

前言
在阅读ImageShop的 https://www.cnblogs.com/Imageshop/p/4441972.html 这篇文章后,逐渐对图像处理中的滤波算法的加速理解得更加深刻一些了,如何做出与半径无关的滤波算法似乎成为了众多优化算法的目标,ImageShop开源了他部分利用直方图技巧加速的滤波算法处理框架,我通过研究原理和他的代码使得这个框架可以应用到自己的代码中,接下来以最大值滤波为例子来分享一下这个框架的原理以及加速手段。
传统的最大值滤波
Mat MaxFilter(Mat src, int radius) {
int row = src.rows;
int col = src.cols;
int border = (radius - 1) / 2;
Mat dst(row, col, CV_8UC3);
for (int i = border; i + border < row; i++) {
for (int j = border; j + border < col; j++) {
for (int k = 0; k < 3; k++) {
int val = src.at<Vec3b>(i, j)[k];
for (int x = -border; x <= border; x++) {
for (int y = -border; y <= border; y++) {
val = max(val, (int)src.at<Vec3b>(i + x, j + y)[k]);
}
}
dst.at<Vec3b>(i, j)[k] = val;
}
}
}
return dst;
}
可以看出直接使用C语言实现,复杂度是 O(Hight∗Width∗Channel∗(2∗R+1)∗(2∗R+1)),这个复杂度对于半径大或图像分辨率大时是难以接受的。
基于SSE加速的恒长任意半径局部直方图获取技术
在最大值滤波中,我们可以发现如果对每个点维护一下在半径范围内的直方图,我们就可以在O(256)的时间复杂度内求出这个最大值,那么我们的算法就和滤波半径没有关系了(还是和图像内容有关的)。算法流程为:沿着列方向一行一行的更行整行的列直方图,新的一行对应的列直方图更新时只需要减去已经不再范围内的那个像素同时加入新进入的像素的直方图信息。之后,对于一行中的第一个像素点,累加半径辐射范围内的列直方图,得到改点的局部直方图,对于行中的其他的像素,则类似于更新行直方图,先减去不在范围内那列的列直方图,然后加上移入范围内的列直方图。由于采用了基于SSE函数的加速过程,直方图想加和相减的速度较普通的加减法有了10倍以上的提速,因此大大的提高了整体的实用性。
#pragma once
#include "Core.h"
#include "Utility.h"
// 函数供能: 在指定半径内,最大值”滤镜用周围像素的最高亮度值替换当前像素的亮度值。
// 参数列表:
// Src: 需要处理的源图像的数据结构
// Dest: 保存处理后的图像的数据结构
// Radius: 半径,有效范围
// 说明:
// 1、程序的执行时间和半径基本无关,但和图像内容有关
// 2、Src和Dest可以相同,不同时执行速度很快
// 3、对于各向异性的图像来说,执行速度很快,对于有大面积相同像素的图像,速度会慢一点
IS_RET MaxFilter(TMatrix *Src, TMatrix *Dest, int Radius)
{
if (Src == NULL || Dest == NULL) return IS_RET_ERR_NULLREFERENCE;
if (Src->Data == NULL || Dest->Data == NULL) return IS_RET_ERR_NULLREFERENCE;
if (Src->Width != Dest->Width || Src->Height != Dest->Height || Src->Channel != Dest->Channel || Src->Depth != Dest->Depth || Src->WidthStep != Dest->WidthStep) return IS_RET_ERR_PARAMISMATCH;
if (Src->Depth != IS_DEPTH_8U || Dest->Depth != IS_DEPTH_8U) return IS_RET_ERR_NOTSUPPORTED;
if (Radius < 0 || Radius >= 127) return IS_RET_ERR_ARGUMENTOUTOFRANGE;
IS_RET Ret = IS_RET_OK;
if (Src->Data == Dest->Data)
{
TMatrix *Clone = NULL;
Ret = IS_CloneMatrix(Src, &Clone);
if (Ret != IS_RET_OK) return Ret;
Ret = MaxFilter(Clone, Dest, Radius);
IS_FreeMatrix(&Clone);
return Ret;
}
if (Src->Channel == 1)
{
TMatrix *Row = NULL, *Col = NULL;
unsigned char *LinePS, *LinePD;
int X, Y, K, Width = Src->Width, Height = Src->Height;
int *RowOffset, *ColOffSet;
unsigned short *ColHist = (unsigned short *)IS_AllocMemory(256 * (Width + 2 * Radius) * sizeof(unsigned short), true);
if (ColHist == NULL) { Ret = IS_RET_ERR_OUTOFMEMORY; goto Done8; }
unsigned short *Hist = (unsigned short *)IS_AllocMemory(256 * sizeof(unsigned short), true);
if (Hist == NULL) { Ret = IS_RET_ERR_OUTOFMEMORY; goto Done8; }
Ret = GetValidCoordinate(Width, Height, Radius, Radius, Radius, Radius, EdgeMode::Smear, &Row, &Col); // 获取坐标偏移量
if (Ret != IS_RET_OK) goto Done8;
ColHist += Radius * 256; RowOffset = ((int *)Row->Data) + Radius;
ColOffSet = ((int *)Col->Data) + Radius; // 进行偏移以便操作
for (Y = 0; Y < Height; Y++)
{
if (Y == 0) // 第一行的列直方图,要重头计算
{
for (K = -Radius; K <= Radius; K++)
{
LinePS = Src->Data + ColOffSet[K] * Src->WidthStep;
for (X = -Radius; X < Width + Radius; X++)
{
ColHist[X * 256 + LinePS[RowOffset[X]]]++;
}
}
}
else // 其他行的列直方图,更新就可以了
{
LinePS = Src->Data + ColOffSet[Y - Radius - 1] * Src->WidthStep;
for (X = -Radius; X < Width + Radius; X++) // 删除移出范围内的那一行的直方图数据
{
ColHist[X * 256 + LinePS[RowOffset[X]]]--;
}
LinePS = Src->Data + ColOffSet[Y + Radius] * Src->WidthStep;
for (X = -Radius; X < Width + Radius; X++) // 增加进入范围内的那一行的直方图数据
{
ColHist[X * 256 + LinePS[RowOffset[X]]]++;
}
}
memset(Hist, 0, 256 * sizeof(unsigned short)); // 每一行直方图数据清零先
LinePD = Dest->Data + Y * Dest->WidthStep;
for (X = 0; X < Width; X++)
{
if (X == 0)
{
for (K = -Radius; K <= Radius; K++) // 行第一个像素,需要重新计算
HistgramAddShort(ColHist + K * 256, Hist);
}
else
{
/* HistgramAddShort(ColHist + RowOffset[X + Radius] * 256, Hist);
HistgramSubShort(ColHist + RowOffset[X - Radius - 1] * 256, Hist);
*/
HistgramSubAddShort(ColHist + RowOffset[X - Radius - 1] * 256, ColHist + RowOffset[X + Radius] * 256, Hist); // 行内其他像素,依次删除和增加就可以了
}
for (K = 255; K >= 0; K--)
{
if (Hist[K] != 0)
{
LinePD[X] = K;
break;
}
}
}
}
ColHist -= Radius * 256; // 恢复偏移操作
Done8:
IS_FreeMatrix(&Row);
IS_FreeMatrix(&Col);
IS_FreeMemory(ColHist);
IS_FreeMemory(Hist);
return Ret;
}
else
{
TMatrix *Blue = NULL, *Green = NULL, *Red = NULL, *Alpha = NULL; // 由于C变量如果不初始化,其值是随机值,可能会导致释放时的错误。
IS_RET Ret = SplitRGBA(Src, &Blue, &Green, &Red, &Alpha);
if (Ret != IS_RET_OK) goto Done24;
Ret = MaxFilter(Blue, Blue, Radius);
if (Ret != IS_RET_OK) goto Done24;
Ret = MaxFilter(Green, Green, Radius);
if (Ret != IS_RET_OK) goto Done24;
Ret = MaxFilter(Red, Red, Radius);
if (Ret != IS_RET_OK) goto Done24; // 32位的Alpha不做任何处理,实际上32位的相关算法基本上是不能分通道处理的
CopyAlphaChannel(Src, Dest);
Ret = CombineRGBA(Dest, Blue, Green, Red, Alpha);
Done24:
IS_FreeMatrix(&Blue);
IS_FreeMatrix(&Green);
IS_FreeMatrix(&Red);
IS_FreeMatrix(&Alpha);
return Ret;
}
}
可以看到代码的实现和上面的流程是一致的,里面出现的新的数据结构TMatrix等都在Core.h里面实现,SSE优化的直方图加减,边界填充等函数都在Utility.h里面。获取完整源码请到我的github:https://github.com/BBuf/Image-processing-algorithm-Speed 。如果我的工程对你有用请帮我点星。
下面贴 一下直方图加减的SSE优化函数:
//函数16: 无符号短整形直方图数据相加减,即是Z = Z + Y - X
//参考: 无
//简介: SSE优化
void HistgramSubAddShort(unsigned short *X, unsigned short *Y, unsigned short *Z)
{
*(__m128i*)(Z + 0) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[0], *(__m128i*)&Z[0]), *(__m128i*)&X[0]); // 不要想着用自己写的汇编超过他的速度了,已经试过了
*(__m128i*)(Z + 8) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[8], *(__m128i*)&Z[8]), *(__m128i*)&X[8]);
*(__m128i*)(Z + 16) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[16], *(__m128i*)&Z[16]), *(__m128i*)&X[16]);
*(__m128i*)(Z + 24) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[24], *(__m128i*)&Z[24]), *(__m128i*)&X[24]);
*(__m128i*)(Z + 32) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[32], *(__m128i*)&Z[32]), *(__m128i*)&X[32]);
*(__m128i*)(Z + 40) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[40], *(__m128i*)&Z[40]), *(__m128i*)&X[40]);
*(__m128i*)(Z + 48) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[48], *(__m128i*)&Z[48]), *(__m128i*)&X[48]);
*(__m128i*)(Z + 56) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[56], *(__m128i*)&Z[56]), *(__m128i*)&X[56]);
*(__m128i*)(Z + 64) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[64], *(__m128i*)&Z[64]), *(__m128i*)&X[64]);
*(__m128i*)(Z + 72) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[72], *(__m128i*)&Z[72]), *(__m128i*)&X[72]);
*(__m128i*)(Z + 80) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[80], *(__m128i*)&Z[80]), *(__m128i*)&X[80]);
*(__m128i*)(Z + 88) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[88], *(__m128i*)&Z[88]), *(__m128i*)&X[88]);
*(__m128i*)(Z + 96) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[96], *(__m128i*)&Z[96]), *(__m128i*)&X[96]);
*(__m128i*)(Z + 104) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[104], *(__m128i*)&Z[104]), *(__m128i*)&X[104]);
*(__m128i*)(Z + 112) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[112], *(__m128i*)&Z[112]), *(__m128i*)&X[112]);
*(__m128i*)(Z + 120) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[120], *(__m128i*)&Z[120]), *(__m128i*)&X[120]);
*(__m128i*)(Z + 128) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[128], *(__m128i*)&Z[128]), *(__m128i*)&X[128]);
*(__m128i*)(Z + 136) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[136], *(__m128i*)&Z[136]), *(__m128i*)&X[136]);
*(__m128i*)(Z + 144) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[144], *(__m128i*)&Z[144]), *(__m128i*)&X[144]);
*(__m128i*)(Z + 152) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[152], *(__m128i*)&Z[152]), *(__m128i*)&X[152]);
*(__m128i*)(Z + 160) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[160], *(__m128i*)&Z[160]), *(__m128i*)&X[160]);
*(__m128i*)(Z + 168) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[168], *(__m128i*)&Z[168]), *(__m128i*)&X[168]);
*(__m128i*)(Z + 176) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[176], *(__m128i*)&Z[176]), *(__m128i*)&X[176]);
*(__m128i*)(Z + 184) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[184], *(__m128i*)&Z[184]), *(__m128i*)&X[184]);
*(__m128i*)(Z + 192) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[192], *(__m128i*)&Z[192]), *(__m128i*)&X[192]);
*(__m128i*)(Z + 200) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[200], *(__m128i*)&Z[200]), *(__m128i*)&X[200]);
*(__m128i*)(Z + 208) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[208], *(__m128i*)&Z[208]), *(__m128i*)&X[208]);
*(__m128i*)(Z + 216) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[216], *(__m128i*)&Z[216]), *(__m128i*)&X[216]);
*(__m128i*)(Z + 224) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[224], *(__m128i*)&Z[224]), *(__m128i*)&X[224]);
*(__m128i*)(Z + 232) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[232], *(__m128i*)&Z[232]), *(__m128i*)&X[232]);
*(__m128i*)(Z + 240) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[240], *(__m128i*)&Z[240]), *(__m128i*)&X[240]);
*(__m128i*)(Z + 248) = _mm_sub_epi16(_mm_add_epi16(*(__m128i*)&Y[248], *(__m128i*)&Z[248]), *(__m128i*)&X[248]);
}
//函数17: 拷贝Alpha通道的数据
//参考: 无
//简介: 直接用原始的代码,速度很好
void CopyAlphaChannel(TMatrix *Src, TMatrix *Dest) {
if (Src->Channel != 4 || Dest->Channel != 4) return;
if (Src->Data == Dest->Data) return;
unsigned char *SrcP = Src->Data, *DestP = Dest->Data;
int Y, Index = 3;
for (Y = 0; Y < Src->Width * Src->Height; Y++, Index += 4) {
SrcP[Index] = DestP[Index];
}
}
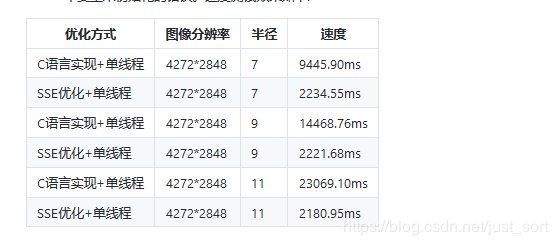
速度测试
参考和感谢
https://www.cnblogs.com/Imageshop/p/4441972.html

 京公网安备 11010502036488号
京公网安备 11010502036488号