定义符号:
Xi=j=1∑NXi,jPi,k=XiXi,kratioi,j,k=Pj,kPi,k
| ratioi,j,k的值 | 单词j,k相关 | 单词j,k不相关 |
| 单词i,k相关 | 趋近1 | 很大 |
| 单词i,k不相关 | 很小 | 趋近1 |
推导:
假设已经得到词向量,则词向量和共现矩阵应该具有很好的一致性。假设词向量$v_i ,v_j, v_k$计算 ratioi,j,k的函数为 g(wi,wj,wk),则:
Pj,kPi,k=ratioi,j,k=g(wi,wj,wk)
需要等式左右尽可能接近,所以代价函数:
J=i,j,k∑N(Pj,kPi,k−g(wi,wj,wk))2
但是模型包括三个单词,复杂度 N∗N∗N。
如何简化:
- 要考虑单词i和j之间的关系,则g大概会有 wi−wj;
- ratioi,j,k是标量,g也应该是标量,所以g应该包含 (wi−wj)Twk;
- 再套上指数运算 exp(),最终 g(wi,wj,wk)=exp((wi−wj)Twk)
Pj,kPi,k=g(wi,wj,wk)Pj,kPi,k=exp((wi−wj)Twk)Pj,kPi,k=exp(wiTwk−wjTwk)Pj,kPi,k=exp(wjTwk)exp(wiTwk)
可以看出:
Pi,j=exp(wiTwj) log(Xi,j)−log(Xi)=wiTwj log(Xi,j)=wiTwj+bi+bj
损失函数变为:
J=i,j∑N(wiTwj+bi+bj−log(Xi,j))2
矩阵分解方法,有个缺点,就是各个词的权重是一样的
基于出现频率越高的词对权重应该越大的原则,损失函数添加权重项:
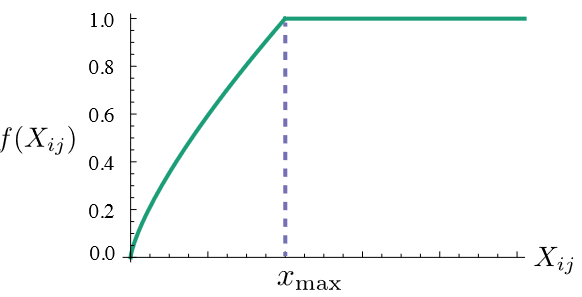
J=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2 f(x)={(x/xmax)0.75,1,if x<xmaxif x>=xmax



 京公网安备 11010502036488号
京公网安备 11010502036488号