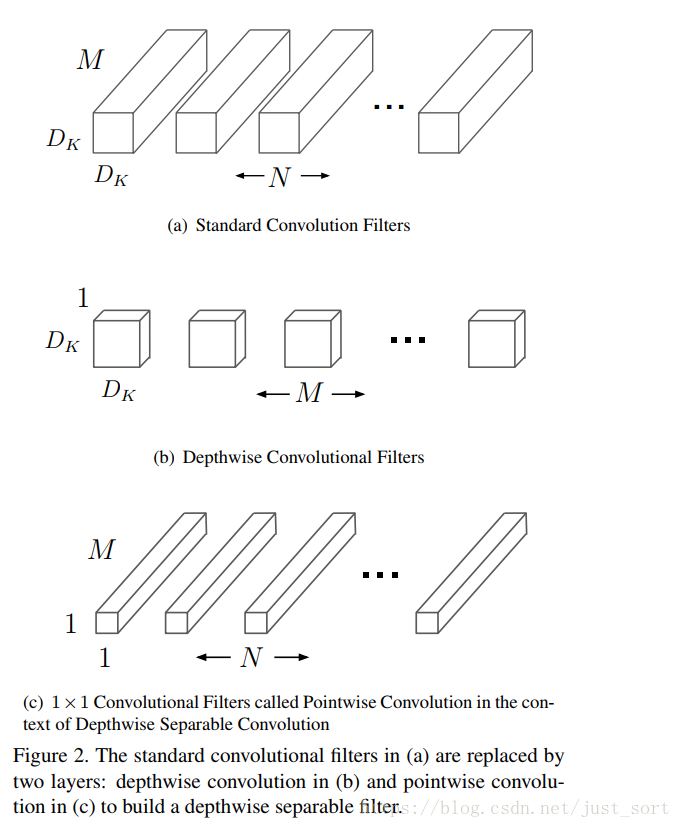
图2:标准卷积的分解过程。
传统的3D卷积使用一个和输入数据通道数相同的卷积核在逐个通道卷积后求和最后得出一个数值作为结果,计算量为
其中M为输入的通道数, 为卷积核的宽和高
一个卷积核处理输入数据时的计算量为(有Padding):
其中DF为输入的宽和高
在某一层如果使用N个卷积核,这一个卷积层的计算量为:
如果使用deep-wise方式的卷积核,我们会首先使用一组二维的卷积核,也就是卷积核的通道数为1,每次只处理一个输入通道的,这一组二维卷积核的数量是和输入通道数相同的。在逐个使用通道卷积处理之后,再使用3D的1*1卷积核来处理之前输出的特征图,将最终输出通道数变为一个指定的数量。
从理论上来看,一组和输入通道数相同的2D卷积核的运算量为:
3D的1*1卷积核的运算为:
因此这种组合方式的计算量为:
deep-wise方式的卷积相比于传统3D卷积计算量为:

一个标准的卷积层输入维度为DFxDFxM的特征图谱F,产生DFxDFxN的特征图谱G,其中DF是正方形输入特征图谱的空间宽和高,M是输入通道数(inputdepth),D是正方形输出特征图谱的空间宽和高,N是输出通道的数量(outputdepth)。
标准的卷积层是由卷积核K(尺寸是 )参数化的,其中 是假设正方形核的空间空间维度,M是输入通道数量,N是输出通道数量。如果假设卷积步幅是1并考虑padding,那么标准化卷积操作的输出特征图谱为:
而该操作的计算复杂度则是DK*DK*M*N*DF*DF,可见该计算复杂度依赖于输入通道M,输出通道N,卷积核心尺寸DkxDk和特征图谱尺寸DfxDf。MobileNet模型就是用来面对这些属于术语及其相互关系的。首先,它使用深度可分离的卷积来破坏输出通道的数量的数量和内核大小的相互作用。
标准的卷积运算,具有基于卷积内核的滤波特征和组合特征,从而产生新的特征。滤波和组合步骤可以通过使用factorized convolutions(深度可分离卷积)分为两个步骤,以显著降低计算成本。
深度可分离卷积由两层构成:depthwise convolutions和pointwise convolutions。我们使用depthwise convolution对每个输入通道(输入的深度)执行单个滤波器。Pointwise convolution(1x1卷积)用来创建depthwise层的线性叠加。MobileNets对两层卷积层都使用了BatchNormalization和ReLU非线性激活。
Depthwise convolution可以被写作以下形式(每个输入通道一个滤波器):

K^指的是depthwise convolution的卷积核,大小是DKxDKxM。K^中的第m个特征作用于F的第m个特征,从而产生输出特征的第m个通道。Depthwise convolution的计算复杂度为:Dk*Dk*M*DF*DF+M*N*DF*DF,就是两层卷积层操作的和。通过将卷积表示为滤波和组合两个过程,可以减少计算量:
=
在第四节中,MobileNets使用3x3的深度可分离卷积比标准的卷积减少了8-9倍的计算复杂度,准确率只减少了一点点。空间维度的因式分解不会节省大量的计算复杂度,因为depthwise convolutions的计算复杂度本来就很小。
3.2 Network Structure and Training (网络结构和训练)
如前面部分所述的那样,MobileNet结构是由深度可分离卷积建立的,其中第一层是全卷积。通过以简单的方式定义网络,我们可以轻松地探索网络拓扑,以找到一个良好的网络。MobileNet的结构定义在表1中。所有层之后都是BatchNormalization和ReLU非线性激活函数,但是最后的全连接层例外,它没有非线性激活函数,直接馈送到softmax层进行分类。图三比较了常规卷积和深度可分离卷积(都跟着BN层和ReLU层)。在depthwise convolution和第一层卷积层中都能处理下采样问题。最后一个平均池化层在全连接层之前,将特征图谱的维度降维1x1。将depthwise convolution和pointwise convolution算为不同的层地话,MobileNet有28层。

图3:左图是标准卷积,右图是深度可分离卷积
仅仅通过少量的Mult-Adds简单地定义网络是不够的。确保这些操作能有效实现也很重要。例如,非结构化的稀疏矩阵操作通常不比密集矩阵运算快,除非是非常稀疏的矩阵。我们的模型结构将几乎全部的计算复杂度放到了1x1卷积中。这可以通过高度优化的通用矩阵乘法(GEMM)功能来实现。通常卷积由GEMM实现,但需要在称为im2col的内存中进行初始重新排序,以将其映射到GEMM。这个方法在流行的Caffe包中正在使用。1x1的卷积不需要在内存中重新排序而可以直接被GEMM(最优化的数值线性代数算法之一)实现。MobileNet在1x1卷积花费了95%计算复杂度,也拥有75%的参数(见表二)。几乎所有的额外参数都在全连接层。
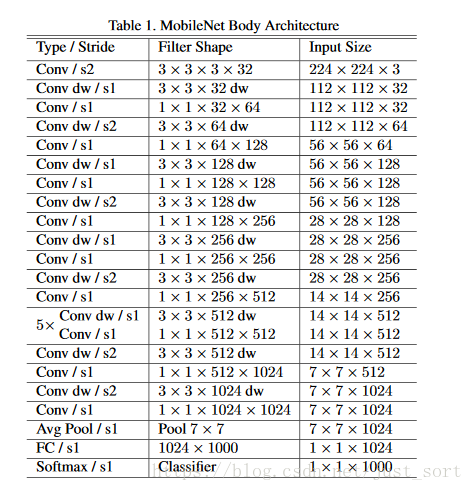
表1:MobileNet的结构
使用类似于InceptionV3的异步梯度下降的RMSprop,MobileNet模型在TensorFlow中进行训练。然而,与训练大模型相反,我们较少地使用正则化和数据增加技术,因为小模型不容易过拟合。当训练MobileNets时,我们不使用sideheads或者labelsmoothing,通过限制croping的尺寸来减少图片扭曲。另外,我们发现重要的是在depthwise滤波器上放置很少或没有重量衰减(L2正则化),因为它们参数很少。在下一节ImageNet的benchmark中,所有的模型通过同样的参数进行训练,但不考虑模型的大小。
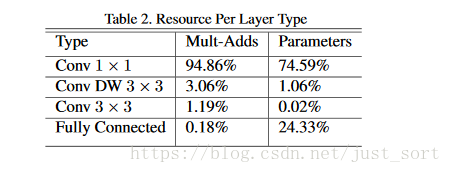
表2:每种层的分布
3.3. Width Multiplier: Thinner Models(alpha参数:更小的模型)
尽管基本MobileNet架构已经很小延迟很低,但特定用例或应用程序需要更小更快的模型。为了构建这些较小且计算量较少的模型,我们引入了一个非常简单的参数α,称为width multiplier。这个参数widthmultiplier的作用是在每层均匀地减负网络。对于一个给定的层和widthmultiplierα,输入通道的数量从M变成αM,输出通道的数量从N变成αN。深度可分离卷积(以widthmultiplier参数α为计)的计算复杂度:
α∈(0,1],通常设为1,0.75,0.5和0.25。α=1表示基准MobileNet,而α<1则表示瘦身的MobileNets。Width multiplier有减少计算复杂度和参数数量(大概α二次方)的作用。Width multiplier可以应用于任何模型结构,以定义一个具有合理准确性,延迟和尺寸的新的较小的模型。它用于定义新的简化结构,但需要重新进行训练。
3.4. Resolution Multiplier: Reduced Representation
降低神经网络的第二个超参数是resolution multiplier ρ。我们将其应用于输入图像,并且每个层的内部特征随后被减去相同的乘数。实际上,我们通过设置输入分辨率隐式设置ρ。我们现在可以将网络核心层的计算复杂度表示为具有width multiplier α和resolution multiplier ρ的深度可分离卷积:ρ∈(0,1],通常设为224,192,160或者128。ρ=1是基本MobileNets而ρ<1示瘦身的MobileNets。Resolutionmultiplier可以减少计算复杂度ρ的平方。作为一个例子,我们可以看一下MobileNet中的一个典型的卷积层,看看深度可分离卷积,width multiplier和resolution multiplier如何降低计算复杂度和参数。表3显示了不同的架构收缩方法应用于该层,而表示的计算复杂度和参数数量。第一行显示了Multi-Adds和参数,其中Multi-Adds具有14x14x512的输入特征图,内核K的大小为3x3x512x512。我们将在下一节中详细介绍模型资源和准确率的折中。

4. Experiments(实验)
在本节中,我们首先研究depthwise convolutions和收缩网络的影响,收缩网络时我们选择减小网络宽度而不是减少层数。然后,我们展示基于两个超参数而瘦身网络的相关结果:width multiplier和resolution multiplier,然后和一系列流行模型对比。接着我们将MobileNets应用于各种不同的应用
4.1ModelChoices
首先,我们展示了具有深度可分离卷积的MobileNet与使用完整卷积构建的模型相比较的结果。在表4中,我们看到,与完全卷积相比,使用深度可分离的卷积在ImageNet上只会将精度降低1%,但在mult-adds和参数方面节省了巨大的成本。
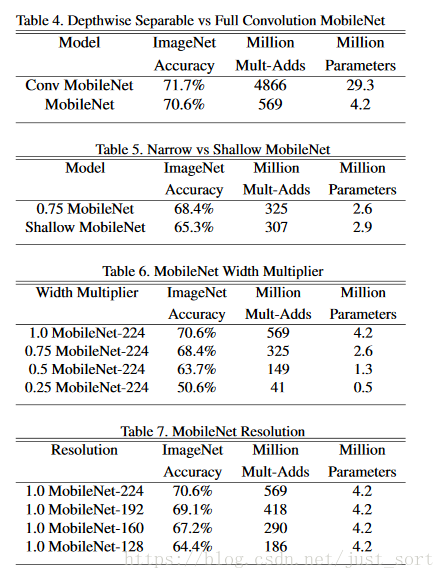
接下来,我们展示比较瘦身模型(widthmultiplier)到更浅模型(更少的层)的结果。为了使MobileNet更浅,在表一中的可分离滤波器(尺寸为14x14x512)被删除了。表5显示,在类似的计算复杂度和参数数量时,瘦身的MobileNets会比更浅的MobileNets好3%左右。
表6展示了利用widthmultiplierα做瘦身MobileNet架构的相关准确率,计算复杂度和参数的结果。准确率一直下降,直到α=0.25。
表7通过减少输入图片的分辨率来训练MobileNets,展示相关准确率,计算复杂度和模型尺寸的结果。随着分辨率减少,准确率也降低。
图4展示了在ImageNet图集上,16个模型准确率(widthmultiplierα∈{1,0.75,0.5,0.25},分辨率{224,192,160,128})和计算复杂度的折中关系。结果近似于log关系,在α=0.25有一个显著降低。
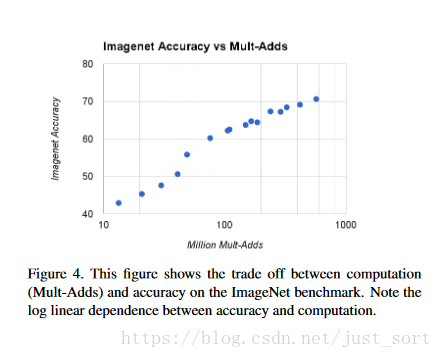
图4:计算量和准确率的关系
图5展示了在ImageNet图集上,16个模型(widthmultiplierα∈{1,0.75,0.5,0.25},分辨率{224,192,160,128})准确率和参数数量的关系。不同颜色代表不同的分辨率。参数数量不会因输入分辨率不同而不同。

表8比较了完全MobileNet和原始的GoogleNet以及VGG16。MobileNet和VGG16准确率相近,但模型大小小了32倍,计算复杂度也小了27倍。它比GoogleNet更加精确,然而模型大小更小,计算复杂度也少了2.5倍。
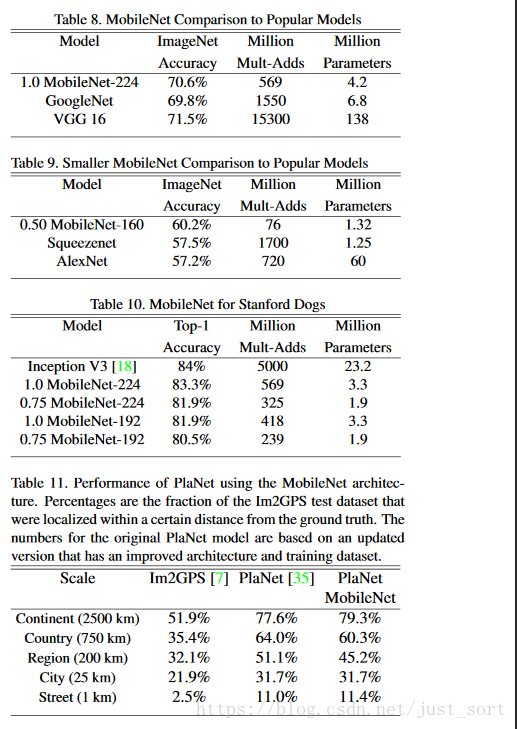
表9比较了瘦身(widthmultiplier α=0.5,分辨率160×160)的MobileNet。瘦身的MobileNet准确率比AlexNet好大约4%,但模型大小小了45倍,计算复杂度也小了9.4倍。在模型尺寸差不多的情况下,它比Squeezenet有更高的准确率,而计算复杂度降低了22倍。
4.3. Fine Grained Recognition(精细分类)
我们在StanfordDogs数据集上训练细粒度识别的MobileNet模型。我们扩展了【18】的方法,并从网络收集比【18】更大但更嘈杂的训练集。我们使用嘈杂的网络数据预先训练一个细粒度的狗识别模型,然后在StanfordDog训练集上对模型进行微调。StanfordDogs测试集结果见表10。MobileNet几乎可以实现最先进的结果【18】,并大大减少了计算量和大小。
4.4. Large Scale Geolocalizaton(大规模地理定位)
PlaNet将如何确定在哪里拍照作为分类问题。该方法将地球划分为一个用作目标类的地理单元格,并在数百万个地理标记的照片上训练卷积神经网络。PlaNet已被证明可以成功确认各种照片的地点,并优于处理相同任务的Im2GPS。我们使用MobileNet架构在相同的数据集上重新训练PlaNet。整个基于InceptionV3架构的PlaNet模型有5200万参数和57.4亿多mult-adds。而MobileNet模型只有1300万参数(3百万用在主架构,1000万用在最后一层)和5.8亿mult-adds。如表11所示,MobileNet版本与PlaNet相比,性能略有降低,但更加小。此外,它仍然大幅度优于Im2GPS。
4.5. Face Attributes(人脸属性分类)
MobileNet的另一个用例是压缩具有未知或深奥的训练过程的大型系统。在面部属性分类任务中,我们展示了MobileNet与distillation的关系,这是深度网络的迁移学习的知识。我们寻求减少7500万个参数和1600万次Mult-Adds的大属性分类器。分类器对类似于YFFC100M的多属性训练集进行了训练。我们使用MobileNet架构提取一个面部属性分类器。Distillation通过仿真大模型的输出(而不是实际标签)来训练分类器,从而可以用大量(可能是无限的)未标记的数据进行训练。综合distillation训练的可扩展性和MobileNet的简约参数化,终端系统不仅不需要正规化(权值降低和早期停止),而且还表现出加强性能。从表12显而易见的是,基于MobileNet的分类器具有强烈弹性的模型收缩性:它在不同的属性达到了近似的平均精度(meanAP)却只有1%的计算量。
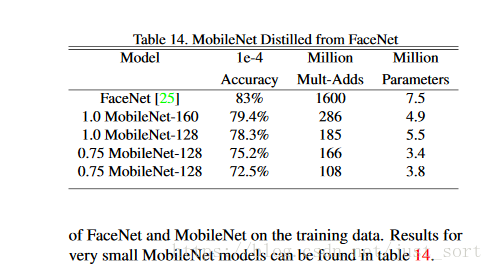
表12:用MobileNet进行人脸属性分类
4.6. Object Detection (目标检测)
MobileNet也可以作为有效地基础网络部署在现代物体检测系统中。根据最近获得2016COCO冠军的工作,我们报告了针对COCO数据集进行目标检测的MobileNet训练结果。在表13中,使用相同Faster-RCNN和SSD框架,MobileNet和VGG与InceptionV2进行了比较。在我们的实验中,SSD使用了300的输入分辨率(SSD300),而Faster-RCNN使用了600和300的分辨率(Faster-RCNN300,Faster-RCNN600)。这个Faster-RCNN模型每张图考虑300PRN建议框。模型通过COCO训练集和测试集训练(排除8000张minival图),然后再minival集中测试。对于这两个框架,MobileNet可以实现与其他网络的相似结果,但计算复杂度和模型大小差很多。

图6:使用MobileNetSSD进行目标检测的例子
4.7. Face Embeddings(人脸识别)
FaceNet模型时最先进的面部识别模型。它基于tripletloss构建人脸特征。为了构建一个移动端的FaceNet模型,我们使用distillation方法去训练模型,训练时尽量最小化FaceNet和MobileNet在训练集上的输出平方差。小MobileNet模型的结果可以在表14中找到。
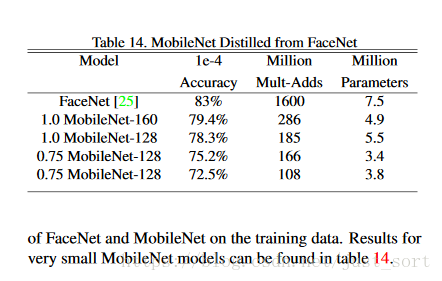
表14:FaceNet中提取MobileNet
5 结论
我们提出了一种基于深度可分离卷积的新型模型架构,称为MobileNets。我们讨论了一些可以得到高效模型的重要设计决策。然后,我们演示了如何通过使用widthmultiplier和resolutionmultiplier来构建更小更快的MobileNets,以减少合理的精度来减少模型尺寸和延迟。然后,我们将不同的MobileNets与流行的模型进行比较,展示了尺寸,速度和精度。我们最终通过展示MobileNet在应用于各种任务时的有效性来得出结论。作为帮助采用和探索MobileNets的下一步,我们计划在TensorFlow中发布模型。
二,总结
用mobilenet实现对mnist数据集进行训练, 代码如下:
import tensorflow as tf
from tensorflow.python.training import moving_averages
UPDATE_OPS_COLLECTION = "_update_ops_"
# create variable
def create_variable(name, shape, initializer, dtype=tf.float32, trainable=True):
return tf.get_variable(name, shape=shape, dtype=dtype,
initializer=initializer, trainable=trainable)
""" 公式如下: y=γ(x-μ)/σ+β 其中x是输入,y是输出,μ是均值,σ是方差,γ和β是缩放(scale)、偏移(offset)系数。 一般来讲,这些参数都是基于channel来做的,比如输入x是一个16*32*32*128(NWHC格式)的feature map, 那么上述参数都是128维的向量。其中γ和β是可有可无的,有的话,就是一个可以学习的参数(参与前向后向), 没有的话,就简化成y=(x-μ)/σ。而μ和σ,在训练的时候,使用的是batch内的统计值,测试/预测的时候,采用的是训练时计算出的滑动平均值。 """
# batchnorm layer
def bacthnorm(inputs, scope, epsilon=1e-05, momentum=0.99, is_training=True):
inputs_shape = inputs.get_shape().as_list()#inputs代表输入,scope代表命名
params_shape = inputs_shape[-1:]#得到numpy数组的维度,例如[3,4]
axis = list(range(len(inputs_shape) - 1))#得到最后一个维度[4]
with tf.variable_scope(scope):
beta = create_variable("beta", params_shape,
initializer=tf.zeros_initializer())
gamma = create_variable("gamma", params_shape,
initializer=tf.ones_initializer())
# for inference
moving_mean = create_variable("moving_mean", params_shape,
initializer=tf.zeros_initializer(), trainable=False)
moving_variance = create_variable("moving_variance", params_shape,
initializer=tf.ones_initializer(), trainable=False)
if is_training:
mean, variance = tf.nn.moments(inputs, axes=axis)
update_move_mean = moving_averages.assign_moving_average(moving_mean,
mean, decay=momentum)
update_move_variance = moving_averages.assign_moving_average(moving_variance,
variance, decay=momentum)
else:
mean, variance = moving_mean, moving_variance
return tf.nn.batch_normalization(inputs, mean, variance, beta, gamma, epsilon)#低级的操作函数,调用者需要自己处理张量的平均值和方差。
# depthwise conv2d layer
def depthwise_conv2d(inputs, scope, filter_size=3, channel_multiplier=1, strides=1):
inputs_shape = inputs.get_shape().as_list()
in_channels = inputs_shape[-1]
with tf.variable_scope(scope):
filter = create_variable("filter", shape=[filter_size, filter_size,
in_channels, channel_multiplier],
initializer=tf.truncated_normal_initializer(stddev=0.01))
return tf.nn.depthwise_conv2d(inputs, filter, strides=[1, strides, strides, 1],
padding="SAME", rate=[1, 1])
# conv2d layer
def conv2d(inputs, scope, num_filters, filter_size=1, strides=1):
inputs_shape = inputs.get_shape().as_list()
in_channels = inputs_shape[-1]
with tf.variable_scope(scope):
filter = create_variable("filter", shape=[filter_size, filter_size,
in_channels, num_filters],
initializer=tf.truncated_normal_initializer(stddev=0.01))
return tf.nn.conv2d(inputs, filter, strides=[1, strides, strides, 1],
padding="SAME")
# avg pool layer
def avg_pool(inputs, pool_size, scope):
with tf.variable_scope(scope):
return tf.nn.avg_pool(inputs, [1, pool_size, pool_size, 1],
strides=[1, pool_size, pool_size, 1], padding="VALID")
# fully connected layer
def fc(inputs, n_out, scope, use_bias=True):
inputs_shape = inputs.get_shape().as_list()
n_in = inputs_shape[-1]
with tf.variable_scope(scope):
weight = create_variable("weight", shape=[n_in, n_out],
initializer=tf.random_normal_initializer(stddev=0.01))
if use_bias:
bias = create_variable("bias", shape=[n_out,],
initializer=tf.zeros_initializer())
return tf.nn.xw_plus_b(inputs, weight, bias)
return tf.matmul(inputs, weight)
class MobileNet(object):
def __init__(self, inputs, labels, num_classes=10, is_training=True, width_multiplier=0.5, scope="MobileNet", ):
self.inputs = inputs
self.num_classes = num_classes
self.is_training = is_training
self.width_multiplier = width_multiplier
# construct model
with tf.variable_scope(scope):
# conv1
net = conv2d(inputs, "conv_1", round(32 * width_multiplier), filter_size=1,
strides=2) # ->[N, 14, 14, 1]
net = tf.nn.relu(bacthnorm(net, "conv_1/bn", is_training=self.is_training))
net = self._depthwise_separable_conv2d(net, 64, self.width_multiplier,
"ds_conv_2") # ->[N, 14, 14, 64]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_3") # ->[N, 14, 14, 128]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_4") # ->[N, 14, 14, 128]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_5") # ->[N, 14, 14, 256]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_6") # ->[N, 14, 14, 256]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_7") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_8") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_9") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_10") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_11") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_12") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_13", downsample=True) # ->[N, 7, 7, 1024]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_14") # ->[N, 7, 7, 1024]
net = avg_pool(net, 7, "avg_pool_15")
net = tf.squeeze(net, [1, 2], name="SpatialSqueeze")
self.logits = fc(net, self.num_classes, "fc_16")
self.predictions = tf.nn.softmax(self.logits)
self.loss = -tf.reduce_mean(labels * tf.log(self.predictions))
def _depthwise_separable_conv2d(self, inputs, num_filters, width_multiplier, scope, downsample=False):
"""depthwise separable convolution 2D function"""
num_filters = round(num_filters * width_multiplier)
strides = 2 if downsample else 1
with tf.variable_scope(scope):
# depthwise conv2d
dw_conv = depthwise_conv2d(inputs, "depthwise_conv", strides=strides)
# batchnorm
bn = bacthnorm(dw_conv, "dw_bn", is_training=self.is_training)
# relu
relu = tf.nn.relu(bn)
# pointwise conv2d (1x1)
pw_conv = conv2d(relu, "pointwise_conv", num_filters)
# bn
bn = bacthnorm(pw_conv, "pw_bn", is_training=self.is_training)
return tf.nn.relu(bn)
if __name__ == "__main__":
# test data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder("float", [None, 784])
y_ = tf.placeholder("float", [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
x_label = tf.reshape(y_, [-1, 10])
mobileNet = MobileNet(x_image, x_label)
train_step = tf.train.AdamOptimizer(1e-4).minimize(mobileNet.loss)
keep_prob = tf.placeholder("float")
correct_prediction = tf.equal(tf.arg_max(mobileNet.predictions, 1), tf.arg_max(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(10000):
batch = mnist.train.next_batch(50)
if i % 10 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accurary %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
tf.nn.separable_conv2d()

 京公网安备 11010502036488号
京公网安备 11010502036488号