

知识点目录
-
-
- 试除法判定质数
- 线性筛质数
- 分解质因数之阶乘分解
- 快速幂
- 快速幂求逆元
- 约数
- 约数个数
- 欧拉函数
- 线性筛法求欧拉函数
- 扩展欧几里得算法
- 扩展欧几里得算法求同余方程
- 同余综合应用
- 中国剩余定理
- 中国剩余定理扩展
- 矩阵乘法
- 矩阵乘法优化状态机DP
- 组合计数
- 递推法求组合数
- 预处理法求组合数
- Lucas定理求组合数
- 分解质因数 + 高精度计算组合数
- 递推法求组合计数问题
- 排列组合问题之方程的解
- 组合数排列数求不规则图形
- 组合数之网格求三角形数量
- 隔板法求不等式解的个数
- 卡特兰序列
- 组合数学之卡特兰数
- 高斯消元解线性方程组
- 高斯消元解线性异或方程组
- 高斯消元应用
- 容斥原理
- 整除分块
- 莫比乌斯函数
- 莫比乌斯函数应用
- 概率与数学期望
- 博弈论之公平组合游戏ICG
- 博弈论之SG函数
- 博弈论应用
-
试除法判定质数
#include <iostream>
using namespace std;
const int N = 110;
int n;
bool is_prime(int val) {
if (val < 2) return false;
for (int i = 2; i <= val / i; ++i) {
if (val % i == 0) return false;
}
return true;
}
int main() {
scanf("%d", &n);
while (n--) {
int val;
scanf("%d", &val);
if (is_prime(val)) puts("Yes");
else puts("No");
}
return 0;
}
线性筛质数
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e6 + 10;
int primes[N], cnt;
bool visited[N];
void init(int val) {
for (int i = 2; i <= val; ++i) {
if (!visited[i]) primes[cnt++] = i;
for (int j = 0; primes[j] * i <= val; ++j) {
visited[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
int main() {
init(N - 1);
int n;
while (cin >> n, n) {
for (int i = 1; ; ++i) {
int val1 = primes[i];
int val2 = n - val1;
if (!visited[val2]) {
printf("%d = %d + %d\n", n, val1, val2);
break;
}
}
}
return 0;
}
每一条边都是从质数连到非质数, 因此是二分图
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e5 + 10;
int n;
int primes[N], cnt;
bool vis[N];
void init(int val) {
for (int i = 2; i <= val; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; primes[j] * i <= val; ++j) {
vis[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
int main() {
scanf("%d", &n);
init(n + 1);
// 输出需要的颜色的个数
if (n <= 2) puts("1");
else puts("2");
for (int i = 2; i <= n + 1; ++i) {
if (!vis[i]) printf("1 ");
else printf("2 ");
}
return 0;
}
寻找在区间 [ l , r ] [l, r] [l,r]之间, 相邻质数差值最大和最小的一对
范围比较小的时候, 直接筛出质数, 然后在区间中进行扫描即可, 但该题数据范围非常大, 因此不能直接扫描
如果一个数是合数, 必然存在一个小于 n \sqrt{n} n的因子
先找出 [ 1 , 50000 ] [1, 50000] [1,50000]所有的质因子, 对于全部区间的数字, 如果该数字是合数, 必然存在一个 [ 1 , 50000 ] [1, 50000] [1,50000]的质因子, 因此将区间中的质因子的倍数全部删去
时间复杂度 O ( n log log n ) O(n\log{}{\log{}{n}}) O(nloglogn)
用范围很小的质数处理范围很大的合数
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e6 + 10;
int primes[N], cnt;
bool vis[N];
void init(int val) {
memset(vis, false, sizeof vis);
cnt = 0;
for (int i = 2; i <= val; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] <= val; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
int main() {
int l, r;
while (scanf("%d%d", &l, &r) == 2) {
init(50000);
memset(vis, false, sizeof vis);
// 找到大于等于l的最小的p的倍数, 将p的倍数全部删去
for (int i = 0; i < cnt; ++i) {
LL p = primes[i];
for (LL j = max(2 * p, (l + p - 1) / p * p); j <= r; j += p) {
vis[j - l] = true;
}
}
// 找到区间中剩余的质数
cnt = 0;
for (int i = 0; i <= r - l; ++i) {
if (!vis[i] && i + l >= 2) primes[cnt++] = l + i;
}
if (cnt < 2) puts("There are no adjacent primes.");
else {
int minp = 0, maxp = 0;
for (int i = 0; i < cnt - 1; ++i) {
int d = primes[i + 1] - primes[i];
if (d < primes[minp + 1] - primes[minp]) minp = i;
if (d > primes[maxp + 1] - primes[maxp]) maxp = i;
}
printf("%d,%d are closest, %d,%d are most distant.\n", primes[minp], primes[minp + 1], primes[maxp], primes[maxp + 1]);
}
}
return 0;
}
注意: 忘记开
long long也会导致段错误
分解质因数之阶乘分解
- 筛出 [ 1 , 1 0 6 ] [1, 10^6] [1,106]中所有的质数
- 求出所有 p p p的次数

#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e6 + 10;
int primes[N], cnt;
bool vis[N];
void init(int val) {
for (int i = 2; i <= val; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] <= val; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
int main() {
int n;
scanf("%d", &n);
init(n);
for (int i = 0; i < cnt; ++i) {
int res = 0;
int p = primes[i];
for (int j = n; j; j /= p) res += j / p;
printf("%d %d\n", p, res);
}
return 0;
}
快速幂
将情况分为等差数列和等比数列
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int MOD = 200907;
LL quick_pow(int val, int k) {
LL res = 1;
while (k) {
if (k & 1) res = (LL) res * val % MOD;
val = (LL) val * val % MOD;
k >>= 1;
}
return res;
}
int main() {
int cases;
scanf("%d", &cases);
while (cases--) {
int a, b, c, k;
scanf("%d%d%d%d", &a, &b, &c, &k);
if (b - a == c - b) {
int d = b - a;
LL res = a + (LL) (k - 1) * d % MOD;
printf("%lld\n", res % MOD);
}
else {
int d = b / a;
LL res = (LL) a * quick_pow(d, k - 1) % MOD;
printf("%lld\n", res % MOD);
}
}
return 0;
}
n n n个犯人, m m m种宗教, 多少种不同的分配方案, 使得至少两个相邻的犯人相邻的宗教是一样的
m n − m × ( m − 1 ) n − 1 m^n - m \times (m - 1)^{n - 1} mn−m×(m−1)n−1
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int MOD = 100003;
int m;
LL n;
LL quick_pow(int val, LL k) {
LL res = 1;
while (k) {
if (k & 1) res = (LL) res * val % MOD;
val = (LL) val * val % MOD;
k >>= 1;
}
return res;
}
int main() {
scanf("%d%lld", &m, &n);
LL res = quick_pow(m, n) - (LL) m * quick_pow(m - 1, n - 1) % MOD + MOD;
printf("%lld\n", res % MOD);
return 0;
}
快速幂求逆元

#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n;
int a, p;
int quick_pow(int val, int k, int mod) {
int res = 1 % mod;
while (k) {
if (k & 1) res = (LL) res * val % mod;
val = (LL) val * val % mod;
k >>= 1;
}
return res;
}
int main() {
scanf("%d", &n);
while (n--) {
scanf("%d%d", &a, &p);
if (a % p == 0) puts("impossible");
else {
int res = quick_pow(a, p - 2, p);
printf("%d\n", res);
}
}
return 0;
}
约数
约数个数: ( c 1 + 1 ) ( c 2 + 1 ) ( . . . ) ( c k + 1 ) (c_1 + 1)(c_2 + 1)(...)(c_k + 1) (c1+1)(c2+1)(...)(ck+1)
1 1 1到 n n n中约数的个数: O ( n log n ) O(n\log{}{n}) O(nlogn)
i n t int int范围内约数个数最多的数的约数有 1600 1600 1600个
约数个数
对于当前数, 其他的数有多少个是他的约数, 给定整数分解质因数是比较困难的, 但是求倍数很简单, 可以对约数进行优化
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e6 + 10;
int n;
int arr[N], cnt[N], s[N];
int main() {
scanf("%d", &n);
for (int i = 0; i < n; ++i) {
scanf("%d", &arr[i]);
cnt[arr[i]]++;
}
for (int i = 1; i < N; ++i) {
for (int j = i; j < N; j += i) {
s[j] += cnt[i];
}
}
for (int i = 0; i < n; ++i) printf("%d\n", s[arr[i]] - 1);
return 0;
}
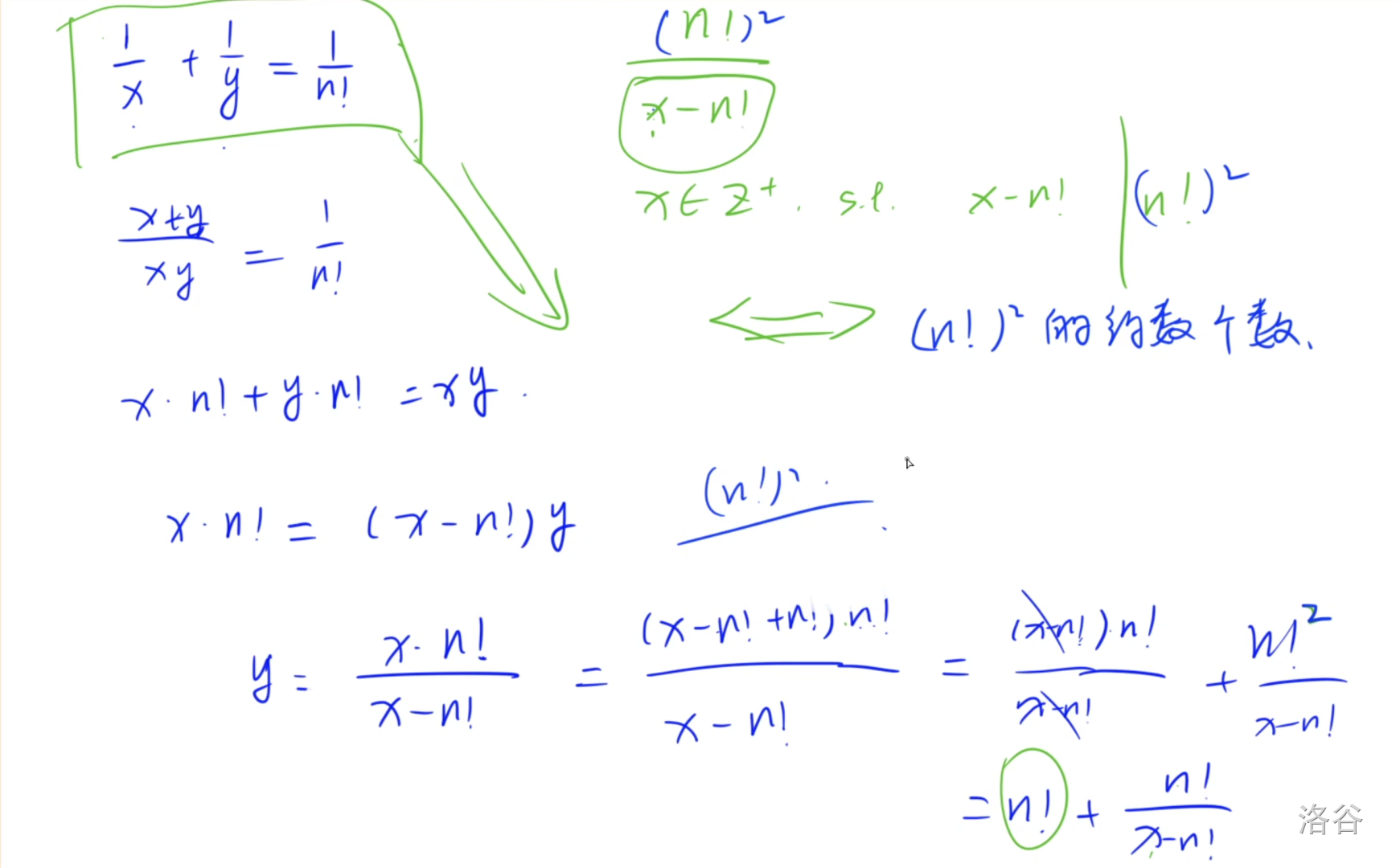
本质上求的是 n ! n! n!的约数个数
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e6 + 10, MOD = 1e9 + 7;
int n;
int primes[N], cnt;
bool vis[N];
void init(int val) {
for (int i = 2; i <= val; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] <= val; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
int main() {
scanf("%d", &n);
init(n);
LL res = 1;
for (int i = 0; i < cnt; ++i) {
int s = 0;
int p = primes[i];
for (int j = n; j; j /= p) s += j / p;
res = (LL) res * (2 * s + 1) % MOD;
}
printf("%lld\n", res);
return 0;
}
最大的反素数: 约数个数最多的数中最小的数
- 不同的质因子数量不会超过 10 10 10
- 最大次数 30 , 30, 30, 因为 2 31 > 2 × 1 0 9 2^{31} > 2 \times 10 ^ 9 231>2×109
- 所有质因子次数递减, 一定是降序, 因为如果不是降序交换一下一定会变得更小
因为搜索空间非常小, 因此直接DFS
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int primes[9] = {
2, 3, 5, 7, 11, 13, 17, 19, 23};
int n;
int cnt, res;
void dfs(int u, int last, int curr, int sum) {
if (sum > cnt || sum == cnt && curr < res) {
cnt = sum;
res = curr;
}
if (u == 9) return;
for (int i = 1; i <= last; ++i) {
if ((LL) curr * primes[u] > n) break;
curr *= primes[u];
dfs(u + 1, i, curr, sum * (i + 1));
}
}
int main() {
scanf("%d", &n);
dfs(0, 30, 1, 1);
printf("%d\n", res);
return 0;
}
给定 4 4 4个正整数, 有多少个正整数 x x x, g c d ( a , x ) = b gcd(a, x) = b gcd(a,x)=b, 并且 [ c , x ] = d [c, x] = d [c,x]=d, 数据范围很大
[ a , b ] [a, b] [a,b]最小公倍数等于 a × b ( a , b ) \frac {a \times b}{(a, b)} (a,b)a×b
直接枚举约数时间复杂度是 O ( n ) O(\sqrt n) O(n), 用分解质因数方法计算效率会高很多
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 50010;
int primes[N], cnt;
bool vis[N];
struct Factor {
int p, s;
} factors[10];
int fcnt;
// 存储约数
int divisor[N], dcnt;
void init() {
for (int i = 2; i <= N - 1; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] <= N - 1; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
void dfs(int u, int curr) {
if (u == fcnt) {
divisor[dcnt++] = curr;
return;
}
for (int i = 0; i <= factors[u].s; ++i) {
dfs(u + 1, curr);
curr *= factors[u].p;
}
}
int gcd(int a, int b) {
return b ? gcd(b, a % b) : a;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
init();
int cases;
cin >> cases;
while (cases--) {
int a, b, c, d;
// 求一个x使得(x, a) = b 并且[x, c] = d
cin >> a >> b >> c >> d;
// 将d分解质因数
fcnt = 0;
int val = d;
for (int i = 0; primes[i] <= val / primes[i]; ++i) {
int p = primes[i];
if (val % p == 0) {
int s = 0;
while (val % p == 0) val /= p, s++;
factors[fcnt++] = {
p, s};
}
}
if (val > 1) factors[fcnt++] = {
val, 1};
dcnt = 0;
// 搜索d的所有约数
dfs(0, 1);
// 枚举d的所有约数, 找到符合条件的一个
int res = 0;
for (int i = 0; i < dcnt; ++i) {
int val = divisor[i];
if (gcd(a, val) == b && (LL) c * val / gcd(c, val) == d) res++;
}
cout << res << endl;
}
return 0;
}
欧拉函数
定义: 1 1 1到 n n n中与 n n n互质的数的个数
线性筛法求欧拉函数
在筛质数的时候同时计算出欧拉函数
- 1的时候, 欧拉函数的值是1
- 当 p j p_j pj是 i i i的最小质因子, φ ( i × p j ) = p j × φ ( i ) \varphi (i \times p_j) = p_j \times \varphi(i) φ(i×pj)=pj×φ(i)
- 当 p j p_j pj不是 i i i的最小质因子, φ ( i × p j ) = ( p j − 1 ) ⋅ φ ( i ) \varphi(i \times p_j) = (p_j - 1)\cdot \varphi(i) φ(i×pj)=(pj−1)⋅φ(i)
( x 0 ) , y 0 (x_0), y_0 (x0),y0能被照到, 等价于是直线上的第一个点, 等价于两个数互质
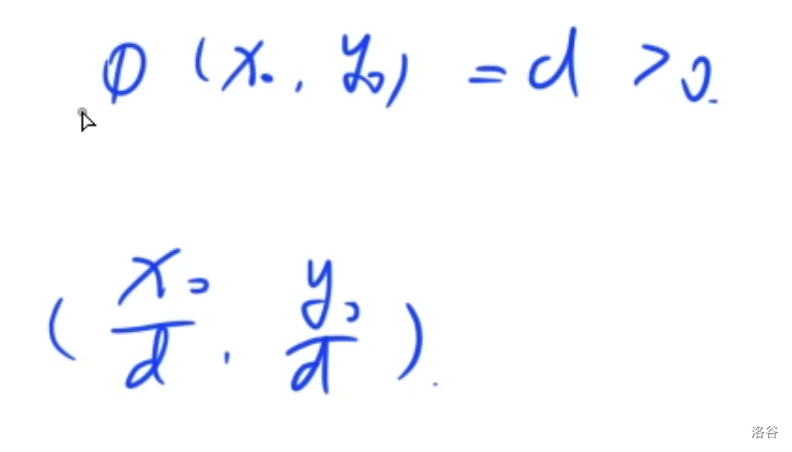
首先证明正向, 如果不互质, 一定存在最大公约数 d d d, 使得新的点的坐标出现在 ( x 0 , y 0 ) (x_0, y_0) (x0,y0)的下方也就不是第一个点, 矛盾
然后证明反向, 如果两个数互质一定不存在一对点使得该点在 ( x 0 , y 0 ) (x_0, y_0) (x0,y0)下方, 因为在同一条直线上, 因此斜率是相同的, 因此 x x x方向的比值和 y y y方向上的比值也是相同的, 但是以为互质就是最简真分数, 因此不存在除了 1 1 1的比值之外的数, 因此不存在该点
问题转化为求 [ 0 , N ] [0, N] [0,N]之间有多少个数对 ( x , y ) (x, y) (x,y)横纵坐标是互质的
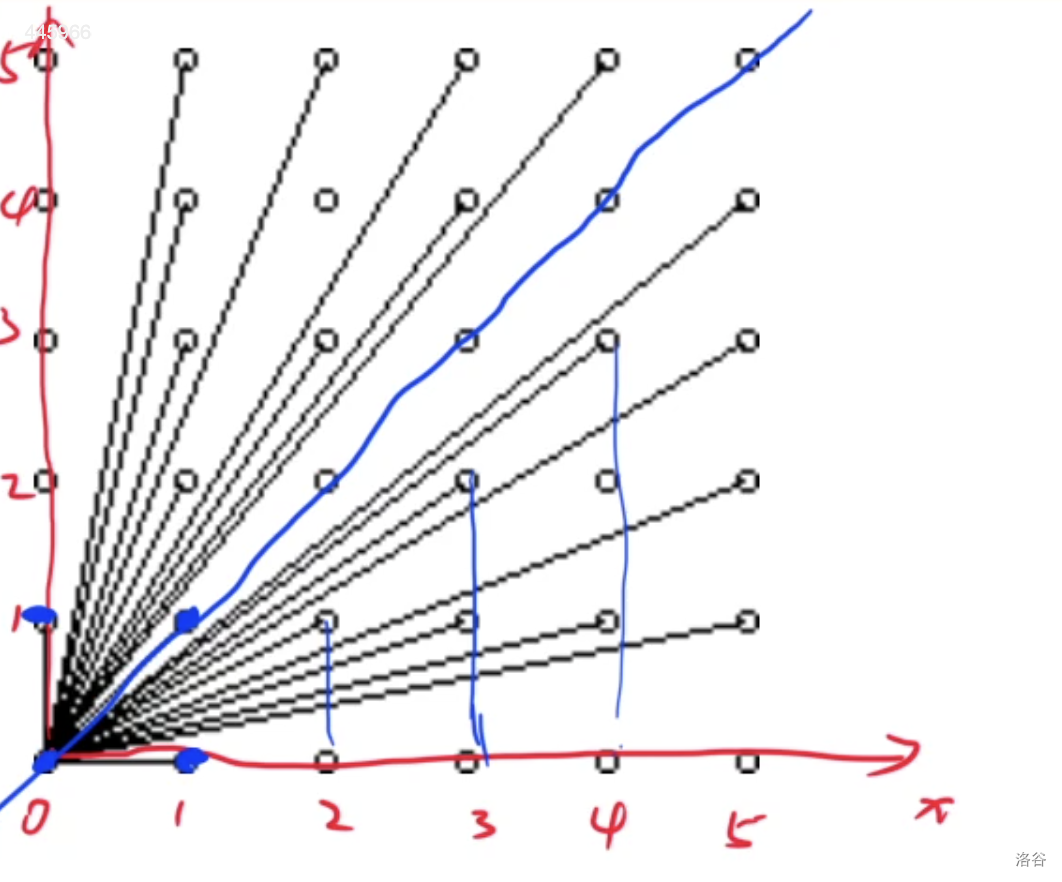
如何计算多少对?
可以将上述图形一分为二, 因为上半部分与下半部分是对称的, 因此考略下半部分
按照横坐标进行枚举, 对于每一个横坐标求出 [ 1 , x ] [1, x] [1,x]之间与 x x x互质的数的个数累加起来就是下半部分的数量
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int primes[N], cnt;
bool vis[N];
int phi[N];
void init(int val) {
phi[1] = 1;
for (int i = 2; i <= val; ++i) {
if (!vis[i]) {
primes[cnt++] = i;
phi[i] = i - 1;
}
for (int j = 0; i * primes[j] <= val; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) {
phi[i * primes[j]] = phi[i] * primes[j];
break;
}
phi[i * primes[j]] = phi[i] * (primes[j] - 1);
}
}
}
int main() {
init(N - 1);
int cases;
scanf("%d", &cases);
for (int i = 1; i <= cases; ++i) {
int n;
scanf("%d", &n);
int res = 0;
for (int i = 1; i <= n; ++i) res += phi[i];
printf("%d %d %d\n", i, n, res * 2 + 1);
}
return 0;
}
在该题中定义 φ ( 1 ) = 1 \varphi(1) = 1 φ(1)=1, 因为在 x x x轴坐标上也有一个点是合法的, 但是真正的欧拉函数 φ ( 1 ) = 0 \varphi(1) = 0 φ(1)=0
求最大公约数是素数的数的个数
将最大公约数是 p p p的数的个数, 等价于

最大公约数是 1 1 1的数对的个数, 也就是互质的数的个数, 与上一题类似
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e7 + 10;
int n;
int primes[N], cnt;
bool vis[N];
int phi[N];
LL sum[N];
void init(int val) {
phi[1] = 0;
for (int i = 2; i <= val; ++i) {
if (!vis[i]) {
primes[cnt++] = i;
phi[i] = i - 1;
}
for (int j = 0; i * primes[j] <= val; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) {
phi[i * primes[j]] = phi[i] * primes[j];
break;
}
phi[i * primes[j]] = phi[i] * (primes[j] - 1);
}
}
for (int i = 1; i <= val; ++i) sum[i] = sum[i - 1] + phi[i];
}
int main() {
scanf("%d", &n);
init(n);
LL res = 0;
// 枚举所有质数
for (int i = 0; i < cnt; ++i) {
int p = primes[i];
res += 2 * sum[n / p] + 1;
}
printf("%lld\n", res);
return 0;
}
扩展欧几里得算法
裴蜀定理: 给定任意正整数 a , b a, b a,b, 一定存在整数 x , y x, y x,y使得 a x + b y = ( a , b ) ax + by = (a, b) ax+by=(a,b)

扩展欧几里得算法求同余方程
求最小正整数解, 也就是求最小正余数
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
int exgcd(int a, int b, LL &x, LL &y) {
if (!b) {
x = 1, y = 0;
return a;
}
int gcd = exgcd(b, a % b, y, x);
y -= (LL) (a / b) * x;
return gcd;
}
int main() {
int a, b;
cin >> a >> b;
LL x, y;
exgcd(a, b, x, y);
cout << (x % b + b) % b << endl;
return 0;
}
同余综合应用
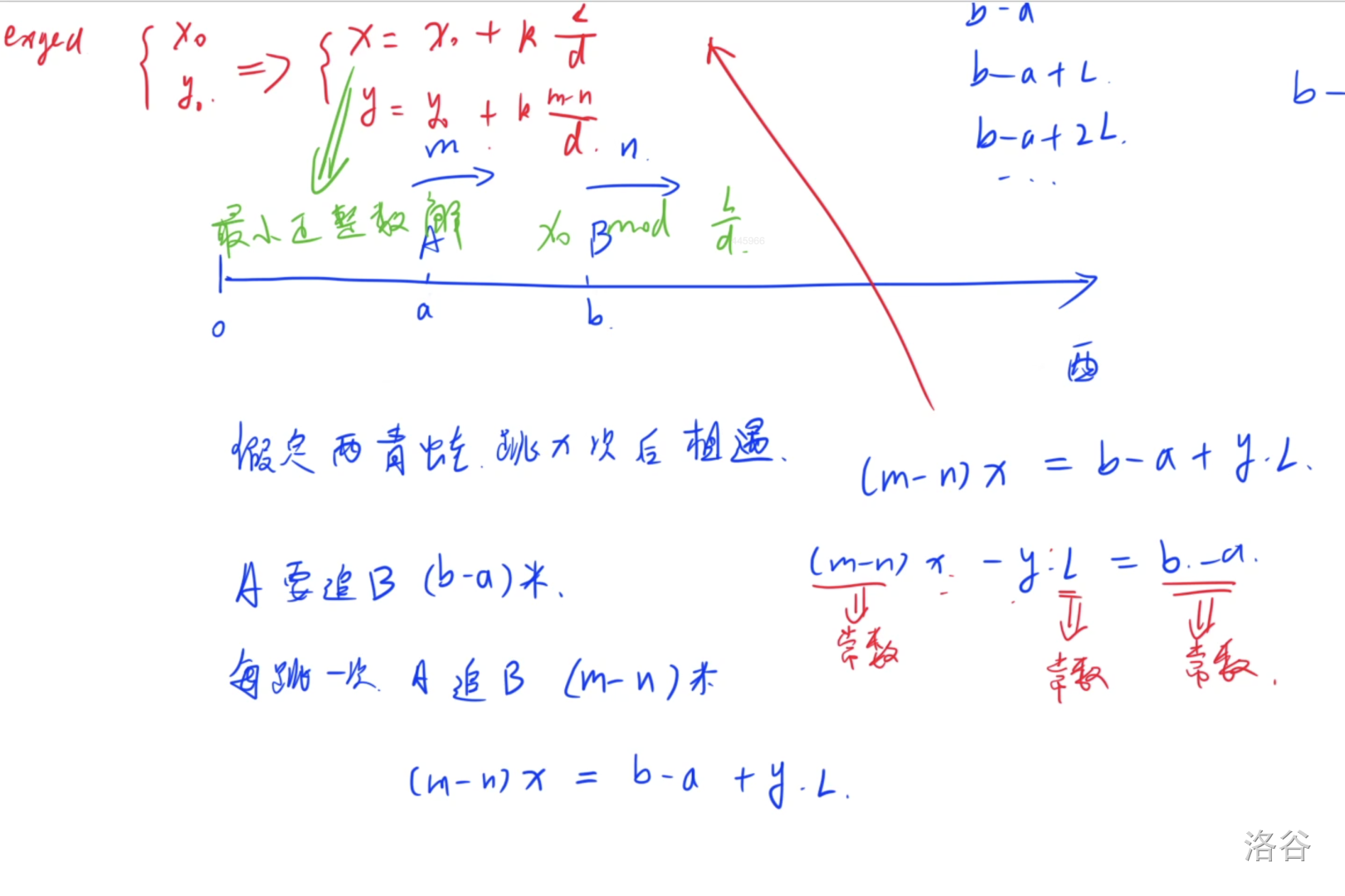
求最小正整数解
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cmath>
using namespace std;
typedef long long LL;
LL exgcd(LL a, LL b, LL &x, LL &y) {
if (!b) {
x = 1, y = 0;
return a;
}
LL d = exgcd(b, a % b, y, x);
y -= (a / b) * x;
return d;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
LL a, b, m, n, len;
cin >> a >> b >> m >> n >> len;
LL x, y;
LL gcd = exgcd(m - n, len, x, y);
// 如果gcd无法转化为b - a一定无解
if ((b - a) % gcd) puts("Impossible");
else {
x = x * (b - a) / gcd;
// 求最小的正整数解, 就是求正余数
LL mod = abs(len / gcd);
cout << (x % mod + mod) % mod << endl;
}
return 0;
}
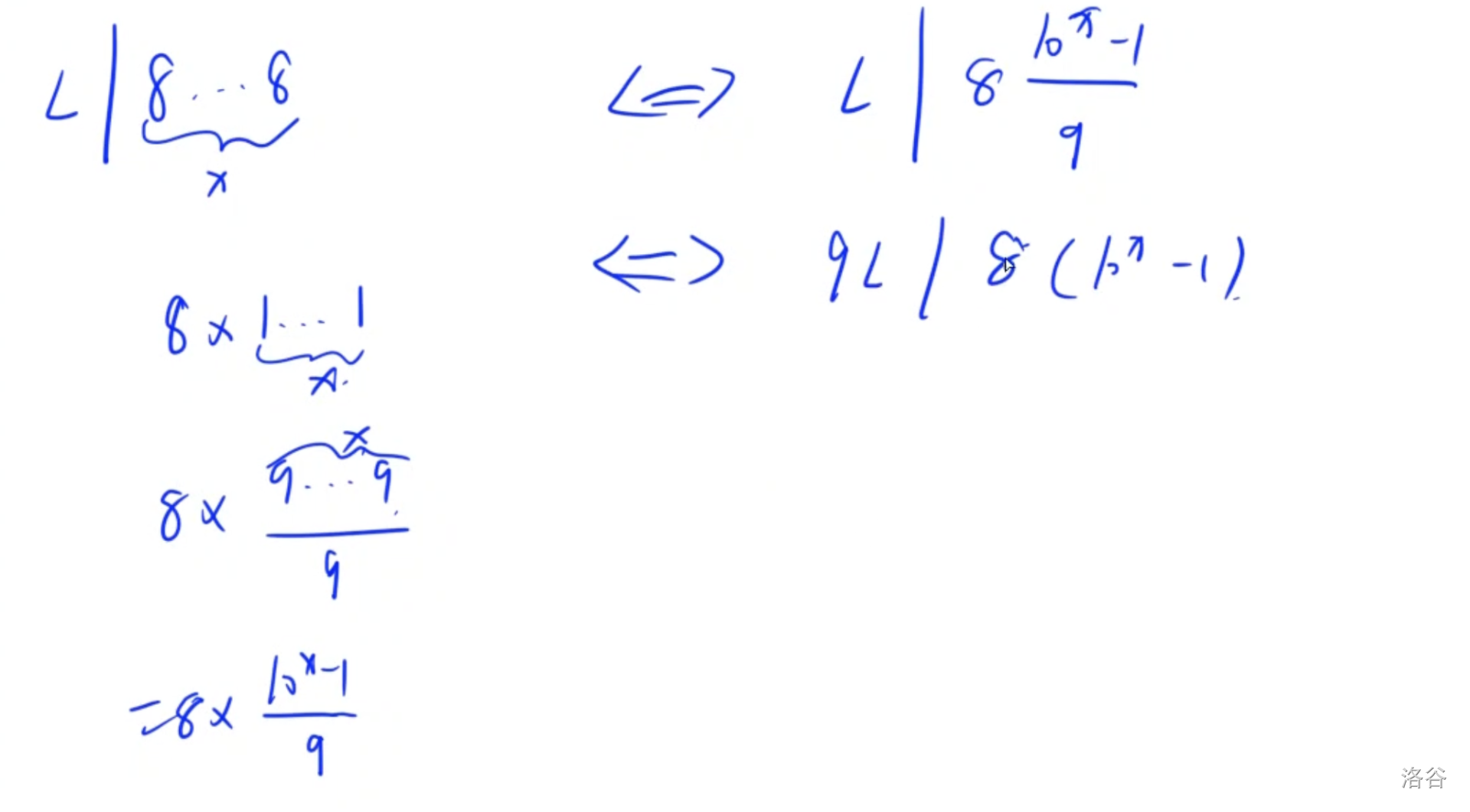
将问题转化为上述形式, 将 9 L 9L 9L和 8 8 8的公因子筛掉
证明如下

在将问题转化为欧拉定理, 但是求的是最小的 x x x, 欧拉定理求的不是最小的解, 需要继续推导
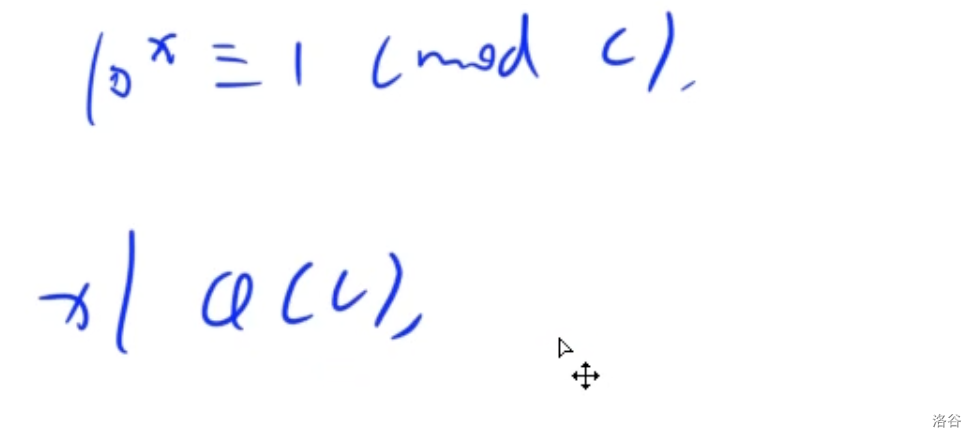
结论: 最小的 x x x一定是 φ ( c ) \varphi(c) φ(c)的约数
枚举所有约数, 找到满足要求的 φ ( c ) \varphi(c) φ(c)的约数

该问题的时间复杂度瓶颈在求约数: O ( n ) O(\sqrt n) O(n)
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
LL gcd(LL a, LL b) {
return b ? gcd(b, a % b) : a;
}
// 计算欧拉函数
LL get_euler(LL val) {
LL res = val;
for (LL i = 2; i <= val / i; ++i) {
// 如果i是val的质因子, 根据定义计算
if (val % i == 0) {
while (val % i == 0) val /= i;
res = res / i * (i - 1);
}
}
if (val > 1) res = res / val * (val - 1);
return res;
}
LL quick_mul(LL val, LL k, LL mod) {
LL res = 0;
while (k) {
if (k & 1) res = (res + val) % mod;
val = (val + val) % mod;
k >>= 1;
}
return res;
}
LL quick_pow(LL val, LL k, LL mod) {
LL res = 1;
while (k) {
if (k & 1) res = quick_mul(res, val, mod);
val = quick_mul(val, val, mod);
k >>= 1;
}
return res;
}
int main() {
int cases = 1;
LL len;
while (scanf("%lld", &len), len) {
LL c = gcd(len, 8);
c = 9 * len / c;
LL phi = get_euler(c);
LL res = 1e18;
if (c % 2 == 0 || c % 5 == 0) res = 0;
else {
for (LL i = 1; i * i <= phi; ++i) {
// 枚举phi的约数
if (phi % i == 0) {
LL d1 = i;
LL d2 = phi / i;
if (quick_pow(10, d1, c) == 1) res = min(res, d1);
if (quick_pow(10, d2, c) == 1) res = min(res, d2);
}
}
}
printf("Case %d: %lld\n", cases++, res);
}
return 0;
}
中国剩余定理
用扩展欧几里得欧几里得算法求 M i M_i Mi对 m i m_i mi的逆元

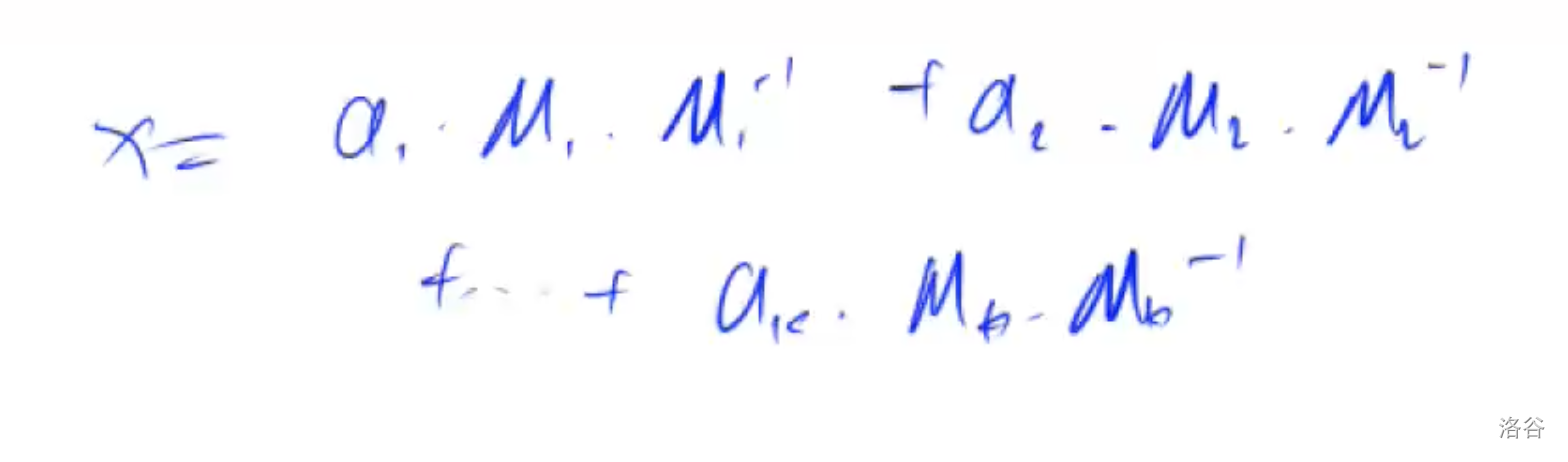
如果计算出的 x x x是负数, 对 M M M取模*
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 20;
int n;
int arr1[N], arr2[N];
LL exgcd(LL a, LL b, LL &x, LL &y) {
if (!b) {
x = 1, y = 0;
return a;
}
LL d = exgcd(b, a % b, y, x);
y -= (a / b) * x;
return d;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
LL mul = 1;
cin >> n;
for (int i = 1; i <= n; ++i) {
cin >> arr1[i] >> arr2[i];
mul *= arr1[i];
}
LL res = 0;
for (int i = 1; i <= n; ++i) {
LL Mi = mul / arr1[i];
LL ti, y;
// 求Mi对mi的逆元
exgcd(Mi, arr1[i], ti, y);
// 计算中国剩余定理
res = (res + (__int128) arr2[i] * Mi * ti) % mul;
}
cout << (res % mul + mul) % mul << endl;
return 0;
}
中国剩余定理扩展
推导过程

每次将新的方程合并到现有方程当中
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
int n;
LL exgcd(LL a, LL b, LL &x, LL &y) {
if (!b) {
x = 1, y = 0;
return a;
}
LL d = exgcd(b, a % b, y, x);
y -= (a / b) * x;
return d;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n;
LL x = 0, a1, m1;
cin >> a1 >> m1;
// 合并两个式子
for (int i = 0; i < n - 1; ++i) {
LL a2, m2;
cin >> a2 >> m2;
LL k1, k2;
LL gcd = exgcd(a1, a2, k1, k2);
// 如果m2 - m1不能整除最大公约数 无解
if (abs(m2 - m1) % gcd) {
x = -1;
break;
}
k1 *= (m2 - m1) / gcd;
LL mod = a2 / gcd;
// 因为数据范围的限制, 每次计算新的k都只能用最小正整数解进行迭代
k1 = (k1 % mod + mod) % mod;
m1 = a1 * k1 + m1;
// 新的a是a1, a2的最小公倍数
a1 = a1 / gcd * a2;
}
if (x == -1) cout << -1 << endl;
// 最后剩余一个式子就是求m1 % a1的正余数
else cout << (m1 % a1 + a1) % a1 << endl;
return 0;
}
矩阵乘法
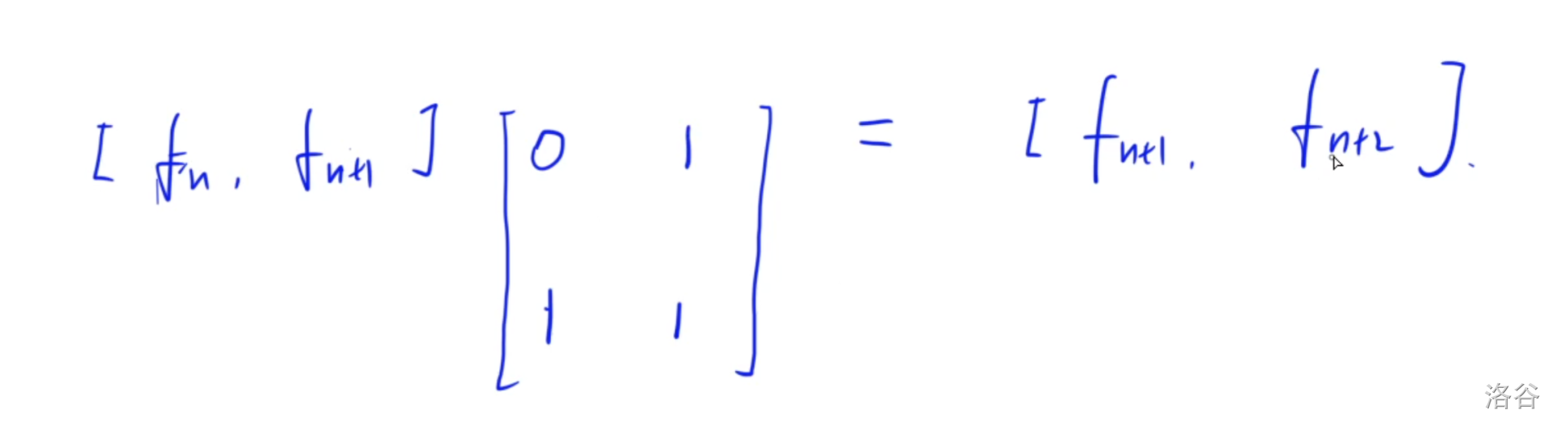
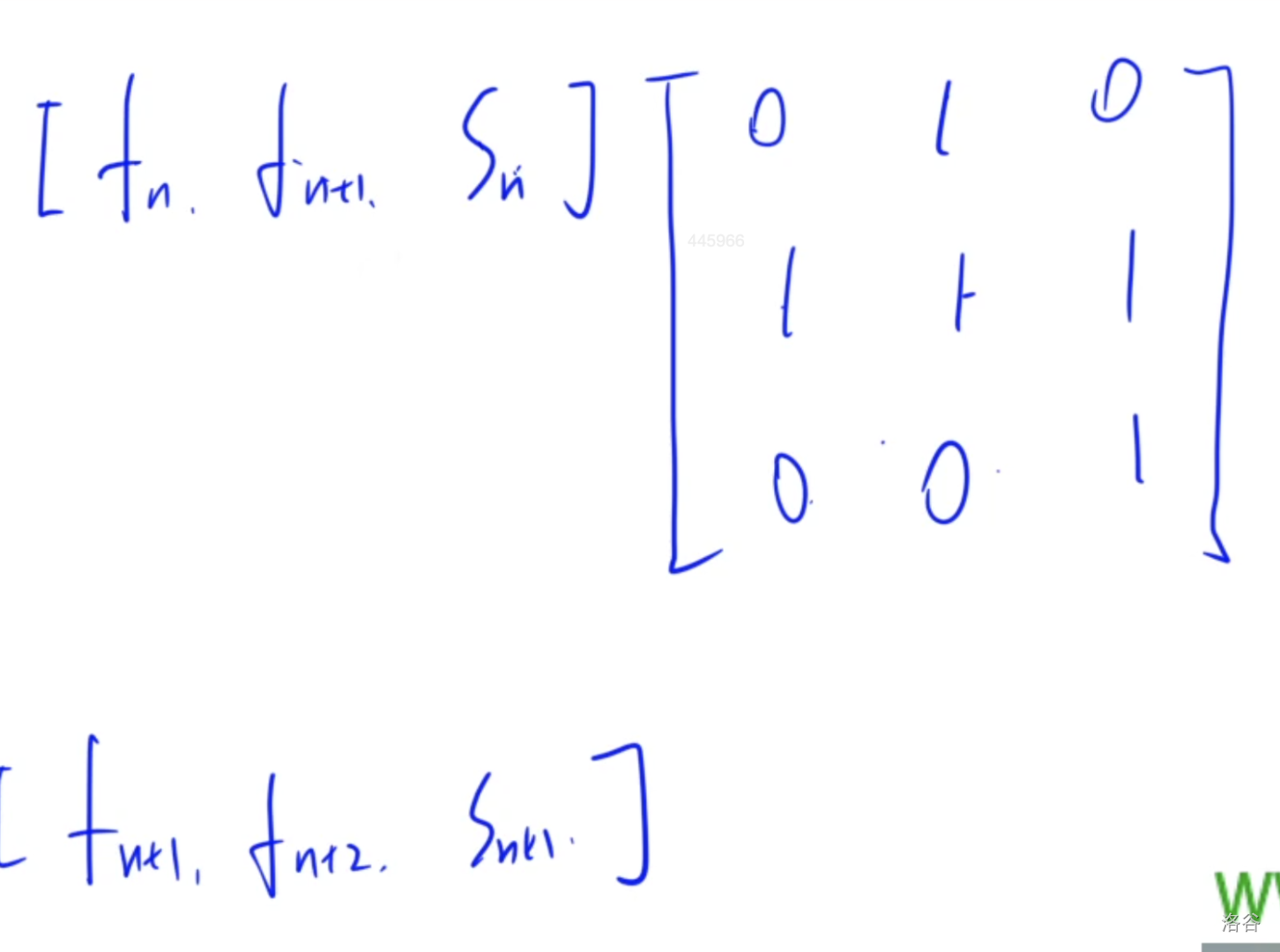
因为矩阵乘法具有结合律但是没有交换律, 因此能用快速幂计算
要求保证第一个矩阵的行数和第二个矩阵的列数相等
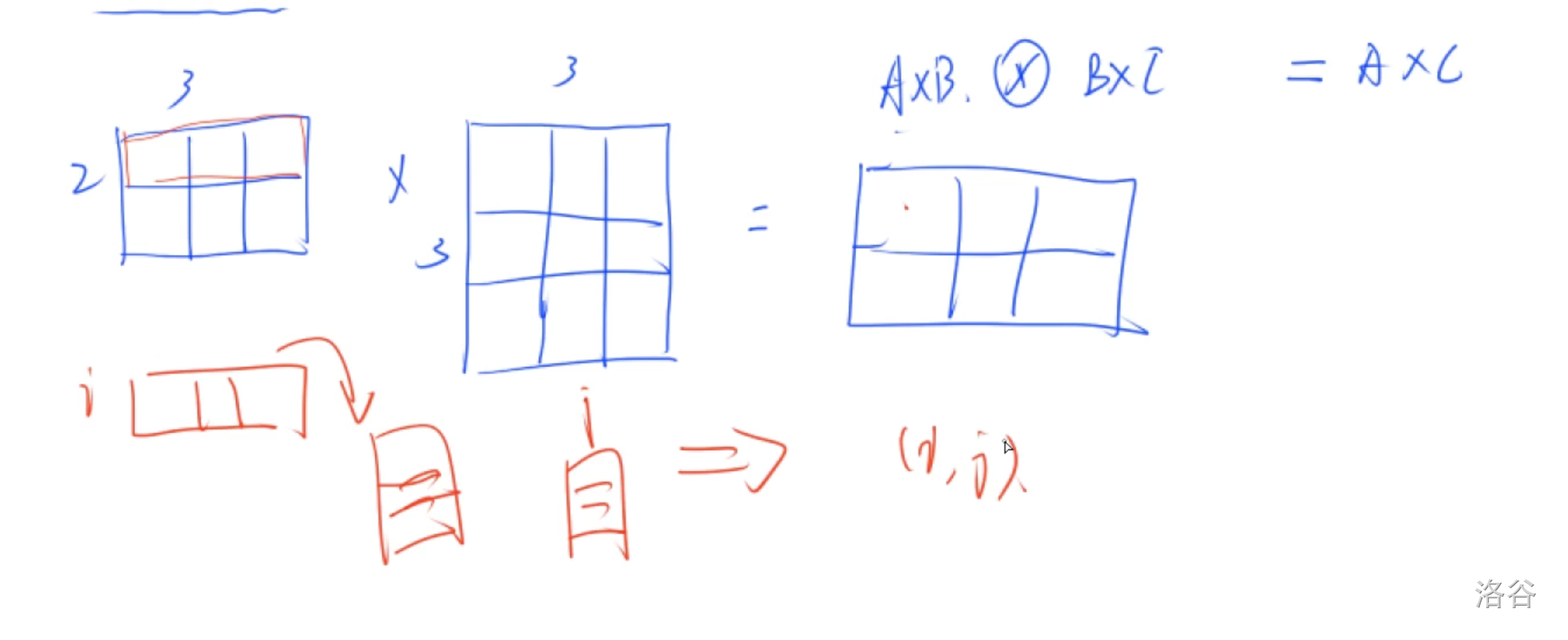
第一个矩阵的第 i i i行和第 j j j个矩阵的第 j j j列相乘得到结果矩阵的 ( i , j ) (i,j) (i,j)位置的值
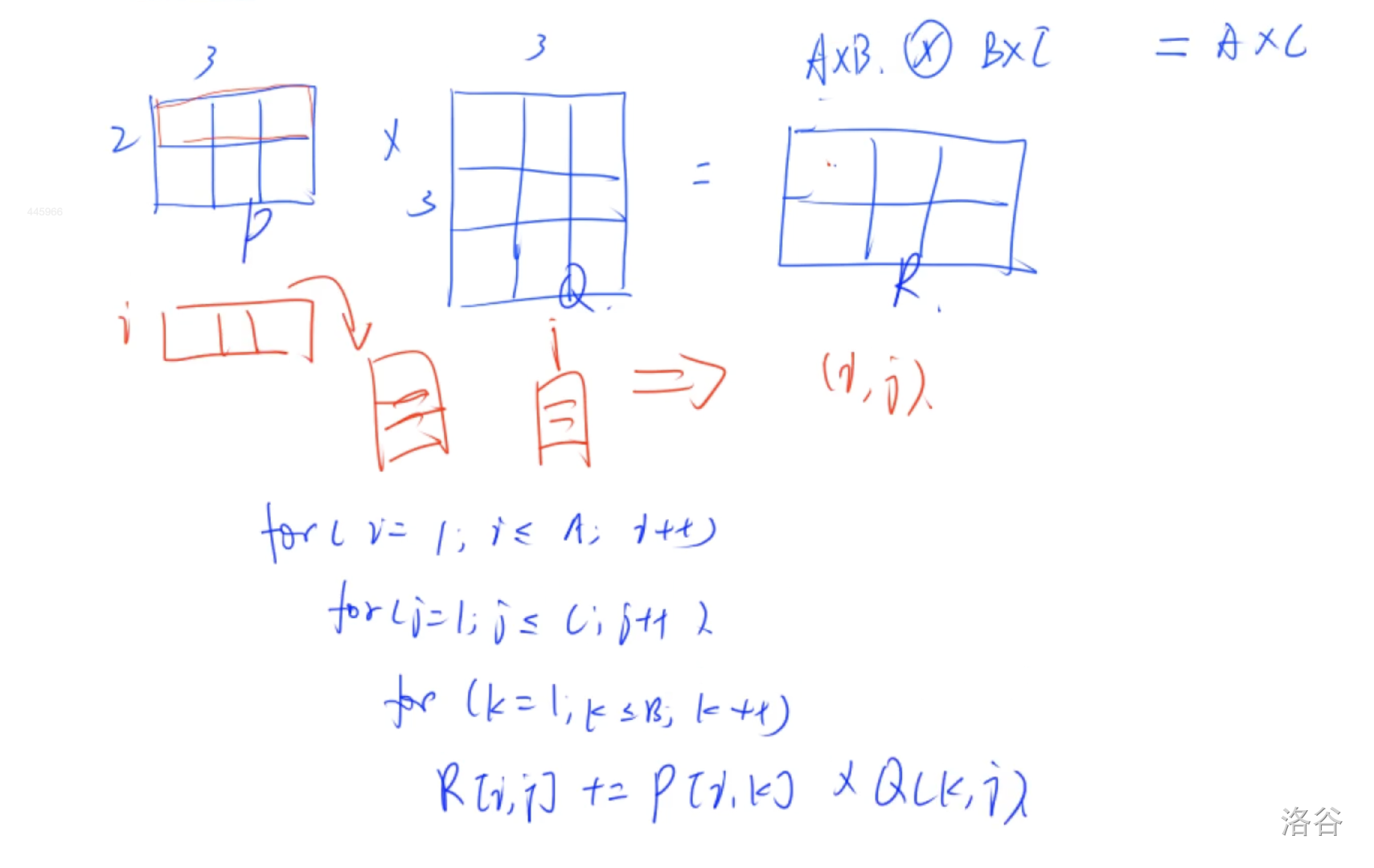
- 枚举结果矩阵的每一行每一列
- 枚举 B B B的位置
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 3;
int n, mod;
void mul(int res[][N], int a[][N], int b[][N]) {
static int tmp[N][N];
memset(tmp, 0, sizeof tmp);
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
for (int k = 0; k < N; ++k) {
tmp[i][j] = (tmp[i][j] + (LL) a[i][k] * b[k][j]) % mod;
}
}
}
memcpy(res, tmp, sizeof tmp);
}
int main() {
cin >> n >> mod;
int f[3][3] = {
1, 1, 1};
// 系数矩阵
int m[3][3] = {
{
0, 1, 0},
{
1, 1, 1},
{
0, 0, 1}};
n--;
// 快速幂求矩阵乘法
while (n) {
if (n & 1) mul(f, f, m);
mul(m, m, m);
n >>= 1;
}
cout << f[0][2] % mod << endl;
return 0;
}

为了写代码的方便, 可以将一维矩阵扩充成系数矩阵大小, 但是只有第一行有值
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 4;
int n, mod;
void mul(LL res[][N], LL a[][N], LL b[][N]) {
static LL tmp[N][N];
memset(tmp, 0, sizeof tmp);
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
for (int k = 0; k < N; ++k) {
tmp[i][j] = (tmp[i][j] + (LL) a[i][k] * b[k][j]) % mod;
}
}
}
memcpy(res, tmp, sizeof tmp);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> mod;
// fn, fn+1, sn, pn
LL f[4][4] = {
1, 1, 1, 0};
LL m[4][4] = {
{
0, 1, 0, 0},
{
1, 1, 1, 0},
{
0, 0, 1, 1},
{
0, 0, 0, 1}};
int k = n - 1;
while (k) {
if (k & 1) mul(f, f, m);
mul(m, m, m);
k >>= 1;
}
LL res = n * f[0][2] - f[0][3];
cout << (res % mod + mod) % mod << endl;
return 0;
}
矩阵乘法优化状态机DP

#include <iostream>
#include <cstring>
using namespace std;
const int N = 25;
int n, len, mod;
char str[N];
int _next[N], m[N][N];
void mul(int res[][N], int a[][N], int b[][N]) {
static int tmp[N][N];
memset(tmp, 0, sizeof tmp);
for (int i = 0; i < len; ++i) {
for (int j = 0; j < len; ++j) {
for (int k = 0; k < len; ++k) {
tmp[i][j] = (tmp[i][j] + a[i][k] * b[k][j]) % mod;
}
}
}
memcpy(res, tmp, sizeof tmp);
}
int quick_pow(int k) {
int f[N][N] = {
1};
while (k) {
if (k & 1) mul(f, f, m);
mul(m, m, m);
k >>= 1;
}
int res = 0;
// 枚举KMP状态机的每个位置
for (int i = 0; i < len; ++i) res = (res + f[0][i]) % mod;
return res;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> len >> mod;
cin >> str + 1;
for (int i = 2, j = 0; i <= len; ++i) {
while (j && str[j + 1] != str[i]) j = _next[j];
if (str[j + 1] == str[i]) j++;
_next[i] = j;
}
for (int i = 0; i < len; ++i) {
for (char c = '0'; c <= '9'; ++c) {
int k = i;
while (k && str[k + 1] != c) k = _next[k];
if (str[k + 1] == c) k++;
if (k < len) m[i][k]++;
}
}
cout << quick_pow(n) << endl;
return 0;
}
组合计数
- 加法原理
- 乘法原理
- 组合数
- 排列数
- 容斥原理
递推法求组合数
数字范围小, 但是询问次数多
1 ≤ n ≤ 10000 , 1 ≤ b ≤ a ≤ 2000 1≤n≤10000, 1≤b≤a≤2000 1≤n≤10000,1≤b≤a≤2000
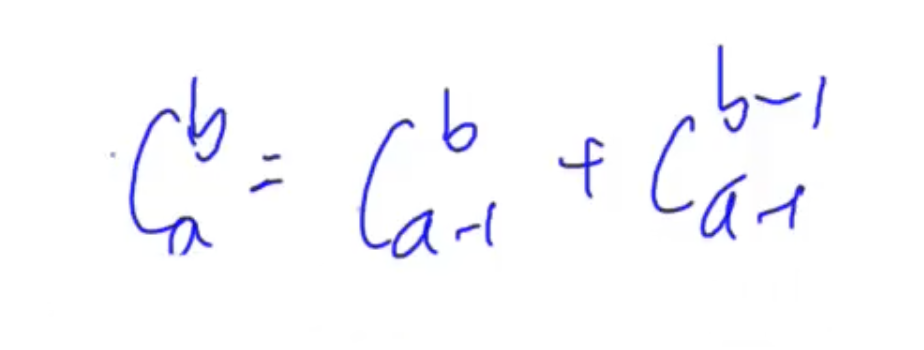
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 2010, MOD = 1e9 + 7;
int a, b, n;
int f[N][N];
int main() {
cin >> n;
for (int i = 0; i < N; ++i) {
for (int j = 0; j <= i; ++j) {
if (!j) f[i][j] = 1;
else f[i][j] = (f[i - 1][j] + f[i - 1][j - 1]) % MOD;
}
}
while (n--) {
cin >> a >> b;
cout << f[a][b] << endl;
}
return 0;
}
时间复杂度: O ( a × b ) O(a \times b) O(a×b)
注意: 枚举 j j j的时候要小于等于 i i i, 正因为这样 i = 0 i = 0 i=0的情况被直接跳过不会发生段错误
预处理法求组合数
数字范围大, 但是询问次数不大
1 ≤ n ≤ 10000 , 1 ≤ b ≤ a ≤ 1 0 5 1≤n≤10000 , 1≤b≤a≤10^5 1≤n≤10000,1≤b≤a≤105
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10, MOD = 1e9 + 7;
int fact[N], infact[N];
LL quick_pow(int val, int k) {
LL res = 1;
while (k) {
if (k & 1) res = (LL) res * val % MOD;
val = (LL) val * val % MOD;
k >>= 1;
}
return res;
}
LL C(int a, int b) {
LL res = (LL) fact[a] % MOD * infact[a - b] % MOD * infact[b] % MOD;
return res;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n;
cin >> n;
// 预处理阶乘和阶乘的逆元
fact[0] = infact[0] = 1;
for (int i = 1; i < N; ++i) {
fact[i] = (LL) fact[i - 1] * i % MOD;
infact[i] = (LL) infact[i - 1] * quick_pow(i, MOD - 2) % MOD;
}
while (n--) {
int a, b;
cin >> a >> b;
cout << C(a, b) << endl;
}
return 0;
}
时间复杂度: O ( n log n ) O(n\log{}{n}) O(nlogn)
Lucas定理求组合数
询问个数非常小, 但是数据范围超级大, 但是模数不能大最好是质数
1 ≤ n ≤ 20 , 1 ≤ b ≤ a ≤ 1 0 1 8 , 1 ≤ p ≤ 1 0 5 , 1≤n≤20 , 1≤b≤a≤10^18 , 1≤p≤10^5 , 1≤n≤20,1≤b≤a≤1018,1≤p≤105,

时间复杂度: O ( p log n p ) O(p\log_{n}{p}) O(plognp)
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int fact[N], infact[N];
int mod;
LL quick_pow(LL val, LL k) {
LL res = 1 % mod;
while (k) {
if (k & 1) res = (LL) res * val % mod;
val = (LL) val * val % mod;
k >>= 1;
}
return res;
}
LL C(int a, int b) {
if (b > a) return 0;
LL res = (LL) fact[a] * infact[a - b] % mod * infact[b] % mod;;
return res;
}
LL lucas(LL a, LL b) {
if (b == 0) return 1;
return C(a % mod, b % mod) * lucas(a / mod, b / mod) % mod;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n;
cin >> n;
while (n--) {
LL a, b;
cin >> a >> b >> mod;
fact[0] = infact[0] = 1;
for (int i = 1; i < N; ++i) {
fact[i] = (LL) fact[i - 1] * i % mod;
infact[i] = (LL) infact[i - 1] * quick_pow(i, mod - 2) % mod;
}
cout << lucas(a, b) << endl;
}
return 0;
}
分解质因数 + 高精度计算组合数
没有模数, 直接计算组合数, 需要结合高精度乘法
如何求 n ! n! n!的质数的个数?
参考阶乘分解
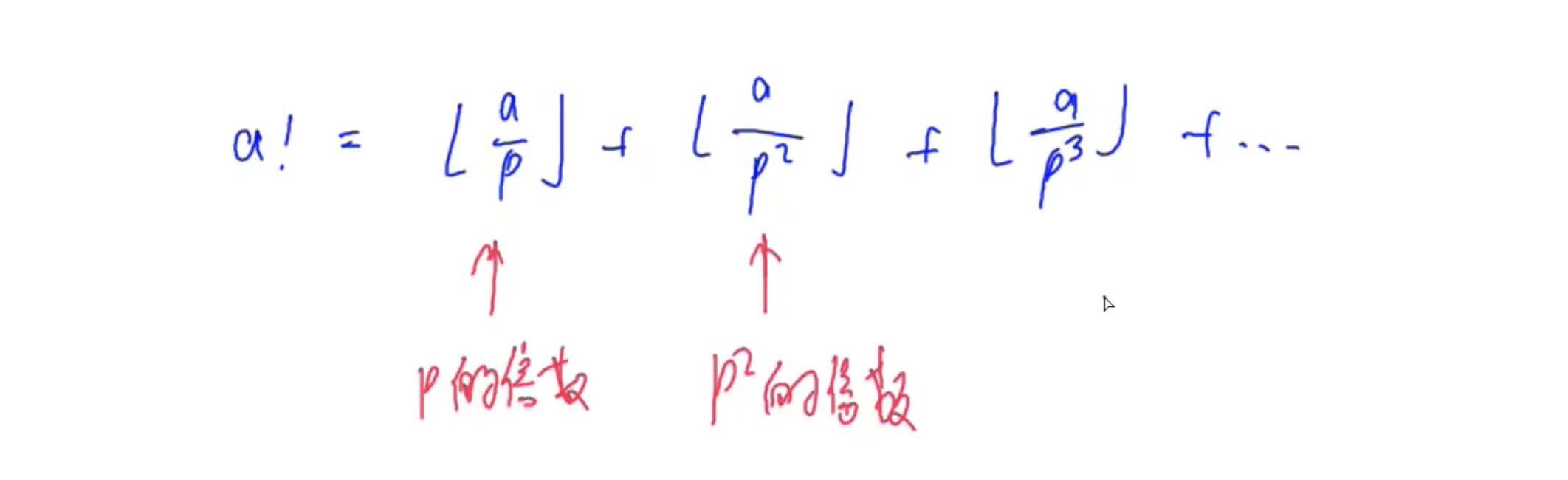
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 5010;
int a, b;
int primes[N], cnt;
bool vis[N];
int s[N];
void init(int val) {
for (int i = 2; i <= val; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] <= val; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
// 计算阶乘有多少个p
int get(int val, int p) {
int res = 0;
while (val) {
res += val / p;
val /= p;
}
return res;
}
void mul(vector<int> &res, int val) {
int c = 0;
for (int i = 0; i < res.size(); ++i) {
c += res[i] * val;
res[i] = c % 10;
c /= 10;
}
while (c) {
res.push_back(c % 10);
c /= 10;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> a >> b;
init(a);
for (int i = 0; i < cnt; ++i) {
int p = primes[i];
s[i] = get(a, p) - get(a - b, p) - get(b, p);
}
vector<int> res;
res.push_back(1);
// 枚举所有质数
for (int i = 0; i < cnt; ++i) {
for (int j = 1; j <= s[i]; ++j) {
mul(res, primes[i]);
}
}
while (res.size() > 0 && res.back() == 0) res.pop_back();
while (res.size()) {
cout << res.back();
res.pop_back();
}
cout << "\n";
return 0;
}
递推法求组合计数问题
题目大意: 当前位置是 1 1 1, 当前位置到前一个位置 1 1 1的距离不能小于等于 k k k
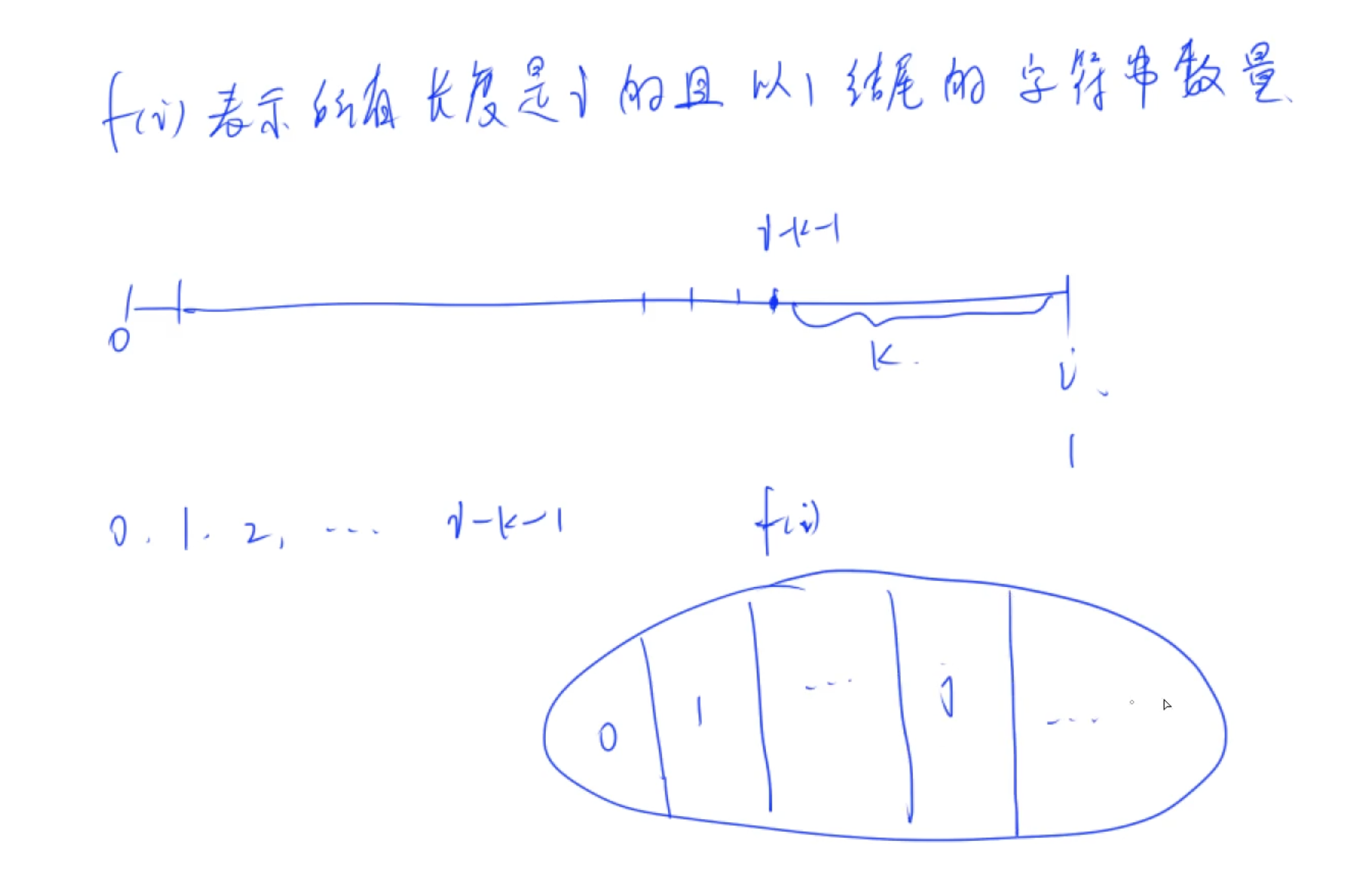
将集合按照上一个 1 1 1的位置进行分类
最坏情况下时间复杂度是 O ( n 2 ) O(n^2) O(n2), 使用前缀和进行优化到 O ( n ) O(n) O(n)
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10, MOD = 5000011;
int f[N], s[N];
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n, k;
cin >> n >> k;
f[0] = s[0] = 1;
// 递推res
for (int i = 1; i < n; ++i) {
// 因为i - k - 1可能是负数, 因此当左边界是负数时, 将左边界设置为0
f[i] = s[max(i - k - 1, 0)];
// 计算前缀和
s[i] = (s[i - 1] + f[i]) % MOD;
}
cout << s[n] << endl;
return 0;
}
排列组合问题之方程的解
关于方程的右侧使用后快速幂解决

方程解的数量用隔板法进行计算, 假如三个未知数
那就在小球中放两个隔板, 将整个集合分为三个部分, 每个部分代表一个未知数$C_{n - 1}^{k - 1} $
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 150;
int k, x;
int f[1000][100][N];
int quick_pow(int val, int k, int mod) {
int res = 1;
while (k) {
if (k & 1) res = res * val % mod;
val = val * val % mod;
k >>= 1;
}
return res;
}
void add(int res[], int a[], int b[]) {
int c = 0;
for (int i = 0; i < N; ++i) {
c += a[i] + b[i];
res[i] = c % 10;
c /= 10;
}
}
int main() {
cin >> k >> x;
int n = quick_pow(x % 1000, x, 1000);
// 计算C(n - 1, k - 1)
for (int i = 0; i < n; ++i) {
for (int j = 0; j <= i && j < k; ++j) {
if (!j) f[i][j][0] = 1;
else add(f[i][j], f[i - 1][j], f[i - 1][j - 1]);
}
}
if (!n) cout << 0 << endl;
else {
int i = N - 1;
// 去除前导零
while (!f[n - 1][k - 1][i]) i--;
// 输出结果的每一位
while (i >= 0) cout << f[n - 1][k - 1][i--];
}
return 0;
}
组合数排列数求不规则图形

如果是规则图形
- 首先先从 n n n行中选择 k k k行, 保证不在同一行
- 然后考虑列, 第一行的车有 m m m中选择, 第二行的车有 k − 1 k - 1 k−1种选择…
将问题拆分成两个规则图形, 因为不知道每个规则图形中放置几个车, 因此可以枚举车在两个规则图形中的数量

对于下面的矩形, 因为上面已经用了 i i i列, 因此是从 a + c − i a + c - i a+c−i中有顺序的选出 k − i k - i k−i个数字
因为组合数排列数都用到阶乘, 因此可以预处理阶乘

#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 2010, MOD = 100003;
int fact[N], infact[N];
LL quick_pow(LL val, LL k) {
LL res = 1;
while (k) {
if (k & 1) res = res * val % MOD;
val = val * val % MOD;
k >>= 1;
}
return res;
}
LL C(int a, int b) {
if (b > a) return 0;
LL res = (LL) fact[a] * infact[a - b] % MOD * infact[b] % MOD;
return res;
}
LL A(int a, int b) {
if (b > a) return 0;
LL res = (LL) fact[a] * infact[a - b] % MOD;
return res;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int a, b, c, d, k;
cin >> a >> b >> c >> d >> k;
// 求阶乘和阶乘的逆元
fact[0] = infact[0] = 1;
for (int i = 1; i < N; ++i) {
fact[i] = (LL) fact[i - 1] * i % MOD;
// 因为MOD是质数, 因此使用费马小定理计算逆元
infact[i] = (LL) infact[i - 1] * quick_pow(i, MOD - 2) % MOD;
}
LL res = 0;
// 枚举上面矩形放置的车的数量
for (int i = 0; i <= k; ++i) {
LL up = (LL) C(b, i) * A(a, i) % MOD;
LL down = (LL) C(d, k - i) * A(a + c - i, k - i) % MOD;
res = (res + up * down % MOD) % MOD;
}
cout << res % MOD << endl;
return 0;
}
注意: 在计算组合数和排列数时, 一定要添加边界条件
组合数之网格求三角形数量
因为正向枚举所有点的位置不好计算, 因此可以采用补集的思想, 减去所有不合法情况
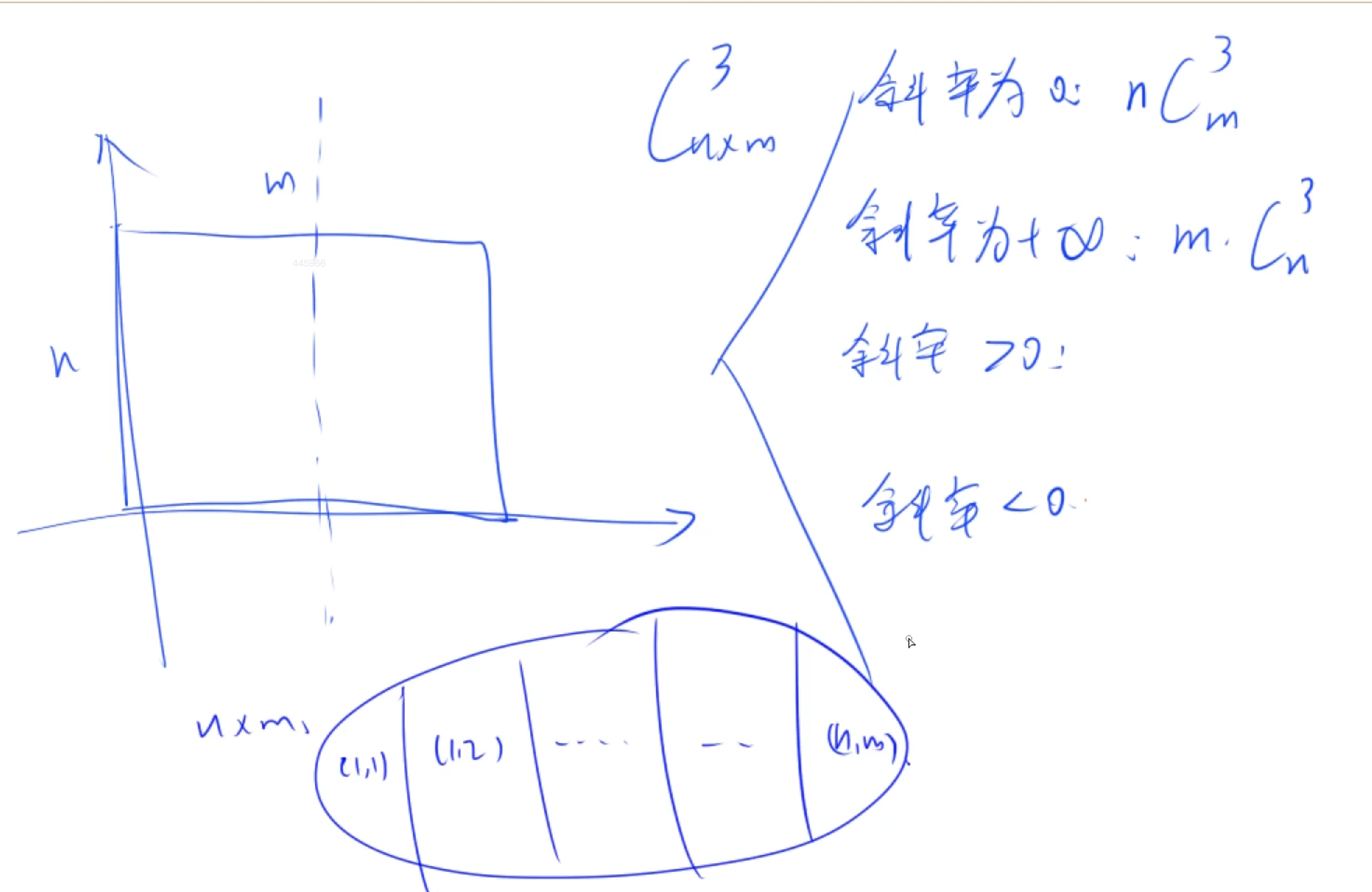
- 对于斜率大于 0 0 0的点, 将直线按照横纵坐标差值进行划分, 也就是在矩形中枚举直角三角形, 直角三角形的斜边就是我们要求的线段
- 对于斜边上的两个端点是确定的, 因此需要知道两个端点中在整点的点的数量, 也就是枚举第三个点
- g c d ( i , j ) − 1 gcd(i, j) - 1 gcd(i,j)−1就是目标值, i , j i, j i,j是横纵坐标差值
为什么是 g c d ( i , j ) gcd(i, j) gcd(i,j)能代表线段上在整点的数量?
- 首先将问题转化为简单形式, 将左下角端点移动到原点, 设右上角端点的坐标是 ( Δ x , Δ y ) (Δx,Δy) (Δx,Δy), 设最大公约数是 d d d
- 那么线段上的点的坐标就能表示为 ( k Δ x d , k Δ y d ) \left( \frac{k \Delta x}{d}, \frac{k \Delta y}{d} \right) (dkΔx,dkΔy), 其中 k k k取值 0 , 1 , . . . , d 0, 1, ..., d 0,1,...,d
- 算上端点, 一共 d + 1 d + 1 d+1的数
为什么是最大公约数, 而不是任意一个公约数?
因为只有最大公约数求出的点的坐标能够代表最小步长, 如果是任意一个公约数, 可能遗漏某些点
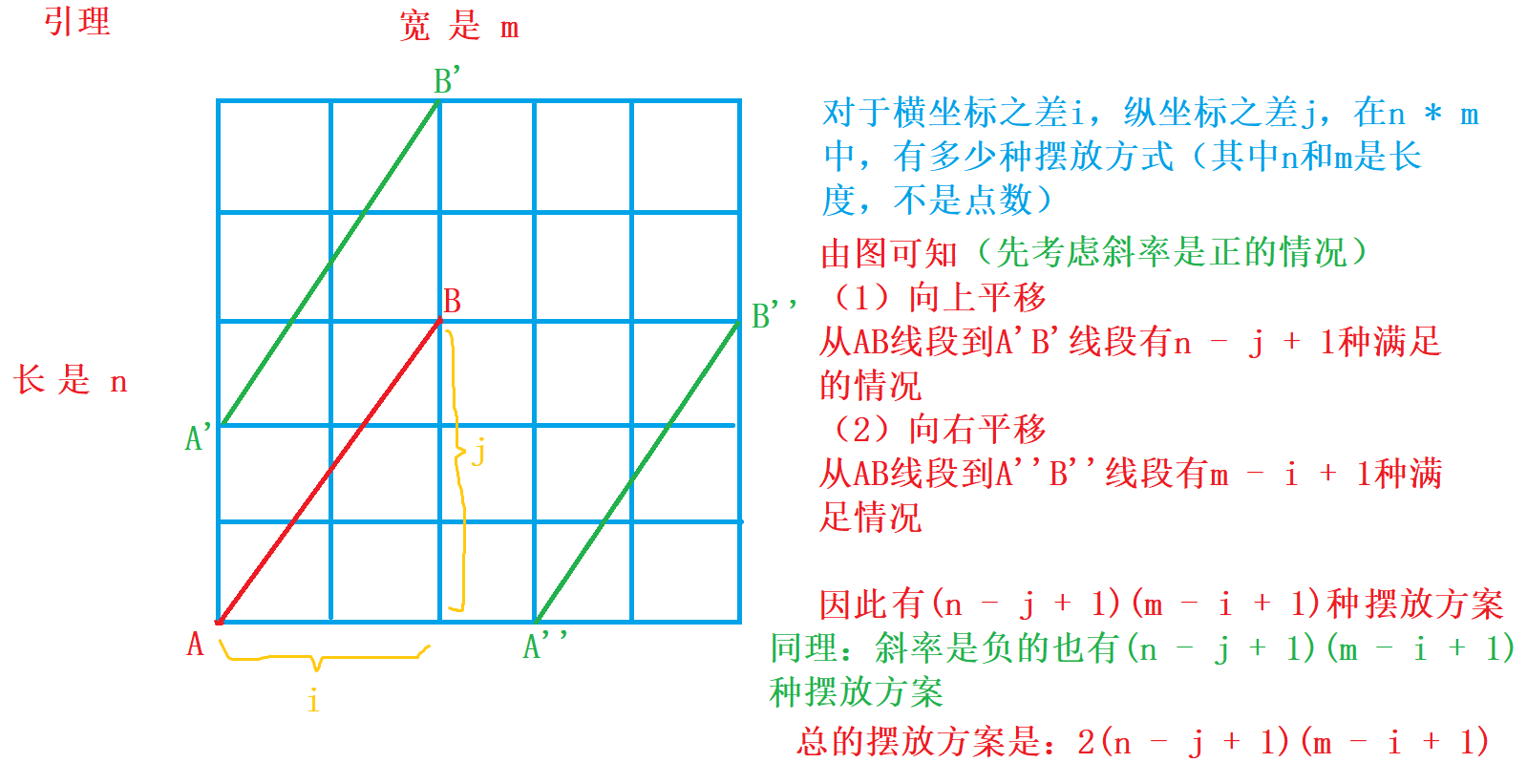
图片引用自小呆呆
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
int gcd(int a, int b) {
return b ? gcd(b, a % b) : a;
}
LL C(int n) {
return (LL) n * (n - 1) * (n - 2) / 6;
}
int main() {
int row, col;
cin >> row >> col;
row++, col++;
// 所有情况减去斜率为0和斜率是正无穷的情况
LL res = C(row * col) - (LL)row * C(col) - (LL) col * C(row);
// 枚举横坐标差值和纵坐标差值
for (int i = 1; i <= row; ++i) {
for (int j = 1; j <= col; ++j) {
// 后面两项是枚举斜边两个端点的取值情况
res -= 2ll * (gcd(i, j) - 1) * (row - i) * (col - j);
}
}
cout << res << endl;
return 0;
}
隔板法求不等式解的个数

将原来的范围进行映射, 然后进行差分拆解, 将问题转化为求不等式的解的个数
再将 x i x_i xi映射到 y i = x i + 1 y_i = x_i + 1 yi=xi+1, 这样保证每个解都是大于等于 1 1 1的
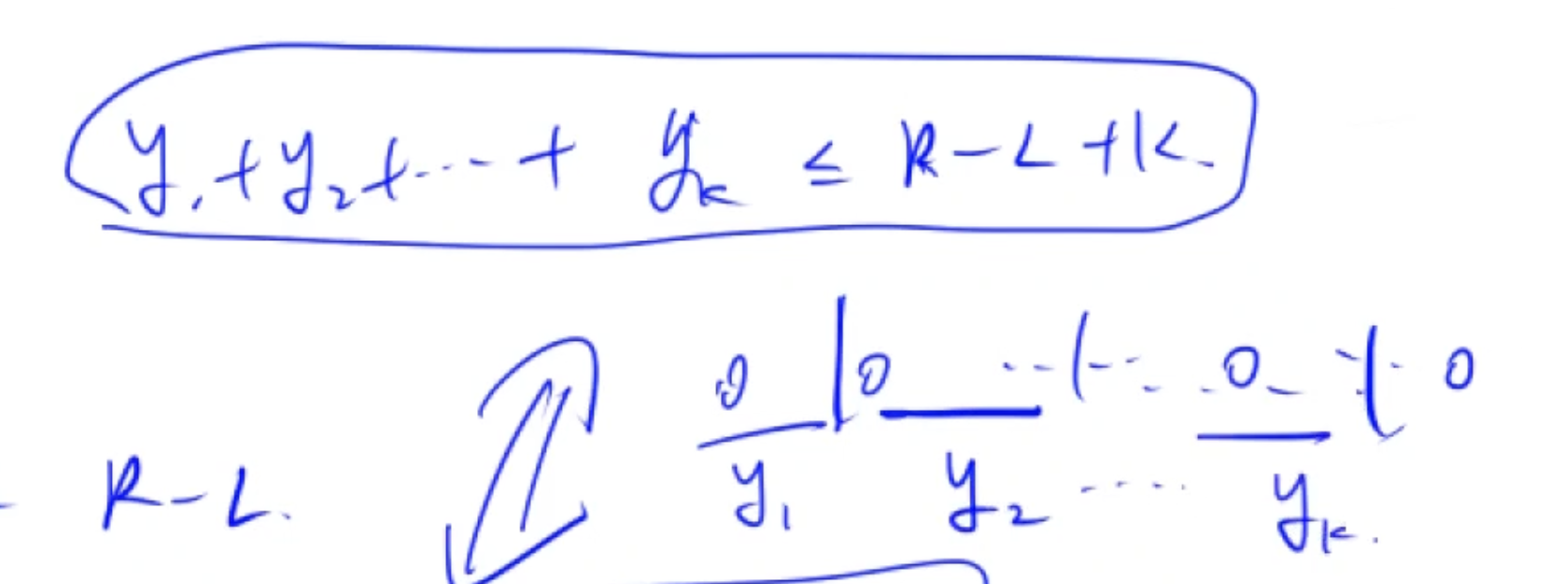
因为是不等式因此放置 k k k个隔板, 如果是等式放置 k − 1 k - 1 k−1个板子
因为枚举 k k k会超时, 因此考虑将原式进行化简

依据组合数递推式进行化简
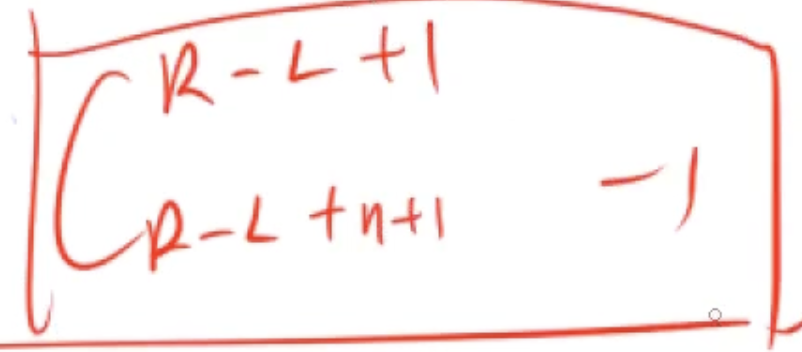
因为数据范围很大, 但是模数很小, 因此使用 l u c a s lucas lucas定理进行计算组合数
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 1e6 + 10, MOD = 1e6 + 3;
int cases;
int n, l, r;
int fact[N], infact[N];
int quick_pow(int val, int k) {
int res = 1;
while (k) {
if (k & 1) res = (LL) res * val % MOD;
val = (LL) val * val % MOD;
k >>= 1;
}
return res;
}
// 处理所有阶乘和阶乘的逆元
void init() {
fact[0] = infact[0] = 1;
for (int i = 1; i < N; ++i) {
fact[i] = (LL) fact[i - 1] * i % MOD;
infact[i] = (LL) infact[i - 1] * quick_pow(i, MOD - 2) % MOD;
}
}
int C(int a, int b) {
if (a < b) return 0;
return (LL) fact[a] * infact[a - b] % MOD * infact[b] % MOD;
}
int lucas(int a, int b) {
if (a < MOD && b < MOD) return C(a, b);
return (LL) C(a % MOD, b % MOD) % MOD * lucas(a / MOD, b / MOD) % MOD;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
init();
cin >> cases;
while (cases--) {
cin >> n >> l >> r;
int res = (lucas(r - l + n + 1, r - l + 1) - 1 + MOD) % MOD;
cout << res << endl;
}
return 0;
}
因为数量一定是整数, 因此在输出最终结果的时候一定要计算正余数
卡特兰序列
求满足任意前缀中 0 0 0的个数不少于 1 1 1的个数的序列的数量
将问题转化为从原点走路径的问题
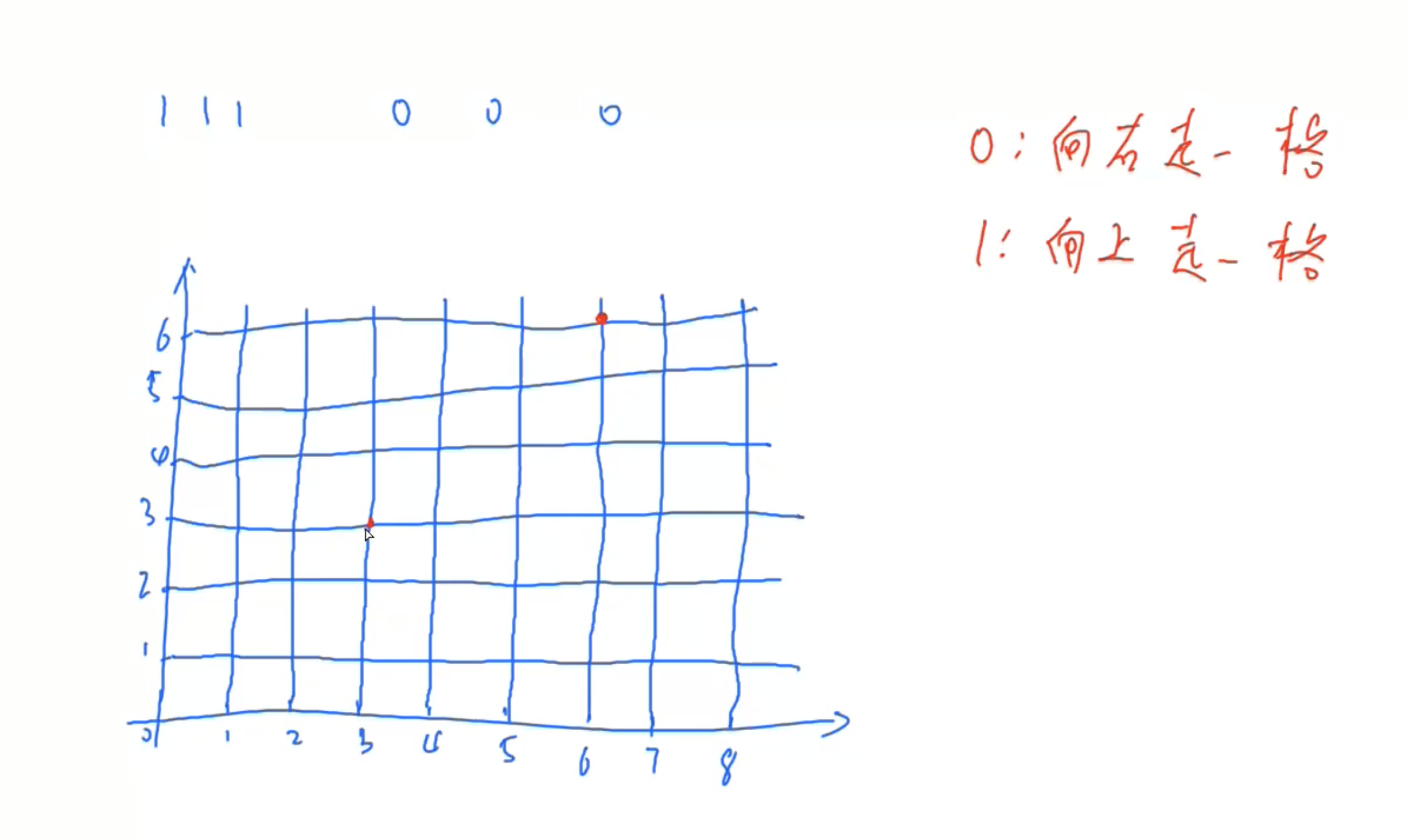
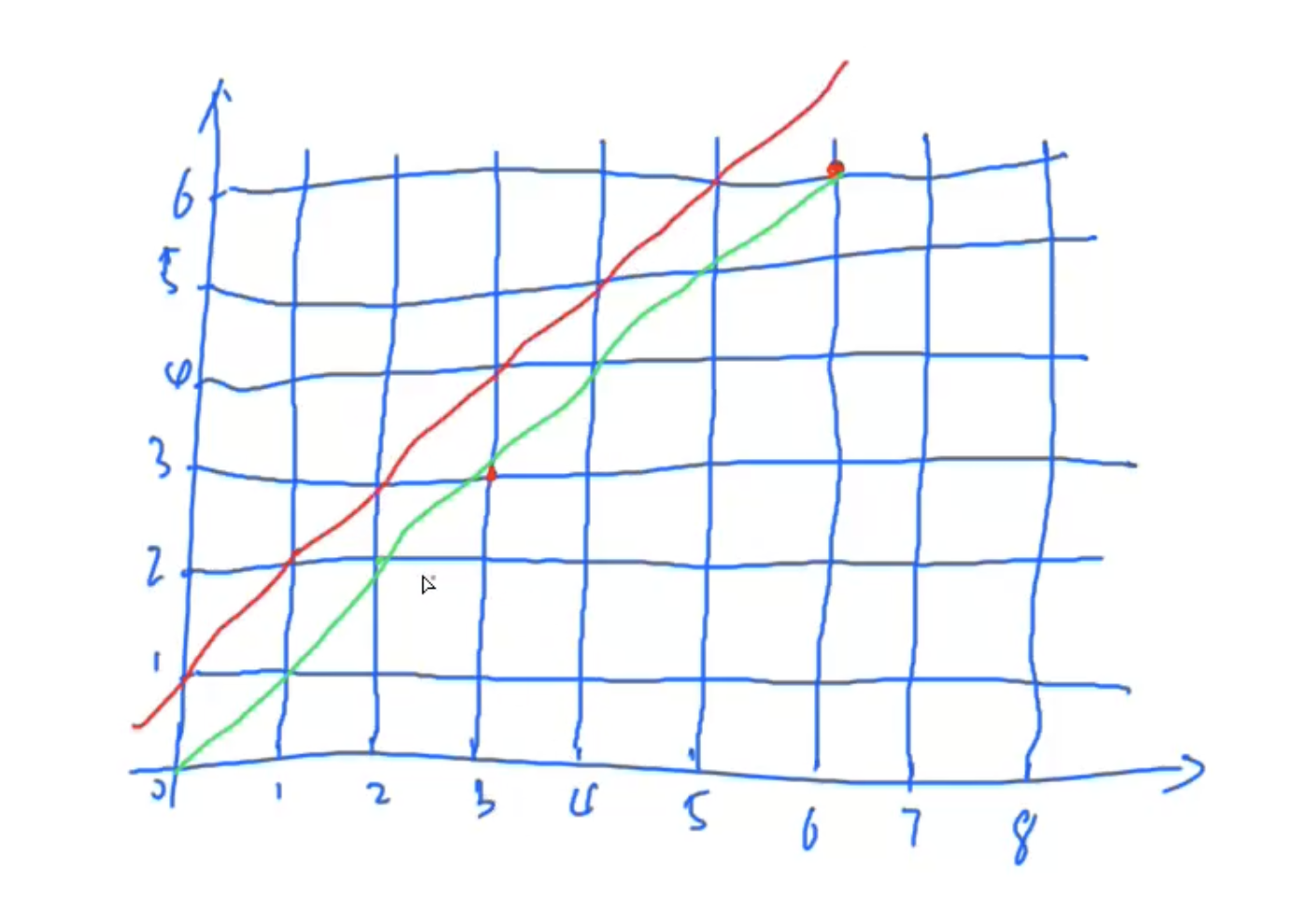
任意一条路径不能走到红颜色线上!
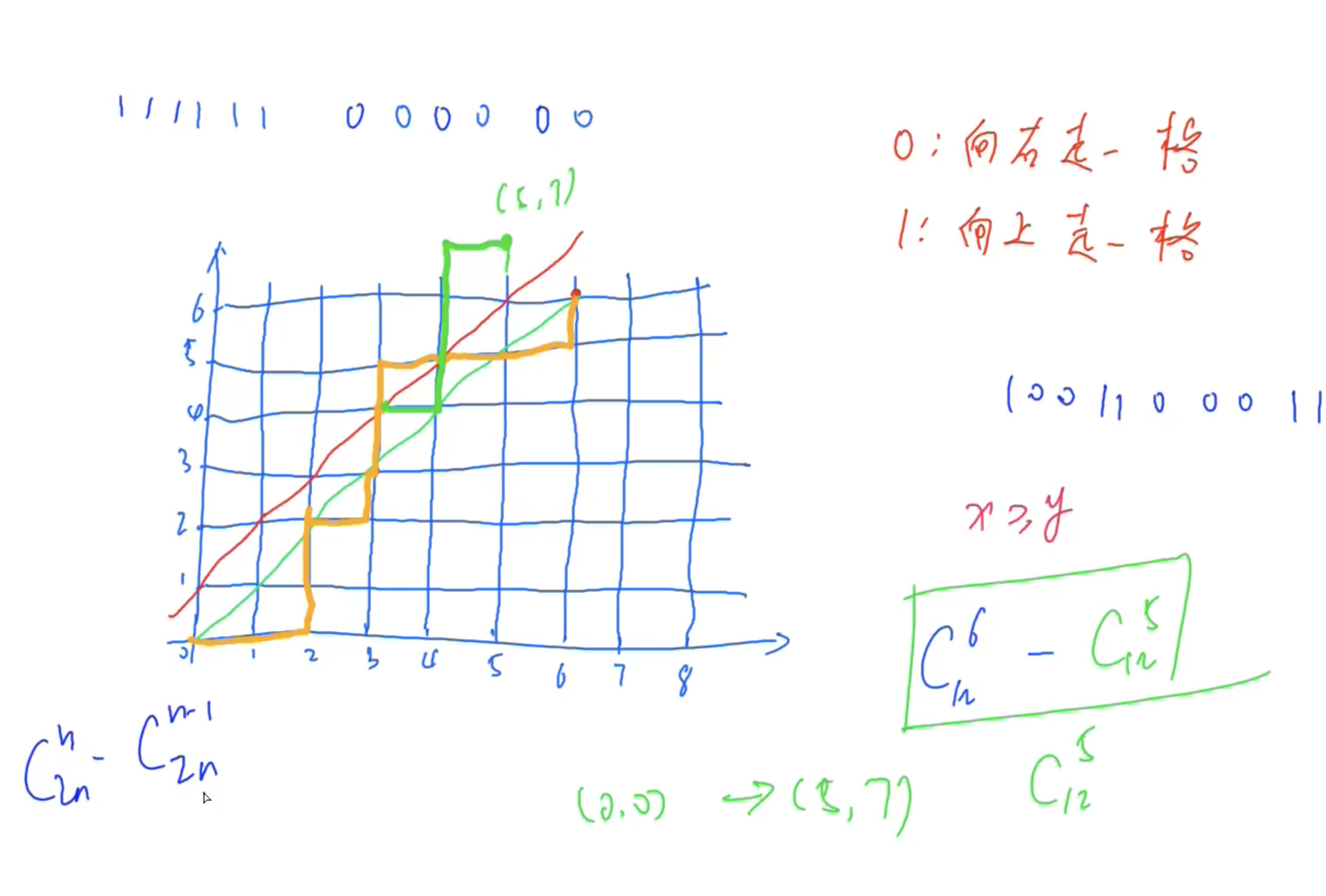
再将卡特兰数进行转化, C 2 n n n + 1 \frac{C_{2n}^{n}}{n + 1} n+1C2nn
- 卡特兰数递推式, f ( n ) = f ( 1 ) × ( n − 1 ) + f ( 2 ) × ( n − 2 ) + . . . f(n) = f(1) \times (n - 1) + f(2) \times (n - 2) + ... f(n)=f(1)×(n−1)+f(2)×(n−2)+...
- 挖掘卡特兰数性质, 任意前缀里面某种东西的个数不能少于另一种东西的个数
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int MOD = 1e9 + 7;
int quick_pow(int val, int k) {
int res = 1;
while (k) {
if (k & 1) res = (LL) res * val % MOD;
val = (LL) val * val % MOD;
k >>= 1;
}
return res;
}
int C(int a, int b) {
if (a < b) return 0;
int val1 = 1;
for (int i = a; i >= a - b + 1; --i) {
val1 = (LL) val1 * i % MOD;
}
// 计算b阶乘的逆元
int val2 = 1;
for (int i = b; i >= 1; --i) {
val2 = (LL) val2 * quick_pow(i, MOD - 2) % MOD;
}
return (LL) val1 * val2 % MOD;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n;
cin >> n;
int res = (LL) C(2 * n, n) * quick_pow(n + 1, MOD - 2) % MOD;
cout << (res % MOD + MOD) % MOD << endl;
return 0;
}
组合数学之卡特兰数
因为此题没有模数, 因此需要第四种求组合数的方法, 也就是分解质因数 + 阶乘分解 + 高精度
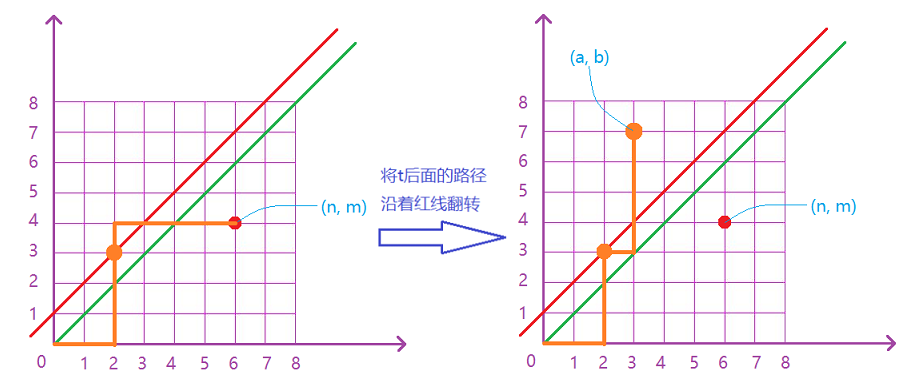
图片引用自文章链接
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 10010;
int row, col;
int primes[N], cnt;
bool vis[N];
void init() {
for (int i = 2; i <= N - 1; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] <= N - 1; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
int get(int val, int p) {
int res = 0;
while (val) res += val / p, val /= p;
return res;
}
//高精度乘法
void mul(vector<int> &res, int val) {
int c = 0;
for (int i = 0; i < res.size(); ++i) {
c += res[i] * val;
res[i] = c % 10;
c /= 10;
}
while (c) res.push_back(c % 10), c /= 10;
}
vector<int> C(int a, int b) {
vector<int> res;
if (a < b) return res;
res.push_back(1);
// 记录每个质数出现的次数
int tmp[N] = {
0};
for (int i = 0; i < cnt; ++i) {
int p = primes[i];
tmp[i] = get(a, p) - get(a - b, p) - get(b, p);
}
// 计算高精度乘法
for (int i = 0; i < cnt; ++i) {
for (int j = 0; j < tmp[i]; ++j) {
mul(res, primes[i]);
}
}
return res;
}
//高精度减法
void sub(vector<int> &res, vector<int> &val) {
int c = 0;
for (int i = 0; i < res.size(); ++i) {
int tmp = res[i] - (i < val.size() ? val[i] : 0) - c;
if (tmp < 0) {
res[i] = tmp + 10;
c = 1;
}
else res[i] = tmp, c = 0;
}
while (res.size() > 1 && res.back() == 0) res.pop_back();
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
init();
cin >> row >> col;
vector<int> res = C(row + col, row);
vector<int> val = C(row + col, col - 1);
sub(res, val);
for (int i = res.size() - 1; i >= 0; --i) cout << res[i];
cout << "\n";
return 0;
}

如果发现数列的第三项是 5 5 5, 大概率是卡特兰序列
对于当前位置是偶数项, 必须满足前面数字中奇数项的个数不能小于偶数项的个数, 如果奇数项个数小于偶数项个数, 必然至少存在某个奇数项是空的, 一定会从当前偶数位置的后面取值, 因为相邻两项的左侧奇数项要求小于等于偶数项, 但是奇数项是从当前偶数项后面选择, 因此一定大于前一个偶数项, 矛盾, 因此奇数项数量大于等于偶数项的数量
因此就将问题转化为了卡特兰序列问题, 因为模数比较大, 因此不能用 l u c a s lucas lucas定理
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 2e6 + 10;
int n, mod;
int primes[N], cnt;
bool vis[N];
void init() {
for (int i = 2; i < N; ++i) {
if (!vis[i]) primes[cnt++] = i;
for (int j = 0; i * primes[j] < N; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) break;
}
}
}
int get(int val, int p) {
int res = 0;
while (val) {
res += val / p;
val /= p;
}
return res;
}
int quick_pow(int val, int k) {
int res = 1 % mod;
while (k) {
if (k & 1) res = (LL) res * val % mod;
val = (LL) val * val % mod;
k >>= 1;
}
return res % mod;
}
int C(int a, int b) {
if (a < b) return 0;
int tmp[N] = {
0};
for (int i = 0; i < cnt; ++i) {
int p = primes[i];
tmp[i] = get(a, p) - get(a - b, p) - get(b, p);
}
int res = 1;
for (int i = 0; i < cnt; ++i) {
if (!tmp[i]) continue;
res = (LL) res * quick_pow(primes[i], tmp[i]) % mod;
}
return res;
}
int main() {
init();
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> mod;
int res = C(2 * n, n) - C(2 * n, n - 1);
cout << (res + mod) % mod << endl;
return 0;
}
高斯消元解线性方程组
高斯消元过程
- 枚举每一列
- 为了精度问题, 找到绝对值最大的一行, 也就是找主元
- 交换到最上面
- 将该行的第一个数变为 1 1 1
- 把下面的行的这一列 c c c全部消成 0 0 0
时间复杂度: O ( n 3 ) O(n^ 3) O(n3)
高斯消元解的情况
- 完美阶梯形就是恰好一组解
- 左边没有未知数, 右边非 0 0 0, 无解
- 消完之后不是完美阶梯形 不够 n n n个方程, 有无穷多组解
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
const int N = 110;
const double EPS = 1e-8;
int n;
double f[N][N];
int gauss() {
int row, col;
for (row = col = 0; col < n; ++col) {
int u = row;
for (int i = row + 1; i < n; ++i) {
if (fabs(f[i][col]) > fabs(f[u][col])) u = i;
}
if (fabs(f[u][col]) < EPS) continue;
for (int i = col; i <= n; ++i) swap(f[row][i], f[u][i]);
// 归一化
for (int i = n; i >= col; --i) f[row][i] /= f[row][col];
for (int i = row + 1; i < n; ++i) {
if (fabs(f[i][col]) < EPS) continue;
for (int j = n; j >= col; --j) {
f[i][j] -= f[row][j] * f[i][col];
}
}
row++;
}
if (row < n) {
for (int i = row; i < n; ++i) if (fabs(f[i][n]) > EPS) return 2;
return 1;
}
for (int i = n - 1; i >= 0; --i) {
for (int j = i + 1; j < n; ++j) {
f[i][n] -= f[i][j] * f[j][n];
}
}
return 0;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n + 1; ++j) {
cin >> f[i][j];
}
}
int res = gauss();
if (res == 2) cout << "No solution" << endl;
else if (res == 1) cout << "Infinite group solutions" << endl;
else {
for (int i = 0; i < n; ++i) printf("%.2lf\n", f[i][n]);
}
return 0;
}
高斯消元解线性异或方程组
- 在解决哟异或线性方程组的时候, 异或是不进位的加法, 也可以理解为加法或者减法
- 乘法是与的关系
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 110;
int n;
int f[N][N];
int gauss() {
int row, col;
for (row = col = 0; col < n; ++col) {
int u = row;
for (int i = row; i < n; ++i) {
if (f[i][col]) {
u = i;
break;
}
}
if (f[u][col] == 0) continue;
for (int i = col; i <= n; ++i) swap(f[row][i], f[u][i]);
// 消元
for (int i = row + 1; i < n; ++i) {
if (!f[i][col]) continue;
for (int j = n; j >= col; --j) {
f[i][j] ^= f[row][j] & f[i][col];
}
}
row++;
}
if (row < n) {
for (int i = row; i < n; ++i) if (f[i][n]) return 2;
return 1;
}
for (int i = n - 1; i >= 0; --i) {
for (int j = i + 1; j < n; ++j) {
f[i][n] ^= f[i][j] & f[j][n];
}
}
return 0;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n + 1; ++j) {
cin >> f[i][j];
}
}
int res = gauss();
if (res == 2) cout << "No solution" << "\n";
else if (res == 1) cout << "Multiple sets of solutions" << "\n";
else {
for (int i = 0; i < n; ++i) cout << f[i][n] << "\n";
}
return 0;
}
高斯消元应用
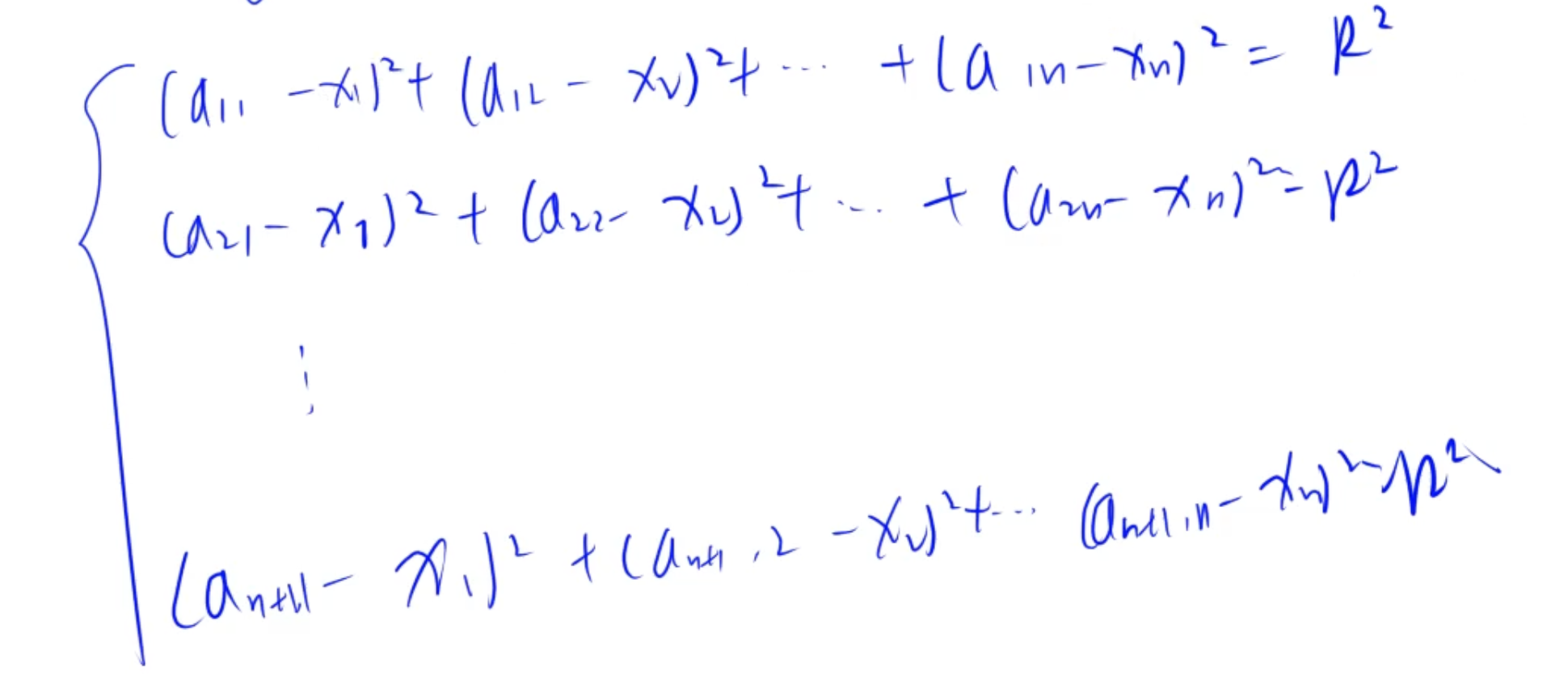
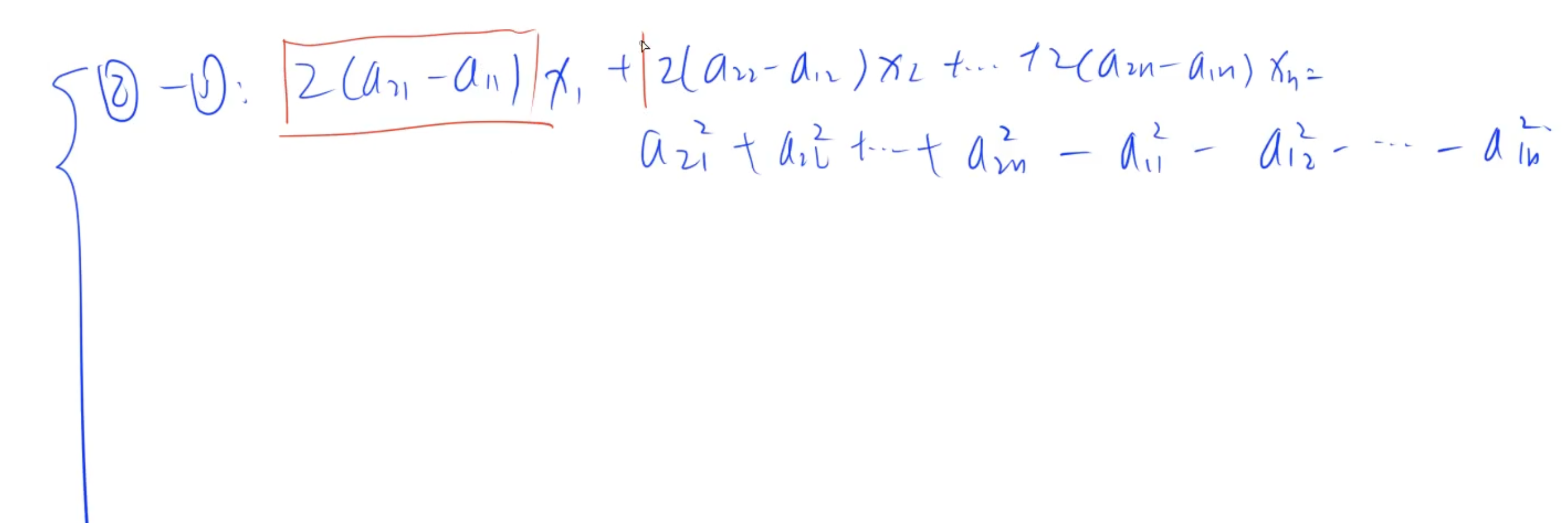
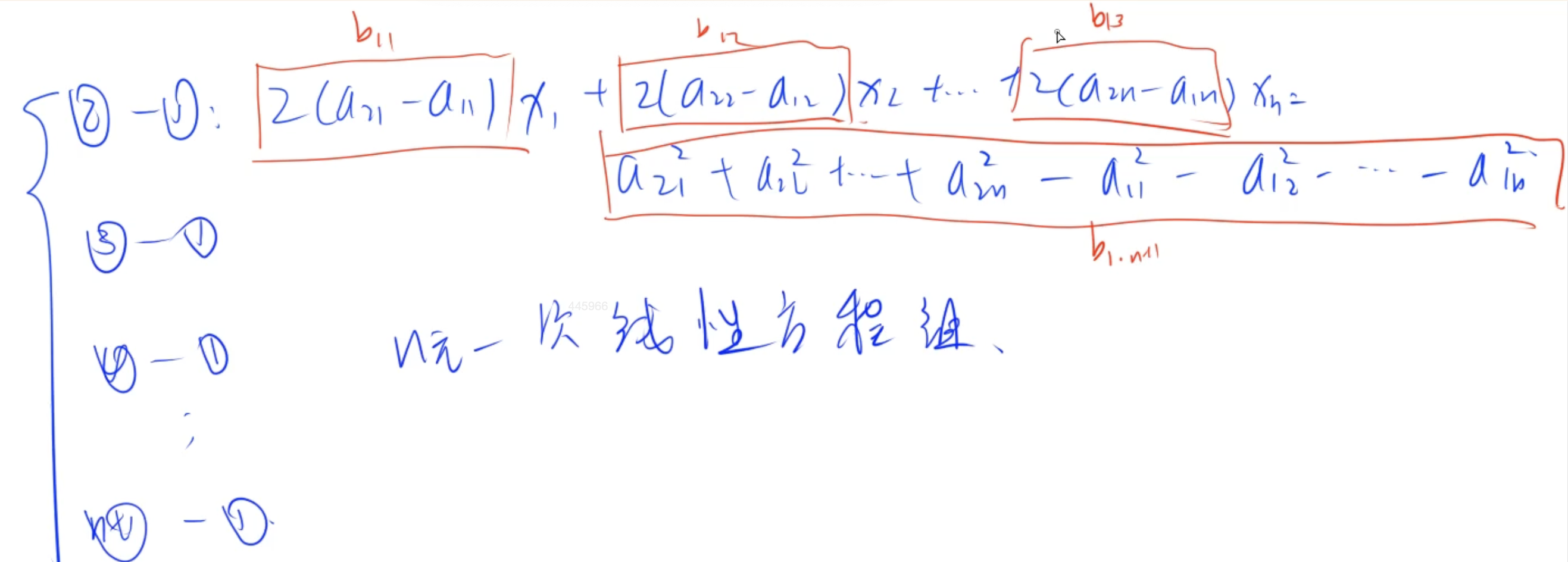
欧式空间 + Gauss消元
将方程转化为线性方程, 使用Gauss消元求解
球面方程的展开
对于点 P i = ( x i 1 , x i 2 , … , x i n ) P_i = (x_{i1}, x_{i2}, \dots, x_{in}) Pi=(xi1,xi2,…,xin),
球面方程为: ( x i 1 − c 1 ) 2 + ( x i 2 − c 2 ) 2 + ⋯ + ( x i n − c n ) 2 = r 2 (x_{i1} - c_1)^2 + (x_{i2} - c_2)^2 + \dots + (x_{in} - c_n)^2 = r^2 (xi1−c1)2+(xi2−c2)2+⋯+(xin−cn)2=r2
展开后得到: ( x i 1 2 − 2 x i 1 c 1 + c 1 2 ) + ( x i 2 2 − 2 x i 2 c 2 + c 2 2 ) + ⋯ + ( x i n 2 − 2 x i n c n + c n 2 ) = r 2 (x_{i1}^2 - 2x_{i1}c_1 + c_1^2) + (x_{i2}^2 - 2x_{i2}c_2 + c_2^2) + \dots + (x_{in}^2 - 2x_{in}c_n + c_n^2) = r^2 (xi12−2xi1c1+c12)+(xi22−2xi2c2+c22)+⋯+(xin2−2xincn+cn2)=r2
减去第一个点的方程
对于第一个点 P 1 = ( x 11 , x 12 , … , x 1 n ) P_1 = (x_{11}, x_{12}, \dots, x_{1n}) P1=(x11,x12,…,x1n),
方程为:$
(x_{11}^2 - 2x_{11}c_1 + c_1^2) + (x_{12}^2 - 2x_{12}c_2 + c_2^2) + \dots + (x_{1n}^2 - 2x_{1n}c_n + c_n^2) = r^2$
将其他点 P i P_i Pi 的方程减去第一个点的方程: [ ( x i 1 2 − 2 x i 1 c 1 + c 1 2 ) + ( x i 2 2 − 2 x i 2 c 2 + c 2 2 ) + ⋯ + ( x i n 2 − 2 x i n c n + c n 2 ) ] − [ ( x 11 2 − 2 x 11 c 1 + c 1 2 ) + ( x 12 2 − 2 x 12 c 2 + c 2 2 ) + ⋯ + ( x 1 n 2 − 2 x 1 n c n + c n 2 ) ] = 0 \begin{aligned} & \left[(x_{i1}^2 - 2x_{i1}c_1 + c_1^2) + (x_{i2}^2 - 2x_{i2}c_2 + c_2^2) + \dots + (x_{in}^2 - 2x_{in}c_n + c_n^2)\right] \\ & - \left[(x_{11}^2 - 2x_{11}c_1 + c_1^2) + (x_{12}^2 - 2x_{12}c_2 + c_2^2) + \dots + (x_{1n}^2 - 2x_{1n}c_n + c_n^2)\right] = 0 \end{aligned} [(xi12−2xi1c1+c12)+(xi22−2xi2c2+c22)+⋯+(xin2−2xincn+cn2)]−[(x112−2x11c1+c12)+(x122−2x12c2+c22)+⋯+(x1n2−2x1ncn+cn2)]=0
消去平方项和 r 2 r^2 r2
整理后得到: ( x i 1 2 − x 11 2 ) − 2 ( x i 1 − x 11 ) c 1 + ( x i 2 2 − x 12 2 ) − 2 ( x i 2 − x 12 ) c 2 + ⋯ + ( x i n 2 − x 1 n 2 ) − 2 ( x i n − x 1 n ) c n = 0 (x_{i1}^2 - x_{11}^2) - 2(x_{i1} - x_{11})c_1 + (x_{i2}^2 - x_{12}^2) - 2(x_{i2} - x_{12})c_2 + \dots + (x_{in}^2 - x_{1n}^2) - 2(x_{in} - x_{1n})c_n = 0 (xi12−x112)−2(xi1−x11)c1+(xi22−x122)−2(xi2−x12)c2+⋯+(xin2−x1n2)−2(xin−x1n)cn=0
将方程整理为线性形式:$
2(x_{i1} - x_{11})c_1 + 2(x_{i2} - x_{12})c_2 + \dots + 2(x_{in} - x_{1n})c_n = (x_{i1}^2 - x_{11}^2) + (x_{i2}^2 - x_{12}^2) + \dots + (x_{in}^2 - x_{1n}^2)
$
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
const int N = 15;
const double EPS = 1e-8;
int n;
double m[N][N], f[N][N];
void gauss() {
int row, col;
for (row = col = 1; col <= n; ++col) {
int u = row;
for (int i = row + 1; i <= n; ++i) {
if (fabs(f[i][col]) > fabs(f[u][col])) u = i;
}
if (fabs(f[u][col]) < EPS) continue;
for (int i = col; i <= n + 1; ++i) swap(f[row][i], f[u][i]);
for (int i = n + 1; i >= col; --i) f[row][i] /= f[row][col];
for (int i = row + 1; i <= n; ++i) {
for (int j = n + 1; j >= col; --j) {
f[i][j] -= f[row][j] * f[i][col];
}
}
row++;
}
for (int i = n; i >= 1; --i) {
for (int j = i + 1; j <= n; ++j) {
f[i][n + 1] -= f[i][j] * f[j][n + 1];
}
}
}
int main () {
cin >> n;
for (int i = 0; i < n + 1; ++i) {
for (int j = 1; j <= n; ++j) {
cin >> m[i][j];
}
}
// 将第2行开始的方程减去第一个方程
for (int i = 1; i < n + 1; ++i) {
for (int j = 1; j <= n; ++j) {
f[i][j] = 2 * (m[i][j] - m[0][j]);
f[i][n + 1] += m[i][j] * m[i][j] - m[0][j] * m[0][j];
}
}
gauss();
for (int i = 1; i <= n; ++i) printf("%.3lf ", f[i][n + 1]);
return 0;
}
- 当解是确定的时候解是唯一的
- 如果最后解是无穷多个, 那么每个开关两种状态 2 k 2 ^ k 2k
- 否则就是无解
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 40;
int n;
int f[N][N];
// 下标范围1~n
int gauss() {
int row, col;
for (row = 1, col = 1; col <= n; ++col) {
int u = row;
for (int i = row + 1; i <= n; ++i) {
if (f[i][col]) {
u = i;
break;
}
}
if (!f[u][col]) continue;
for (int i = col; i <= n + 1; ++i) swap(f[row][i], f[u][i]);
for (int i = row + 1; i <= n; ++i) {
for (int j = n + 1; j >= col; --j) {
f[i][j] ^= f[row][j] & f[i][col];
}
}
row++;
}
int res = 1;
if (row <= n) {
for (int i = row; i <= n; ++i) {
if (f[i][n + 1]) return -1;
res *= 2;
}
}
return res;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int cases;
cin >> cases;
while (cases--) {
memset(f, 0, sizeof f);
cin >> n;
for (int i = 1; i <= n; ++i) cin >> f[i][n + 1];
for (int i = 1; i <= n; ++i) {
int val;
cin >> val;
f[i][n + 1] ^= val;
f[i][i] = 1;
}
int val1, val2;
while (cin >> val1 >> val2, val1 || val2) {
f[val2][val1] = 1;
}
int res = gauss();
if (res == -1) cout << "Oh,it's impossible~!!" << "\n";
else cout << res << "\n";
}
return 0;
}
容斥原理
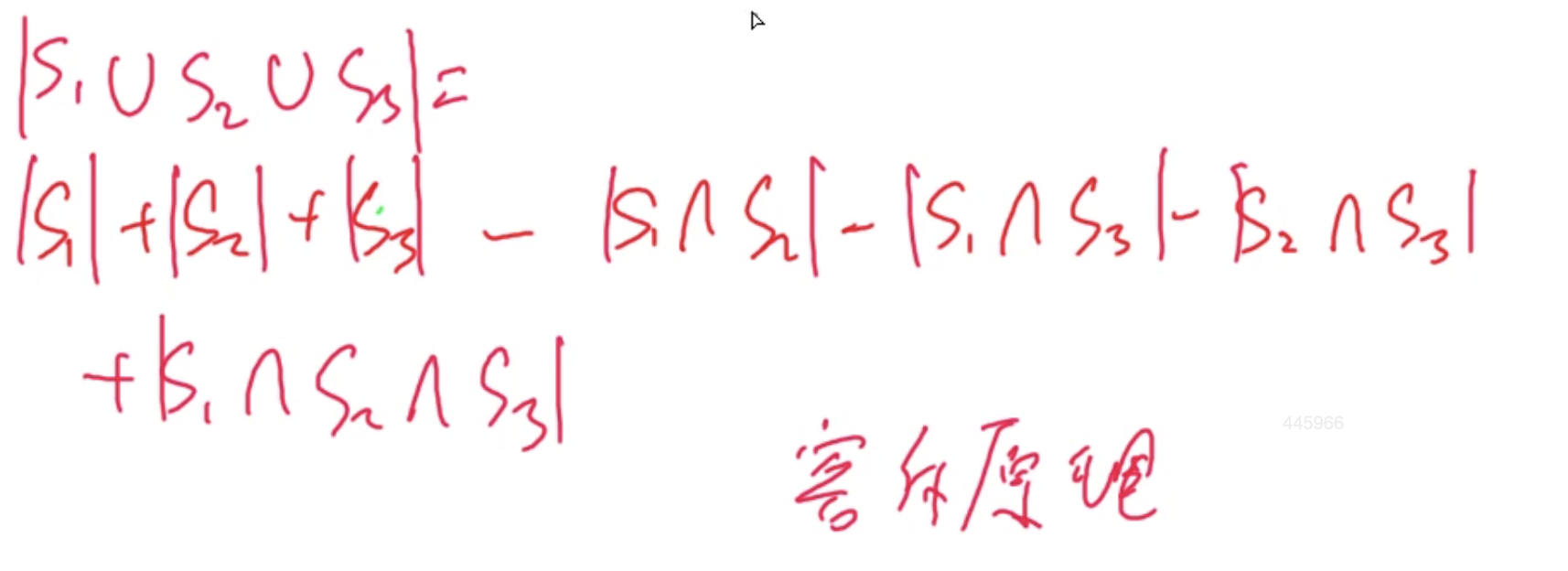
1 1 1到 n n n中至少被给质数一个整除的数的个数
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 20;
int val, n;
int primes[N];
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> val >> n;
for (int i = 0; i < n; ++i) cin >> primes[i];
int res = 0;
for (int i = 1; i < 1 << n; ++i) {
// 记录分母, 以及质因子个数
int tmp = 1, cnt = 0;
for (int j = 0; j < n; ++j) {
if (i >> j & 1) {
if ((LL) tmp * primes[j] > val) {
tmp = -1;
break;
}
tmp *= primes[j];
cnt++;
}
}
if (tmp != -1) {
cnt % 2 ? res += val / tmp : res -= val / tmp;
}
}
cout << res << "\n";
return 0;
}
首先将问题简化, 考虑所有位置的花有无限个

用总数减去至少不满足一个条件的数量就是答案

我们需要求满足 x 1 ≤ A 1 , … , x N ≤ A N x_1 \leq A_1, \ldots, x_N \leq A_N x1≤A1,…,xN≤AN 的方案数。根据容斥原理,问题可以转化为补集的形式:
res = C M + N − 1 N − 1 − cnt ( S 1 ∪ S 2 ∪ … ∪ S N ) \text{res} = C_{M+N-1}^{N-1} - \text{cnt}(S_1 \cup S_2 \cup \ldots \cup S_N) res=CM+N−1N−1−cnt(S1∪S2∪…∪SN)
其中:
- S i S_i Si 表示 x i > A i x_i > A_i xi>Ai 的集合。
- cnt ( S i ) \text{cnt}(S_i) cnt(Si) 表示满足 x i > A i x_i > A_i xi>Ai 的方案数。
根据容斥原理,补集的计算公式为:
cnt ( S 1 ∪ S 2 ∪ … ∪ S N ) = ∑ i cnt ( S i ) − ∑ i < j cnt ( S i ∩ S j ) + ∑ i < j < k cnt ( S i ∩ S j ∩ S k ) − … \text{cnt}(S_1 \cup S_2 \cup \ldots \cup S_N) = \sum_{i} \text{cnt}(S_i) - \sum_{i < j} \text{cnt}(S_i \cap S_j) + \sum_{i < j < k} \text{cnt}(S_i \cap S_j \cap S_k) - \ldots cnt(S1∪S2∪…∪SN)=i∑cnt(Si)−i<j∑cnt(Si∩Sj)+i<j<k∑cnt(Si∩Sj∩Sk)−…
因此,答案可以表示为:
res = C M + N − 1 N − 1 − ∑ i = 1 N C M + N − 1 − ( A i + 1 ) N − 1 + ∑ i < j C M + N − 1 − ( A i + 1 ) − ( A j + 1 ) N − 1 − … \text{res} = C_{M+N-1}^{N-1} - \sum_{i=1}^{N} C_{M+N-1 - (A_i + 1)}^{N-1} + \sum_{i < j} C_{M+N-1 - (A_i + 1) - (A_j + 1)}^{N-1} - \ldots res=CM+N−1N−1−i=1∑NCM+N−1−(Ai+1)N−1+i<j∑CM+N−1−(Ai+1)−(Aj+1)N−1−…
计算 cnt ( S 1 ) \text{cnt}(S_1) cnt(S1)
cnt ( S 1 ) \text{cnt}(S_1) cnt(S1) 表示满足 x 1 ≥ A 1 + 1 x_1 \geq A_1 + 1 x1≥A1+1 的所有方案数。我们可以通过以下方式计算:
cnt ( S 1 ) = C M + N − 1 − ( A 1 + 1 ) N − 1 \text{cnt}(S_1) = C_{M+N-1 - (A_1 + 1)}^{N-1} cnt(S1)=CM+N−1−(A1+1)N−1
其中:
- C n k C_{n}^{k} Cnk 表示组合数,即从 n n n 个元素中选取 k k k 个元素的方案数。
因为容斥原理会枚举所有的情况, 因此使用二进制数枚举每一位, 如果是奇数个符合条件的减去, 偶数的加上
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 20, MOD = 1e9 + 7;
LL n, m;
LL arr[N];
//分母阶乘的逆元
LL val2;
LL quick_pow(LL val, LL k) {
LL res = 1;
while (k) {
if (k & 1) res = res * val % MOD;
val = val * val % MOD;
k >>= 1;
}
return res;
}
//计算组合数
LL C(LL a, LL b) {
if (a < b) return 0;
LL val1 = 1;
for (LL i = a; i >= a - b + 1; --i) val1 = i % MOD * val1 % MOD;
return val1 * val2 % MOD;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> m;
for (int i = 0; i < n; ++i) cin >> arr[i];
// 预处理分母的逆元
val2 = 1;
for (int i = n - 1; i >= 1; --i) val2 = val2 * i % MOD;
val2 = quick_pow(val2, MOD - 2);
LL res = 0;
for (int i = 0; i < 1 << n; ++i) {
LL a = n + m - 1, b = n - 1;
int tag = 1;
for (int j = 0; j < n; ++j) {
if (i >> j & 1) {
tag *= -1;
a -= arr[j] + 1;
}
}
res = (res + C(a, b) * tag) % MOD;
}
cout << (res % MOD + MOD) % MOD << "\n";
return 0;
}
注意: 该题数据范围超级大, 因此在计算这个数的时候需要先对数取模再让该数参与运算
整除分块
因此, a n s = ∑ i = 1 n k − i × ⌊ k i ⌋ = n k − ∑ i = 1 n i × ⌊ k i ⌋ ans = \sum_{i=1}^{n} k - i \times \left\lfloor \frac{k}{i} \right\rfloor = nk - \sum_{i=1}^{n} i \times \left\lfloor \frac{k}{i} \right\rfloor ans=∑i=1nk−i×⌊ik⌋=nk−∑i=1ni×⌊ik⌋。
用样例打表找规律,发现 ⌊ k i ⌋ \left\lfloor \frac{k}{i} \right\rfloor ⌊ik⌋ 分别在一定的区域内相等,如下表所示:
$
\begin{array}{c|cccccccccc}
i & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \
\hline
\left\lfloor \frac{k}{i} \right\rfloor & 5 & 2 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 \
\end{array}$
可见 ⌊ k i ⌋ \left\lfloor \frac{k}{i} \right\rfloor ⌊ik⌋ 分成了 3 块,我们只需要计算 n × k n \times k n×k 减去每一块的和即可
枚举块的左边界根据左边界和 k k k计算出右边界

#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
LL n, k;
cin >> n >> k;
LL res = n * k;
for (int l = 1, r; l <= n; l = r + 1) {
if (k / l != 0) r = min(k / (k / l), n);
else r = n;
res -= (k / l) * (r - l + 1) * (l + r) / 2;
}
cout << res << endl;
return 0;
}
莫比乌斯函数

假设有问题求与 n n n互质的数的个数
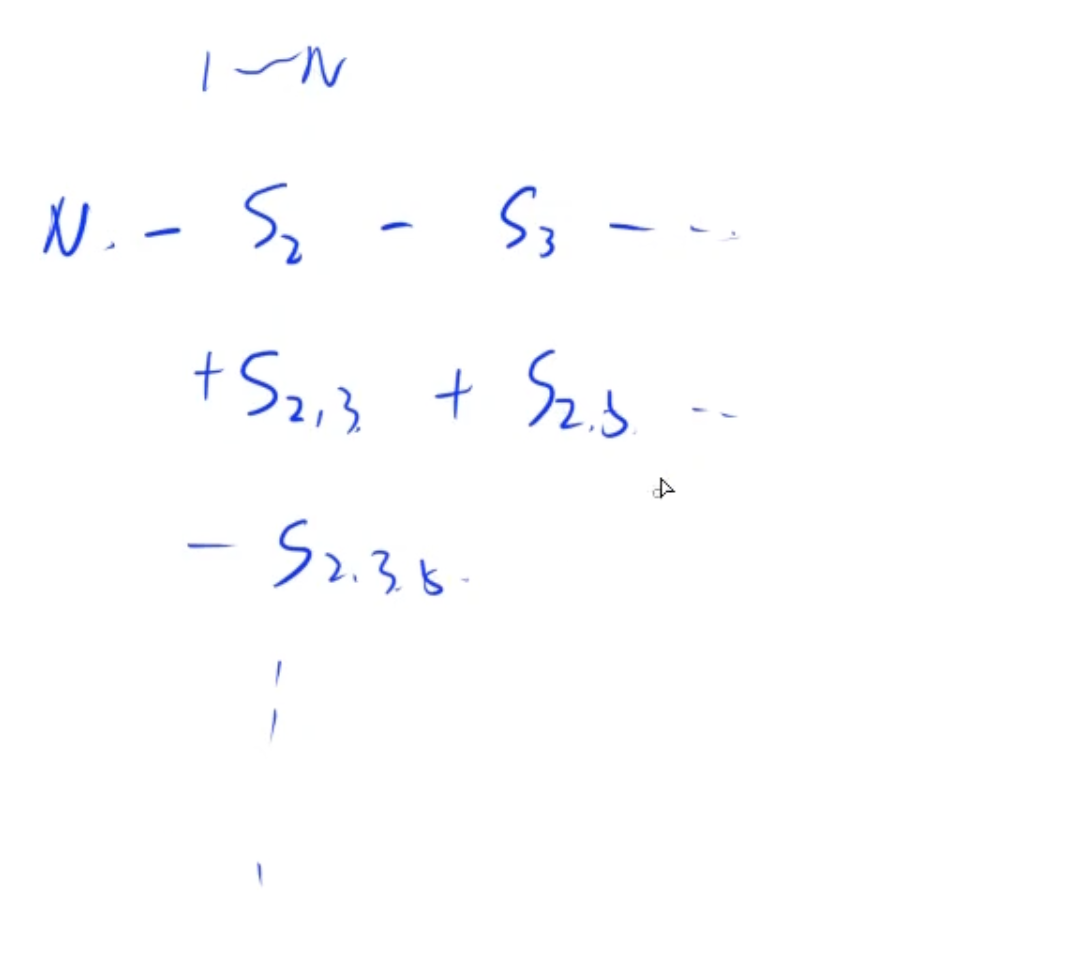
其中 S i S_i Si代表 i i i的倍数的个数
对于当前问题, 每一个数前面的系数就是莫比乌斯函数
如何求莫比乌斯函数?
- 当前数是质数, 只有一个质因子, 函数值是-1
- 如果 p j p_j pj是 i i i的最小质因子, i × p j i \times p_j i×pj当中至少包含两个 p j p_j pj, 函数值是0
- 如果未 b r e a k break break, i × p j i \times p_j i×pj 中的所有质因子都只出现过一次 函数值 × − 1 \times -1 ×−1
莫比乌斯函数应用
首先将问题进行映射

直接做的时间复杂度是 O ( n 2 ) O(n ^ 2) O(n2), 不同的数字的个数是有限的, 参考上面的整除分块, 通过该算法将复杂度优化成 O ( n n ) O(n\sqrt n) O(nn)
段内部整除的值是相等的, 因此求莫比乌斯函数的前缀和就能求出这一段的值
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 50010;
int cases;
int a, b, d;
int primes[N], cnt;
bool vis[N];
int mobius[N], s[N];
// 筛质数过程中计算莫比乌斯函数
void init() {
// 质因子数量0偶数
mobius[1] = 1;
for (int i = 2; i < N; ++i) {
if (!vis[i]) {
primes[cnt++] = i;
mobius[i] = -1;
}
for (int j = 0; i * primes[j] < N; ++j) {
vis[i * primes[j]] = true;
if (i % primes[j] == 0) {
mobius[i * primes[j]] = 0;
break;
}
mobius[i * primes[j]] = mobius[i] * -1;
}
}
// 预处理莫比乌斯函数前缀和
for (int i = 1; i < N; ++i) s[i] = s[i - 1] + mobius[i];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
init();
cin >> cases;
while (cases--) {
cin >> a >> b >> d;
a /= d, b /= d;
int n = min(a, b);
LL res = 0;
// 整除分块
for (int l = 1, r; l <= n; l = r + 1) {
r = min({
n, a / (a / l), b / (b / l)});
res += (s[r] - s[l - 1]) * (LL) (a / l) * (b / l);
}
cout << res << "\n";
}
return 0;
}
概率与数学期望
E ( a X + b Y ) = a E ( X ) + b E ( Y ) E(aX + bY) = aE(X) + bE(Y) E(aX+bY)=aE(X)+bE(Y)
计算路径长度的期望
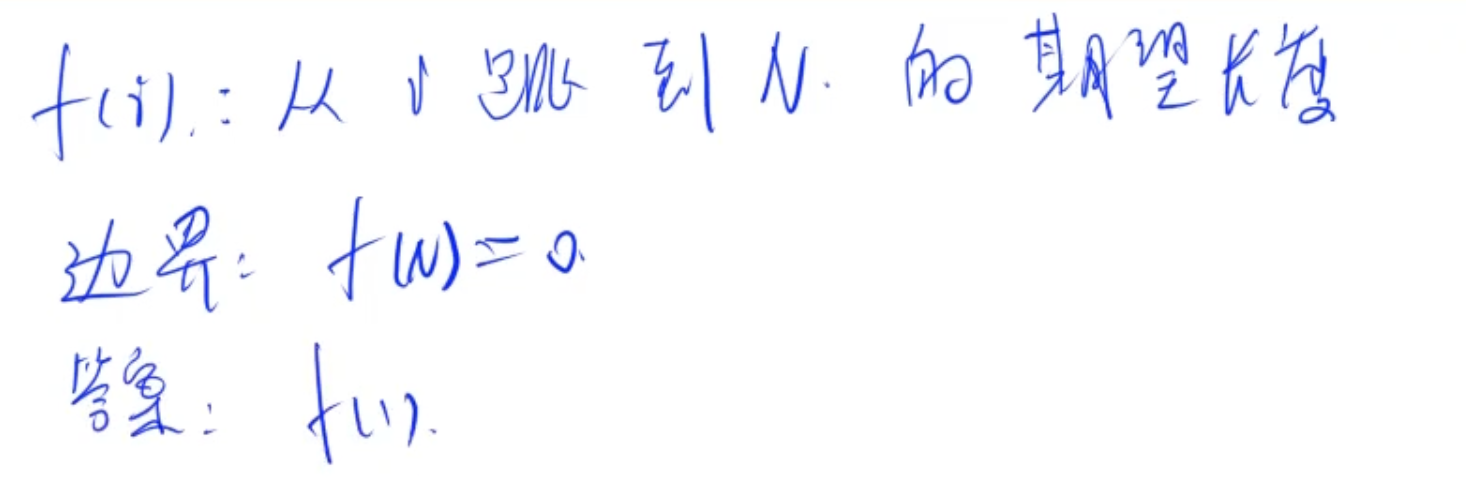

#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e5 + 10, EDGE_NUM = N << 1;
int n, edge_num;
int head[N], edge_end[EDGE_NUM], next_edge[EDGE_NUM], w[EDGE_NUM], edge_index;
int deg[N];
double f[N];
void add(int ver1, int ver2, int val) {
edge_end[edge_index] = ver2, next_edge[edge_index] = head[ver1], w[edge_index] = val, head[ver1] = edge_index++;
}
// 记忆化搜索
double dfs(int u) {
if (f[u] >= 0) return f[u];
f[u] = 0;
for (int i = head[u]; ~i; i = next_edge[i]) {
int ver = edge_end[i];
// 每次出边概率都是相等的
f[u] += (w[i] + dfs(ver)) / deg[u];
}
return f[u];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
memset(head, -1, sizeof head);
cin >> n >> edge_num;
while (edge_num) {
int ver1, ver2, val;
cin >> ver1 >> ver2 >> val;
add(ver1, ver2, val);
deg[ver1]++;
}
memset(f, -1, sizeof f);
dfs(1);
printf("%.2lf", f[1]);
return 0;
}
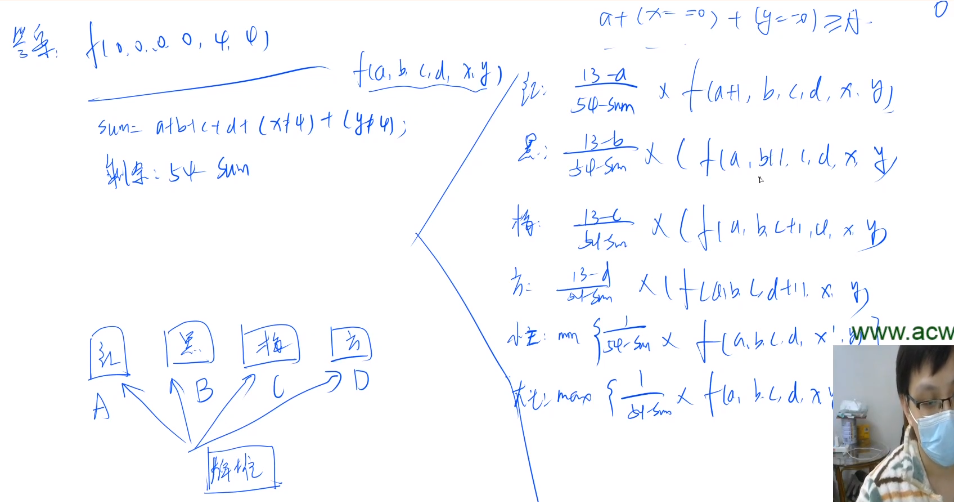
问题描述: 给定四堆扑克牌数量, 求最少的翻的牌的数学期望是多少(如果是大小王可以选择), 因为大小王放置到四个牌堆的概率是相等的, 因此可以转化为 d p dp dp问题
f [ a ] [ b ] [ c ] [ d ] [ x ] [ y ] f[a][b][c][d][x][y] f[a][b][c][d][x][y]: 从当前状态跳到终点的期望长度


枚举当前翻出的牌是什么牌, 一共六种状态
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 14;
const double INF = 1e20;
int A, B, C, D;
double f[N][N][N][N][5][5];
double dfs(int a, int b, int c, int d, int x, int y) {
double &u = f[a][b][c][d][x][y];
if (u >= 0) return u;
int as = a + (x == 0) + (y == 0);
int bs = b + (x == 1) + (y == 1);
int cs = c + (x == 2) + (y == 2);
int ds = d + (x == 3) + (y == 3);
if (as >= A && bs >= B && cs >= C && ds >= D) return u = 0;
// 计算还剩多少张牌没有翻
double sum = a + b + c + d + (x != 4) + (y != 4);
sum = 54 - sum;
// 翻到最后也没到达目标, 无解
if (sum <= 0) return u = INF;
// 否则翻开当前牌
u = 1;
if (a < 13) u += (13.0 - a) / sum * dfs(a + 1, b, c, d, x, y);
if (b < 13) u += (13.0 - b) / sum * dfs(a, b + 1, c, d, x, y);
if (c < 13) u += (13.0 - c) / sum * dfs(a, b, c + 1, d, x, y);
if (d < 13) u += (13.0 - d) / sum * dfs(a, b, c, d + 1, x, y);
// 当前牌是大小王
if (x == 4) {
double tmp = INF;
for (int i = 0; i < 4; ++i) {
tmp = min(tmp, 1.0 / sum * dfs(a, b, c, d, i, y));
}
u += tmp;
}
if (y == 4) {
double tmp = INF;
for (int i = 0; i < 4; ++i) {
tmp = min(tmp, 1.0 / sum * dfs(a, b, c, d, x, i));
}
u += tmp;
}
return u;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> A >> B >> C >> D;
memset(f, -1, sizeof f);
double res = dfs(0, 0, 0, 0, 4, 4);
if (res > INF / 2) res = -1;
printf("%.3lf\n", res);
return 0;
}
博弈论之公平组合游戏ICG
- 两名玩家交替行动
- 任意时刻, 可以执行的合法行动与轮到哪名玩家无关
- 不能行动的玩家判负
先手必胜状态: 操作之后是必败态, 就是必胜状态, 也就是把当前状态变成必败状态
先手必败状态: 操作之后变成的所有状态都是必胜状态
- 终点的异或值一定是 0 0 0
- 当异或值不是 0 0 0一定可以通过某种操作使其变为 0 0 0
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int main() {
int n;
cin >> n;
int res = 0;
for (int i = 0; i < n; ++i) {
int val;
cin >> val;
res ^= val;
}
if (res == 0) cout << "No" << "\n";
else cout << "Yes" << "\n";
return 0;
}
任选一个台阶拿若干个石子放到下一个台阶
结论: 将奇数台阶上石子当做普通 N i m Nim Nim游戏
- 如果当前异或值不是 0 0 0, 一定可以将当前状态转换为 0 0 0
- 如果对手从偶数台阶拿石子, 我们就把他拿的放到下一层台阶, 使得对手操作后奇数台阶石子不变
- 如果对手拿的奇数石子, 拿完后的异或值一定不是 0 0 0, 也就是经典Nim游戏
因此将奇数台阶看作经典Nim游戏是正确的
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10;
int main() {
int n;
cin >> n;
int res = 0;
for (int i = 1; i <= n; ++i) {
int val;
cin >> val;
if (i % 2) res ^= val;
}
if (res) cout << "Yes" << "\n";
else cout << "No" << "\n";
return 0;
}
博弈论之SG函数
M e x Mex Mex运算: 找到不属于当前集合的最小的非负整数
$SG(x): 如何计算当前状态的 如何计算当前状态的 如何计算当前状态的SG(x) ? 看当前局面能变成哪些局面 , 然后计算 ? 看当前局面能变成哪些局面, 然后计算 ?看当前局面能变成哪些局面,然后计算Mex$函数的值
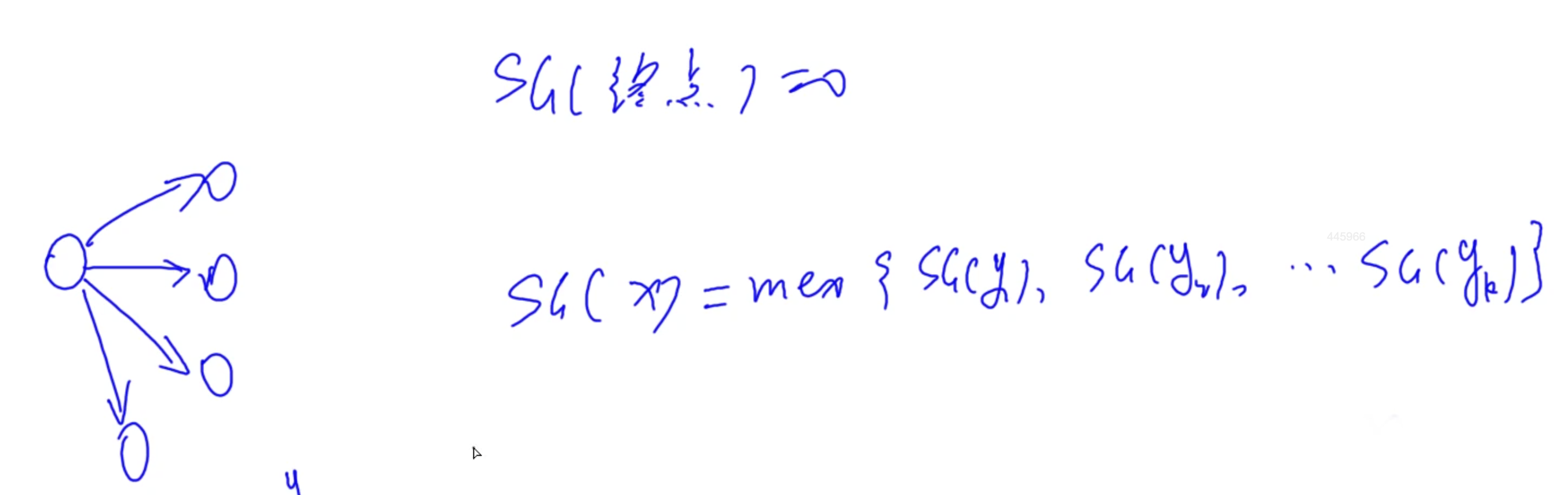
任何一个非 0 0 0的 S G ( x ) SG(x) SG(x)状态一定能变成 0 0 0, S G ( x ) ≠ 0 SG(x) \neq 0 SG(x)=0必胜, 可以适用多个局面
n n n堆石子, 就是 n n n个有向图, 对于每一个有向图的起点的 S G SG SG值进行异或
#include <iostream>
#include <algorithm>
#include <cstring>
#include <unordered_set>
using namespace std;
const int N = 110, STATE = 10010;
int k;
int arr[N];
int n;
int f[STATE];
int dfs(int u) {
if (f[u] != -1) return f[u];
unordered_set<int> s;
for (int i = 0; i < k; ++i) {
if (u >= arr[i]) s.insert(dfs(u - arr[i]));
}
for (int i = 0; ; ++i) {
if (!s.count(i)) return f[u] = i;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> k;
for (int i = 0; i < k; ++i) cin >> arr[i];
cin >> n;
memset(f, -1, sizeof f);
int res = 0;
// 读入石子个数, 计算每个起点的sg值
for (int i = 0; i < n; ++i) {
int val;
cin >> val;
res ^= dfs(val);
}
if (res) cout << "Yes" << "\n";
else cout << "No" << "\n";
return 0;
}
操作: 取出一堆石子, 放入两堆数量更少的石子, 无法操作的判负, 因为最大值在变少, 因此一定会结束
求出每一个局面的 S G SG SG值, 两堆的 S G SG SG值等于两个值进行异或
#include <iostream>
#include <algorithm>
#include <cstring>
#include <unordered_set>
using namespace std;
const int N = 110;
int n;
int f[N];
int dfs(int u) {
if (f[u] != -1) return f[u];
unordered_set<int> s;
// 枚举当前堆石子能分成的石子, 分成两堆满足SG函数性质, 直接异或起来就是答案
for (int i = 0; i < u; ++i) {
for (int j = 0; j <= i; ++j) {
s.insert(dfs(i) ^ dfs(j));
}
}
for (int i = 0; ; ++i) {
if (!s.count(i)) return f[u] = i;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n;
int res = 0;
memset(f, -1, sizeof f);
for (int i = 0; i < n; ++i) {
int val;
cin >> val;
res ^= dfs(val);
}
if (res) cout << "Yes" << "\n";
else cout << "No" << "\n";
return 0;
}
博弈论应用
S G SG SG函数在有向图上的应用
#include <iostream>
#include <algorithm>
#include <cstring>
#include <unordered_set>
using namespace std;
const int N = 2010, EDGE_NUM = 6010;
int n, edge_num, k;
int head[N], edge_end[EDGE_NUM], next_edge[EDGE_NUM], edge_index;
int f[N];
void add(int ver1, int ver2) {
edge_end[edge_index] = ver2, next_edge[edge_index] = head[ver1], head[ver1] = edge_index++;
}
int dfs(int u) {
if (f[u] != -1) return f[u];
unordered_set<int> s;
for (int i = head[u]; ~i; i = next_edge[i]) {
int ver = edge_end[i];
s.insert(dfs(ver));
}
for (int i = 0; ; ++i) {
if (!s.count(i)) return f[u] = i;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
memset(head, -1, sizeof head);
memset(f, -1, sizeof f);
cin >> n >> edge_num >> k;
while (edge_num--) {
int ver1, ver2;
cin >> ver1 >> ver2;
add(ver1, ver2);
}
int res = 0;
for (int i = 0; i < k; ++i) {
int val;
cin >> val;
res ^= dfs(val);
}
if (res) cout << "win" << "\n";
else cout << "lose" << "\n";
return 0;
}

 京公网安备 11010502036488号
京公网安备 11010502036488号