

UMFiT
Introduction
文章贡献点:
- 利用迁移学习的思想, 提出基于微调的通用语言模型(ULMiT)
- 提出discriminative fine-tuning, slanted triangular learning rates, gradual unfreezing等方法
Model
进入正题, 先来看下模型结构
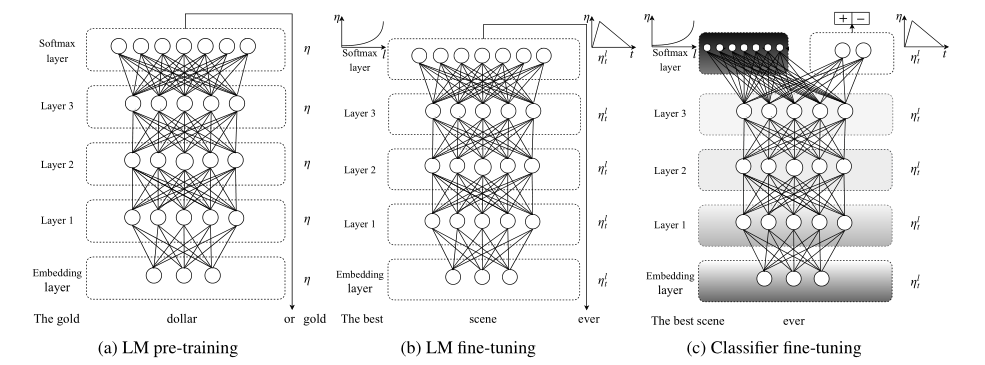
首先预训练一个语言模型, 论文中采用的是AWD-LSTM(没有attention, short-cut connection, 只是加了很多dropout等防止过拟合的策略).
整个模型训练主要分为三部分:
- General-domin LM pretraining
- Target task LM fine-tuning
- Target task classifier fine-tuning
1. General-domin LM pretraining
在Wikitext-103上预训练一个语言模型, 其中包含28595篇处理过的文章.
预训练对小数据集的任务帮助很大.
2. Target task LM fine-tuning
利用目标任务数据集对预训练模型进行fine-tuning.
针对fine-tuning, 提出discriminative fine-tuning和slanted triangular learning rates.
Discriminative fine-tuning
对于不同层可以设置不同的学习率.
SGD更新方程变为:
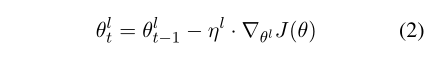
其中, ηl−1=ηl/2.6
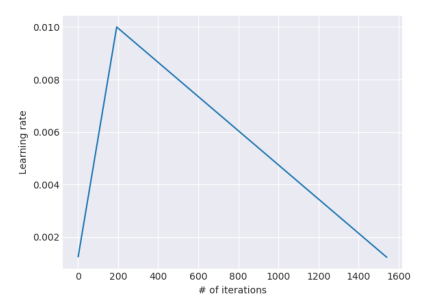
Slanted triangular learning rates(STLR)
学习率一开始线性增长, 之后再线性降低.

这里, T是训练的迭代次数. cut就代表学习率从增长改为下降的迭代次数
3. Target task classifier fine-tuning
为了fine-tuning分类器, 在预训练模型基础上加了两层全连接.
每层都使用batch normalization和dropout, 并用ReLU作为中间层激活函数, 最后加上softmax输出结果.
Concat pooling
对隐藏层分别进行max-pooling和avg-pooling, 之后和隐藏层时间T的输出做拼接:
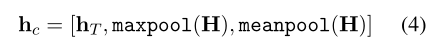
Gradual unfreezing
作者提出, 太“急躁”的微调会很快失去通过LM学到features的优势; 太谨慎的微调会导致收敛太慢,甚至过拟合。所以想出逐渐解冻的方法, 从最后一层开始, 每个epoch解冻一层, 直到fine-tune所有层, 模型收敛.
BPTT for Text Classification (BPT3C)
为了让在大数据集上fine-tuning更灵活, 提出新的反向传播算法.
具体地, 将一个文档分成固定长度的batches, 在每个batch开始, 模型用上一个batch最后状态来初始化.
实验
参数设置
embedding size: 400
语言模型使用三层双向的AWD-LSTM.
hidden layer: 1150
BPTT batch size: 70
dropout: 全连接设置为0.4, RNN层0.3, 输入embedding层0.4.
分类器的hidden layer: 50
batch size: 64
base LR: 0.004
fine-tuning LR: 0.01

 京公网安备 11010502036488号
京公网安备 11010502036488号