

项目代码:https://github.com/CMU-Perceptual-Computing-Lab/convolutional-pose-machines-release
论文原文:https://arxiv.org/abs/1602.00134
推荐一篇写的特别好的总结博文:http://blog.csdn.net/zimenglan_sysu/article/details/52077138
参考文章:http://blog.csdn.net/twt520ly/article/details/79224226
Convolutional Pose Machines
摘要
Pose Machines为学习丰富的隐式空间模型提供了一个顺序预测框架。在这项工作中,我们展示了一个系统的设计,为什么卷积网络可以被纳入到姿态机框架去学习图像特征和图像相关空间模型的任务的姿态估计。本文的贡献是隐式地建模结构化预测任务中的变量之间的长期依赖关系,如关节姿态估计。我们通过设计一个由卷积网络组成的顺序架构来实现这一点,直接在前一阶段的信念图上进行操作,不需要明确的图形模型式推理就可以对零件位置进行日益精确的估计。我们的方法通过提供自然的学习目标函数来强化中间监督,从而补充反向传播的梯度并调整学习过程,从而解决了在训练期间特征的梯度消失的困难。我们展示了最先进的性能,并在包括MPII,LSP和FLIC数据集在内的标准基准测试中胜出了各种竞争方法。
1。介绍
我们引入卷积姿态机(CPMs)来进行关节姿态估计。 CPM继承了姿态机架构的好处 - 图像和多部分线索之间的远程依赖性的隐式学习,学习和推理之间的紧密集成,模块化的顺序设计 - 并将它们与卷积架构提供的优势相结合: 直接从数据中学习图像和空间上下文的特征表示的能力; 一个可区分的架构,允许全局联合反向传播训练和有效处理大型训练数据集的能力。
CPM包含一系列卷积网络,为每个部分的位置重复生成2D信念图。 在CPM的每个阶段,图像特征和前一阶段产生的信念图被用作输入。 信念图为后续阶段提供了对每个部分的位置空间不确定性的表达式非参数编码,使得CPM能够学习丰富的与图像相关的空间模型。 我们不是使用图形模型或专门的后处理步骤来明确地解析这样的信念映射,而是学习直接在中间信念图映射上操作的卷积网络,并学习部分之间关系的隐式图像相关空间模型。 总体上提出的多级架构是完全可区分的,因此可以使用反向传播以端到端的方式进行培训。
在CPM的特定阶段,部分置信图的空间背景为后续的阶段提供了明确的线索。因此,CPM的每一个阶段都会生成置信图,其中
每个阶段的位置都有不同的估计值(例如图1)。为了捕捉各部分之前的长期相互作用,我们顺序预测框架中每一个阶段的网
络设计都是通过在图像和置信图上实现了一个大的感受野来达到的。我们通过实验发现,置信地图上的大型感受野对于学习
长距离的空间关系是很重要的,并且提高了准确率。

在CPM中组合多个卷积网络导致整个网络具有许多层,在学习期间存在梯度消失的风险。 反向传播渐变强度减弱,因为它们通过网络的许多层传播,可能会发生此问题。 虽然最近的研究表明,监督中间层的非常深的网络有助于学习,但是它们大多局限于分类问题。在这项工作中,我们展示了如何对结构化预测问题如姿态估计,CPM自然地提出了一个 系统的框架,补充梯度,并指导网络定期通过执行中间监督产生越来越准确的信念地图。 我们还讨论了这种顺序预测体系结构的不同训练方案。我们的主要贡献是(a)通过卷积体系结构的顺序组合来学习隐式空间模型,以及(b)设计和训练这种体系结构的系统方法,以学习结构化预测任务的图像特征和图像相关空间模型, 不需要借助任何图形模型风格推断。 我们在MPII,LSP和FLIC数据集的基准上,综合分析联合训练多级架构和重复中间监督的效果,达到了目前最好。(state-of-the-art )
2。相关工作
经典的关节姿态估计方法是图像结构模型,其中身体各部分之间的空间相关性被表示为具有运动学先验的连接肢体的树形结构图形模型。这些方法在人的所有肢体都可见的图像上是成功的,但是易于出现特征性错误,例如由于树形结构模型未捕获的变量之间的相关性而出现的重复图像证据。Kiefel的工作是基于图形结构模型,但在底层图形表示方面有所不同。分层模型表示分层树结构中不同尺度和大小的部件之间的关系。这些模型的基本假设是较大的部分(对应于全肢而不是关节)通常可以具有有区别的图像结构,其可以更容易检测,并且因此有助于推测较小的,难以检测的部件的位置。非树模型结合了引入循环的相互作用来微调树结构,可以额外的捕捉边缘对称性,遮挡和长距离关系。这些方法通常在学习和测试时间都必须依赖近似推理,因此必须将空间关系的精确建模与允许有效推理的模型进行权衡,通常使用简单的参数形式来进行快速推理。相反,基于顺序预测框架的方法通过直接训练一个推理过程来学习一个潜在的变量之间复杂相互作用的隐式空间模型。
最近,人们对使用卷积架构进行关节姿态轨迹的模型产生了兴趣。Toshev采取使用标准的卷积结构直接回归笛卡尔坐标的方法。最近的研究将图像映射为置信图,并借助于需要手动设计的能量函数或空间概率先验的启发式初始化的图形模型,以去除回归后的置信图上的异常值。其中一些还利用专门的网络模块进行精确的修复。在这项工作中,我们展示了回归置信图适合输入到具有大的感受野的卷积神经网络,以学习隐式空间的参数,而不需要手工设计先验信息,并且在没有专门的初始化和专用的精确度的情况下成为了业界最强。Pfister还使用了一个具有大感受野的网络的模块来捕获隐式空间模型。由于卷积的可微性,我们的模型可以进行全局训练,Tompson和Steward也讨论了联合训练的好处。
Carreira等人利用误差反馈迭代地改善了部分检测的深度网络,但是使用了笛卡尔表示,因为其不能保持空间不确定性并导致精度较低的精度。 在这项工作中,我们展示了顺序预测框架如何利用保留的不确定性来保存丰富的空间上下文,通过强化中间局部监督来解决梯度消失的问题。
3。方法
3.1.姿势机
我们把第p个身体部位表示为 ,其中Z是一张图片里面所有位置的集合。我们的目标是对P个pair预测输出值 。姿势机由一系列多级预测因子组成(见图2a和图2b),这些预测变量被训练用来预测层次结构中每个层次中每个部分的位置。
定义 是图片的第p个位置, ,Z是二维图像, 表示坐标(u,v), 表示在位置z的特征。对于每一个阶段 ,每一个阶段都有一个多分类器 。对于每一个阶段 ,每一个阶段都有一个多分类器 ,得到预测结果
第一阶段需要初始化:
是一个的得分,代表了第一阶段的分类器 对于第 个位置的预测结果为z的分数,也可以表示为
对于后面阶段(t>1)
其中 可以映射出前一阶段的分数对阶段的影响,对于所有的阶段
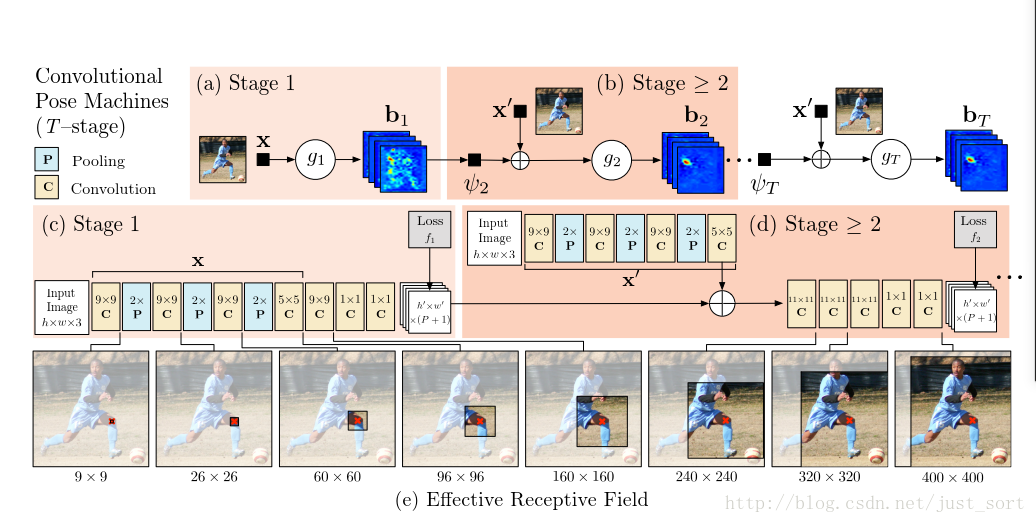
3.2。卷积姿态机
我们演示了使用CNN代替Pose Machine直接从数据中学习到图像和上下文信息。CNN是完全可微的,从而使CPM在所有的阶段都可以直接进行端到端的联合训练。我们提出了CPM的结构,结合了CNN的优点和Pose machine的隐式姿态空间建模能力。
3.2.1使用图片的局部信息进行关键点定位
CPM的第一阶段仅仅从局部图片信息获取部位的信度图。图2.c展示了网络结构从局部图像信息出发,利用深度卷积神经网络进行目标区域检测。证据是局部的,因为网络的第一阶段的感知野被限制在输出像素的周围一小部分。我们使用的网络结构由五个卷积层和两个1x1卷积层组成,得到的结果再经过一个全连接层。在测试后,为了提高训练的精度,我们需要对输入图像调整为368x368。神经网络的感知野是160x160像素。该结构可以看做是一个图片和一个160x160的滑动窗口在上面移动,最后得到P+1维度的向量,代表了每一个部位的得分值。
为什么要使用1x1卷积?
1x1卷积的大小是1x1,没有考虑吧前一层的局部信息之间的关系,1X1卷积可以加深网络结构,在InceptionNet中用来降维。
1.降维:在卷积过程中,多个通道的值一般情况下会转换为单通道,如果之前有x个通道,现在使用y个卷积核进行卷积,那么得到的feature map在通道维度上就是y。
2.进行非线性处理:卷积后进行非线性激活。
3.2.2通过学习空间上下文特征序列预测
3.3使用卷积姿态机进行学习
上文所述的检测结果中使用了深层次的神经网络,因此很容易导致梯度消失。发现反向传播过程中梯度下降的强度受中间层的数量影响。
幸运的是,PM的时序预测序列框架天然可以训练深层模型的过程中,来解决这个问题。PM的每一个阶段都会重复的产生信度图来表示每一个部位的定位。我们引导网络的运行结果到达一个预期的效果,通过定义一个损失函数在每一个阶段的输出位置来最小化预测结果与每一部分理想的信度图的 距离。每一个部分 的理想信度图记作:
产生的方式是通过肢体每一部位 的真实位置的高斯分布值作为上述的值。我们定义最小化输出中的代价函数为:
,其中 遍历每一个部位, 表示对应的区域。然后将每一个阶段的损失函数加起来得到:
我们使用标准随梯度下降法去全局训练 个时刻的网络参数。为了在后续的阶段***享 ,我们们在后面的阶段中对应的网络层***享权重,也就是说每个stage是相似的。

 京公网安备 11010502036488号
京公网安备 11010502036488号