1. 定向选择、不定项选择和填空题
主要考察了卷积神经网络参数量计算、感知野计算、卷积后图像的大小计算、GAN 的损失函数、贝叶斯网络、L1 L2正则化、概率论、Python、Shell、数据库等知识,比较全面琐碎。
2. 编程题
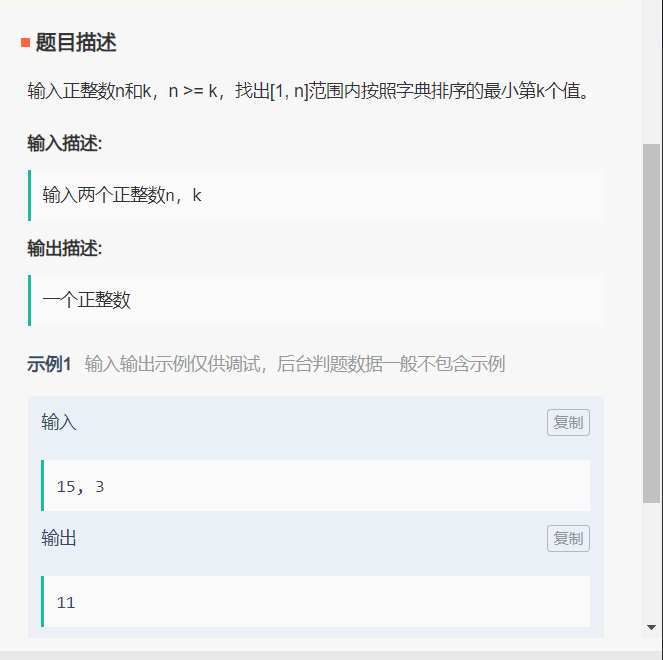
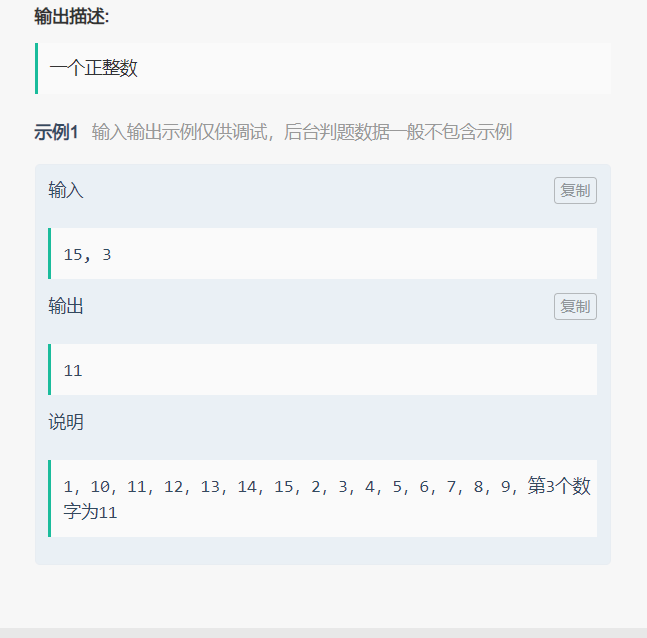
详见 LeetCode 386——字典序的第 K 小数字
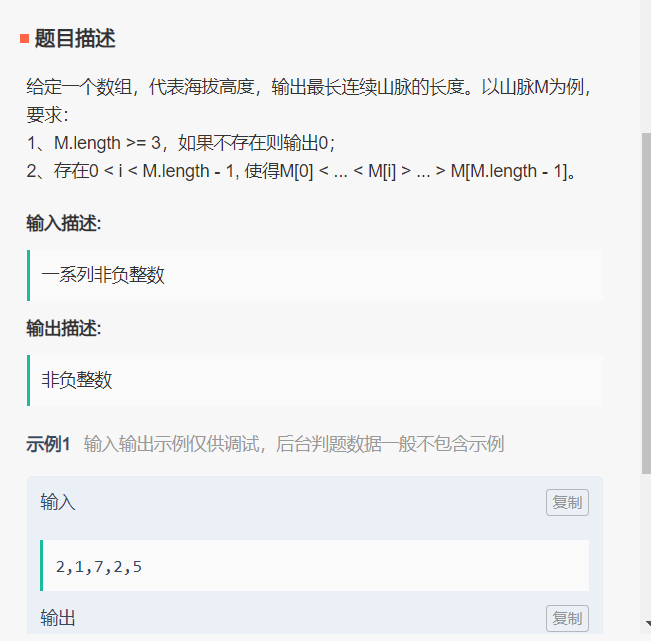
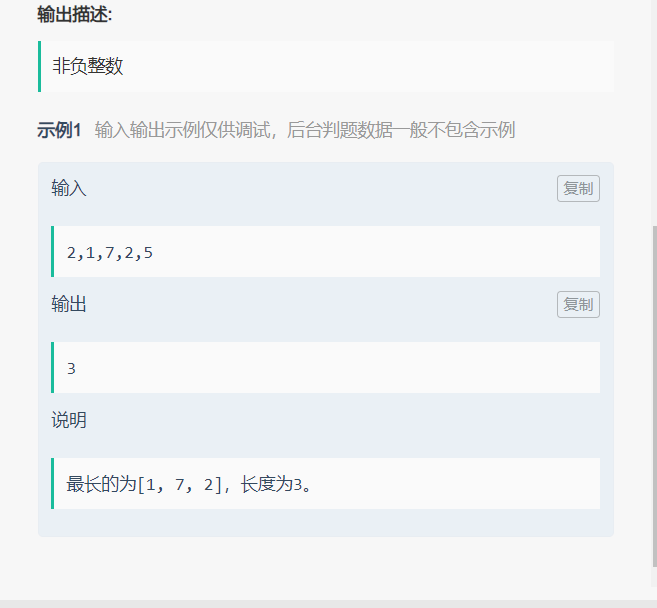
详见 LeetCode 845——数组中的最长山脉
3. 简答题
支持向量机的基本模型为
{min21∣∣w∣∣2s.t.yi(wTxi+b)⩾1,i=1,2,...m(1)
对上式的约束添加拉格朗日乘子 αi⩾0,则该问题的拉格朗日函数可写为
L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))(2)
令 L(w,b,α) 对 w 和 b 的偏导为零可得
w=i=1∑mαiyixi(3)
0=i=1∑mαiyi(4)
将 (3) 式代入到 (2) 式,并考虑 (4) 式的约束,就可以得到式 (1) 的对偶问题
⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧maxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t.i=1∑mαiyi=0αi⩾0,i=1,2,...m(5)
- Sigmoid 和 Relu 求导,Relu 相较 Sigmoid 优点,怎么解决梯度消失和爆炸
Sigmoid 函数
f(z)=1+e−z1
f′(z)=(1+e−z)2e−z=1+e−z1⋅1+e−ze−z=f(z)⋅(1−f(z))
Relu 函数
f(z)=max(0,z)
f′(z)={10if z>0if z<0
Relu 相较 Sigmoid 梯度较大,神经网络收敛速度较快。
梯度消失:BN、引入残差网络
梯度爆炸:BN、梯度裁剪
Dropout 每次会让一部分神经元随机失活,这样就不会让某一个神经元占据主导作用,也就是不会让某一个神经元的权重过大,从而可以避免过拟合。反向传播的时候我们只将梯度反向传播到那些激活的神经元上去即可。
获取更多精彩,请关注「seniusen」!




 京公网安备 11010502036488号
京公网安备 11010502036488号