

文章目录
1. Siamese Recurrent Architectures for Learning Sentence Similarity
模型结构
Manhattan LSTM Model
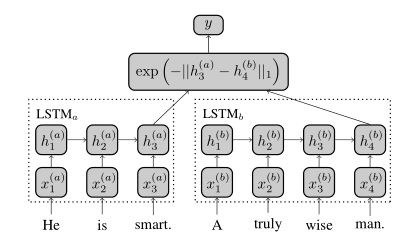
先通过一个Embedding层,这部分用预训练的word2vec等词向量就可以了.
之后使用两个共享权重的LSTM提取特征, 将最后的output作为句的向量表示.
定义一种新的相似性函数: g(hTa(a),hTbb)=exp(−∣∣hTa(a)−hTbb∣∣1∈[0,1])
为了拟合数据集[1, 5]评分,最后又加了一层没有参数的回归层.
实验
参数设置
word_embedding: 300
hidden_dim: 50
opitmizer: Adadelta(with gradient clipping)
损失函数使用MSE而不是交叉熵.(因为它测试的数据集是用[1, 5]的评分衡量句子对的相关度,是回归问题而不是分类)
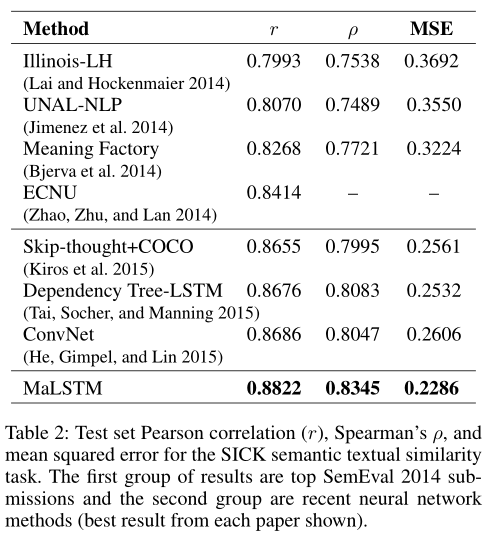
实验结果
2. Learning Text Similarity with Siamese Recurrent Networks
和上面那篇模型很相似, 稍微复杂些
模型结构
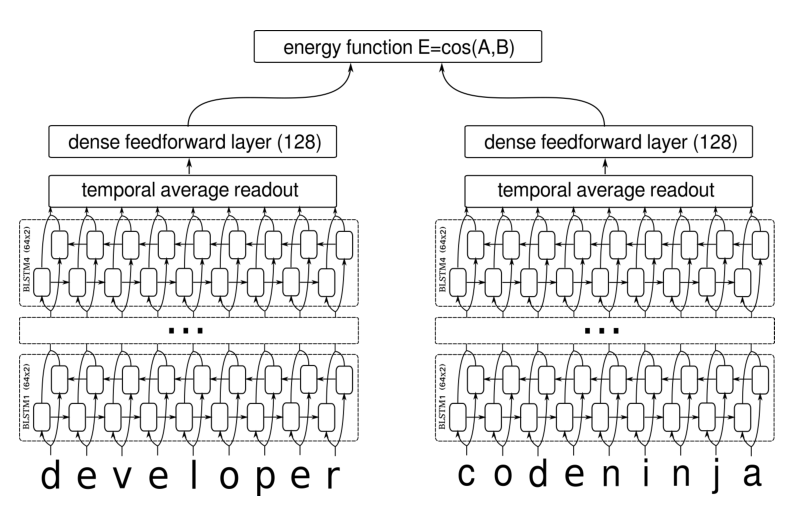
与第一篇的区别:
- 这篇论文采用的是字向量而不是词向量, 可以解决OOV问题.
- 采用Bi-LSTM
- 损失函数不同
Contrastive loss function
使用余弦距离 ∣∣fW(x1)∣∣∣fW(x2)∣∣EW(x1,x2)=<fW(x1),fW(x2)>
损失函数 LW(i)=y(i)L+(x1(i),x2(i))+(1−y(i))L−(x1(i),x2(i))
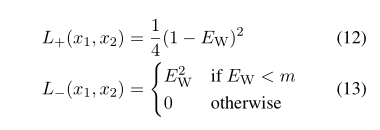

 京公网安备 11010502036488号
京公网安备 11010502036488号