

概述
一篇17年的论文, 采用无监督的方法.
主要思想可以概括为两步:
- 利用词嵌入方法,通过词向量的线性的加权组合对一个句子进行编码
- 利用奇异向量求出最终的句向量。
算法

实验
1. Textual Similarity Tasks
数据集
- all the datasets from SemEval semantic textual similarity (STS) tasks (2012-2015)
- the SemEval 2015 Twitter task
- the SemEval 2014 Semantic Relatedness task
实验设置
词向量分别采用了无监督的GloVe和弱监督的PSL.
α固定为 10−3, 词频利用commoncrawl dataset进行统计.
实验结果

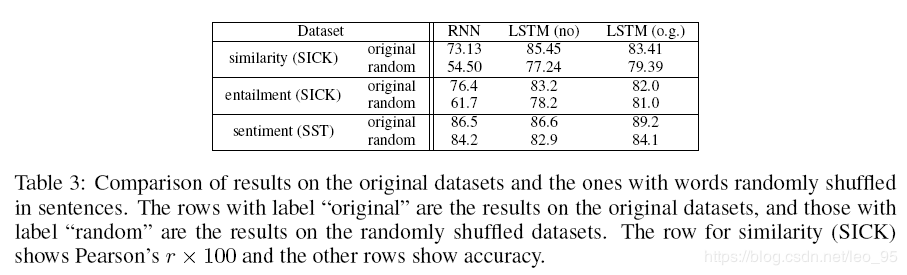
2. Supervised Tasks
- the SICK similarity task
- the SICK entailment task
- the Stanford Sentiment Treebank (SST) binary classification task
实验结果

 京公网安备 11010502036488号
京公网安备 11010502036488号