

文章目录
论文贡献: 提出了一种双向的多角度匹配模型(bilateral multi-perspective matching).
Method
Model Overview
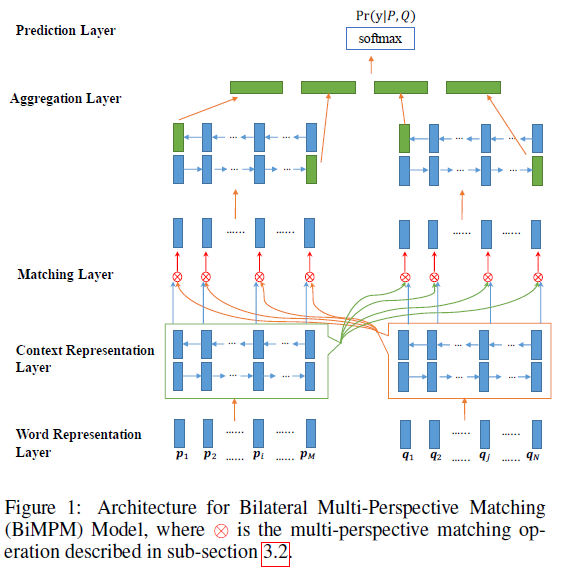
1. Word Representation Layer
The goal of this layer is to represent each word in P and Q with a d-dimensional vector.
输入向量由两部分组成:一部分是固定的词向量(Glove或者word2vec),另一部分是字符向量构成的词向量.字符向量是随机初始化然后输入到LSTM学习得到的.
2. Context Representation Layer
这一层目的是将上下文信息融合到 P 和 Q 每个 time-step 的表示中,这里利用 Bi-LSTM 去得到 P 和 Q 每个time-step 的上下文向量。
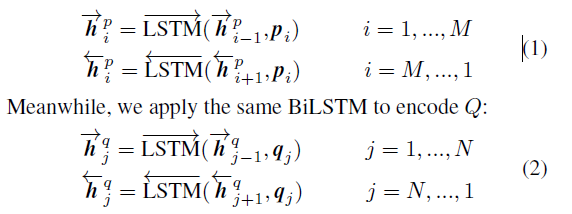
3. Matching Layer
模型的关键层.
比较句子 P 的每个上下文向量(time-step)和句子 Q 的所有上下文向量(time-step),比较句子 Q 的每个上下文向量(time-step)和句子 P 的所有上下文向量(time-step)。为了比较一个句子中某个上下文向量(time-step)和另外一个句子的所有上下文向量(time-step),这里设计了一种 multi-perspective 的匹配方法 ⊗,用于获取两个句子细粒度的联系信息。
这层的输出是两个序列,序列中每一个向量是一个句子的某个 time-step 相对于另一个句子所有的 time-step 的匹配向量。
4. Aggregation Layer
这层主要功能是聚合两个匹配向量序列为一个固定长度的匹配向量。对两个匹配序列分别使用 Bi-LSTM,然后连接 Bi-LSTM 最后一个 time-step 的向量(4个)得到最后的匹配向量。
5. Prediction Layer
这层目的是计算概率 Pr(y∣P,Q).前一次的输出连接两层前馈神经网络,之后再加上softmax输出结果.
Multi-prespective Matching Operation
重点介绍下论文提出的多角度匹配算法.
论文中提到多角度匹配运算 ⊗有以下两步:
1.定义多角度余弦匹配方程 fm来比较两个向量 m=fm(v1,v2;W)
这里 v1,v2是两个d-dimensional向量, W是一个 l×d维的学习参数, m是一个 l维向量,其中 mk表示第k个角度,具体计算方式 mk=cosine(Wk∘v1,Wk∘v2) 这里 ∘表示element-wise multiplication.
2.基于上步提到的 fm, 定义了四种匹配策略来比较一个句子的某个 time-step 与另一个句子的所有 time-step.
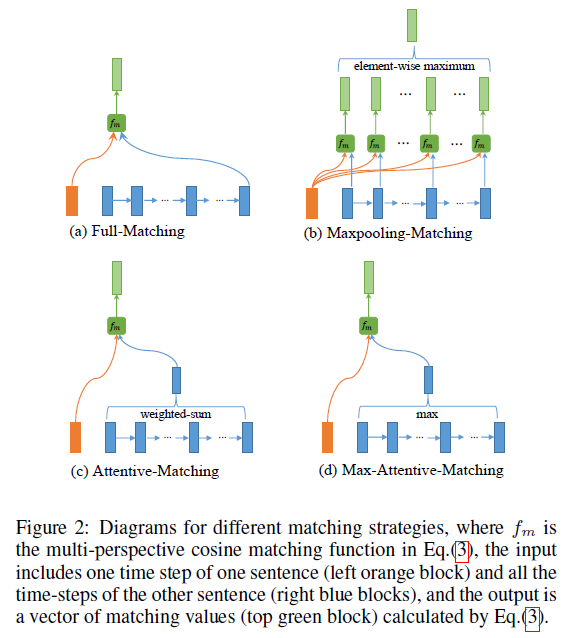
- 第一种 Full-Matching
取一个句子的某个 time-step 和另一个句子的最后一个 time-step 做比较
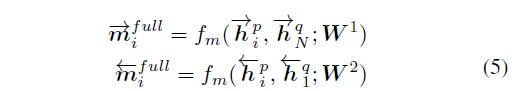
- 第二种 Maxpooling-Matching
取一个句子的某个 time-step 和另一个句子的所有 time-step 比较后取最大
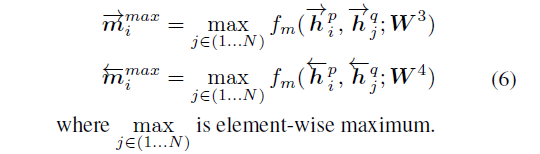
- 第三种 Attentive-Matching
首先计算一个句子的某个 time-step 和另一个句子的所有 time-step 的余弦相似度,类似 Attention 矩阵。
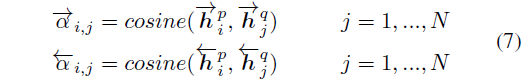
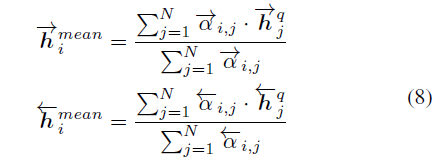
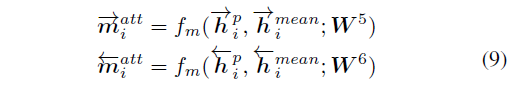
-
第四种 Max-Attentive-Matching
和第三种类似,不过最后attentive vector是求max而不是mean.对句子每一个time-step都使用了以上四种匹配策略,之后将这8个匹配向量进行concatenate.
实验
实验设置
word_embedding: 300(freeze)
OOV: initialize randomly
character-composed embedding: 初始化为20维向量, 然后将每个词输入到50维的lstm
BiLSTM hidden layer: 100
dropout: 0.1
损失函数: cross entropy
optimizer: ADAM
learning rate: 0.001
实验结果
实验了三个任务:
- Paraphrase Identification
- Natural Language Inference
- Answer Sentence Selection
数据集1 Quora Question pairs

数据集2 SNLI
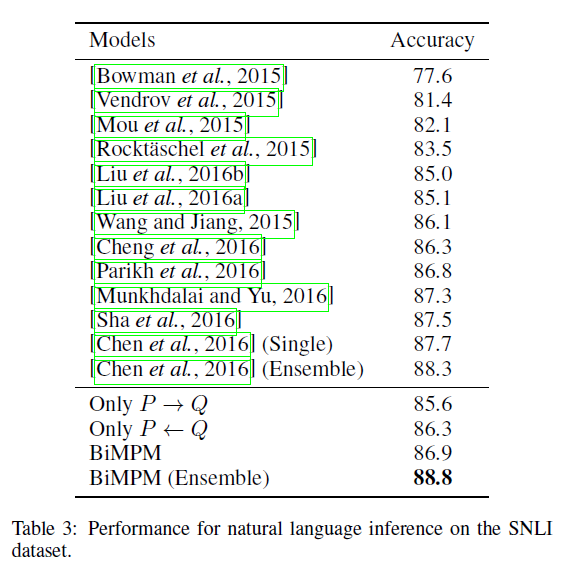
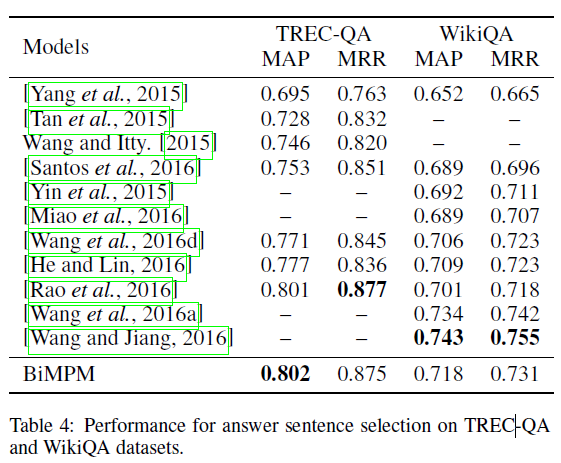
数据集3 TREC-QA WikiQA

 京公网安备 11010502036488号
京公网安备 11010502036488号