

模型
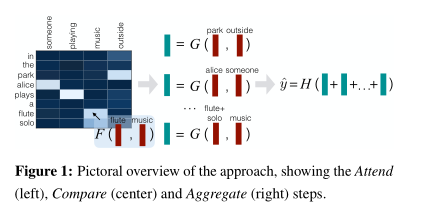
模型主要包括四部分: Input representation, Attend, Compare, Aggregate
Input representation
最简单的方式就是直接将词向量作为输入.更复杂的方式见后面optinal部分.
Attend
首先计算a和b中的每个词之间的attention weights
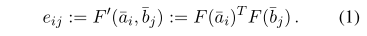
F是一个激活函数为ReLU的前馈神经网络。
attention权重如下:
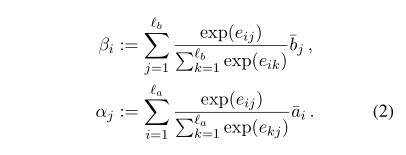
Compare
该模块的功能主要是对加权后的一个句子与另一个原始句子进行比较
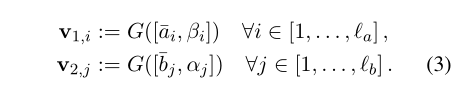
这里的G也是一个前馈神经网络
Aggregate
上一步得到两个比较向量的集合,分别求和

将两个向量concatenate后使用前馈神经网络进行分类, 损失函数利用交叉熵损失函数

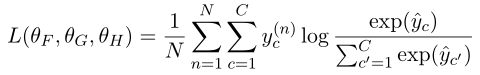
Intra-Sentence Attention(Optional)
上面的模型使用词向量作为输入, 除此之外, 还可以在每个句子中使用句子内的attention方式来加强输入词语的语义信息.

这里 Fintra也是一个前馈神经网络
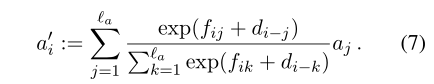
这里的 di−j表示当前词i与句子中的其他词j之间的距离偏差,所有距离大于10的词共享一个距离偏差(distance-sensitive bias),这样每一个时刻的输入就变为原始输入跟self-attention后的值的拼接所得到的向量 aˉi:=[ai,ai′],bˉj:=[bj,bj′]
参数设置
- embedding_size: 300(freeze)
- embedding之后加一个projection变成200
- 所有参数随机高斯初始化(mean 0, standard deviation 0.01)
- dropout: 0.2(除了最后输出, 其他所有的全连接之前都加)
- learning rate: 0.05(vanilla) 0.025(intro-attention)
- optimizer: Adagrad
- 前馈网络都是两层(hidden size=200)
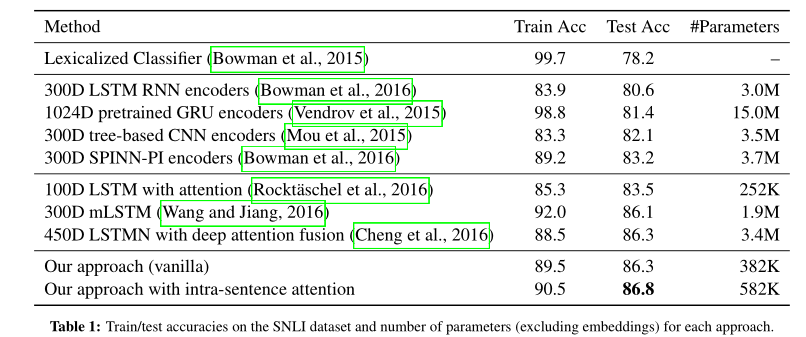
实验
使用SNLI数据集

 京公网安备 11010502036488号
京公网安备 11010502036488号