

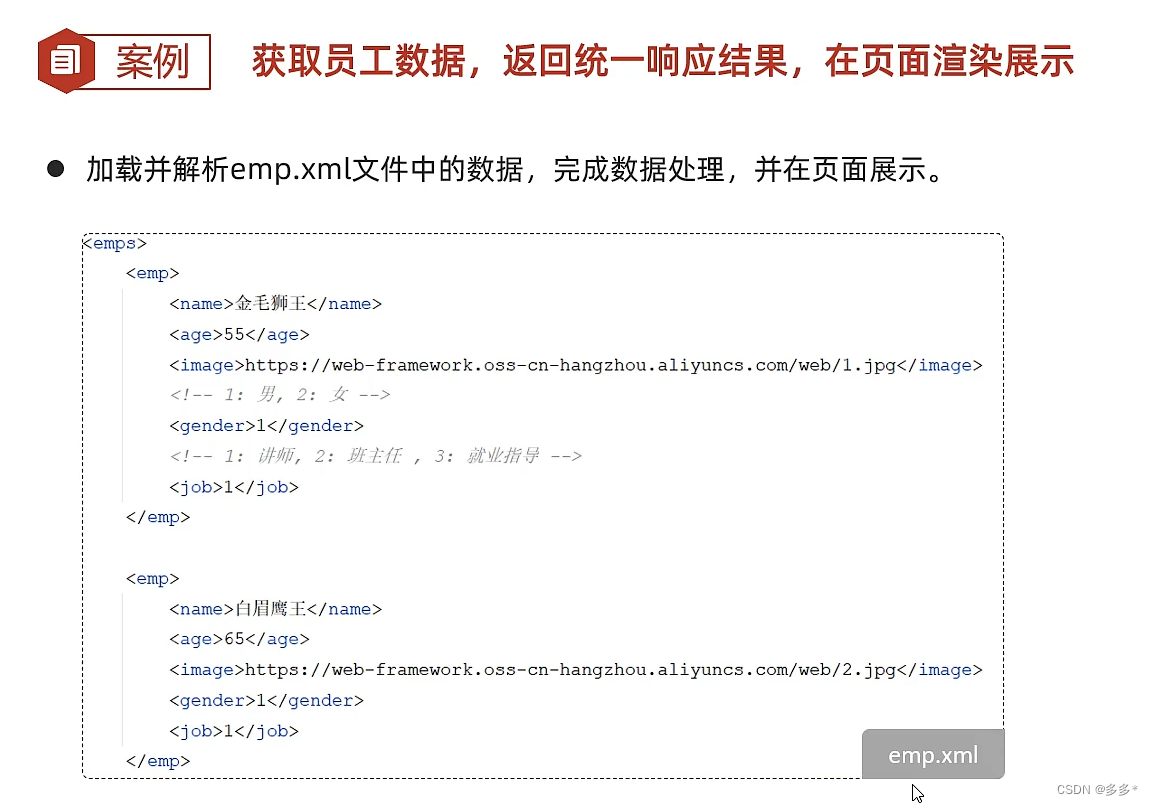
请求响应案例
步骤

步骤1 配置环境 引入依赖
我们需要引入解析dom4j的工具类
再引入一个实体类
dom4j技术
dom4j 是一个用于处理 XML 文档的 Java 库,具有以下主要作用:
-
解析 XML 文档:dom4j 可以帮助你解析 XML 文档,将 XML 文档中的数据提取出来,以便在 Java 应用程序中进行处理和操作。
-
创建 XML 文档:使用 dom4j,你可以动态地创建 XML 文档,设置元素、属性和文本内容,并将其保存为 XML 文件或输出到流中。
-
XPath 支持:dom4j 提供了对 XPath 查询语言的支持,可以方便地通过 XPath 表达式查询和定位 XML 文档中的元素。
-
XML 文档的遍历与操作:dom4j 提供了灵活的 API,使你可以轻松地遍历和操作 XML 文档的各个部分,包括元素、属性、文本节点等。
-
与其他 XML 相关技术的集成:dom4j 可以与其他 XML 相关技术(如 XSLT、XPath、XML Schema 等)配合使用,实现更加复杂的 XML 处理任务。
总的来说,dom4j 是一个功能强大且易于使用的 XML 处理库,适用于在 Java 应用程序中进行各种 XML 相关的操作和处理。
dom4j 是一个用于处理 XML 的 Java 库。如果你想在你的 Java 项目中使用 dom4j,你需要将 dom4j 库添加到你的项目依赖中。
你可以通过 Maven、Gradle 或手动下载 JAR 文件来添加 dom4j 依赖。
使用 Maven
如果你使用 Maven,可以在你的项目的 pom.xml 文件中添加以下依赖:
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.3</version>
</dependency>使用 Gradle
如果你使用 Gradle,可以在你的项目的 build.gradle 文件中添加以下依赖
groovy复制代码implementation 'org.dom4j:dom4j:2.1.3'手动下载
你也可以手动下载 dom4j 的 JAR 文件,并将它添加到你的项目的类路径中。你可以从 dom4j 的官方网站或 Maven 仓库中下载相应的 JAR 文件。
无论你选择哪种方法,确保添加了正确的版本,以满足你的项目需求。

步骤2 部署前端页面并配置Vue
对于springboot项目来说 我们是可以在项目中添加前端页面的
但是存放目录有考究 默认是放在static目录下的
一般我们推荐static目录 因为springboot工程会自动创建static目录

这里在教的就是后端处理数据的流程:获取请求、参数;处理数据业务;响应数据。到后面会封装起来的
案例中要返回统一结果 我们使用之前采用的result类
我们查看引入的html页面
发现再script标签类创建了一个vue对象
vue接管的区域是app
服务端的路径为 /listEmp

步骤3 配置后端控制器
创建类 加载员工数据 (EmpController)员工控制器
-
MVC(Model-View-Controller)中的控制器(Controller): 在软件架构中,控制器是MVC模式的一部分,负责处理用户输入并调度对应的业务逻辑处理程序(模型)和视图(View)。在Web开发中,控制器通常是处理HTTP请求的组件,根据请求的路径和参数调用相应的业务逻辑并返回结果。
-
Spring MVC中的控制器(Controller): Spring MVC是一个基于MVC模式的Web框架,其中的控制器负责接收和处理HTTP请求,并将请求委托给适当的业务逻辑处理器,最终返回响应给客户端。
-
前端开发中的控制器(Controller): 在前端开发中,控制器通常是指AngularJS、React等前端框架中的组件,负责管理视图和模型之间的交互逻辑,响应用户输入并更新视图状态。
加载xml文件 运用了工具类XmlParserUtils 事先导入的工具类
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.File;
import java.io.IOException;
public class XmlParserUtils {
// 解析XML文件并返回Document对象
public static Document parseXmlFile(String filePath) throws ParserConfigurationException, IOException, SAXException {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
return builder.parse(new File(filePath));
}
// 获取指定节点的子节点列表
public static NodeList getChildNodes(Element element, String tagName) {
return element.getElementsByTagName(tagName);
}
// 获取节点的文本内容
public static String getNodeText(Node node) {
return node.getTextContent();
}
// 获取节点的属性值
public static String getNodeAttribute(Node node, String attributeName) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
return element.getAttribute(attributeName);
}
return null;
}
// 示例用法
public static void main(String[] args) {
try {
// 解析XML文件
Document doc = parseXmlFile("example.xml");
// 获取根节点
Element root = doc.getDocumentElement();
// 获取根节点下的所有子节点
NodeList nodeList = root.getChildNodes();
// 遍历子节点
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
// 获取节点名称
String nodeName = element.getNodeName();
// 获取节点的文本内容
String nodeText = getNodeText(element);
// 获取节点的属性值
String attributeValue = getNodeAttribute(element, "attributeName");
// 打印节点信息
System.out.println("Node Name: " + nodeName);
System.out.println("Node Text: " + nodeText);
System.out.println("Attribute Value: " + attributeValue);
System.out.println();
}
}
} catch (ParserConfigurationException | IOException | SAXException e) {
e.printStackTrace();
}
}
}
对数据进行转换处理
响应数据
用类加载器获取资源
类加载器在Java中具有以下几个重要作用:
-
加载类文件: 类加载器负责将.class文件加载到内存中,并转换成对应的Class对象。这个过程是Java程序运行的基础,没有类加载器,Java程序无法运行。
-
类的唯一性和一致性: 类加载器通过委托机制,保证了类的唯一性和一致性。即同一个类文件只会被加载一次,并且被不同的类加载器加载得到的是同一个Class对象。
-
实现类加载的安全机制: 类加载器可以根据特定的策略来加载类文件,例如根据类路径、URL等。这种灵活性可以实现类加载的安全控制,防止恶意类文件的加载和执行。
-
实现模块化和动态加载: 类加载器可以根据需要动态加载类文件,从而实现模块化的程序设计和动态扩展功能。例如,在Java的模块化系统中,可以通过自定义类加载器实现模块的动态加载和卸载。
-
实现类的加载优化: 类加载器可以根据具体的应用场景实现类的加载优化,例如缓存已加载的类、延迟加载等。这样可以提高程序的性能和效率。
-
支持类的热部署: 类加载器可以在运行时动态加载新的类文件,从而实现类的热部署功能。这对于需要频繁更新和修改的应用程序是非常有用的。
总的来说,类加载器在Java中扮演着至关重要的角色,它不仅负责将类文件加载到内存中,还可以实现一些额外的功能,如模块化、安全控制、动态加载等,为Java程序的灵活性和可扩展性提供了基础支持。
用类加载器


因为返回值的是result 统一的一个响应结果
响应统一结果 所以我们要将empList传递进方法
然后数据类型就是json形式的

并且响应回去了统一的数据 就是这个empList集合

控制器 EmpController
做的是解析xml文件 将数据放到泛型为emp的集合里去
然后将集合用Result类里面的success方法
将数据封装到result里面去
返回统一的响应结果
这样我们就获取到了接口数据
用postman测试接口数据

启动springboot工程
访问本地端服务器 这样就能展示页面

代表我们的程序已经搭建完毕
分层解耦
在 web 开发中,三层架构通常指的是将一个应用程序分为三个逻辑层:表示层(Presentation Layer)、业务逻辑层(Business Logic Layer)和数据访问层(Data Access Layer)。
-
表示层(Presentation Layer):
- 表示层是用户与应用程序交互的界面,通常是用户界面(UI)或者用户体验(UX)层。
- 它负责接收用户的请求,展示信息给用户,并将用户的输入传递给业务逻辑层进行处理。
- 在 web 开发中,表示层通常由 HTML、CSS、JavaScript 和用户界面框架(如 React、Vue.js 等)来实现。
-
业务逻辑层(Business Logic Layer):
- 业务逻辑层负责处理应用程序的业务逻辑,即应用程序中真正的核心功能。
- 它接收表示层传递过来的请求,执行相应的业务逻辑,然后将结果返回给表示层。
- 在这一层中,会进行数据处理、业务规则验证、逻辑运算等操作,以确保应用程序的正确运行。
- 业务逻辑层通常由后端服务器端的编程语言和框架(如 Python 的 Django、Java 的 Spring、Node.js 的 Express 等)实现。
-
数据访问层(Data Access Layer):
- 数据访问层负责与数据存储(通常是数据库)进行交互,从而实现数据的持久化和管理。
- 它负责执行数据库操作(如查询、插入、更新、删除等),并将数据返回给业务逻辑层进行处理。
- 数据访问层的设计应该独立于具体的数据库类型,以便于在需要时更换数据库而不需要修改业务逻辑层的代码。
- 数据访问层通常由数据库访问框架或 ORM(对象关系映射)库来实现,如 SQLAlchemy(Python)、Hibernate(Java)、Sequelize(Node.js)等。
示意图以及自我理解


前端发起请求 先到达controller层
然后交给service层执行业务逻辑
service层向dao层拿数据
然后处理后再交给controller层
controller层返回给前端页面展示给用户
思考
我们以后软件设计开发时
要尽量让每一个类 接口 方法功能单一
单一职责原理
一个类 接口 方法只管自己的区域
这样有利于代码的拓展与维护
那么我们刚刚的请求案例书写就存在代码冗余的问题
改进请求响应案例
我们在上一个案例中的所有方法都写在了一个控制器方法中
代码冗余 逻辑复杂
代码的复用性太差 难以拓展 难以维护

web开发三层架构分析

 我们在Java包下通常这样书写
我们在Java包下通常这样书写

使用三层架构将大数据展示在前端页面有几个好处:
-
分层清晰:三层架构将应用程序分为数据访问层、业务逻辑层和表示层(UI层),使得各层的职责清晰明确。这样的结构使得系统更易于理解、维护和扩展。
-
可维护性:由于各层之间的明确分离,使得系统的维护更为容易。例如,如果需要更改数据访问逻辑,可以只修改数据访问层,而不影响业务逻辑层和表示层。
-
可扩展性:三层架构使得系统的各个部分相对独立,因此很容易实现水平或垂直扩展。例如,如果需要增加更多的数据源或者改变数据处理方式,可以只对数据访问层进行修改而不影响其他层。
-
性能优化:通过在不同层次上分配和优化资源,可以更有效地管理系统的性能。例如,可以在数据访问层使用缓存技术来提高数据检索的速度,而在表示层使用异步加载来提高页面加载速度。
-
安全性:通过在不同层次上实施安全措施,可以增强系统的安全性。例如,可以在数据访问层实施访问控制来限制对数据库的访问,而在表示层实施输入验证来防止恶意输入。
这是我最近在做的数据可视化ppt 其中我就展示了web开发的三层架构


 京公网安备 11010502036488号
京公网安备 11010502036488号