

01 前言
InnoDB数据页的7个组成部分,各个数据页组成了一个双向链表,而每个数据页中的记录按照主键从小到大的顺序组成一个单链表,每个数据页中为这些记录生成了一个目录,可以采用二分法查找,提升查询速度。
那么问题来就来了,如果表中的记录涉及多个数据页,那又该如何查找呢?
02 没有索引的查找
为了方便理解,咱先说一个SQL语句的情况,就是最简单的精准查询,如下:
select [列名列表] from [表名] where 列名=XXX
2.1 在一个页中的查找
- 以主键为搜索条件
可以直接使用数据页中的目录进行二分查找。
- 以其他列为搜索条件
不可以使用数据页中的目录进行二分查找,只能顺序查找,一列列的对比是否满足条件。
2.2 在多个页中的查找
不管是否以主键作为搜索提交,都不能使用数据页中的目录进行二分查找,只能顺序查找,逐一对比。
结果:这样查找速度肯定是慢的,我们得想一个提升速度的方法,那么索引就出现了。
03 有索引的查找
3.1 索引是什么?
我们先来创建一个表score,并为其新增三条语句,语句如下:
create table score(
id varchar(10),
name varchar(10),
score int,
primary key (id)
);
insert into score values('001','张三',100);
insert into score values('002','李四',90);
insert into score values('004','王五',70);
根据之前我们说的,其在硬盘上的存储结构如下(假设每一页只存3条数据,其他不必要的信息都删掉了)。

如果再新增一条数据,这一页可以放不下了,需要新增一页来存放数据啦,如下图。

通过上图,我们发现003比004小,却排在了后面,不符合下一个数据页中用户记录的主键值必须大于上一页中用户记录的主键值这一标准,所以我们需要将003的这条记录和004的这条记录交换一下。
为什么要符合这一标准呢?我们在页内可以使用目录进行二分查找,提升查询速度,那么我们在页间是不是也可以采用二分查找呢?答案是肯定的,所以就要符合刚才的标准,因为二分查找的前提就是数据必须有序。
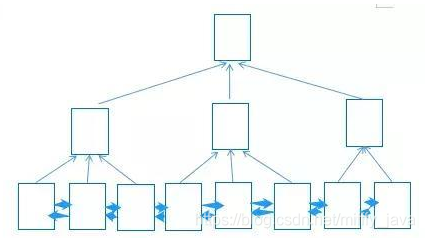
试想一下,如果有很多页数据,我们每三页合并一个大的页,大的页一共三条数据,分别对应着底下小页的最小值,但是即使这样,数据量还是很多,我们就再进行页的合并,这样就形成了下图的形式,即为B+树。
事实上,经他人统计(哈哈哈,错了好甩锅,链接见文章尾),600万的数据也就3层,so,一般情况下B+树不超过4层(包括3层目录项页和1层数据项页)。
所以,索引是对按主键排列的数据进行速度提升的一种数据结构。我自己想的,非官方概念。
3.2 万年面试题:索引为什么是B+树?而不是B树?
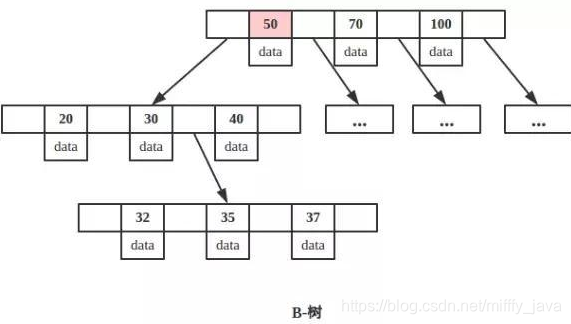
在搞清楚这个问题前,我们先来看一下什么是B树,什么是B+树?(我就盗图啦,不想自己画了)
B树:也就是B-树,主要特点是非叶子节点上不仅有指针,也有data域。
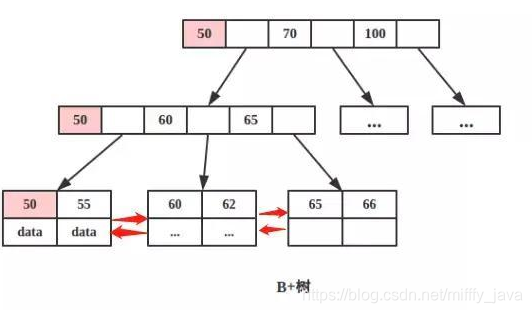
B+树:非叶子节点只有指针,没有data域,InnoDB的默认索引存储引擎。
那么问题就来了,为什么索引采用B+树呢?
- B+树的所有叶子节点都通过双向链表关联(不要问我截的图为什么没有,因为是从人家那里偷得,我已经用红色的箭头加上了),如果我想搜索范围,比如数值从60到66的,就可以直接通过叶子节点的之间的指针来获取,速度比较慢。如果使用的B树,得采用中序遍历的方式,查询速度慢。
- 之前我们有说到数据是有分成页的,而InnoDB存储引擎层是将数据页分批读取到内存,由内存对数据进行加工完返回给客户端的。如果在读取相同页数的情况下,B+树能存放的数据信息更多,因为其只有指针,没有数据,所占的内存更小。所以B+树单次磁盘IO信息大于B树,所以B+树比B树的IO次数少,当然速度也就更快。
3.3 聚簇索引
上面说的就是聚簇索引,包括两个特点:
- 使用表中定义的主键建立树形结构。页中的记录是按照主键的大小顺序排列,呈现单链表的形式,页与页之间是通过双向链表的形式相关联的。比如上面的score表主键是id,那么他的聚簇索引就是按照id从小到大的顺序排放。如果我要查id=XXX的记录,就可以直接通过该聚簇索引来采用类二分的方法查询,可以明显的提升查询速度。
- 聚簇索引的叶子节点存储的是完整的用户记录,也就是说score表中除了主键id外,name和score都存储在叶子节点中。
注意:这一点我们在辅助索引(二级索引)说,因为聚簇索引存储的是完整的用户记录,总有什么索引存储的不是完整的用户记录。
3.4 辅助索引(二级索引)
当当当,辅助索引(二级索引)到了。
如果当要查询name=XXX的记录时,我们只能通过主键id聚簇索引的叶子节点来一个个遍历,然后比对哪一个name=XXX,这样的方式就是一个遍历单链表查询,不用说了,这肯定贼慢。那有没有更好一点的方法呢?
答案肯定是有的,那就是再为name列建一个索引,根据name从小到大的顺序排列,这个就可以和主键id一样,采用类二分的形式快速查出数据。
那我们就先在name上建一个索引index_name,语句如下:
alter table score add index index_name(name)
索引已经建立好了,那么辅助索引是如何存放数据的?简易版的,讲究看看吧,哈哈哈。
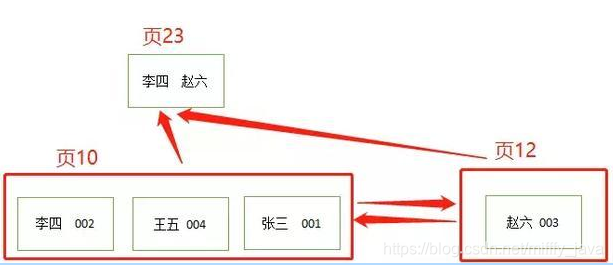
从上图中我们可以发现辅助索引的叶子节点并没有分数score字段,但是却有主键id字段,也就是他的叶子节点的数据并不完整。那么如果我们要查看李四的id,name,score这三个字段,我们就可以使用基于name的所有index_name,采用类二分法找到李四这条记录的主键id,再通过主键id去主键构成的聚簇索引查找这条记录的完整信息,这个过程叫做回表。
注意:为什么要采用回表的形式呢?因为如果辅助索引的叶子节点存放的也是完整的记录,列存放的数据越大,对内存的消耗就越明显,越浪费空间。采用回表的方式,可以节省下空间,多浪费了一些时间。那么问题就来了,如果我采用辅助索引得出来的数据量很大,已经接近于所有数据,然后再根据各自的主键id去查看完整的记录,这样的时间消耗可以比我直接采用主键索引一个个遍历对比的时间消耗来的大,那么MySQL还会选择辅助索引吗?
3.5 联合索引
比如我想找name=张三,score=100的这条记录,如果使用基于主键id的聚簇索引,只能一个个遍历并且对比,这样的速度是很慢的。或者采用基于name的辅助索引,但是辅助索引里面没有分数score字段,所以还要通过回表的方式,找到score字段,但如果name=张三的记录有100条,那我们只能找到100条数据,再挨个通过回表的方式,找到score=100的这条记录。这样看来,不管是基于主键id的聚簇索引还是基于name的辅助索引,都不是最好的方案。
所以可以创建联合索引,语句如下,他其实就是当name一样的时候,再按score进行排序,索引包括name,score,和主键id。其所对应的索引图如下,简单点啦,将就看看吧。我已经努力画了(为了测试,我多加了两条数据,005和006)。
create index name_and_score_index on score (name,score);

注意:因为这边就只有三个字段,如果字段量多的话,也是需要回表,通过主键id得到其他字段信息。
04 索引的正确打开方式
基于上面的理论知识,我们来实践一下(上面的弄得明明白白就可以)。
再介绍下背景,score表有三个字段,分别是id,name,score。其还有两个索引,一个是聚簇索引,一个是基于name和score的联合索引。
先看下面的语句,判断是不是能使用索引进行查询。如果能准确说出下面是不是有使用索引,那么下面就不要看了,就说的这些内容。
select * from score where id=XXX; 聚簇索引
select * from score where name=XXX;联合索引
select * from score where score=XXX;不使用索引
select * from score where name=XXX and score=XXX; 联合索引
select * from score where score=XXx and name=XXX; 不使用索引
select * from score order by name; 联合索引
select * from score order by score;不使用索引
前五个语句主要是最左前缀原则的使用。
第一个不用说了,如果where后面的查询条件是id,那么他直接根据聚簇索引,采用类二分法,也就是从树的根节点开始,能很快的查询到相应的记录。
第二个where后面的查询条件是name,那么也可以根据联合索引来查询。(因为联合索引是根据先name后score的方式来排序的,所以通过name查出一系列数据)。
第三个where后面的查询条件是score,那就不能用联合索引了,因为有可能不同的name有着相同的score,那么数据就是分散在各个页上的,所以只能使用聚簇索引来一个个遍历,并对比字段。
第四个和第二个类似,第五个和第三个类似。
后面两个主要是用于排序的,如果SQL语句中有根据某个字段排序,尽量让其在索引层面完成排序。如果在索引层面没有完成排序,那么就会在内存中就会浪费时间和空间来进行一系列排序算法来实现排序功能,这肯定对性能有影响。回到刚才的SQL语句,如果按name排序,则可以使用索引,因为索引是先按name排序,再按score索引的。但是如果按score排序,则不可以使用索引,因为score是后面排序的,也就是只有name一样才会按score排序,但是SQL语句需要的是全量的按照score排序。
如果觉得有所收获,就请点个赞再走呗~


 京公网安备 11010502036488号
京公网安备 11010502036488号