

文章目录
DPCNN
与之前CNN模型相比, 加深了很多.通过不断加深网络,可以抽取长距离的文本依赖关系. 参考了ResNet结构.
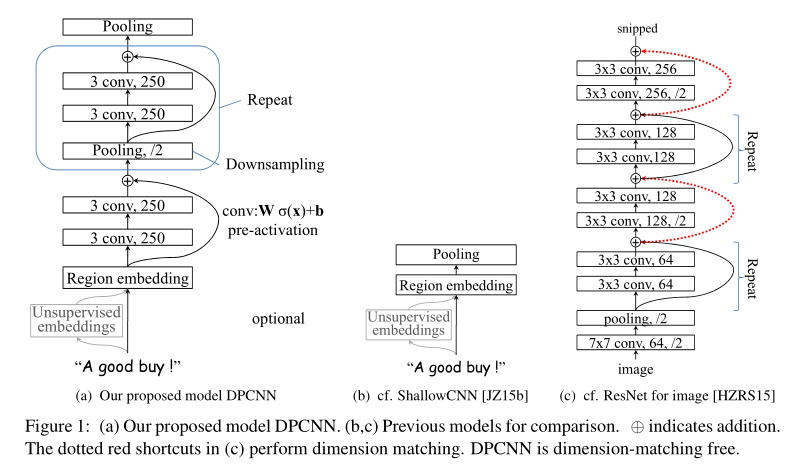
模型结构
等长卷积
首先交代一下卷积的的一个基本概念。一般常用的卷积有以下三类:
假设输入的序列长度为n,卷积核大小为m,步长(stride)为s,输入序列两端各填补p个零(zero padding),那么该卷积层的输出序列为(n-m+2p)/s+1。
- 窄卷积(narrow convolution): 步长s=1,两端不补零,即p=0,卷积后输出长度为n-m+1。
- 宽卷积(wide onvolution) :步长s=1,两端补零p=m-1,卷积后输出长度 n+m-1。
- 等长卷积(equal-width convolution): 步长s=1,两端补零p=(m-1)/2,卷积后输出长度为n。如下图所示,左右两端同时补零p=1,s=3。
池化
那么DPCNN是如何捕捉长距离依赖的呢?Downsampling with the number of feature maps fixed。
作者选择了适当的两层等长卷积来提高词位embedding的表示的丰富性。然后接下来就开始 Downsampling (池化)。再每一个卷积块(两层的等长卷积)后,使用一个size=3和stride=2进行maxpooling进行池化。序列的长度就被压缩成了原来的一半。其能够感知到的文本片段就比之前长了一倍。
固定feature maps(filters)的数量
为什么要固定feature maps的数量呢? 许多模型每当执行池化操作时,增加feature maps的数量,导致总计算复杂度是深度的函数。与此相反,作者对feature map的数量进行了修正,他们实验发现增加feature map的数量只会大大增加计算时间,而没有提高精度。
固定了feature map的数量,每当使用一个size=3和stride=2进行maxpooling进行池化时,每个卷积层的计算时间减半(数据大小减半),从而形成一个金字塔。

Shortcut connections with pre-activation
网络太深会有以下问题:
-
初始化CNN的时,往往各层权重都初始化为很小的值,这导致了最开始的网络中,后续几乎每层的输入都是接近0,这时的网络输出没有意义;
-
小权重阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代好久才能启动;
-
就算网络启动完成,由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题。
所以, 论文参考ResNet, 采用Shorcut connection, 这样就可以极大的缓解了梯度消失问题.
另外, 在做卷积运算时, 作者采用了pre-activation的做法.也就是说, 卷积运算是 Wσ(x)+b, 而不是通常用的 σ(Wx+b), 直观上,这种“线性”简化了深度网络的训练.
Text region embedding
作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对一个文本区域/片段(比如3-gram)进行一组卷积操作后生成的embedding。
另外,作者为了进一步提高性能,还使用了tv-embedding (two-views embedding)进一步提高DPCNN的accuracy。也就是引入预训练的词向量.
最终, 输入的词向量变为 Wx+∑u∈UW(u)z(u)+b.
x就是Basic region embedding, z(u)则表示x中每个词的词向量
实验
数据集及预处理
数据集就是几个常用的分类数据集:
- AG
- Sougou
- Dbpedia
- Yelp
- Yahoo
- Amazon
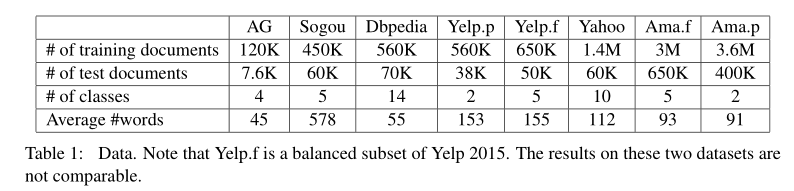
预处理主要是大小写转换. 另外对数据vocabulary size限制为3w.
参数设置
- optimizer: SGD with momentum 0.9
- epoch: 在AG数据集上50, Yelp和Dbpedia上30, 其他数据集15
- batch size: 100
- dropout: 0.5
- region size: {1, 3, 5}
- 模型深度: 15(15 means 7 convolution blocks of 2 layers plus 1 layer for region embedding.)
- 另外, 为了防止过拟合, 设置了early-stopping.
- Unsupervised embedding不进行fine-tuning.
结果

 京公网安备 11010502036488号
京公网安备 11010502036488号