

Java-编码
标签(空格分隔): Java
在开发过程中我们往往会遇到很多中文乱码的问题,而要解决这个问题无非抓住编码和解码的一致性问题,但理解其背后的原因及定位问题,还需要了解现有的编码基础知识。
1. 词汇概念
1.1 编码与解码
数据在计算机中存储格式都是用0和1表示的。
编码是信息从一种形式或格式转换为另一种形式的过程,通俗点讲就是就是将我们看到的文字、图片等信息按照某种规则存储在计算机中;
解码是编码的逆过程,它是将存储在计算机的二进制转换为我们可以看到的文字、图片等信息,它体现的是视觉上的刺激。
在编码和解码中,他们就如加密、解密一般,他们一定会遵循某个规则,如果两者规则不一致就会出现乱码,这就是乱码的根源。
1.2 字符
字符是可使用多种不同字符方案或代码页来表示的抽象实体,它是一个单位的字形、类字形单位或符号的基本信息,也是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。在计算机中,字符是指计算机中使用的字母、数字、字和符号,包括:1、2、3、A、B、C、!·#¥%……—()——+等等。
在 ASCII 编码中,一个英文字母字符存储需要1个字节。在 GB 2312 编码或 GBK 编码中,一个汉字字符存储需要2个字节。在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
1.3 字符集(Charset)
字符是各种文字和符号的总称,而字符集则是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同。而计算机要准确的处理各种字符集文字,需要进行相应的字符编码,以便计算机能够识别和存储各种文字。
常见字符集名称:
- ASCII字符集
- GB2312字符集
- GB18030字符集
- Unicode字符集
1.4 字符编码(CharactorEncoding)
计算机中的信息包括数据信息和控制信息,然而不管是那种信息,他们都是以二进制编码的方式存入计算机中,但是他们是如何存放和显示而不会出错?这个时候字符编码就起到了重要作用,字符编码是一套规则,一套建立在符合集合与数字系统之间的对应关系之上的规则,即建立在字符集的基础上的规则,它是信息处理的基本技术。
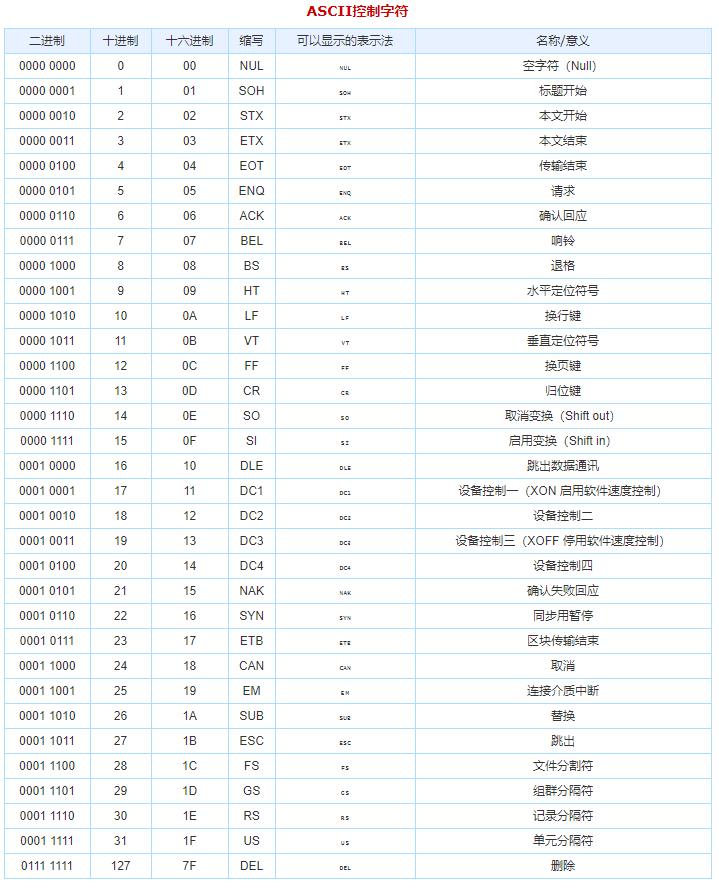
常见字符编码有:
- ASCII
- ISO-8859-1
- GB系列
- GB2312 - GBK - GB18030
- UTF系列
- UTF-8 - UTF-16
2. 编码标准
2.1 ASCII编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧英语,它是现今最通用的单字节编码系统。
ASCII使用7位或者8位来表示128或者256种可能的字符。标准的ASCII码则是使用7位二进制数来表示所有的大小写字母、数字、标点符合和一些控制字符。
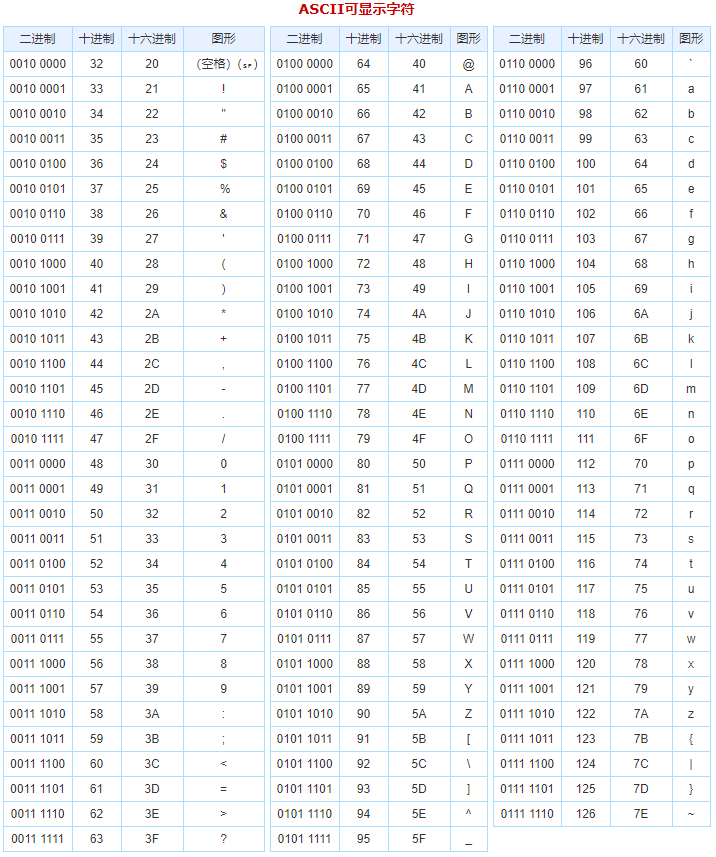
2.2 ISO-8859-1
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
2.3 GB系列编码
对于欧美国家来说,ASCII能够很好的满足用户的需求,但是我们的汉字达到将近10万,显示中文的常用字符编码有:GB2312、GBK、GB18030。一个汉字字符存储需要2个字节。
1)GB2312
在GB2312中,GB2312共收录6763个汉字,其中一级汉字3755个,二级汉字3008个,还收录了拉丁字母、希腊字母、日文等682个全角字符。
2)GBK
GBK是GB2312的扩展,他向下与GB2312兼容,向上支持 ISO 10646.1 国际标准,是前者向后者过渡过程中的一个承上启下的标准。同时它是使用双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),首字节在 81-FE 之间,尾字节在 40-FE 之间,共23940个码位,共收录了21003个汉字。
3)GB18030
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。
2.4 Unicode及其实现
2.4.1 Unicode简介
1)Unicode
Unicode又称为统一码、万国码、单一码,它是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。可以想象Unicode作为一个字符大容器,它将世界上所有的符号都包含其中,并且每一个符号都有自己独一无二的编码,这样就从根本上解决了乱码的问题。所以Unicode是一种所有符号的编码。
Unicode为了和它们相互兼容,其首256字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息。
2)Unicode转换格式
一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
Unicode是字符集,它主要有UTF-8、UTF-16、UTF-32三种实现方式。
2.4.2 UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示Unicode转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
2.4.3 UTF-8
UTF-8是一种针对Unicode的可变长度字符编码,可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
转换规则:
- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
转换表如下:
| Unicode | UTF-8 |
|---|---|
| 0000 ~007F | 0XXX XXXX |
| 0080 ~07FF | 110X XXXX 10XX XXXX |
| 0800 ~FFFF | 1110XXXX 10XX XXXX 10XX XXXX |
| 1 0000 ~1F FFFF | 1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX |
| 20 0000 ~3FF FFFF | 1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
| 400 0000 ~7FFF FFFF | 1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
根据上面的转换表,理解UTF-8的转换编码规则就变得非常简单了:第一个字节的第一位如果为0,则表示这个字节单独就是一个字符;如果为1,连续多少个1就表示该字符占有多少个字节。
3. 编码标准的例子
下文以字符串“I am 君山”的 char 数组为 49 20 61 6d 20 541b 5c71,下面把它按照不同的编码格式转化成相应的字节。
3.1 按照 ISO-8859-1 编码
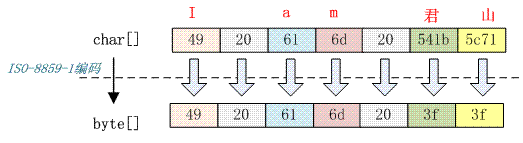
从上图看出 7 个 char 字符经过 ISO-8859-1 编码转变成 7 个 byte 数组,ISO-8859-1 是单字节编码,中文“君山”被转化成值是 3f 的 byte。3f 也就是“?”字符,所以经常会出现中文变成“?”很可能就是错误的使用了 ISO-8859-1 这个编码导致的。中文字符经过 ISO-8859-1 编码会丢失信息,通常我们称之为“黑洞”,它会把不认识的字符吸收掉。由于现在大部分基础的 Java 框架或系统默认的字符集编码都是 ISO-8859-1,所以很容易出现乱码问题
3.2 按照 GB2312 编码
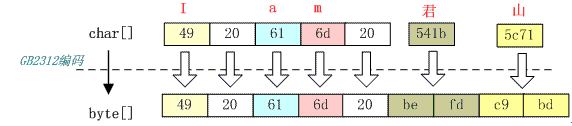
从上图可以看出前 5 个字符经过编码后仍然是 5 个字节,而汉字被编码成双字节,在第一节中介绍到 GB2312 只支持 6763 个汉字。
3.3 按照 GBK 编码
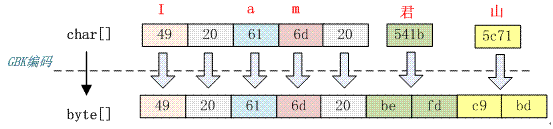
GBK 编码是兼容 GB2312 编码的,它们的编码算法也是一样的。不同的是它们的码表长度不一样,GBK 包含的汉字字符更多。
3.4 按照 UTF-16 编码

用 UTF-16 编码将 char 数组放大了一倍,单字节范围内的字符,在高位补 0 变成两个字节,中文字符也变成两个字节。从 UTF-16 编码规则来看,仅仅将字符的高位和地位进行拆分变成两个字节。特点是编码效率非常高,规则很简单,由于不同处理器对 2 字节处理方式不同。
3.5 按照 UTF-8 编码

UTF-16 虽然编码效率很高,但是对单字节范围内字符也放大了一倍,这无形也浪费了存储空间,另外 UTF-16 采用顺序编码,不能对单个字符的编码值进行校验,如果中间的一个字符码值损坏,后面的所有码值都将受影响。而 UTF-8 这些问题都不存在,UTF-8 对单字节范围内字符仍然用一个字节表示,对汉字采用三个字节表示。
4 Java内存编码解码过程
4.1 编码过程
在Java中编码和解码的一般过程:
1)保存Java源文件:
当编写java源文件时,程序文件在保存时会采用操作系统(IDE)默认的编码格式形成一个.java文件,参数名为file.encoding编码格式(一般中文操作系统默认采用的是GBK编码格式)保存的:
System.out.println(System.getProperty("file.encoding")); 2)编译源文件为类文件
当编译Java源文件时,JDK首先会确认它的编译参数encoding来确定源代码字符集,缺省值为操作系统默认的file.encoding参数,JDK就会把Java源程序从file.encoding编码格式转化为JVM默认的Unicode编码的类文件并载入内存中。
4.2 String编码分析
String s = "我是clj"; byte[] bytes = s.getBytes(); // 编码 String s1 = new String(bytes,"GBK"); // 解码(编译参数是GBK) String s2 = new String(bytes); // 解码(编译参数是默认ISO-8859)
在这段代码中我们看到了三处编码转换过程(一次编码,两次解码),接下来分析编码和解码的源代码
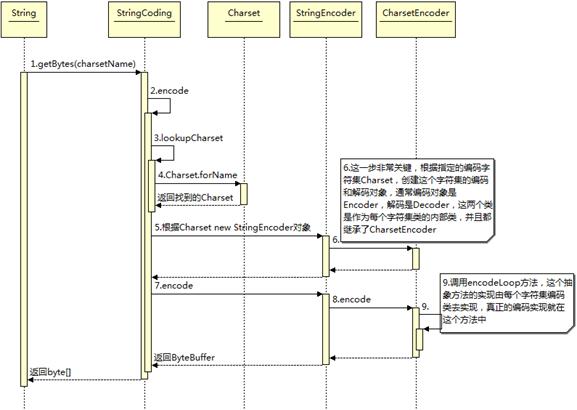
1)编码
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
} static byte[] encode(char[] ca, int off, int len) {
String csn = Charset.defaultCharset().name();
try {
// use charset name encode() variant which provides caching.
return encode(csn, ca, off, len);
} catch (UnsupportedEncodingException x) {
warnUnsupportedCharset(csn);
}
try {
return encode("ISO-8859-1", ca, off, len);
} catch (UnsupportedEncodingException x) {
// If this code is hit during VM initialization, MessageUtils is
// the only way we will be able to get any kind of error message.
MessageUtils.err("ISO-8859-1 charset not available: "
+ x.toString());
// If we can not find ISO-8859-1 (a required encoding) then things
// are seriously wrong with the installation.
System.exit(1);
return null;
}
} 其中,StringCoding.encode(char[] paramArrayOfChar, int paramInt1, int paramInt2)方法首先调用系统的默认编码格式,如果没有指定编码格式则默认使用ISO-8859-1编码格式进行编码操作,进一步:
String csn = (charsetName == null) ? "ISO-8859-1" : charsetName;
2)解码
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charset, bytes, offset, length);
} new String的构造函数内部是调用StringCoding.decode()方法。decode方法和encode对编码格式的处理是一样的,首先调用系统的默认编码格式,如果没有指定编码格式则默认使用ISO-8859-1编码格式进行编码操作。
4.3 Charset类库
Java内部的编码全由Charset类库支持的,上述的String的编码与解码的源码中也可以看出是由Charset支持的。
java.nio.charset包中提供了Charset类,它继承了Comparable接口;还有CharsetDecoder、CharsetEncoder编码和解码的类,它们都是继承Object类。
Java中的JVM字符使用Unicode编码,每个字符占用两个字节,16个二进制位,向ByteBuffer中存放数据的时候需要考虑字符的编码,从中读取的时候也需要考虑字符的编码方式,也就是编码和解码。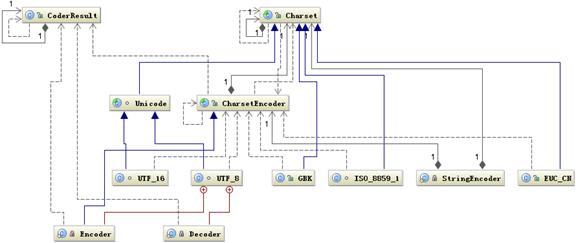
1)获取字符集有如下两种方式
//返回指定的字符集CharSet
Charset charset = Charset.forName("utf8");
//返回虚拟机默认的字符集CharSet
Charset charset = Charset.defaultCharset(); 2)创建一个编码器和一个解码器
//编码器 CharsetEncoder encoder = charset.newEncoder(); //解码器 CharsetDecoder decoder = charset.newDecoder();
3)解析数据
//编码,传入CharBuffer ByteBuffer bytebuffer = encoder.encode(in); //解码,传入ByteBuffer CharBuffer charbuffer = decoder.decode(in);
public static void main(String[] args) {
Charset charset = Charset.forName("utf8");
System.out.println(charset.name()+"--"+charset.canEncode());
//返回一个包含该字符的别名,字符集的别名是不可变的
Set<String> set = charset.aliases();
Iterator<String> it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
System.out.println("----------编码----------------");
ByteBuffer buffer = charset.encode("sdf");
System.out.println(buffer);
System.out.println("缓冲区剩余的元素数--"+buffer.remaining());
while(buffer.hasRemaining()) {
System.out.println((char)buffer.get());
}
System.out.println("缓冲区剩余的元素数--"+buffer.remaining());
System.out.println("----------解码----------------");
//清空缓冲区,将限制设置恢复,如果定义了标记,则将它们丢弃
buffer.flip();
} 5. Java磁盘I/O编码解码过程
5.1 字节流
在我们用InputStream读取文件时,读取字节的编码取决于文件所使用的编码格式,而读出字节流后在转换为String过程中也会涉及到编码,如果两者之间的编码格式不同可能会出现问题。
例如文件test.txt编码设置为UTF-8,那么通过字节流读取文件时所获得的数据流编码格式就是UTF-8,而我们在转化成String过程中如果不指定编码格式则默认使用ISO-8859(上述String有提到)来解码操作,由于两者编码格式不一致,那么在构造String过程肯定会产生乱码:
File file = new File("C:\\test.txt");
InputStream input = new FileInputStream(file);
StringBuffer buffer = new StringBuffer();
byte[] bytes = new byte[1024];
for(int n ; (n = input.read(bytes))!=-1 ; ){
buffer.append(new String(bytes,0,n));
}
System.out.println(buffer); 输出结果:锘挎垜鏄?cm
test.txt中的内容为:我是 cm。
解决方法:
在构造String过程中指定编码格式,使得编码解码时两者编码格式保持一致即可:
buffer.append(new String(bytes,0,n,"UTF-8"));
5.2 字符流
字符流的底层还是采用字节流来读取字节,也就是说在上述字节流的基础上多了编码成字符流的操作。见下述字节流转字符流。
5.3 字节流转字符流
字节流转字符流,即InputStreamReader和OutputStreamWriter,手动将字节流转换为字符流。下面以InputStreamReader叙述,OutputStreamWriter和其大体相同。
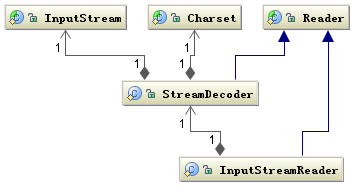
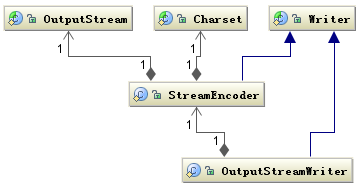
InputStreamReader 类就是关联字节到字符的桥梁,它负责在 I/O 过程中处理读取字节到字符的转换,而具体字节到字符的解码实现它由 StreamDecoder 去实现,在 StreamDecoder 解码过程中必须由用户指定 Charset 编码格式。值得注意的是如果你没有指定 Charset,将使用本地环境中的默认字符集,例如在中文环境中将使用GBK编码。
String file = "C:\\test.txt";
String charset = "UTF-8";
// 写字符换转成字节流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(outputStream, charset);
try {
writer.write("我是 cm");
} finally {
writer.close();
}
// 读取字节转换成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buf, 0, count);
}
} finally {
reader.close();
}
System.out.println(buffer); 6. Java控制台I/O编码解码过程
这种情况下,JVM首先会把保存在操作系统中的class文件读入到内存中,这个时候内存中class文件编码格式为Unicode,然后JVM运行它。
如果需要用户输入信息,则会采用file.encoding编码格式对用户输入的信息进行编码同时转换为Unicode编码格式保存到内存中。程序运行后,将产生的结果再转化为file.encoding格式返回给操作系统并输出到界面去。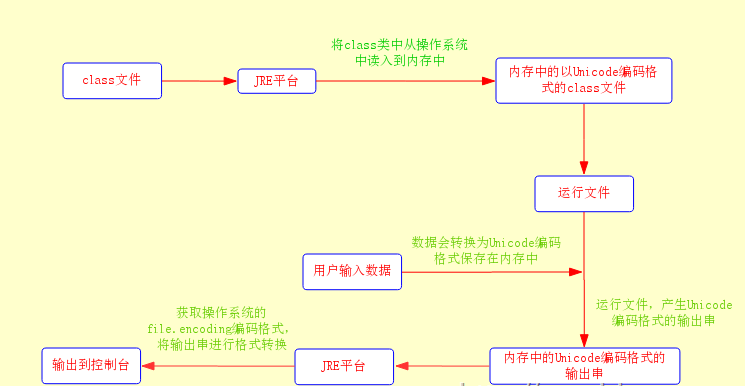
7. Java网络I/O编码解码过程
大部分 I/O 引起的乱码都是网络 I/O,因为现在几乎所有的应用程序都涉及到网络操作,而数据经过网络传输都是以字节为单位的,所以所有的数据都必须能够被序列化为字节。以web为例子讲述Java网络I/O的编码解码过程。
用户从浏览器端发起一个HTTP请求,涉及的编码有URI、表单提交、Cookie;服务器端接受到HTTP请求后对URI、表单提交、Cookie参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。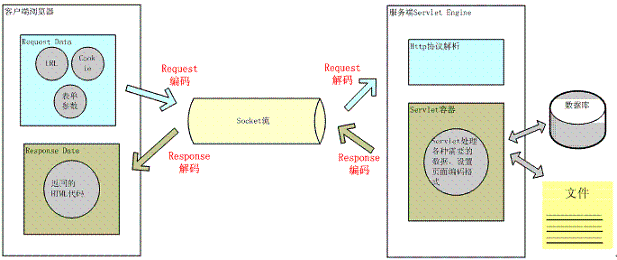
7.1 URL的编解码
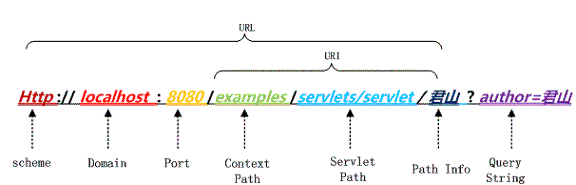
PathInfo 和 QueryString 出现了中文,浏览器端和服务端编码和解析这个URL ,上述URL测试结果:

PathInfo 是UTF-8编码, QueryString 是经过GBK编码,查阅 URL 的编码规范 RFC3986可知浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成 16 进制数字然后将每个 16 进制表示的字节前加上“%”,所以最终的 URL 就成了上图的格式了。
1)PathInfo的编码:
不同浏览器对 PathInfo 的编码可能不一样,这就对服务器的解码造成很大的困难。
为了统一期间,以tomcat对URL的编码入手进行统一编码,tomcat对URI进行解码的字符集是在 connector 的 <Connector URIEncoding=”UTF-8”/>中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。
2)QueryString的编码:
QueryString的参数设置是通过设置直接URL传参或表单Get方式传。
QueryString 的解码字符集是通过 HTTP 的 Header 传到服务端的,并且也在 URL 中,和 URI 的解码字符集不一样(前面提过)。
QueryString 的解码字符集:
- Header 中 ContentType 中定义的 Charset
- 默认的
ISO-8859-1
要使用 ContentType 中定义的编码就要设置 connector 的 <Connector URIEncoding=”UTF-8” useBodyEncodingForURI=”true”/> 中的 useBodyEncodingForURI 设置为 true。这个配置项的名字有点让人产生混淆,它并不是对整个 URI 都采用 BodyEncoding 进行解码而仅仅是对 QueryString 使用 BodyEncoding 解码,这一点还要特别注意。这个BodyEncoding是通过下文setCharacterEncoding方式设置的。
7.2 POST 表单的编解码
GET 方式 HTTP 请求的 QueryString 与 POST 方式 HTTP 请求的表单参数都是作为 Parameters 保存,都是通过 request.getParameter 获取参数值。对它们的解码是在 request.getParameter 方法第一次被调用时进行的。request.getParameter 方法被调用时将会调用 org.apache.catalina.connector.Request 的 parseParameters 方法。Get方式前面提过。
POST 表单参数传递方式与 QueryString 不同,它是通过 HTTP 的 BODY 传递到服务端的。将根据 ContentType 的 Charset 编码格式对表单填的参数进行编码然后提交到服务器端,在服务器端同样也是用 ContentType 中字符集进行解码。可以通过 request.setCharacterEncoding(charset) 来设置。
在获取并Response 返回给客户端浏览器,这个过程先要经过编码再到浏览器进行解码。这个过程的编解码字符集可以通过 response.setCharacterEncoding 来设置,它将会覆盖 request.getCharacterEncoding 的值,并且通过 Header 的 Content-Type 返回客户端。
浏览器接受到返回的 socket 流时将通过 Content-Type 的 charset 来解码,如果返回的 HTTP Header 中 Content-Type 没有设置 charset,那么浏览器将根据 Html 的
<meta HTTP-equiv="Content-Type" content="text/html; charset=GBK" />
中的 charset 来解码。如果也没有定义的话,那么浏览器将使用默认的编码来解码。
另外针对 multipart/form-data 类型的参数,也就是上传的文件编码同样也是使用 ContentType 定义的字符集编码
7.3 HTTP Header的编解码
当客户端发起一个 HTTP 请求除了上面的 URL 外还可能会在 Header 中传递其它参数如 Cookie、redirectPath 等,这些用户设置的值很可能也会存在编码问题。
默认使用的默认编码也是 ISO-8859-1,如果要含有中文,那么就可以使用org.apache.catalina.util.URLEncoder或URLDecoder来进行处理。
7.4 其它的编解码
7.4.1 数据库交互
Java程序与数据库的连接都是通过JDBC驱动程序来连接的,而JDBC驱动程序默认的是ISO-8859-1编码格式的,也就是说我们通过java程序向数据库传递数据时,JDBC首先会将Unicode编码格式的数据转换为ISO-8859-1的编码格式,然后在存储在数据库中,即在数据库保存数据时,默认格式为ISO-8859-1。
可以通过:
useUnicode=true&characterEncoding=utf8
另外,数据库本身的存储编码则是通过my.ini来配置的,将默认的latin改成utf8。

 京公网安备 11010502036488号
京公网安备 11010502036488号