

算法能解决的问题
- 子串的搜索与匹配
- 统计不同子串的数量
- 子串出现次数的统计
- 寻找最长公共子串
算法步骤
有限状态自动机 D F A DFA DFA
s s s的 S A M SAM SAM是一个接受 𝑠 𝑠 s的所有后缀的最小 D F A DFA DFA
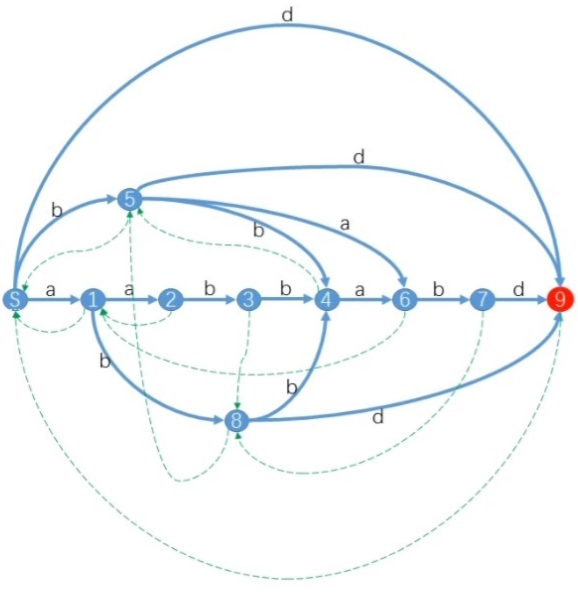
从起点出发的每个路径和 D F A DFA DFA的子串都是一一对应的, 如果暴力的存储空间复杂度是 O ( n 3 ) O(n ^ 3) O(n3)级别的(子串数量是 n 2 n ^ 2 n2, 点的数量是 n n n), 但是如果是用后缀自动机( S A M SAM SAM)存储, 空间能降低到 O ( n ) O(n) O(n)
- 某个点会对应若干个不同的子串
- 这些子串是的最长路径的连续后缀
- S A M SAM SAM包含两种边, 蓝色边类似于 T r i e Trie Trie树的边, 第二种边是虚线边
- 虚线边必定会形成一棵树
虚线边是当前表示的子串中最短的一个子串, 指向去掉第一个字母的节点
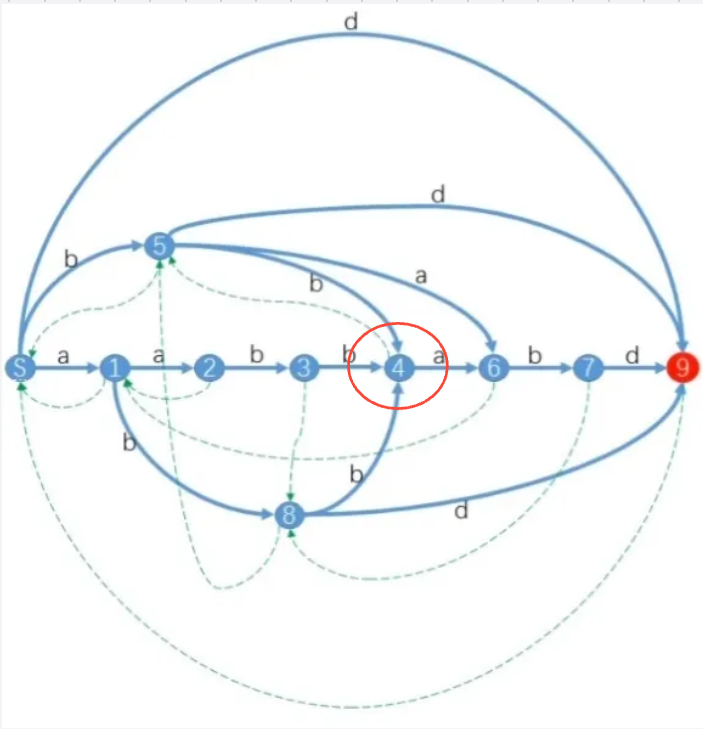
节点 4 4 4表示的最短子串是 b b bb bb, 因此指向节点 b b b, 也就是从节点 4 4 4连向节点 5 5 5
因为每个状态的最短子串是固定的, 并且最短串去掉首字母后的状态也是唯一的, 因此只会连接一条边, 因此所有的虚线边构成的图就是树
如何构造 S A M SAM SAM
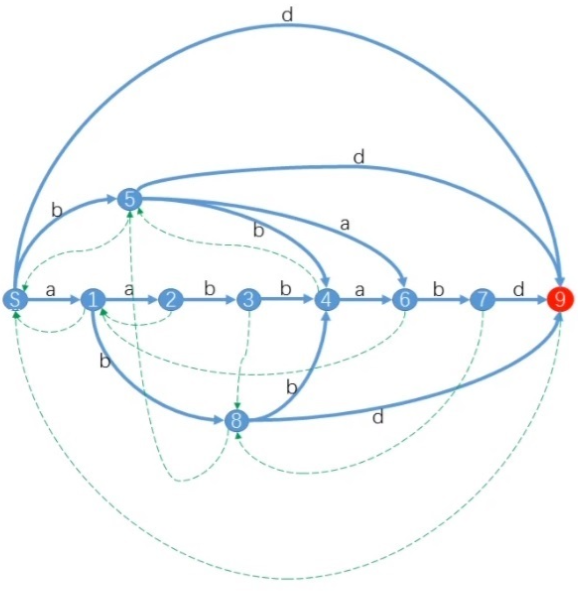

原串是 a a b b a b d aabbabd aabbabd, 那么定义一个函数
e n d p o s [ ′ ′ a b ′ ′ ] = { 3 , 6 } endpos[''ab''] = \{3, 6\} endpos[′′ab′′]={ 3,6}
对于原串的所有子串都可以求一个 e n d p o s endpos endpos
如果两个字符串的 e n d p o s endpos endpos集合是相同的, 那么称这两个字符串是 e n d p o s endpos endpos等价类
-
如果 ∣ s 1 ∣ ≤ ∣ s 2 ∣ |s_1| \le |s_2| ∣s1∣≤∣s2∣, s 1 s_1 s1是 s 2 s_2 s2后缀等价与 e n d p o s ( s 1 ) ⊇ e n d p o s ( s 2 ) endpos(s_1) \supseteq endpos(s_2) endpos(s1)⊇endpos(s2)
-
s 1 s_1 s1不是 s 2 s_2 s2后缀, e n d p o s ( s 1 ) endpos(s_1) endpos(s1)与 3 e n d p o s ( s 2 ) 3endpos(s_2) 3endpos(s2)交集为空集
-
任意两个子串的 e n d p o s endpos endpos集合, 要么是包含关系要么是没有交集
-
如果 ∣ s 1 ∣ ≤ ∣ s 2 ∣ |s_1| \le |s_2| ∣s1∣≤∣s2∣并且两个子串的 e n d p o s endpos endpos相同, 必然有 s 1 s_1 s1是 s 2 s_2 s2的后缀
-
对于所有子串假设 e n d p o s endpos endpos相同状态记为 s t st st, 最长的后缀记为 l o n g e s t ( s t ) longest(st) longest(st), 最短的后缀记为 s h o r t e s t ( s t ) shortest(st) shortest(st), 那么短的串是长的串的后缀
并且有子串 s s s满足
∣ s h o r t e s t ( s t ) ∣ ≤ ∣ s ∣ ≤ l o n g e s t ( s t ) |shortest(st)| \le |s| \le longest(st) ∣shortest(st)∣≤∣s∣≤longest(st)
e n d p o s ( 最长 ) ⊆ e n d p o s ( s ) ⊆ e n d p o s ( 最短 ) endpos(最长) \subseteq endpos(s) \subseteq endpos(最短) endpos(最长)⊆endpos(s)⊆endpos(最短), 并且 e n d p o s ( 最长 ) = e n d p o s ( 最短 ) endpos(最长) = endpos(最短) endpos(最长)=endpos(最短)
由夹逼定理 e n d p o s ( 最长 ) = e n d p o s ( s ) = e n d p o s ( 最短 ) endpos(最长) = endpos(s) = endpos(最短) endpos(最长)=endpos(s)=endpos(最短)
因此对于任意
∣ s h o r t e s t ( s t ) ∣ ≤ ∣ s ∣ ≤ l o n g e s t ( s t ) e n d p o s ( s ) = e n d p o s ( 最长 ) = e n d p o s ( 最短 ) |shortest(st)| \le |s| \le longest(st)endpos(s) = endpos(最长) = endpos(最短) ∣shortest(st)∣≤∣s∣≤longest(st)endpos(s)=endpos(最长)=endpos(最短)
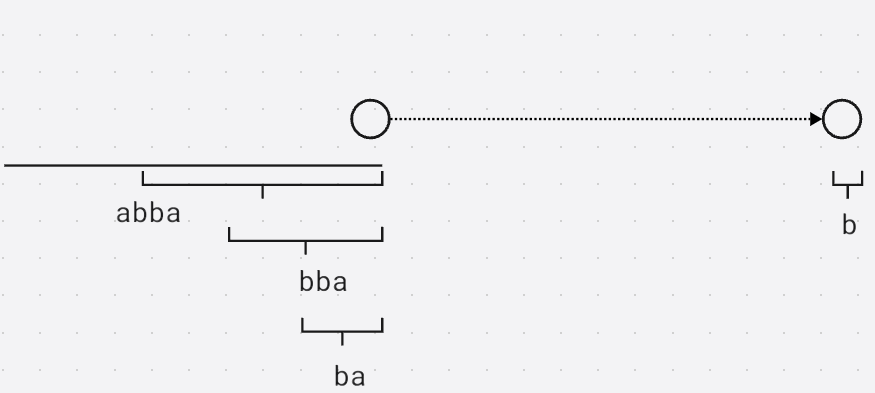
关于虚线边的解释
对于一个节点存储的最长子串, 当子串长度变小的过程中(因为存储的子串都是连续的), e n d p o s ( ) endpos() endpos()位置就会变多, 也就是对于当前节点的最短子串去掉首字母后向包含该子串的集合连接一条边
如何统计答案
(1) 如何求出对于串 s s s的不同子串的数量?
每个路径对应一个串, 每个点记录多个串, 不同点表示的串没有交集
因此只要求出来每个点表示的不同串的数量, 求和就是整个串的不同子串的数量
m a x i , m i n i max_i, min_i maxi,mini分别表示当前集合的最长后缀的长度和最短后缀的长度, 形式化的表示
a n s = ∑ i = 1 n m a x i − m i n i + 1 ans = \sum_{i = 1} ^ n max_i - min_i + 1 ans=i=1∑nmaxi−mini+1
(2) 如何统计每种子串出现多少次?
子串 s s s出现次数等价于 ∣ e n d p o s ( s ) ∣ |endpos(s)| ∣endpos(s)∣, 也就是集合的元素个数, 在 S A M SAM SAM中只会用到虚线边
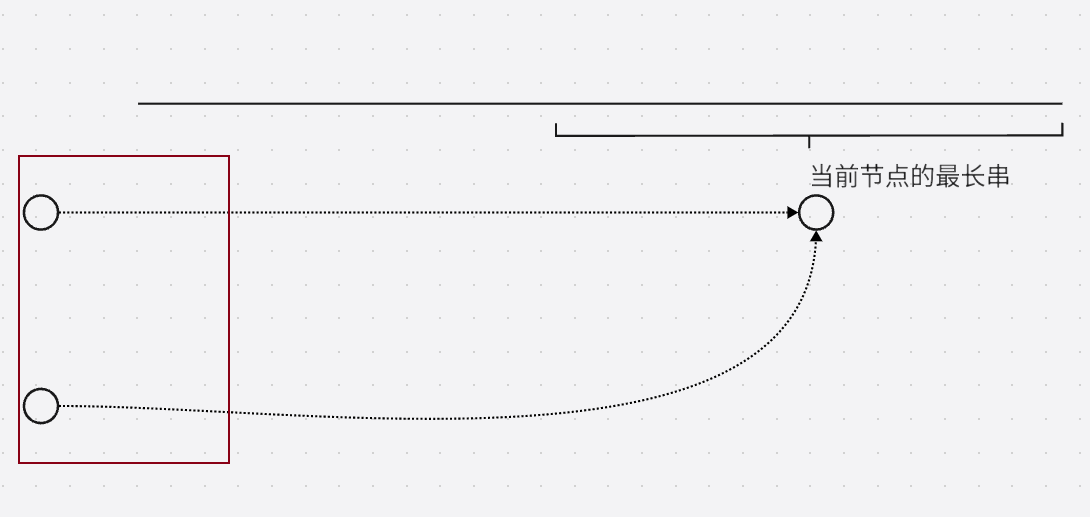
观察哪些子串去掉一个字符之后会变成当前串, 那么子串出现次数应该累计(上图深红色的节点), 并且根据上面的性质, 这些点都是互相没交集的
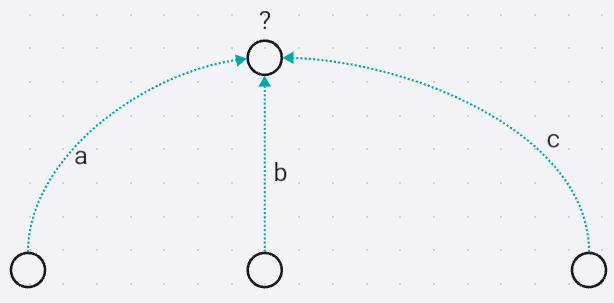
因此可以按照虚线边向前累计出现的次数就是某个后缀在串 s s s出现的次数
结束时刻: 当某个子串前面无法再补新的字符的时候, 也就是当前子串是所求子串的前缀的时候停止累计
模板题和示例代码
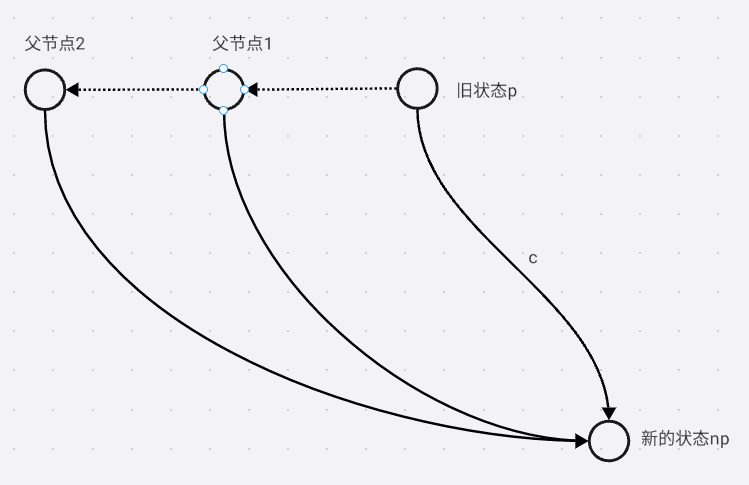
只要当前点没有 c c c的边, 一直向父节点走, 直到有 c c c这条边, 假设指向节点是 q q q
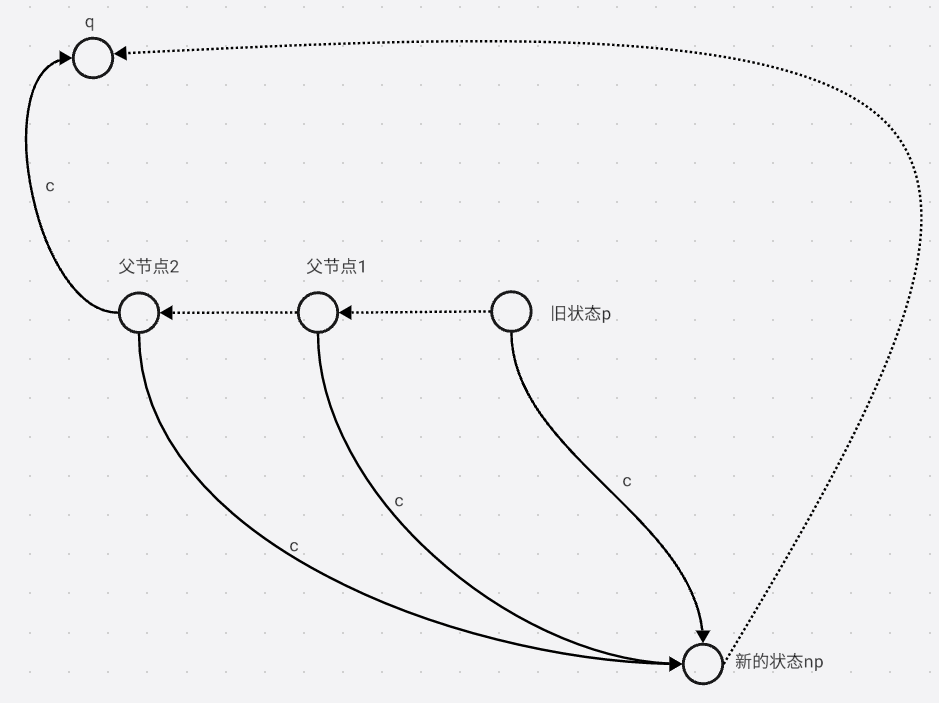
如果 q . l e n = q . l e n + 1 q.len = q.len + 1 q.len=q.len+1, n p . f a = q np.fa = q np.fa=q
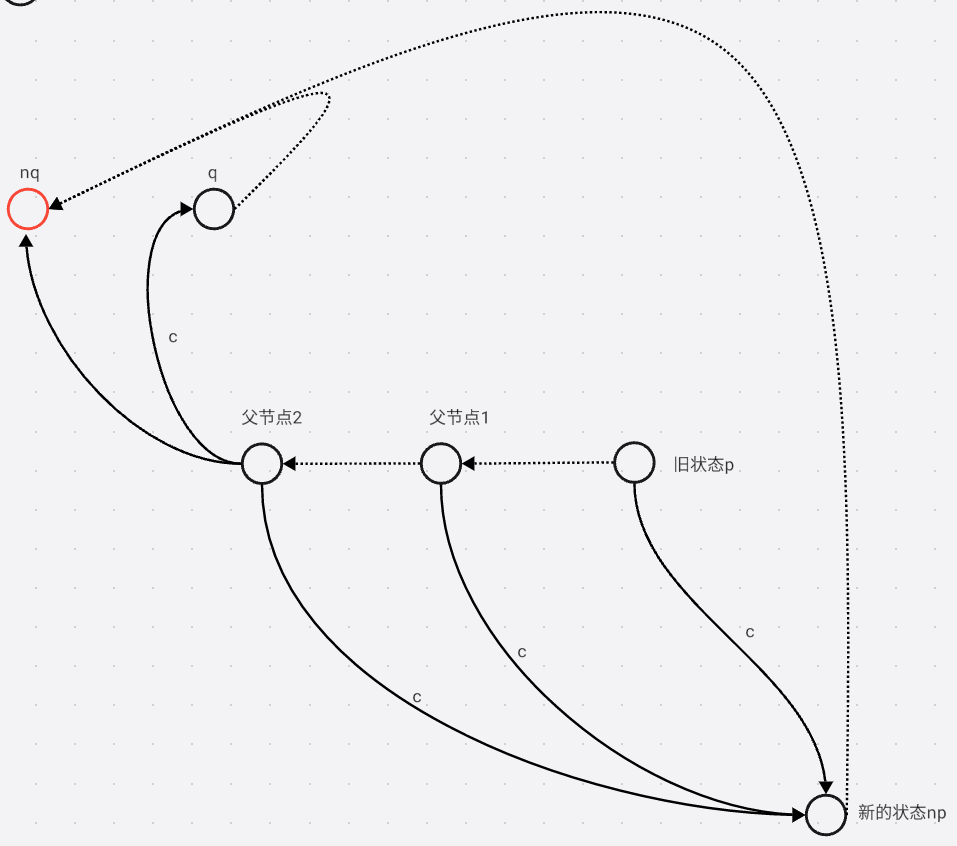
否则就新建一个 n q nq nq, 将旧的 q q q复制到 n q nq nq, 并且新的 n q . l e n = p . l e n + 1 nq.len = p.len + 1 nq.len=p.len+1, 再将 n p np np指向新的 n q nq nq
然后再将所有 p p p的 c c c边的儿子替换成 n q nq nq
示例代码
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 2e6 + 10;
int tot = 1, last = 1;
struct Node {
int len, fa, ch[26];
} nodes[N];
string s;
LL f[N];
int head[N], ed[N], ne[N], idx;
LL ans;
void add(int u, int v) {
ed[idx] = v, ne[idx] = head[u], head[u] = idx++;
}
void extend(int c) {
int p = last, np = last = ++tot;
f[tot] = 1;
nodes[np].len = nodes[p].len + 1;
for (; p && !nodes[p].ch[c]; p = nodes[p].fa) nodes[p].ch[c] = np;
if (!p) nodes[np].fa = 1;
else {
int q = nodes[p].ch[c];
if (nodes[q].len == nodes[p].len + 1) nodes[np].fa = q;
else {
int nq = ++tot;
nodes[nq] = nodes[q];
nodes[nq].len = nodes[p].len + 1;
nodes[q].fa = nodes[np].fa = nq;
for (; p && nodes[p].ch[c] == q; p = nodes[p].fa) nodes[p].ch[c] = nq;
}
}
}
void dfs(int u) {
for (int i = head[u]; ~i; i = ne[i]) {
int v = ed[i];
dfs(v);
f[u] += f[v];
}
if (f[u] > 1) ans = max(ans, f[u] * nodes[u].len);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> s;
for (int i = 0; i < s.size(); ++i) extend(s[i] - 'a');
memset(head, -1, sizeof head);
for (int i = 2; i <= tot; ++i) add(nodes[i].fa, i);
dfs(1);
cout << ans << '\n';
return 0;
}
*玄武密码

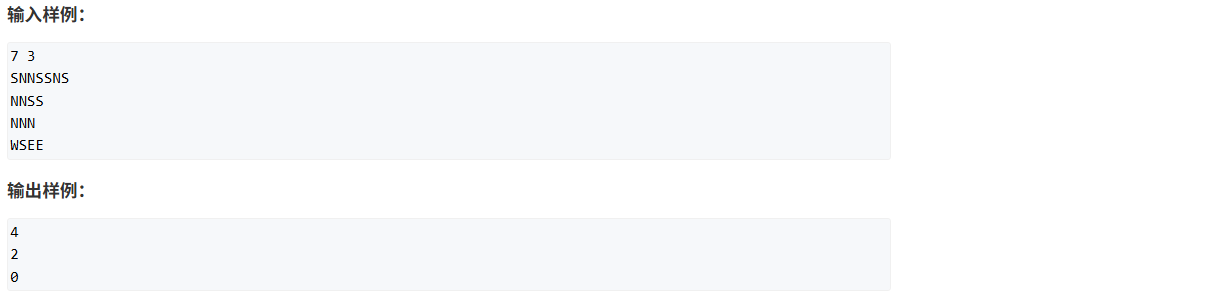
给定一个长度为 n n n的母串, 然后给一些短串, 求解每一段短串的前缀在母串的最大匹配长度
首先将原串构建成 S A M SAM SAM, 从原点出发的所有路径就就是原串的所有子串
#include <bits/stdc++.h>
using namespace std;
const int N = 1e7 + 10;
int n, m;
int tot = 1, last = 1;
struct Node {
int len, fa, ch[4];
} nodes[N * 2];
string s;
inline int get(char c) {
if (c == 'E') return 0;
if (c == 'S') return 1;
if (c == 'W') return 2;
return 3;
}
void extend(int c) {
int p = last, np = last = ++tot;
nodes[np].len = nodes[p].len + 1;
for (; p && !nodes[p].ch[c]; p = nodes[p].fa) nodes[p].ch[c] = np;
if (!p) nodes[np].fa = 1;
else {
int q = nodes[p].ch[c];
if (nodes[q].len == nodes[p].len + 1) nodes[np].fa = q;
else {
int nq = ++tot;
nodes[nq] = nodes[q], nodes[nq].len = nodes[p].len + 1;
nodes[q].fa = nodes[np].fa = nq;
for (; p && nodes[p].ch[c] == q; p = nodes[p].fa) nodes[p].ch[c] = nq;
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> m;
cin >> s;
for (int i = 0; s[i]; ++i) extend(get(s[i]));
while (m--) {
cin >> s;
int p = 1, res = 0;
for (int i = 0; s[i]; ++i) {
int c = get(s[i]);
if (nodes[p].ch[c]) p = nodes[p].fa, res++;
else break;
}
cout << res << '\n';
}
return 0;
}
*最长公共子串
首先先考虑简单情况, 假设是两个字符串
假设先将 a a a字符串存入 S A M SAM SAM, 第二个字符进行匹配, 最暴力的做法是枚举子串的起点, 然后再向下走, 直到 S A M SAM SAM中下个节点没有字符为止, 但是观察数据范围 n ≤ 10000 n \le 10000 n≤10000, 直接暴力枚举算法时间负复杂度是 O ( n 2 k ) O(n ^ 2 k) O(n2k), k k k是子串数量, 无法通过, 需要进行优化
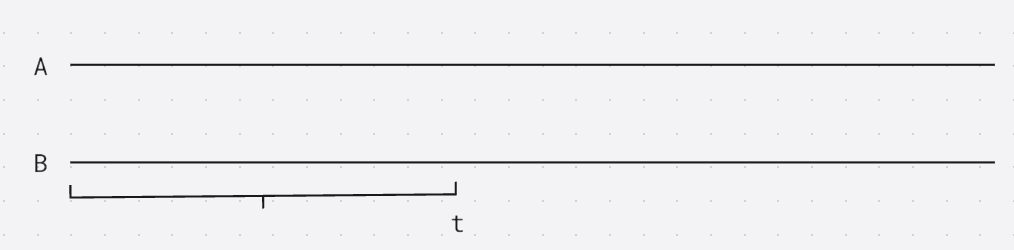
在后缀自动机里面走, 假设匹配到了位置 t t t, 后面没有字符了, 假设在后缀自动机中的点是 p p p
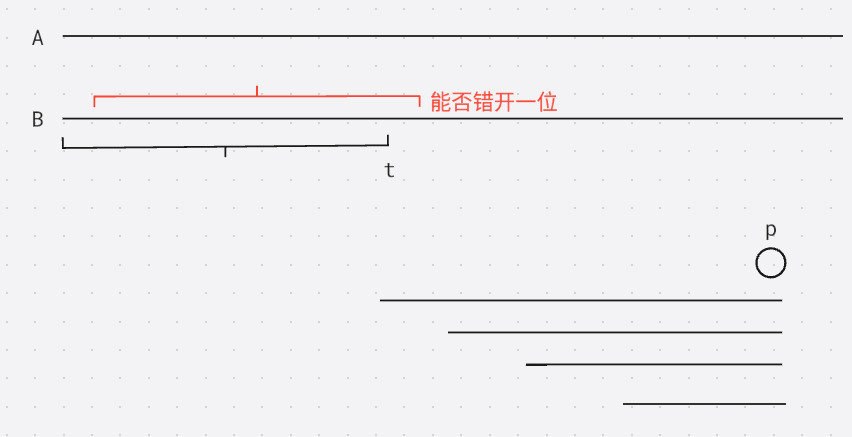
我们希望将子串的起点位置后移一位
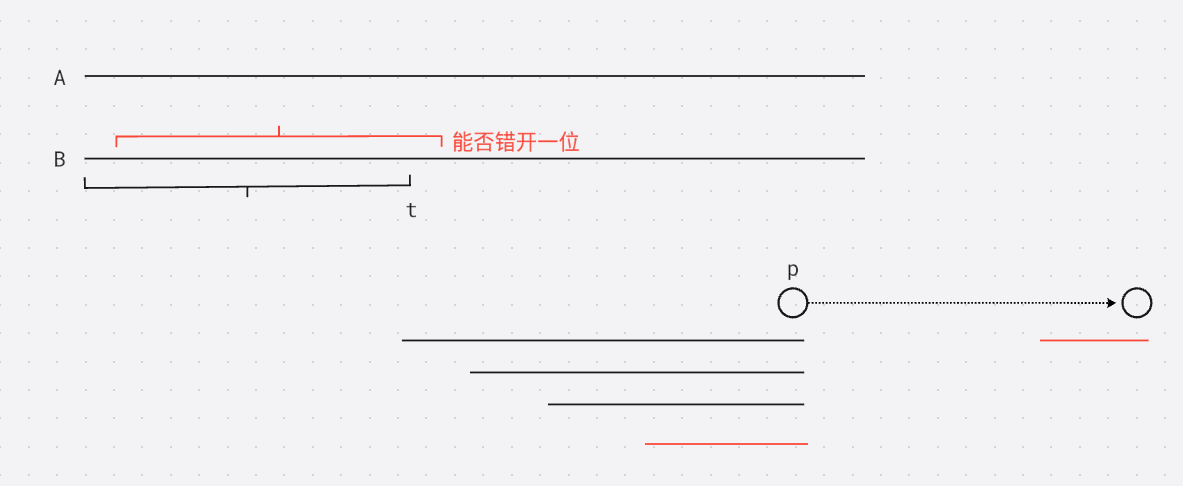
注意到由后缀自动机的性质, 如果去掉首字母可以转移到其他状态只有虚线边, 因为节点内部的子串都是连续的, 去掉除了最短串其他的首字母都依旧转移到节点 p p p, 因此考虑最短串删除第一个字母效果等价于枚举子串向后错开一位
现在考虑复杂情况, 假设是多个字符串, 如何计算最长公共子串?
设 n o w ( p ) now(p) now(p)表示 p p p子串在 B B B出现过的子串的最大长度
对于单个字符串内部取 m a x max max, 对于多个字符串共同维护一个 n o w now now, 因为是公共的, 因此多个子串之间取最小值 m i n min min
#include <bits/stdc++.h>
using namespace std;
const int N = 20010;
int n;
int tot = 1, last = 1;
struct Node {
int len, fa;
int ch[26];
} nodes[N];
int res[N], now[N];
int head[N], ed[N], ne[N], idx;
string s;
void add(int u, int v) {
ed[idx] = v, ne[idx] = head[u], head[u] = idx++;
}
void extend(int c) {
int p = last, np = last = ++tot;
nodes[np].len = nodes[p].len + 1;
for (; p && !nodes[p].ch[c]; p = nodes[p].fa) nodes[p].ch[c] = np;
if (!p) nodes[np].fa = 1;
else {
int q = nodes[p].ch[c];
if (nodes[p].len + 1 == nodes[q].len) nodes[np].fa = q;
else {
int nq = ++tot;
nodes[nq] = nodes[q], nodes[nq].len = nodes[p].len + 1;
nodes[q].fa = nodes[np].fa = nq;
for (; p && nodes[p].ch[c] == q; p = nodes[p].fa) nodes[p].ch[c] = nq;
}
}
}
void dfs(int u) {
for (int i = head[u]; ~i; i = ne[i]) {
int v = ed[i];
dfs(v);
now[u] = max(now[u], now[v]);
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> s;
for (int i = 0; i < s.size(); ++i) extend(s[i] - 'a');
for (int i = 1; i <= tot; ++i) res[i] = nodes[i].len;
memset(head, -1, sizeof head);
for (int i = 2; i <= tot; ++i) add(nodes[i].fa, i);
for (int i = 0; i < n - 1; ++i) {
cin >> s;
memset(now, 0, sizeof now);
int p = 1, t = 0;
for (int j = 0; j < s.size(); ++j) {
int c = s[j] - 'a';
while (p > 1 && !nodes[p].ch[c]) p = nodes[p].fa, t = nodes[p].len;
if (nodes[p].ch[c]) p = nodes[p].ch[c], t++;
now[p] = max(t, now[p]);
}
dfs(1);
for (int j = 1; j <= tot; ++j) res[j] = min(res[j], now[j]);
}
int ans = 0;
for (int i = 1; i <= tot; ++i) ans = max(ans, res[i]);
cout << ans << '\n';
return 0;
}

 京公网安备 11010502036488号
京公网安备 11010502036488号