

目录
通俗理解极大似然估计
举个例子:假设有一百个男生,我们抽取五十个人进行身高的统计。 我们根据先验知识知道,身高服从高斯分布 ,但高斯分布的方差和均值不知道。 我们想通过抽取出的五十个人升高估计这两个参数,这就是极大似然估计。

后面累乘的那部分就是:假设已知参数,抽取每个同学的概率。 对于咱们这个问题,就是累乘我们抽取50个学生的概率。在那100多个男生中,我一抽就抽到这50个男生,而不是其他人,那说明在整个男生中,这50个人(的身高)出现的概率最大啊,这个概率就是上面这个似然函数L(θ)。 也就是使L(θ)最大的情况下,求未知的那个参数。
一般求极大似然估计的方法:
- 写出似然函数;
- 对似然函数取对数,并整理; (这里去对数似然只是为了好运算)
- 求导数,令导数为0,得到似然方程;
- 解似然方程,得到的参数即为所求;
EM算法引例
现在有两枚硬币A和B,假定随机抛掷后正面朝上概率分别为PA,PB。为了估计这两个硬币朝上的概率,咱们轮流抛硬币A和B,每一轮都连续抛5次,总共5轮:
| 硬币 | 结果 | 统计 |
|---|---|---|
| A | 正正反正反 | 3正-2反 |
| B | 反反正正反 | 2正-3反 |
| A | 正反反反反 | 1正-4反 |
| B | 正反反正正 | 3正-2反 |
| A | 反正正反反 | 2正-3反 |
第一轮用A抛,出现了三正两反,第二轮用B抛,出现了三反两正 ,依次可从上表中观察到。那我们现在算PA和PB就变得非常简单:
PA = (3+1+2)/ 15 = 0.4 # A总共抛了15次,总共有6次正面,那概率一目了然
PB= (2+3)/10 = 0.5 # B总共抛了15次,总共有5次正面,那概率一目了然
那么问题来了,如果我们不知道抛的硬币是A还是B呢(即硬币种类是隐变量),然后再轮流抛五轮,得到如下结果:
| 硬币 | 结果 | 统计 |
|---|---|---|
| 不知道 | 正正反正反 | 3正-2反 |
| 不知道 | 反反正正反 | 2正-3反 |
| 不知道 | 正反反反反 | 1正-4反 |
| 不知道 | 正反反正正 | 3正-2反 |
| 不知道 | 反正正反反 | 2正-3反 |
此时的我们,不知道每一次用什么抛的,那PA和PB咋算呢?
显然,此时我们多了一个硬币种类的隐变量,设为z,可以把它认为是一个5维的向量(z1,z2,z3,z4,z5),代表每次投掷时所使用的硬币,比如z1,就代表第一轮投掷时使用的硬币是A还是B。
但是,这个变量z不知道,就无法去估计PA和PB,所以,我们必须先估计出z,然后才能进一步估计PA和PB。
可要估计z,我们又得知道PA和PB,这样我们才能用极大似然概率法则去估计z,这不是鸡生蛋和蛋生鸡的问题吗,如何破?
答案就是先随机初始化一个PA和PB,用它来估计z,然后基于z,还是按照最大似然概率法则去估计新的PA和PB,如果新的PA和PB和我们初始化的PA和PB一样,请问这说明了什么?这说明我们初始化的PA和PB是一个相当靠谱的估计!
就是说,我们初始化的PA和PB,按照最大似然概率就可以估计出z,然后基于z,按照最大似然概率可以反过来估计出P1和P2,当与我们初始化的PA和PB一样时,说明是P1和P2很有可能就是真实的值。这里面包含了两个交互的最大似然估计。
如果新估计出来的PA和PB和我们初始化的值差别很大,怎么办呢?就是继续用新的P1和P2迭代,直至收敛。
我们不妨这样,先随便给PA和PB赋一个值,比如:
硬币A正面朝上的概率PA = 0.2
硬币B正面朝上的概率PB = 0.7
然后,我们看看第一轮抛掷最可能是哪个硬币。
如果是硬币A,得出3正2反的概率为 0.2*0.2*0.2*0.8*0.8 = 0.00512
如果是硬币B,得出3正2反的概率为0.7*0.7*0.7*0.3*0.3=0.03087
然后依次求出其他4轮中的相应概率。做成表格如下(标粗表示其概率更大):
| 轮数 | 若是硬币A | 若是硬币B |
| 1 | 0.00512,即0.2 0.2 0.2 0.8 0.8,3正-2反 | 0.03087,3正-2反 |
| 2 | 0.02048,即0.2 0.2 0.8 0.8 0.8,2正-3反 | 0.01323,2正-3反 |
| 3 | 0.08192,即0.2 0.8 0.8 0.8 0.8,1正-4反 | 0.00567,1正-4反 |
| 4 | 0.00512,即0.2 0.2 0.2 0.8 0.8,3正-2反 | 0.03087,3正-2反 |
| 5 | 0.02048,即0.2 0.2 0.8 0.8 0.8,2正-3反 | 0.01323,2正-3反 |
按照最大似然法则(就看这一轮谁投,出现这种将局面的概率大):
第1轮中最有可能的是硬币B
第2轮中最有可能的是硬币A
第3轮中最有可能的是硬币A
第4轮中最有可能的是硬币B
第5轮中最有可能的是硬币A
我们就把概率更大,即更可能是A的,即第2轮、第3轮、第5轮出现正的次数2、1、2相加,除以A被抛的总次数15(A抛了三轮,每轮5次),作为z的估计值,B的计算方法类似。然后我们便可以按照最大似然概率法则来估计新的PA和PB。
PA = (2+1+2)/15 = 0.33
PB =(3+3)/10 = 0.6
设想我们是全知的神,知道每轮抛掷时的硬币就是如本文本节开头标示的那样,那么,PA和PB的最大似然估计就是0.4和0.5(下文中将这两个值称为PA和PB的真实值)。那么对比下我们初始化的PA和PB和新估计出的PA和PB:
| 初始化的PA | 估计出的PA | 真实的PA | 初始化的PB | 估计出的PB | 真实的PB |
| 0.2 | 0.33 | 0.4 | 0.7 | 0.6 | 0.5 |
看到没?我们估计的PA和PB相比于它们的初始值,更接近它们的真实值了!就这样,不断迭代 不断接近真实值,这就是EM算法的奇妙之处。
可以期待,我们继续按照上面的思路,用估计出的PA和PB再来估计z,再用z来估计新的PA和PB,反复迭代下去,就可以最终得到PA = 0.4,PB=0.5,此时无论怎样迭代,PA和PB的值都会保持0.4和0.5不变,于是乎,我们就找到了PA和PB的最大似然估计。
EM算法公式推导
从分布是p(x|θ)的总体样本中抽取到这50个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本,现在我们想找到每个样本隐含的类别z,能使得p(x,z)最大。p(x,z)的极大似然估计如下:
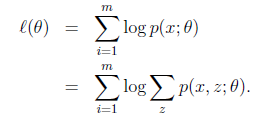
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与极大似然不同的只是似然函数式中多了一个未知的变量z,见下式(1)。也就是说我们的目标是找到适合的θ和z,以让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?
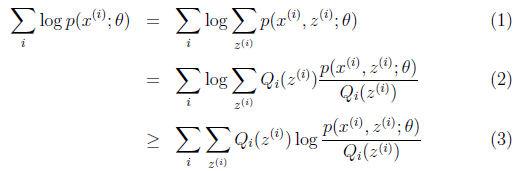
本质上我们是需要最大化(1)式,也就是似然函数,但是可以看到里面有“和的对数”,求导后形式会非常复杂(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)复合函数的求导),所以很难求解得到未知参数z和θ。
我们把分子分母同乘以一个相等的函数(即隐变量Z的概率分布Qi(z(i)),其概率之和等于1,即),即得到上图中的(2)式,但(2)式还是有“和的对数”,还是求解不了,咋办呢?接下来,便是见证神奇的时刻,我们通过Jensen不等式可得到(3)式,此时(3)式变成了“对数的和”,如此求导就容易了。我们此时就可以通过找(3)式的最大值来找(2)式的最大值。
从(2)式到(3)式,神奇的地方有两点:
当我们在求(2)式的极大值时,(2)式不太好计算,我们便想(2)式大于某个方便计算的下界(3)式,而我们尽可能让下界(3)式最大化,直到(3)式的计算结果等于(2)式,便也就间接求得了(2)式的极大值;
Jensen不等式,促进神奇发生的Jensen不等式到底是什么来历呢?
Jensen不等式
设f是定义域为实数的函数
- 如果对于所有的实数x,f(x)的二次导数
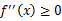 ,那么f是凸函数。
,那么f是凸函数。 - 当x是向量时,如果其hessian矩阵H是半正定的(
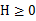 ),那么f是凸函数。
),那么f是凸函数。 - 如果
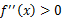 或者
或者 ,那么称f是严格凸函数。
,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X]),通俗的说法是函数的期望大于等于期望的函数。
特别地,如果f是严格凸函数,当且仅当 ,即 是
常量时,上式取等号,即:
如下图所示
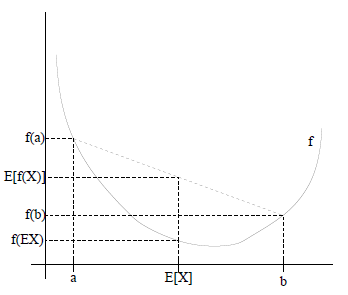
图中,实线f是凸函数(因为函数上方的区域是一个凸集),X是随机变量,有0.5的概率是a,有0.5的概率是b(就像抛硬币一样)。X的期望值就是a和b的中值了,可以很明显从看出: 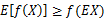
现在我们来看看上式(2)到(3)变化过程:
首先:(2)式中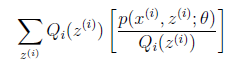 就是
就是 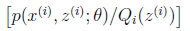 的期望。为什么?回想期望公式中的Lazy Statistician规则,如下:
的期望。为什么?回想期望公式中的Lazy Statistician规则,如下:
设Y是随机变量X的函数
(g是连续函数),那么
(1) X是离散型随机变量,它的分布律为
,k=1,2,…。若
绝对收敛,则有
(2) X是连续型随机变量,它的概率密度为
,若
绝对收敛,则有
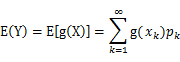
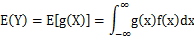
这里我们提期望干什么? 因为jensen不等式就是讨论的期望的函数值,和函数值的期望之间的关系。
又因为f(x)=log x为凹函数,所以这里的jensen不等式变为: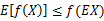
对照Jensen不等式,我们就可以将(2)式转换到(3)式 。如下图(期望的函数值大于函数值的期望)
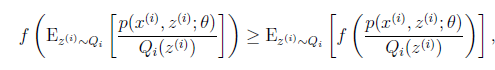
OK,到这里,现在式(3)就容易地求导了,但是式(2)和式(3)是不等号啊,式(2)的最大值不是式(3)的最大值啊,而我们想得到式(2)的最大值,那怎么办呢?
上面的式(2)和式(3)不等式可以写成:似然函数L(θ)>=J(z,Q),我们可以通过不断的最大化这个下界J,来使得L(θ)不断提高,最终达到L(θ)的最大值。
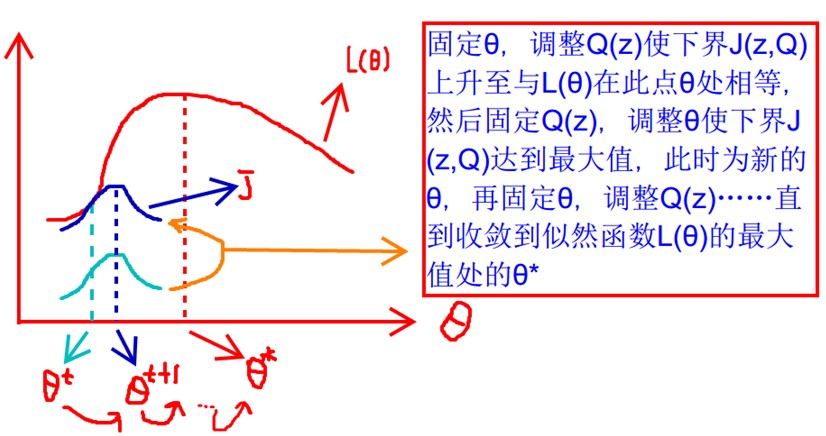
见上图,我们固定θ,调整Q(z)使下界J(z,Q)上升至与L(θ)在此点θ处相等(绿色曲线到蓝色曲线),然后固定Q(z),调整θ使下界J(z,Q)达到最大值(θt到θt+1),然后再固定θ,调整Q(z)……直到收敛到似然函数L(θ)的最大值处的θ*。
EM算法的流程
我们来总结下,期望最大EM算法是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
换言之,当我们不知道隐变量z的具体取值时(比如是硬币A还是硬币B),也就不好判断硬币A或硬币B正面朝上的概率θ,既然这样,那就
1 随机初始化分布参数θ
2 然后循环重复直到收敛 {
(E步,求Q函数)对于每一个i,计算根据上一次迭代的模型参数来计算出隐性变量的后验概率(其实就是隐性变量的期望),来作为隐藏变量的现估计值:
(M步,求使Q函数获得极大时的参数取值)将似然函数最大化以获得新的参数值
关于后面的证明就不总结了。
参考博客:
July大神的博客地址https://blog.csdn.net/v_JULY_v/article/details/81708386

 京公网安备 11010502036488号
京公网安备 11010502036488号