

MT-DNN
Introduction
学习文本的向量空间表达对许多自然语言理解问题都很重要.
现在两个比较流行的方法是
- multi-task learning
- language model pre-training
在这篇论文中, 作者提出结合两种方法的网络–Multi-Task Deep Neural Network(MT-DNN).
1. Multi-Task learning
multi-task learning优点:
- 监督学习往往需要大量的标注样本, 但有时候标注数据并不容易取得. MTL可以利用相关的多个任务的标注数据来训练.
- MTL获益于正则化, 可以避免发生对一个特定任务出现过拟合.
2. language model pretraining
语言模型预训练借助大量无标注数据进行预训练.比如最近很火的ELMo, GPT, BERT都是采用预训练的思想. 对于特定的下游任务, 利用预训练模型进行fine-tuning就可以获得不错的效果.
目前的做法都是采用其中一个方法去训练, 但是作者认为以上两种方法其实是可以互补的.
MT-DNN在训练上和BERT类似, 包括两个阶段: pre-training和fine-tuning.
不同的是, MT-DNN在fine-tuning阶段进行multi-tasks learning.
Tasks
MT-DNN包含了四个NLU任务:
- single-sentence classification
- pairwise text classification
- text similarity scoring
- relevance ranking
Model

模型包括两大部分:
- Shared layers
- Task specific layers
Shared layers
shared layer包括两个encoder:
- lexicon encoder
- transformer encoder
对于一个输入 X, 首先通过lexicon encoder层 l1得到embedding vectors, 然后, 在 l2层transformer编码器通过self-attention机制捕捉每个词的上下文信息, 生成上下文embeddings.
下面展开介绍下:
Lexicon Encoder( l1)
首先, 和BERT类似, 对于输入 X=x1,...,xm, 我们要把 x1设置为[CLS].
如果输入是句子对, 还需要在两个句子中间加入特殊符号[SEP].
然后, lexicon encoder将输入 X每个词映射为word, segment和positional embeddings.
Transformer Encoder( l2)
这部分利用多层的双向Transformer encoder将 l1层的输出映射为contextual embedding向量. BERT在预训练之后对每个独立的任务进行fine-tuning, MT-DNN则是利用多任务.
训练过程
前面讲到, MT-DNN训练包括两个阶段:
- pretraining
- multi-task fine-tuning
Shared layers的两个编码器(lexicon和transformer)利用两个非监督的预测任务来进行学习.
这两个任务和BERT预训练一样: masked language modeling和next sentence prediction.
而在multi-task fine-tuning阶段, MT-DNN和BERT就不一样了.

对分类任务, 定义损失函数如下:
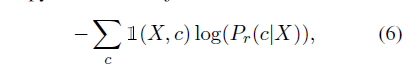
对文本相似任务, 定义损失函数如下:
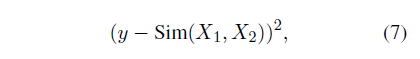
对相关性排序, 定义损失函数如下:

实验
1. 数据集
GLUE, SNLI, SciTail
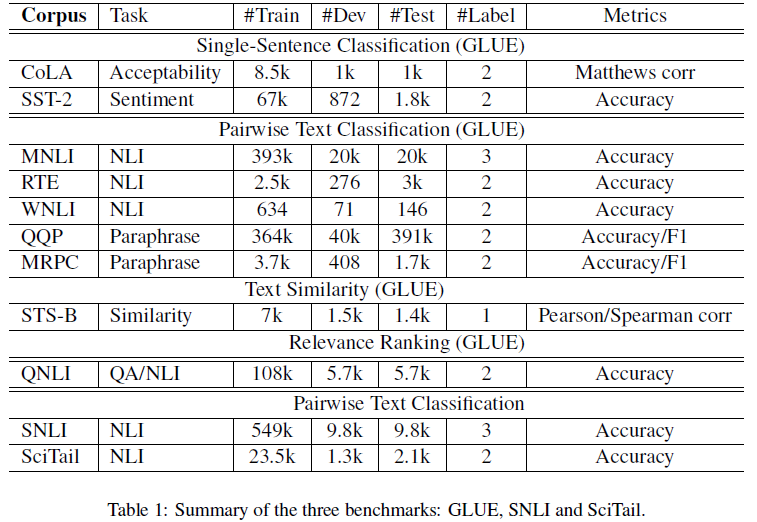
GLUE包含9个NLU数据集(CoLA, SST-2, STS-B, QNLI, QQP, MRPC, MNLI, RTE, WNLI), 主要包括以下三方面:
- question answering
- sentiment analysis
- textual entailment
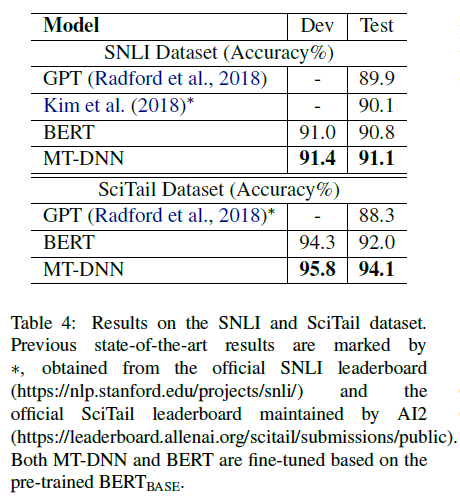
SNLI和SciTail都是NLI任务.
实现细节
- optimizer: Adamax
- learning rate: 5e-5
- batch size: 32
- epoch: 5
- dropout: 0.1
- gradient clip: gradient norm within 1
- 输入最长长度: 不超过512个tokens
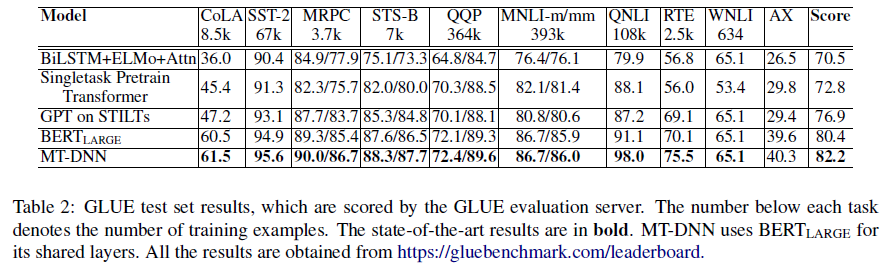
结果

 京公网安备 11010502036488号
京公网安备 11010502036488号