

Dynamic Convolutional Neural Network
一、介绍
一篇14年的很经典的论文, 模型采用动态k-max pooling取出得分topk的特征值,能处理不同的句子,不依赖解析树。网络包含两种类型的层:一维的卷积层和动态k-max池化层(Dynamic k-max pooling)。
k-max pooling:
- pooling的结果不是返回一个最大值,而是返回k组最大值,这些最大值是原输入的一个子序列;
- pooling中的参数k可以是一个动态函数,具体的值依赖于网络的其他参数。
二、模型的特点
- 保留了句子中词序信息和词语之间的相对位置;
- 宽卷积的结果是传统卷积的一个扩展,某种意义上,也是n-gram的一个扩展,更加考虑句子边缘的信息;
- 模型不需要任何先验知识,并且模型考虑了句子中相隔较远的词语之间的语义信息。
三、模型结构及原理
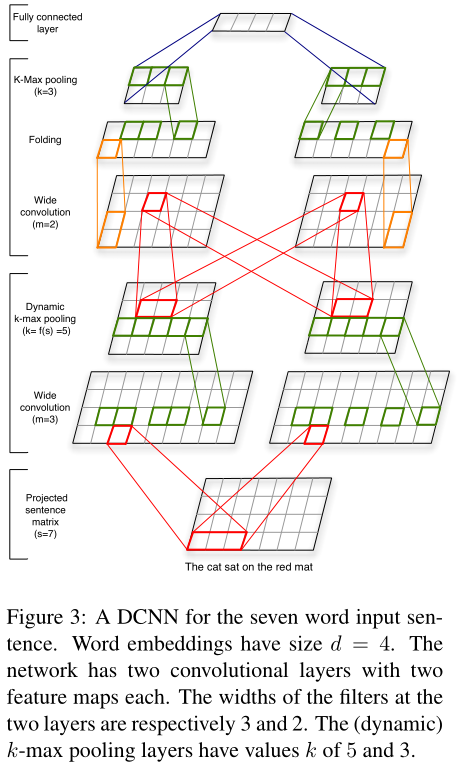
可以发现和textCNN不同, 这里卷积是做的二维卷积.
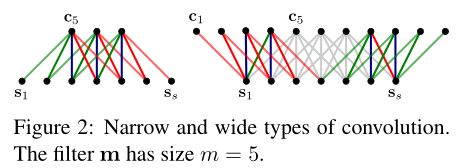
1. 宽卷积
卷积层使用 宽卷积(Wide Convolution) 的方式。
与传统卷积操作相比,宽卷积输出Feature Map宽度更宽,因为卷积窗口并不需要覆盖所有的输入值。
感觉就是先padding吧.
2. k-max池化
k-max pooling选择序列p中的前k个最大值,这些最大值保留原来序列的词序。
k-max pooling的好处在于,既提取句子中的较重要信息(不止一个),同时保留了它们的次序信息。同时,由于应用在最后的卷积层上只需要提取出k个值,所以这种方法允许不同长度的输入。
3. 动态k-max池化
所谓动态k-max池化, 就是k值是动态变化的.
k是输入句子长度和网络深度两个参数的函数。
Kl=max(ktop,⌈LL−ls⌉)
l表示当前卷积的层数, L是网络总共卷积层的层数; ktop为最顶层卷积层pooling对应的k值,是一个固定值;s是输入句子的长度。
动态k-max池化的意义在于,从不同长度的句子中提取出相应数量的语义特征信息,以保证后续卷积层的统一性。
4. 非线性特征函数
对pooling层的输出做非线性变化
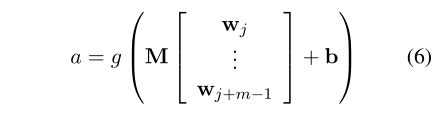
5. 多个Feature Map
和传统CNN一样, 提取出多个featured map以保证提取特征的多样性.
6. 折叠操作(Folding)
之前的宽卷积是在输入矩阵d×s中的每一行内进行计算操作,其中d是word vector的维数,s是输入句子的词语数量。而Folding操作则是考虑相邻的两行之间的某种联系,方式也很简单,就是将两行的vector相加;该操作没有增加参数数量,但是提前(在最后的全连接层之前)考虑了特征矩阵中行与行之间的某种关联.
实验
optimizer: Adagrad
实验1 Sentiment Prediction in Movie Reviews
数据集:SST
参数设置:
word embedding: 48
卷积核大小: 7和5
k-max pooling: k=4
第一层feature map:6
第二层feature map: 14

实验2 Question Type Classification
数据集: TREC
参数设置:
word embedding: 32
feature map: 8, 5
pytorch实现k-max pooling
def kmax_pooling(x, dim, k):
index = x.topk(k, dim = dim)[1].sort(dim = dim)[0]
return x.gather(dim, index)

 京公网安备 11010502036488号
京公网安备 11010502036488号