

CUDA:一个在 GPU 上计算的新架构 CUDA ( Compute Unified Device Architecture ) 统一计算设备架构,在 GPU 上发布的一个新的硬件和软件架构,它不需要映射到一个图型 API 便可在 GPU 上管理和进行并行数据计算。从 G80 系列和以后的型号都可以支持。操作系统的多任务机制通过几个 CUDA 和图型应用程序协调运行来管理访问 GPU 。
DRAM DRAM(Dynamic Random Access Memory),即动态随机存取存储器,最为常见的系统内存。DRAM 只能将数据保持很短的时间。为了保持数据,DRAM使用电容存储,所以必须隔一段时间刷新(refresh)一次,如果存储单元没有被刷新,存储的信息就会丢失。 (关机就会丢失数据)
On-chip 内存共享在global Memory部分,数据对齐和连续是很重要的话题,当使用L1的时候,对齐问题可以忽略,但是非连续的获取内存依然会降低性能。依赖于算法本质,某些情况下,非连续访问是不可避免的。使用shared memory是另一种提高性能的方式。global memory就是一块很大的on-board memory,并且有很高的latency。而shared memory正好相反,是一块很小,低延迟的on-chip memory,比global memory拥有高得多的带宽。我们可以把他当做可编程的cache,其主要作用有:
- An intra-block thread communication channel 线程间交流通道
- A program-managed cache for global memory data可编程cache
- Scratch pad memory for transforming data to improve global memory access patterns
一个超多线程协处理器当通过 CUDA 编译时, GPU 可以被视为能执行非常高数量并行线程的计算设备。它作为主 CPU 的一个协处理器。
协处理器 协处理器,这是一种协助中央处理器完成其无法执行或执行效率、效果低下的处理工作而开发和应用的处理器。这种中央处理器无法执行的工作有很多,比如设备间的信号传输、接入设备的管理等;而执行效率、效果低下的有图形处理、声频处理等。为了进行这些处理,各种辅助处理器就诞生了。需要说明的是,由于现在的计算机中,整数运算器与浮点运算器已经集成在一起,因此浮点处理器已经不算是辅助处理器。而内建于CPU中的协处理器,同样不算是辅助处理器,除非它是独立存在。
DMA DMA(Direct Memory Access,直接内存存取) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用。
线程批处理 线程批处理就是执行一个被组织成多线程块的kernel,如图2-1
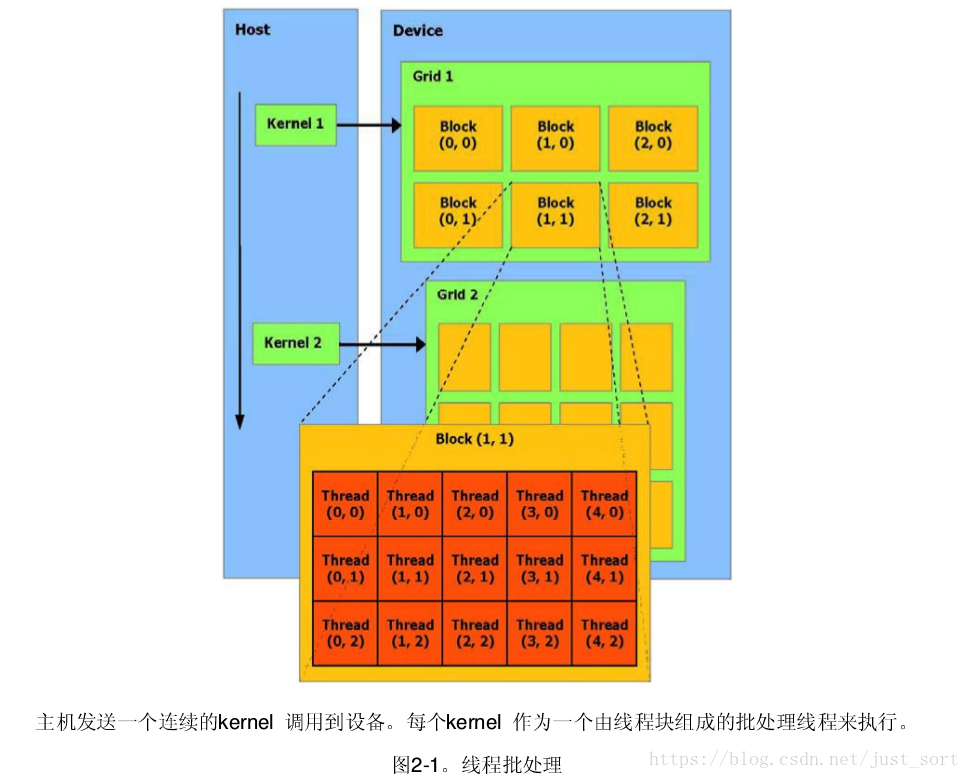
线程块一个线程块是一个线程的批处理,它通过一些快速的共享内存有效地分享数据并且在制定的内存访问中同
步它们的执行。更准确地说,它可以在 Kernel 中指定同步点,一个块里的线程被挂起直到它们所有都到达同步点。每条线程是由它的线程 ID 所确定, ID 是在块之内的线程编号。根据线程的 ID 可以帮助进行复杂寻址,一个应用程序可以指定一个块作为一个二维或三维数组的任意大小,并且通过一个 2 - 或 3- 组件索引代替来指定每条线程。对于一个大小为 二维块,线程的索引是 (x, y) ,这个线程 ID 是 。而对于一个三维的大小为 的块,这个线程的索引是 (x , y , z) , 线程的 ID 是 。
线程块栅格 一个块可以包含的线程最大数量是有限的。然而,执行同一个 kernel 的块可以合成一批线程块的栅格,因
此通过单一 kernel 发送的请求的线程总数可以是非常巨大的。线程协作的减少会造成性能的损失,因为来自同一个栅格的不同线程块中的线程彼此之不间能通讯和同步。这个模式允许 kernel 用不同的并行能力有效地运行在各种设备上而不用再编译:一个设备可以序列地运行栅格的所有块,如果它有非常少的并行特性,或者并行地运行,如果它有很多的并行的特性,或者通常是二者的组合。
内存模型 一条执行在设备上的线程,只允许通过以下的内存空间使用设备的DRAM和On-Chip内存,如下图所示:

- 读写每条线程的寄存器
- 读写每条线程的本地内存
- 读写每个块的共享内存
- 读写每个栅格的全局内存
- 读写每个栅格的常量内存
- 读写每个栅格的纹理内存
全局,常量,和纹理内存空间可以通过主机或者同一应用程序持续的通过 kernel 调用来完成读取或写入。
全局,常量,和纹理内存空间对不同内存的用法加以优化。纹理内存同样提供不同的寻址模式,也为一些
特殊的数据格式进行数据过滤。
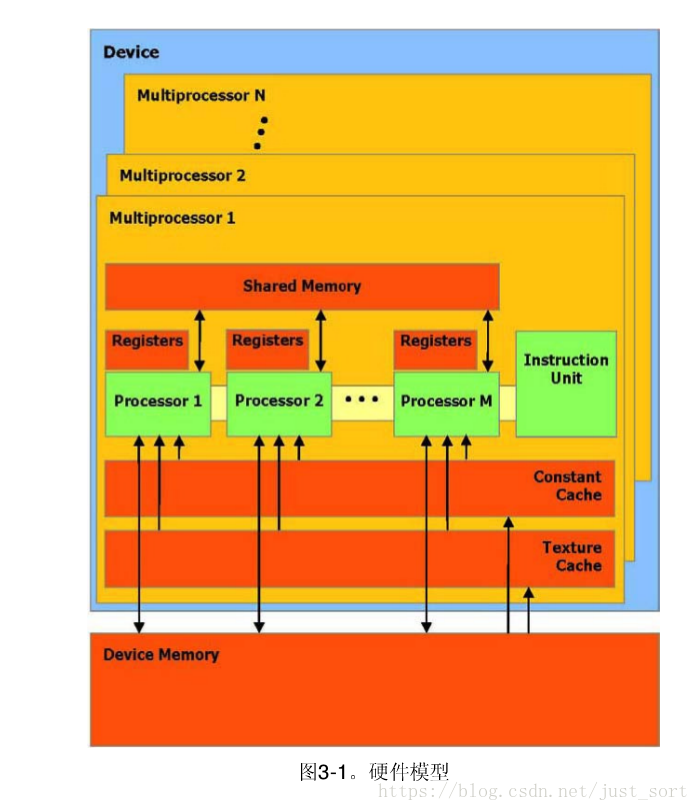
一组带有on-chip共享内存的SIMO多处理器 设备可以被看作一组多处理器,如图 3-1 所示。每个多处理器使用单一指令,多数据架构 (SIMD) :在任何给定的时钟周期内,多处理器的每个处理器执行同一指令,但操作不同的数据。每个多处理器使用四个以下类型的 on-chip 内存:
- 每个处理器一组本地 32 位寄存器
- 并行数据缓存或共享内存,被所有处理器共享实现内存空间共享
- 通过设备内存的一个只读区域,一个只读常量缓冲器被所有处理器共享
- 通过设备内存的一个只读区域,一个只读纹理缓冲器被所有处理器共享
本地和全局内存空间作为设备内存的读写区域,而不被缓冲。每个多处理器通过纹理单元访问纹理缓冲器,它执行各种各样的寻址模式和数据过滤。
active 线程块在一个批处理中被一个多处理器执行,被称作 active 。每个 active 块被划分成为 SIMD 线程组,称为 warps; 每一条这样的 warp 包含数量相同的线程,叫做 warp 大小,并且在 SIMD 方式下通过多处理器执行 ; 线程调度程序周期性地从一条 warp 切换到另一条 warp ,以达到多处理器计算资源使用的最大化。块被划分成为 warp 的方式总是相同的 ; 每条 warp 包含连续的线程,线程索引从第一个 warp 包含着的线程0开始递增。
计算兼容性 设备的计算兼容性由两个参数定义,主要版本号和次要版本号。设备拥有相同的主要版本号代表相同的核
心架构。在附录 A 中列出的设备全部是 1.x (它们的主要版本号是 1 )。次要版本号代表一些改进的核心架构,比如新的特性。不同计算兼容性的技术规格见附录 A 。
多设备 为一个应用程序使用多GPU 作为CUDA 设备,必须保证这些GPU 是一样的类型。如果系统工作在SLI 模式下,那么只有一个GPU 可以作为CUDA 设备,由于所有的GPU 在驱动堆栈中被底层的融合了。SLI 模式需要在控制面板中关闭,这样才能事多个GPU 作为CUDA设备。
SLI SLI的全称是Scalable Link Interface(可升级连接接口)也称速力,是英伟达公司的专利技术。它是通过一种特殊的接口连接方式,在一块支持双PCI Express X 16的主板上,同时使用两块同型号的PCIE显卡。 以增强NVIDIA在工作站产品中的竞争力,毕竟ATI凭借FireGL系列在该领域不断蚕食NVIDIA的市场。在未来的产品线中,SLI将成为新的至高点。
模式切换 GPU 指定一些DRAM 来存储被称作primary surface 的内容,这些内容被用于显示输出。如果用户改变显示的分辨率或者色深,那么primary surface 的存储需求量将改变。比如,如果用户将显示分辨率从1280x1024x32bit 到1600x1200x32bit ,系统必须指定7.68MB 的primary surface 而不在是5.24MB。(使全屏抗锯齿的应用程序需要更多的primary surface空间)。另外,比如在Windows 中使用Alt+Tab 的切换,或者Ctrl+Alt+Del 的操作同样需要额外的primary surface 空间。如果模式切换增加了primary surface 的内存空间,系统将占用CUDA 指定的内存空间,导致程序崩溃。
C语言扩展 CUDA 编程接口的目标是为熟悉 C 语言的用户提供一个相对简单的途径来编写设备执行程序,应该强调的是,只有来自C 标准库的函数支持在设备上运行,是由公共Runtime 的组件提供的函数。
函数类型限定词
__device____device__限定词声明一个函数是:设备上执行的,仅可以从设备调用__global____global__在设备上执行仅可以从主机调用__host____host__限定词声明的函数是在主机上执行的,仅可从主机调用,它等于声明一个函数仅仅带有__host__限定词或者声明它没有任何__host__,__device__,或__global__限定词;在其他情况下这个函数仅仅为主机编译。然而__host__限定词也可以用于与__device__的组合,这种情况下这个函数是为主机设备双方编译。__device__和__global__函数不支持递归__device__和__global__函数不能声明静态变量在它们体内__device__和__global__函数不能有自变量的一个变量数字__device__函数不可能取得它们的地址;另一方面,函数指向__global__函数是支持的
不能一起使用__global__和__host__限定词__global__函数必须有void的返回类型。任何调用到一个__global__函数必须指定它的执行配置,如在4.2.3部分所描述。对一个__global__函数的调用是同步的,意味着在设备执行完成前返回。__global__函数参数目前是通过共享内存到设备的,并且被限制在256个字节__device__限定词声明驻留在设备上的一个变量,最多的一个其他类型限定词被定义在下面的三项里,可以与__device__一起共同用于进一步指定变量归属在哪些内存空间。如果它们都不存在,这个变量:
- 驻留在全局内存空间
- 具有应用的生存期
- 从栅格内所有线程和从主机通过runtime库是可访问的
__constant__限定词,与__device__一起随机使用,声明一变量:
- 驻留在常量内存空间
- 具有应用的生存期
- 从栅格内所有线程和从主机通过runtime库是可以访问的
__shared__限定词,与__device__一起选择使用,声明一个变量:
- 驻留在线程块的共享内存空间中
- 具有块的生存期
- 只有块之内的所有线程是可访问的
在线程***享的变量有完全的顺序一致性。只有执行过一个__syncthreads()函数,从其他线程的写才保证可见。除非变量被定义为可挥发的,否则只要前一个状态到达,编译器将自由的优化共享内存中的读写。当声明一个在共享内存的变量作为一个外部数组时,例如:extern_shared_float_shared[];数组的大小是由发送时间 ( 参见第 4.2.3 部分 ) 决定的。所有变量用这种方式声明的,开始于内存的同一个地址,因此在数组的变量布局必须通过 offset( 位移量 ) 明确地加以控制。例如,如果你想要等于
short arry0[128];
float array1[64];
int array[256]; 在动态分配的共享内存,你可以用以下方式定义数组:
extern __shared__ short array[];
__device__ void func() //__device__or__global__function
{
Short* array0 = (short*)array;
float* array1 = (float*)&array0[128];
int* array2 =
(int*)&array1[64];
}NVCC编译 nvcc 是编译 CUDA 代码过程的编译器驱动程序的简称:它提供简单和熟悉的命令行选项,并且通过调用
实施不同编译阶段汇集的工具来执行它们。

 京公网安备 11010502036488号
京公网安备 11010502036488号